Mise en prod de la data science, le jour d’après - Compte-rendu du talk de Mehdi Houacine et Emmanuel-Lin Toulemonde à La Duck Conf 2020
On parle beaucoup de mise en production de data science, mais peu du jour d'après. Que se passe-t-il après la mise en production, comment monitorer un modèle de data science ? Les systèmes de data science introduisent une complexité supérieure à une application de SI traditionnelle puisqu’ils sont souvent composés de composants introduisants de l’aléa.
Emmanuel-Lin et Mehdi, consultant data science chez Octo Technology, vous proposent une méthodologie pour mettre en place le monitoring de vos systèmes de data science.

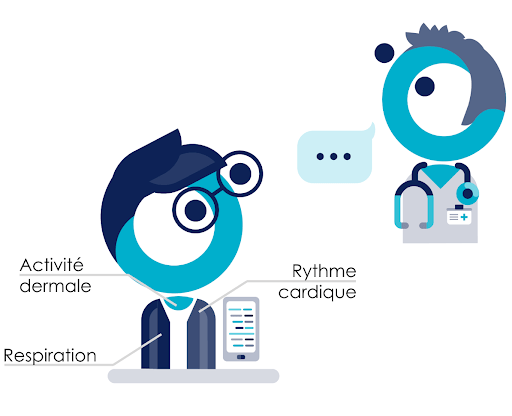
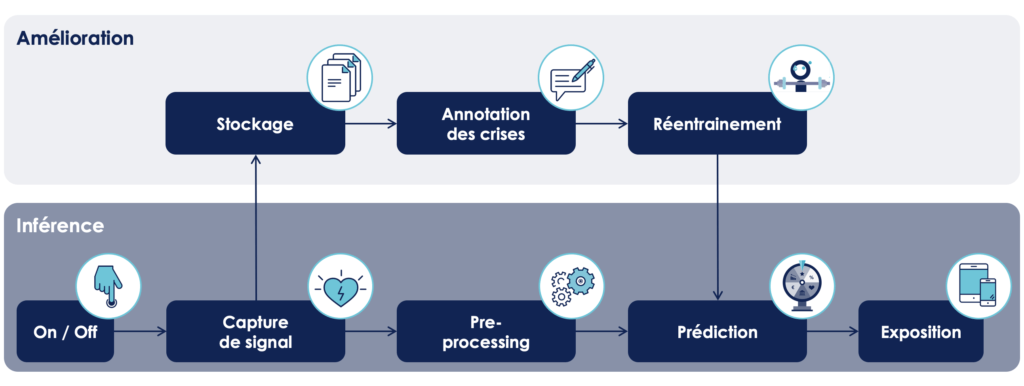
Pour cela, partons d’un exemple concret de système de data science : la prédiction des crises d’épilepsie. Les crises d’épilepsie sont très handicapantes notamment car un patient ne sait pas quand elles vont arriver. Savoir quand aura lieu la prochaine crise permet aux patients de prévoir et réaliser des activités qu’ils n’auraient pas pu faire sereinement comme conduire, par exemple.
Pour parvenir à cette prédiction, le patient porte un certain nombre de capteurs sur lui qui permettent l’acquisition de son rythme cardiaque, sa respiration, son activité dermale. L’objectif est de lui fournir des alertes sur son téléphone lorsqu’une crise est imminente.
Voir la présentation complète sur slideshare
Nous faisons l’hypothèse que ce modèle est en production et utilisé par les patients. Les différents interlocuteurs qui interagissent avec notre système ont alors des attentes différentes vis à vis du système :
- Le data scientist : savoir si le modèle de machine Learning fonctionne bien en production
- L’utilisateur : recevoir une prédiction avec au moins 5 minutes d’avance
- Le régulateur : s’assurer que le modèle n’est pas biaisé envers certaines populations
- Le sponsor : considérant son investissement, s’assurer que cela fonctionne
Ces attentes doivent être observées et suivies dans la durée, pour cela, nous avons besoin de monitorer la totalité du système et pas seulement le modèle.
L'intuition du monitoring par la distribution
L’intuition du data scientist consiste généralement à adresser le monitoring par la visualisation de diverses distributions calculées à partir des données en entrée du système, des données de sortie et des résultats intermédiaires :
Cette approche amène à calculer de nombreuses métriques et visualiser de nombreux graphes qui viennent alors peupler des dashboards peu lisibles: la multiplicité des indicateurs, tel du bruit dans un signal, nous empêche de savoir si le système fonctionne comme prévu.
Avant de s’attaquer au monitoring, il convient de poser des notions de base pour découper le problème au mieux :
Différents types de Monitoring
Dans un premier temps, il existe deux grandes familles de monitoring :
- le monitoring à froid : une investigation à posteriori sur une information historisée
- le monitoring à chaud : une investigation en temps réel sur des indicateurs exposés immédiatement
Dans le cadre de cette conférence, nous allons nous concentrer sur le monitoring à chaud.
Le déterminisme et le non-déterminisme
Un système de data science peut se comporter de façon déterministe (étant donné une situation, le résultat d’un traitement déterministe est anticipable) mais aussi de façon non-déterministe (par exemple: l'aléa à l'entraînement du modèle rend cette étape de non-déterministe). C’est d’ailleurs le challenge des systèmes de data science, le monitoring du non-déterminisme.
Un feedback à différentes vitesses
En fonction de l’interlocuteur, le monitoring apporte du feedback à différentes vitesses :
- Un monitoring technique : usage GPU, usage RAM.
- Un monitoring du niveau de service pour les utilisateurs afin de comprendre ce qu’ils attendent réellement du service et éviter les insatisfactions : Service Licence Agreements (SLA) ou Service Licence Objective (SLO).
- Un monitoring du coût ou du gain financier pour le sponsor : pour valoriser une bonne prédiction, on peut utiliser des proxys et des hypothèses tout en étant sur de mesurer la vérité (même sur un temps plus long).
- Un monitoring par le prisme de la donnée en utilisant la donnée à différentes étapes de transformation pour identifier des comportements inattendus.
Une méthodologie simple et itérative
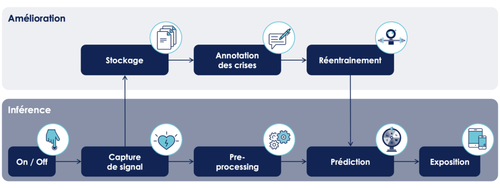
Emmanuel-Lin et Mehdi proposent une méthode simple en monitorant la donnée qui consiste à poser des sondes pour monitorer votre système de data science :
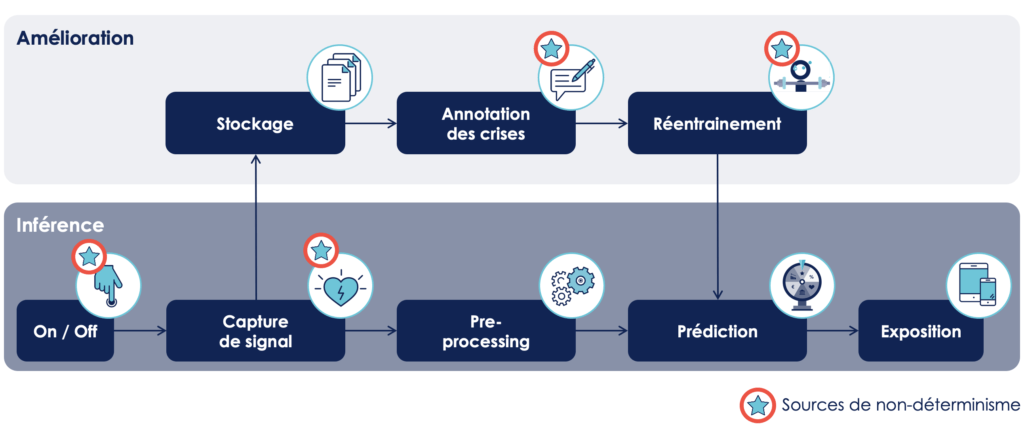
- Tracer le pipeline de traitement de notre système :
- Identifier les sources de non-déterminisme :
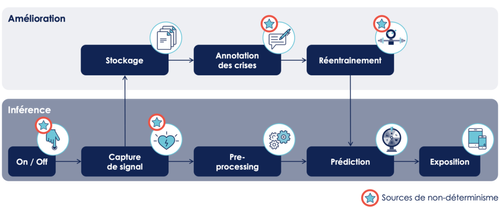
- Sur chaque source de non-déterminisme poser une sonde en explicitant :
- La raison du non-déterminisme
- La propriété attendue dans un comportement nominal du système
- La sonde proposée pour pour vérifier cette propriété
Soit si on s’intéresse à l’exemple de l’étape du réentraînement :
- La raison du non-déterminisme : L’aléa est au cœur des algorithmes d’apprentissages
- La propriété attendue dans un comportement nominal du système : Performance au moins équivalente sinon meilleure au modèle déjà en production
- La sonde proposée pour pour vérifier cette propriété : Shadow production pour comparer les performances des modèles candidats par rapport au modèle déployé en production
Enfin le concept de la “voiture balais”, qui consiste à monitorer la distribution des prédictions en bout de pipeline, permet de valider que la prédiction est stable dans le temps. Ainsi on peut à faible coût identifier des problèmes peu probables, pas identifiés ou pas formalisés.
Quelques grands principes
Pour challenger vos sondes, quelques grands principes émergents à l’usage de cette méthodologie :
- Plus une sonde est loin dans le pipeline, plus elle est générique : Une sonde qui arrive tard dans le pipeline va lever de nombreuses défaillances sans identifier de manière précise leur source.
- Lorsqu’une sonde lève une erreur à l’étape N mais qu’il n’y a pas de problème après, cette sonde mérite d’être challengée : Si la sonde mesure que le rythme cardiaque est supérieur à 180, mais que la performance réelle du système est toujours bonne, alors cela ne servait à rien de fixer ce seuil : il faut modifier ou retirer cette sonde.
- Une sonde ne doit pas casser les SLAs : Les sondes ne doivent pas impacter le fonctionnement de l’application par exemple en introduisant de la latence à la prédiction.
- Seuls les aléas anticipables et probables méritent des sondes : Nous pourrions monitorer le fait que c’est bien notre patient qui porte les capteurs et pas son chat, mais c’est tellement peu probable que cela ne vaut pas le coût.
- Si le besoin est critique, la sonde doit faire partie de l’application : Nous pourrions monitorer le nombre de capteurs effectivement branchés, mais comme ils sont tous nécessaires au bon fonctionnement de l’application, cette vérification n’est pas un monitoring mais doit être intégrée au pipeline.
En conclusion, une fois votre modèle en production, il faudra le monitorer avec un suivi : des indicateurs techniques, du SLA et SLO, de la donnée et du ROI. Plutôt que d’adopter un monitoring des distributions qui s'avère coûteux et inefficace, préférez appliquer la méthode suivante de façon itérative :
- Tracer le pipeline de donnée
- Poser des sondes sur les comportements non-déterministes
- Challenger ces sondes
Si vous travaillez actuellement sur un projet de data science, vous pouvez dès maintenant ajouter ces cartes à votre backlog pour commencer à réfléchir au monitoring :
- Faire un atelier monitoring de systèmes de data science
- Mesurer et historiser les métriques identifiées
- Construire un Dashboard pour visualiser les sondes
- Donner accès au Dashboard aux parties prenantes
- Récolter du feedback
Si vous souhaitez en savoir plus, retrouvez l'article de blog détaillé et la vidéo de la conférence :