Mise en production d'un projet de Machine Learning
De nos jours, il fait consensus que pour aller en production, le code produit dans un projet de Machine Learning doit tôt ou tard quitter le format Jupyter Notebook, si cher aux data scientists, pour trouver sa place dans un IDE:
- Thoughtworks en parle au travers de Coding habits for data scientists sur son blog,
- Le blog de Martin Fowler nous suggère: Don't put data science notebooks into production,
- Nous partageons aussi cette conviction chez OCTO, nous l'avons formalisé en 2019 lors du meetup Crafting Data Science.
- Et les amateurs de memes et de gifs animés trouveront certainement leur bonheur dans l'exposé à l'avis très tranché de Joel Grus lors de la JupyterCon 2018: I don't like Notebooks.
En effet, les "bonnes pratiques" de conception logicielle peuvent s'appliquer plus facilement et de façon plus systématique dans un IDE, et cela peut nous aider à produire du code de qualité tout en restant confiant en ce que nous comptons livrer en production.
Toutefois, migrer du code de data science depuis le notebook vers l'IDE peut s'avérer compliqué pour le data scientist de formation, non-initié aux concepts de software craftsmanship. Le signal peut encore plus se brouiller au moment fatidique d'aller en production, action qui fait appel à un second ensemble de compétences à découvrir: l'ingénierie opérationnelle (ou l'ops pour les intimes).
Sans avoir la prétention de faire de vous des data scientists moutons à cinq pattes, nous vous proposons dans cet article de faire un premier pas dans le monde du MLOps en abordant le sujet du packaging d'applications de Machine Learning. Cela nous amènera, petit à petit, à le démystifier en commençant par aborder le format Wheel, puis Docker, et nous couvrirons enfin quelques stratégies de déploiement dont le choix peut impacter la façon de packager.
Si packager du code de Machine Learning en Python est pour vous synonyme de demander à vos utilisateurs de cloner votre repository git sur leur machine, cet article devrait vous intéresser.
Pour illustrer cela, nous utiliserons le désormais iconique challenge de classification en Computer Vision: "Muffin versus Chihuahua", qui consiste à produire un programme capable de détecter si un muffin 🍪 ou un chihuahua 🐶 est présent dans une image et les distinguer. Nous réaliserons le packaging d'une application capable de faire cela, avec son code Python mais aussi un modèle de deep learning et des fichiers (des images de muffin et de chihuahua à des fins de démonstration).
Du code de démonstration est disponible sur GitHub, dans ce repo-ci pour illustrer une approche de packaging avec modele embarqué, et dans cet autre repo pour illustrer une approche de packaging avec un modele isolé en tant que service. Ces approches seront détaillées en fin d'article.
📦 Livrer du code (littéralement) en production, est-ce bien sérieux ? 🤔
La question peut paraître provocatrice, mais le Python étant un langage interprété, contrairement au C qui se compile ou au JavaScript norme ES6 qui se transpile, il est légitime de se la poser.
Nous pouvons en effet vous livrer le code suivant en vous demandant de le copier sur votre poste local dans un fichier greetings.py et vous arriveriez à l'exécuter sans trop de problèmes (si tant est que vous l'exécutiez dans une version de Python supportant le type hinting) :
def greeting(name: str) -> str: return "Hello " + name
greeting("OCTO")
Toutefois, si on met de côté cet exemple volontairement simpliste pour se pencher sur du code de data science réaliste, comme celui de la librairie de calcul scientifique Numpy, les choses se compliquent :
- Il n'y a plus uniquement 1 fonction et son appel à livrer, mais plusieurs fichiers. Comment tous les récupérer ? Comment s'assurer qu'aucun fichier ne va manquer lors de la livraison ?
- Dans les sources, il y a du code Python, mais aussi du C. Est-ce qu'on peut livrer ces sources telles quelles ? Faut-il les compiler au préalable ou laisser l'utilisateur faire, sachant que, selon la cible (Windows, Linux ou OS X), les modalités de compilation peuvent changer ?
- Ce n'est pas le cas de Numpy, mais si votre application a besoin d'un modèle de Machine Learning ou de données pour fonctionner, comment les prendre en compte lors du packaging ?
Il y a une dizaine d'années, ces questions n'avaient pas de réponse standard : il fallait construire et partager ses propres recettes et imposer à nos utilisateurs d'exécuter du code arbitraire sur leur poste, rendant le packaging d'applications Python (de Machine Learning ou non) une douleur. Nous aborderons dans cet article des approches standards pour y remédier.
Et pour notre classifieur de muffins 🍪 et de chihuahuas 🐶 ?
Nous pouvons packager le code Python, le modèle et les images dans une unique archive pour démarrer simplement comme suit :
# dans un Makefile, en suivant la convention "self-documented"
.PHONY: package ## 📦 packaging de l'application au format zip package: zip -r muffin-v-chihuahua.zip ${path_to_code} ${path_to_model} ${path_to_data}
.PHONY: install-app ## ⚙️ Code arbitraire à exécuter chez vous si vous voulez vous servir de cette application install-app: MY_OS := 'windows_vista' unzip muffin-v-chihuahua.zip -d ${site_packages_destination_path} $(MAKE) compilation_en_c OS=${MY_OS}
Il devient alors de notre responsabilité de produire ce code de packaging et d'installation, mais aussi : de le tester, de le maintenir dans la durée et de s'assurer qu'il fonctionne comme souhaité dans tous les environnements que nos utilisateurs pourraient utiliser (Windows, Linux, Mac OS, Raspberry Pi, …).
Devant la multiplicité des façons de faire ou l'effort de maintenance à fournir, il n'est pas rare de voir des projets open-source se passer complètement de packaging pour demander à leurs utilisateurs de cloner le code via git en ligne de commande s'ils veulent s'en servir.
Toutefois, il est possible de faire différemment: le format standard Wheel a fini par émerger, et nous pouvons nous appuyer dessus désormais pour éviter d'avoir à produire, maintenir, et faire exécuter chez autrui du code arbitraire.
🐍 Le format Wheel ☸️ pour éviter de réinventer la roue 🥁
Le format Wheel est un format de packaging d'applications standard en Python.
📦 Petit point vocabulaire: par packager, nous entendons encapsuler :
- une version qui peut correspondre à un commit ou une date,
- le code qui est exécuté ou importé par l'utilisateur,
- avec des metadata pour le package manager (ex: pip, apt, yum),
- le tout dans une archive : zip | tar.gz | bzip2.
👉 Ce tout est communément appelé un artefact ou un paquet ... sauf en Python, où l'on parle de distribution.
Le format Wheel est un standard car celui-ci a émergé du processus de création standard de la communauté Python, via une Python Enhancement Proposal (ou PEP): en l'occurrence, la PEP427 initiée en 2012. Aussi, ce format est le seul format officiellement préconisé à ce jour par la Python Packaging Authority (PyPA).

Extrait de la documentation de la Python Packaging Authority (PyPA) sur le packaging en Python
Les distributions Wheel se publient généralement dans un dépôt public: le Python Package Index (PyPI), elles se génèrent avec la librairie standard setuptools, elles se publient dans PyPI via la librairie twine et se téléchargent avec la librairie pip.

La librairie setuptools s'emploie par convention dans un fichier setup.py, positionné par convention à la racine du projet :
from setuptools import setup
setup()
Le contenu de ce fichier setup.py peut paraître bien maigre. Il est en effet possible de renseigner la configuration de packaging via du code, de façon impérative, en renseignant les nombreux arguments de la fonction setup.
On préférera déporter cette configuration dans un fichier setup.cfg, en suivant un paradigme déclaratif. Ceci est possible depuis décembre 2016 et fonctionne comme suit :
[metadata] name = muffin-v-chihuahua-with-embedded-model version = 1.0 author = Mehdi Houacine author_email = <mon adresse>@octo.com home-page = https://github.com/Mehdi-H/muffin-v-chihuahua-with-embedded-model license = <une licence> description = To detect a muffin or a chihuahua in an image. platform = any classifiers = Programming Language :: Python :: 3 Intended Audience :: Developers, DataScientists, MLEngineers Operating System :: OS Independent Bug Tracker = https://github.com/Mehdi-H/muffin-v-chihuahua-with-embedded-model/issues [options] zip_safe = false packages = find: install_requires = numpy==1.19.4 Pillow==8.1.0 streamlit==0.74.1 watchdog==1.0.2 keras==2.4.3 tensorflow==2.4.0 include_package_data = True python_requires = >=3.8 [options.entry_points] console_scripts = muffin-v-chihuahua-with-embedded-model = muffin_v_chihuahua.__main__:main
On remarquera qu'il devient alors possible de renseigner les dépendances du projet directement au niveau de setup.py ou de setup.cfg (option install_requires) pour ainsi éviter de maintenir un fichier de dépendances ad-hoc, généralement nommé requirements.txt. Les dépendances python s'installent alors avec la commande "pip install ." à la racine du projet.
On notera que si PyPI est un dépôt de distributions Wheel publique, il existe un dépôt "bac à sable" TestPyPI, lui aussi publique, qui permet de s'essayer à la publication de packages Python. Il est aussi possible de créer des dépôts privés en montant son propre index ou en s'appuyant sur des offres managées comme le service Package Registry de Gitlab, le service PyPI repositories de JFrog ou encore le service Code Artifact chez AWS.
La librairie setuptools, qui permet de générer des distributions Wheel, permet aussi de gérer la compilation et le packaging d'extensions C au travers de l'argument ext_modules dans le fichier setup, ou encore de spécifier des fichiers de données devant être embarqués dans la distribution via les directives packages, package_data ou data_files comme employées, pour certaines, dans l'extrait de code ci-avant.
Si les subtilités entre les directives data_files et py_modules peuvent être difficiles à cerner (usage de chemin vers des fichiers avec extension, usage de chemins vers des modules sans extension, certaines directives mutuellement exclusives, sous-modules et récursivité, …), il est possible d'utiliser en remplacement la directive include_package_data = True ainsi qu'un fichier MANIFEST.in au même niveau que le fichier setup.py pour déclarer simplement les fichiers que l'on souhaite voir être embarqués dans l'archive, comme suit:
# MANIFEST.in ## 👇 On embarque toutes les données au format images JPG recursive-include muffin_v_chihuahua/data/muffin *.jpg recursive-include muffin_v_chihuahua/data/chihuahua *.jpg
## 👇 On embarque le modèle de classification include muffin_v_chihuahua/inception_v3_weights_tf_dim_ordering_tf_kernels.h5
Et pour notre classifieur de muffins 🍪 et de chihuahuas 🐶 ?
⚠️ Pour rappel, cet article sert un but démonstratif: montrer ce qu'il est possible de faire en termes de packaging avec setuptools et le format Wheel.
Nous allons illustrer cela en embarquant des fichiers dans une distribution Wheel. Cela a pour effet de créer une dépendance directe (un couplage fort) entre le code Python et d'autres artéfacts qui gravitent autour de celui-ci : des images et un modèle de Machine Learning dans notre cas.
Une dépendance aussi forte est rarement souhaitable car, souvent, le code, les données et les modèles ont des cycles de vie différents: on peut vouloir déployer une nouvelle version du code sans toucher aux images ou au modèle (et inversement).
Pour éviter ce couplage, nous aborderons en fin d'article une alternative à ce packaging en isolant le code d'une part et le modèle de Machine Learning d'autre part, en tant que service séparé.
Avec le fichier setup.py ci-avant, nous pouvons packager le code Python, le modèle et les images au format de distribution Wheel comme suit :
# makefile v2, remplacement du code de packaging arbitraire pour créer une distribution Wheel
.PHONY: package ## 📦 packaging de l'application au format standard wheel via le fichier setup.py package: pip install wheel && python setup.py bdist_wheel # 👉 produit un fichier .whl dans le dossier dist/
.PHONY: install-app ## ⚙️ Installation de l'application de façon standard avec l'installateur de paquets python install-app: pip install dist/muffin-v-chihuahua-1.0-py3-none-any.whl
.PHONY: run-app ## ⚙️ Pour lancer l'application, tel que défini dans la directive entry_point du fichier setup run-app: install-app muffin-v-chihuahua run-demo
On notera que setuptools permet aussi de générer une archive au format .zip si le format Wheel ne vous convient pas. Pour cela, on parle dans l'écosystème Python de générer une "distribution source" (ou source distribution dans la langue de Jay-Z), qui se produirait comme suit :
.PHONY: package ## 📦 packaging de l'application au format zip package: python setup.py sdist # produit une archive muffin-v-chihuahua.zip
Enfin, un dernier aparté : la PEP427, qui décrit le format Wheel, précise: a wheel is a ZIP-format archive with a specially formatted file name and the .whl extension. Cela signifie qu'il est possible d'interagir avec une distribution Wheel programmatiquement de la même façon qu'avec un fichier au format .zip. Pour vérifier que le modèle de Machine Learning ou les images y sont bien présentes, il est alors possible de lister le contenu d'une distribution Wheel de la façon suivante :
from zipfile import ZipFile path_to_wheel = './dist/muffin-v-chihuahua-1.0-py3-none-any.whl' print(ZipFile(path_to_wheel).namelist())
>>> ['muffin_v_chihuahua/__init__.py', 'muffin_v_chihuahua/__main__.py', # 👇 Le code source Python est présent 'muffin_v_chihuahua/classifier.py', 'muffin_v_chihuahua/display_predictions_with_an_embedded_model.py', # 👇 On retrouve bien le modèle dans la distribution Wheel 'muffin_v_chihuahua/inception_v3_weights_tf_dim_ordering_tf_kernels.h5',
'muffin_v_chihuahua/data/__init__.py', # 👇 On retrouve bien aussi les images au format .jpg 'muffin_v_chihuahua/data/chihuahua/1285578556_f4815c46f3.jpg',
'muffin_v_chihuahua/data/chihuahua/137564013_7dd48b5f1e.jpg',
'muffin_v_chihuahua/data/chihuahua/13803476_d1751cb3ec.jpg',
'muffin_v_chihuahua/data/chihuahua/7463030_7c1a554dc2.jpg',
'muffin_v_chihuahua/data/chihuahua/75541.jpg', # … plein d'autres fichiers ... 'muffin_v_chihuahua/data/muffin/520365653_d07fe2128e.jpg',
'muffin_v_chihuahua/data/muffin/7232767_aeca4dc59f.jpg',
'muffin_v_chihuahua/data/muffin/877626288_59961572e4.jpg']
On notera enfin que si pip permet d'installer une distribution depuis un fichier .whl comme ci-avant, il peut aussi en installer une via une URL pointant vers un projet versionné avec un système de gestion de version (VCS) supporté.
Il devient alors possible de distribuer son application Python auprès d'utilisateurs qui peuvent l'installer avec pip en pointant vers une URL d'un dépôt de code, par exemple @@ARTICLE_CONTENT@@gt; pip install git+<url HTTPS d'un repo github>, plutôt que de leur demander de cloner un repository quelque part sur leur poste. Le module pip se base sur la présence d'un fichier setup.py qui doit impérativement se trouver à la racine du projet pour parvenir à cela.
📦 Pour aller plus loin sur l'histoire du packaging d'applications en Python et l'écosystème d'outils cités dans cette partie (pip, index PyPI, …), la conférence de Dustin Ingram lors de la PyCon de Cleveland en 2018: Inside the cheesechop - How Python Packaging works aborde ces sujets 🎥
🐳 Le packaging en image Docker, pour aller plus loin
Même s'il est préférable de suivre des pratiques telles que le DevOps pour favoriser la collaboration entre développeurs et ops dans une organisation, il peut arriver que le déploiement d'une application (de Machine Learning ou non) soit réalisé par des ops qui ne l'ont pas conçue.
En découvrant le code de l'application, ces personnes découvriront aussi qu'il existe des pré-requis, parfois implicites, au bon fonctionnement de celle-ci qu'il faut installer sur une infrastructure cible (sur leur propre poste pour la tester ou bien dans un environnement de production, par exemple):
des dépendances systèmes, spécifiques à l'OS,
- comme des drivers GPU ou des paquets à installer avec apt ou yum,
une version de Python bien précise,
- ex: Python 2 à partir de la version 2.6 ou python 3 à partir de la version 3.6.5,
une liste de dépendances Python à installer avec pip,
- pouvant provenir d'un index publique (comme PyPi) ou privé,
de la configuration,
sous la forme de fichiers contenant des variables ou pour le logging,
ou sous la forme de variables d'environnement,
des données et/ou un éventuel modèle de Machine Learning, qui devront être positionnés à un endroit spécifique du système relativement aux sources Python.
Si le format Wheel permet d'automatiser la réalisation de quelques-unes de ces tâches, comme télécharger puis embarquer les dépendances Python de l'application, il ne permet pas aujourd'hui d'embarquer une version de Python ou d'adresser le sujet des dépendances systèmes, par exemple. Il existe bien une directive python_requires qui permet de spécifier une version de Python dans le fichier setup.py, mais elle ne sert qu'à bloquer l'installation si la version de Python de l'utilisateur n'est pas compatible.
Il y a une dizaine d'années, ce soucis se serait réglé par la rédaction d'une procédure, pourquoi pas au format Word, pour décrire toutes les actions manuelles à réaliser sur notre système pour livrer une version fonctionnelle de notre application, comme nous le rapporte Arnaud Mazin dans le podcast Café Craft. Des outils comme Docker existent aujourd'hui pour automatiser la réalisation de ces pré-requis et limiter les actions manuelles.
Si vous souhaitez vous familiariser avec Docker, voici un article pouvant servir d'introduction à ce vaste sujet qu'est la conteneurisation.
Et pour notre classifieur de muffins 🍪 et de chihuahua 🐶 ?
Afin d'aider à la lecture du dockerfile qui va suivre, voici un aperçu de l'arborescence de fichiers du code que nous allons packager. Il est aussi disponible sur github.
. ├── MANIFEST.in ├── README.md ├── dist # généré par la commande python setup.py bdist_wheel │ └── muffin_v_chihuahua_with_embedded_model-1.0-py3-none-any.whl ├── dockerfile ├── makefile ├── muffin_v_chihuahua │ ├── __init__.py │ ├── __main__.py │ ├── classifier.py # classif. des images de muffins et de chihuahuas │ ├── data │ │ ├── __init__.py │ │ ├── chihuahua # contient des images de chihuahuas .jpeg │ │ └── muffin # contient des images de muffins .jpeg .jpeg │ ├── display_predictions_with_an_embedded_model.py │ └── inception_v3_weights_tf_dim_ordering_tf_kernels.h5 ├── setup.cfg └── setup.py
En python, un dockerfile permettant de décrire le packaging d'une application de Machine Learning serait le suivant :
FROM python:3.8.0-slim # 👈 définition de la version de Python nécessaire, tirée du dockerhub
# 👇 Installation de dépendances sur le système RUN apt-get update \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* # 👇 Packaging du modèle de machine learning COPY inception_v3_weights_tf_dim_ordering_tf_kernels.h5 /app/ # 👇 Packaging des sources python COPY display_predictions_with_embdded_model.py \ pretrain_model.py \ requirements.txt /app/ # 👇 Packaging des données COPY data/ /app/data # 👇 Installation de dépendances Python via pip WORKDIR /app RUN pip install --user -U pip && pip install -r requirements.txt # 👇 Exposition de l'application avec Streamlit via le port 8080 EXPOSE 8080 CMD streamlit run display_predictions.py --server.port 8080
Si ce dockerfile permet de packager l'application de Machine Learning en y copiant et exécutant les sources mêmes via les instructions COPY et CMD, il est aussi possible de se servir du format wheel pour éviter cette situation présentée en première partie d'article :
FROM python:3.8.0-slim ...
# 👇 Packaging des sources python COPY display_predictions.py classifier.py /app/ # 👇 Installation de dépendances Python via une wheel copiée depuis le poste local WORKDIR /app COPY /app/dist/ /app/dist/ # 👈 la wheel est préalablement générée en local, dans un dossier dist/ RUN pip install dist/muffin_v_chihuahua-1.0-py3-none-any.whl ...
Au lieu de copier la distribution Wheel depuis le poste local, il peut être intéressant de générer celle-ci au sein du dockerfile afin de le rendre plus autoportant et d'automatiser la génération d'artefacts.
FROM python:3.8.0-slim # 👈 définition de la version de Python nécessaire ...
# 👇 Packaging des sources python COPY display_predictions_with_embedded_model.py classifier.py \ requirements.txt setup.py /app/ # 👇 Génération et installation de dépendances Python via wheel WORKDIR /app RUN pip install --user -U pip && python setup.py bdist_wheel RUN pip install dist/muffin_v_chihuahua-1.0-py3-none-any.whl ...
Toutefois, ce packaging est bien complexe. Le résultat de la construction est une image docker dans laquelle vont se trouver les sources Python en double: celles copiées dans l'image via l'instruction COPY et celles produites en installant la distribution wheel fraîchement produite.
Pour remédier à cela, docker propose la fonctionnalité multi-stage build qui permet de produire une image docker à publier dans laquelle on peut venir positionner des artéfacts issus d'images intermédiaires (appelées généralement dans les exemples de la documentation de Docker: builder images).
Cette fonctionnalité propose d'apporter plus de lisibilité au dockerfile, en le découpant en étapes, et de produire une image docker plus petite en n'embarquant que ce qui sera nécessaire en production.
Cela donnerait dans notre cas un dockerfile que nous pourrions séparer en plusieurs étapes intermédiaires: une étape de génération pour le modèle de machine learning, une pour les données, et une dernière pour la distribution Wheel :
FROM python:3.8.0-slim as model-builder # 👈 étape de production du modèle : il peut être généré ici ou télécharger depuis un dépôt de modèles ... # 👇 Génération des data FROM python:3.8.0-slim as data-builder ... # 👇 Génération de la Wheel FROM python:3.8.0-slim as app-builder ... # 👇 Génération de l'image résultante à publier FROM python:3.8.0-slim as app …
En complétant les trous, nous obtenons enfin :
FROM python:3.8.0-slim as model-builder # 👈 étape de génération du modèle RUN apt-get update \ && apt-get install -y wget --no-install-recommends \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* # 👇 On pourrait entraîner un modèle ici, mais on va plutôt télécharger un modèle pré-entraîné. RUN wget https://github.com/fchollet/deep-learning-models/releases/download/v0.5/inception_v3_weights_tf_dim_ordering_tf_kernels.h5 # 👇 Génération des data FROM python:3.8.0-slim as data-builder COPY Makefile /app/ WORKDIR /app/ ## 👇 Téléchargement des données dans /app/data/ (via HTTP) RUN make chihuahua-dataset && make muffin-dataset # 👇 Génération de la distribution Wheel ## pour cela il faut: les sources python, le modèle produit ci-avant, et les données (images de muffins et de chihuahuas) FROM python:3.8.0-slim as app-builder RUN apt-get update \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* COPY muffin_v_chihuahua/ /app/muffin_v_chihuahua/ COPY MANIFEST.in setup.cfg setup.py /app/ ## 👇 Récupération du modèle, qui est une dépendance de la distribution Wheel, via l'option --from COPY --from=model-builder ./inception_v3_weights_tf_dim_ordering_tf_kernels.h5 /app ## 👇 Récupération des données qui sont une dépendance de la Wheel via --from COPY --from=data-builder /app/data/ /app/data/ WORKDIR /app ## 👇 Génération de la wheel avec le nécessaire: sources, modèle et data RUN pip install --user -U pip \ && python setup.py bdist_wheel # 👇 Génération de l'image résultante à publier FROM python:3.8.0-slim as app COPY --from=app-builder /root/.local /root/.local COPY --from=app-builder /app/dist/ /app/dist/ WORKDIR /app ## 👇 Installation de la distribution Wheel qui embarque les sources, le modèle et la data RUN pip install dist/muffin_v_chihuahua_with_embedded_model-1.0-py3-none-any.whl ENV PATH=/root/.local/bin:$PATH EXPOSE 8080 CMD ["muffin-v-chihuahua-with-embedded-model", "run-demo", "--server.port", "8080"]
Pouir rappel, ce dockerfile est consultable dans ce repo Github.
⚠️ Pour rappel, cet article sert un but démonstratif: montrer ce qu'il est possible de faire en termes de packaging avec setuptools, le format Wheel et Docker.
Pour un usage de production, il conviendra de réaliser ces différentes actions de packaging dans le dockerfile avec un utilisateur non-root.
Voici un panorama de quelques outils que vous pouvez utiliser pour analyser vos dockerfiles ou vos images docker pour en améliorer la qualité ou détecter des vulnérabilités de sécurité.
Le packaging peut alors se réaliser de la façon suivante :
.PHONY: package ## 📦 packaging de l'application au format docker. "." désigne le dossier courant contenant le dockerfile package: docker build -t muffin-v-chihuihua:v1 .
.PHONY: run-app ## ⚙️ Pour lancer l'application une fois l'image docker buildée run-app: docker run muffin-v-chihuihua:v1
📦 Quelques ressources supplémentaires sur le packaging avec Docker pour Python :
👉 Exemple de packaging en Python sur le blog officiel de docker👉 De bonnes pratiques lors de la rédaction d'un dockerfile
👉 Un panorama d'outils pour scanner un dockerfile (lint, scan de sécurité, …)
Les stratégies de déploiement impactent la façon de packager
Nous avons vu jusqu'à maintenant une unique façon de packager nos applications de Machine Learning avec Docker, mais il en existe plusieurs.
En effet, l'article Continuous Delivery 4 Machine Learning (CD4ML) décrit l'approche de conteneurisation que nous avons étudiée jusqu'à maintenant comme une approche de packaging intéressante pour envisager un déploiement d'application avec modèle embarqué : le modèle de Machine Learning est traité comme une dépendance de l'application qui consomme ses prédictions, il est construit et packagé avec celle-ci.
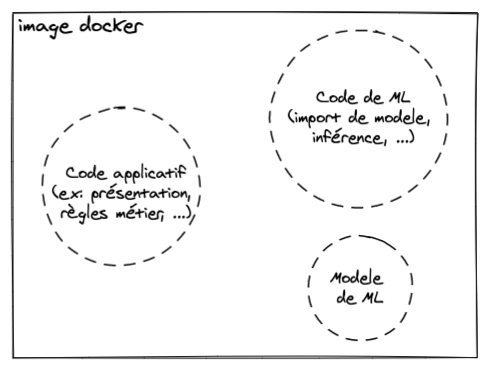
Packaging pour un déploiement avec "modèle embarqué" (embedded model) avec docker, la même image docker produit des prédictions et les affiche.
Nous sommes naturellement arrivés à ce format de packaging dans le déroulé de cet article, mais il est possible de réaliser le packaging différemment.
Pour illustrer cela, voici une façon de packager, avec Docker, au service d'une autre stratégie de déploiement: la stratégie du modèle utilisé en tant que service (model deployed as a separate service).
Ici, deux images docker sont créés puis exécutées:
la première a pour objectif d'afficher des prédictions afin que des utilisateurs les consultent,
La seconde image peut prendre la forme d'un service pouvant être interrogé par la première pour lui fournir des prédictions.
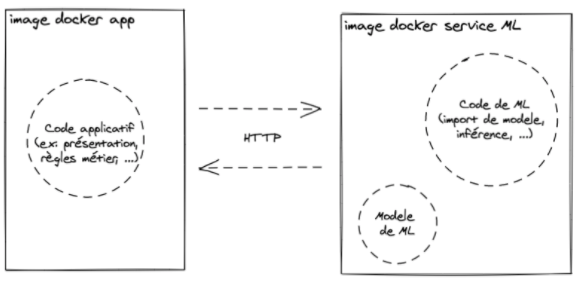
Packaging pour déploiement avec "modèle séparé en tant que service" avec Docker. L'image Docker de gauche affiche uniquement des prédictions sur un frontend, l'image de droite est un service web HTTP backend réalisant une inférence quand il est requêté.
Ce dernier mode de packaging peut demander un certain effort dans la conception d'une application pour isoler le contenu relatif au Machine Learning, mais cet investissement pour obtenir une application avec un faible couplage ouvre la porte à des stratégies de déploiement intéressantes : lorsque le modèle de Machine Learning doit évoluer, il est possible de mettre à jour uniquement celui-ci, sans impacter le code de l'application (et vice-versa).
Et pour notre classifieur de muffins 🍪 et de chihuahuas 🐶 ?
Cette approche d'isolation du modèle en tant que service auquel nous pourrions demander des prédictions de classification de muffins ou de chihuahuas peut s'illustrer avec les deux dockerfiles qui suivent :
# Fichier app-dockerfile pour packager le code de présentation des prédictions FROM python:3.8.1-slim as app-builder RUN apt-get update && apt-get clean && rm -rf /var/lib/apt/lists/* COPY muffin_v_chihuahua/ /app/muffin_v_chihuahua/ COPY MANIFEST.in setup.cfg setup.py /app/ WORKDIR /app RUN pip install --user -U pip \ && python setup.py bdist_wheel FROM python:3.8.1-slim as app COPY --from=app-builder /root/.local /root/.local COPY --from=app-builder /app/dist/ /app/dist/ COPY muffin_v_chihuahua/data/ /app/data WORKDIR /app RUN pip install --user -U pip \ && pip install dist/muffin_v_chihuahua_frontend-1.0-py3-none-any.whl ENV PATH=/root/.local/bin:$PATH ENV INFERENCE_HOST localhost EXPOSE 8090 CMD ["muffin-v-chihuahua-model-as-a-service", "run-demo", "--server.port", "8090"]
# Fichier ml-web-service-dockerfile pour packager un service web capable de fournir des prédictions FROM python:3.8.1-slim as model-builder RUN apt-get update \ && apt-get install --no-install-recommends -y wget \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* RUN wget https://github.com/fchollet/deep-learning-models/releases/download/v0.5/inception_v3_weights_tf_dim_ordering_tf_kernels.h5 FROM python:3.8.1-slim as web-service-builder RUN apt-get update \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* COPY muffin_v_chihuahua_ml_service/ml_web_service.py setup.py setup.cfg \ muffin_v_chihuahua_ml_service/classifier.py /app/ WORKDIR /app RUN pip install --user -U pip && pip install --user --no-cache-dir . FROM python:3.8.1-slim as ml-web-service COPY --from=web-service-builder /root/.local /root/.local COPY --from=web-service-builder /app /app COPY --from=model-builder ./inception_v3_weights_tf_dim_ordering_tf_kernels.h5 /app WORKDIR /app ENV PATH=/root/.local/bin:$PATH EXPOSE 8000 CMD ["uvicorn", "ml_web_service:app", "--host", "0.0.0.0", "--port", "8000"]
Pour rappel, ces deux dockerfiles sont consultables dans cet autre repo Github.
En exécutant les deux images produites avec ces dockerfiles en local,
- on accède sur http://localhost:8090 à l'image "application frontend" qui a pour but d'afficher des prédictions afin de répondre à la question: "est-ce une image de muffin ou de chihuahua ?".
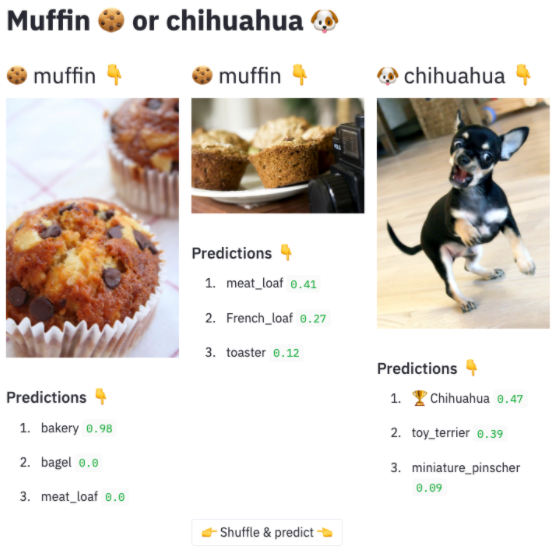
Application (frontend Streamlit) qui affiche des images avec une probabilité sur la présence d'un muffin ou d'un chihuahua dans celles-ci.
- et on accède sur http://localhost:8080 au service web, côté backend.
Notamment, un healthcheck est exposé sur la route / afin de renvoyer le code HTTP 200 OK pour s'assurer que le service est actif,
et ce service fournit des prédictions avec un modèle de Deep Learning quand il reçoit une image en HTTP POST sur la route /predict.
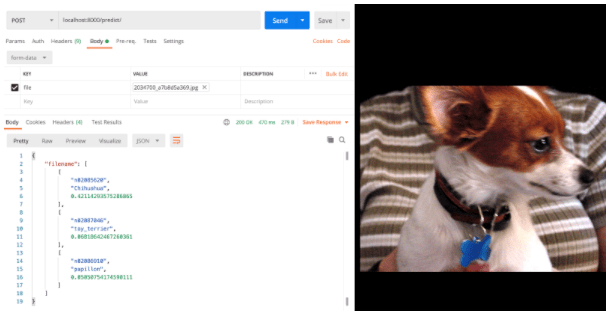
Envoi dans Postman d'une image de chihuahua dans le corps de la requête HTTP POST sur la route /predict au service web de machine learning (backend FastAPI).
Conclusion
Dans cet article, nous avons vu plusieurs façons de packager une application de Machine Learning. Au cours de la dernière décennie, des standards ont émergé dans l'écosystème Python afin d'éviter de partager et exécuter nos applications en se servant des sources mêmes, via l'usage de setuptools et du format Wheel. Plus largement, Docker est devenu un incontournable du packaging, quel que soit le langage. Ces formats sont adaptés pour le Machine Learning: pour packager un modèle ou des données par exemple grâce à leurs philosophies de conception : build once, run anywhere ou encore batteries included.
Si cet article se voulait démonstratif des capacités de Wheel et Docker pour packager du code de Machine Learning, on veillera toutefois à éviter de mettre tous nos oeufs dans le même panier : packager du code, un modèle et des données dans un unique artéfact peut nous amener a créer des adhérences non-souhaitées qui peuvent devenir difficiles à rompre avec le temps. Aussi, il est généralement de bon ton de suivre les grands principes de conception logicielle que sont [separation of concerns](https://fr.wikipedia.org/wiki/S%C3%A9paration_des_pr%C3%A9occupations#:~:text=La%20s%C3%A9paration%20des%20pr%C3%A9occupations%20(ou,g%C3%A8re%20un%20aspect%20pr%C3%A9cis%20de) ou encore les 12-factors app, notamment le troisième facteur qui encourage la stricte séparation de la configuration, que nous n'avons pas abordé dans cet article, et du code.
L'usage même de ces formats (Docker ou Wheel) peut varier en fonction des usages que nous souhaitons en faire, comme nous avons pu le voir au travers des stratégies de déploiement de modèles de Machine Learning détaillées dans l'article CD4ML (modèle embarqué dans l'application, ou isolé pour être consulté en tant que service). Dans l'absolu, aucune stratégie n'est vraiment meilleure qu'une autre, mais choisir la plus adaptée dans son contexte demande de se projeter sur l'usage que nos utilisateurs feront de notre application de Machine Learning ainsi qu'une réflexion sur la façon d'intégrer cette application de manière pérenne dans son SI.
Pour rappel, du code permettant de jouer ces différentes approches de packaging est disponible sur Github : dans ce repo-ci (modèle embarqué) et dans cet autre repo (modèle isolé en tant que service), et des ressources ont été disposées en fin de chaque partie de cet article si vous souhaitez aller plus loin.