Mise en place d'un mécanisme de déploiement continu
Disclaimer
L’article qui suit fait appel à des concepts relativement avancés sur le fonctionnement de Kubernetes. Une connaissance raisonnable de l’outil est nécessaire afin de bien appréhender les concepts abordés.
Il s’agit également de la suite d’un premier article. N’hésitez pas à aller à l’adresse suivante. avant de commencer.
Introduction
Dans un article précédent, j’abordais une technique permettant d’éteindre des environnements de développement notamment en supprimant les nœuds d’un cluster Kubernetes lorsqu’ils ne sont plus nécessaires.
Toutefois, le besoin de démarrage d’environnement de développement n’est pas le seul contexte dans lequel on peut appliquer cette technique. On peut le retrouver notamment dans les cas suivants :
- Construction d’artefacts applicatifs (images de conteneurs, librairie ou application Java, pages web statiques, etc).
- Lancement d’environnements éphémères afin de lancer une série de tests
- Lancement de traitements longue durée (batchs)
Cette liste n’est bien sûr pas exhaustive !
Dans tous les cas, le système lance une série de traitements durant un laps de temps avant de rendre les ressources disponibles. Elles peuvent alors être réaffectées à d’autres usages.
Si pendant un temps donné, l’activité n’est plus significative, on peut même procéder à une suppression de la puissance souscrite afin de réaliser des économies. En poursuivant le raisonnement plus loin, il est même possible d’imaginer de ne démarrer les machines que lorsque le besoin s’en fait sentir.
Le but de cet article est de mettre en œuvre un gestionnaire de construction et de voir comment l’intégrer avec Gitlab. La suite des instructions se fera sur l’instance Gitlab publique (gitlab.com). Néanmoins, les différentes indications sont tout à fait transposables dans le cas d’une instance dédiée.
Gestion de la construction des livrables
Présentation de l’architecture initiale
Pour la suite de l’article, un agent Gitlab Runner va être ajouté au système afin de prendre en charge la construction des livrables.
Dans l’article précédent, deux groupes de machines ont été créés :
- Un groupe en charge de l’hébergement de production (ou par défaut)
- L’hébergement d’environnement de développement
Afin de préserver au maximum l’environnement de production, le groupe de machine chargé de l’environnement de développement va être utilisé pour la partie construction.
Ci-dessous un schéma résumant ces différents éléments :

Au démarrage des environnements, l’agent Gitlab Runner démarre dans son espace de nom. À noter que ce dernier ne consomme que très peu de ressources, il peut donc démarrer sur le même nœud que l’environnement de développement.
En revanche, la partie construction est relativement coûteuse en ressources et déclenchera très certainement la création de nœuds de traitement dans Kubernetes.
Installation de l’agent Gitlab Runner dans Kubernetes
Rattachement de l’agent à Gitlab
L’agent Gitlab Runner s’installe sous forme de chart Helm. Afin de l’associer à une instance Gitlab, il est nécessaire de spécifier deux informations :
- L’URL de l’instance Gitlab
- Le token d’accès de l’instance Gitlab
En plus de ces deux paramètres, le chart Helm va se charger de créer le compte de service ainsi que l’attribution des droits nécessaires à la création des pods de build.
La création du token se définit au niveau du projet dans le contexte du Projet dans l’écran Settings →Runners → New project runner. Dans cet écran, entrez un nom de Runner (ex : kube-cluster) et cliquez sur le bouton Create runner. Attention de ne pas perdre le token du Runner : il n’est pas possible de le récupérer ultérieurement.
Sur l’écran suivant, conservez bien la valeur du Token. Il sera nécessaire de l’indiquer à Helm dans le champ runnerToken couplé au champ gitlabUrl pour indiquer l’url de l’instance Gitlab.
Ci-dessous la déclaration reprenant ces indications :
gitlabUrl: https://gitlab.com/
runnerToken: glrt-xxxx
rbac:
create: true
serviceAccount:
create: true
Sélection des machines, tolérances et affectation de ressources
En plus de cette configuration, il est nécessaire d'indiquer aux pods en charge des constructions d’utiliser les machines de développement et de tolérer les taints évoqués dans l’article précédent.
Ci-dessous les indications correspondantes à injecter dans les pods :
nodeSelector:
env: dev
tolerations:
- key: env
value: dev
effect: NoSchedule
Ces machines sont basées sur le modèle Discovery d2-8. Elles sont constituées de 2 CPU accompagnées de 8 Go de mémoire. De fait, la quantité de ressources n’est pas infinie et il est important d’indiquer la quantité de CPU et mémoire qui doit être réservée aux constructions réalisées par Gitlab.
À noter que cet outil utilise trois types de traitement :
- Le job en charge de la construction en lui-même
- Les conteneurs chargés de lancer les services supplémentaires : base de données PostgreSQL, MongoDB, gestionnaire de messages, etc.
- Le conteneur helper chargé de faire les “petites manipulations” : communication avec Gitlab, récupération du code source, copie des binaires, etc.
Pour la suite, l’essentiel des ressources seront affectées au conteneur principal tandis que les deux autres conteneurs auront une quantité de ressources plus petites. Afin de laisser le plus de souplesse possible, l’affectation sera dirigée essentiellement par la mémoire. La CPU sera affectée de manière plus “lâche” : une valeur de base sera affectée avec un maximum assez important de manière à laisser de la souplesse dans le lancement de la construction.
Ci-dessous un exemple de définition compatible avec l’utilisation de machine de type Discovery de chez OVH (d2-8 par exemple) :
gitlabUrl: https://gitlab.com/
runnerToken: glrt-xxxx
rbac:
create: true
serviceAccount:
create: true
runners:
config: |-
[[runners]]
[runners.kubernetes]
image = "ubuntu:22.04"
cpu_request = "0.2"
cpu_limit = "3"
memory_request = "5Gi"
memory_limit = "7Gi"
privileged = true
# service containers
service_cpu_request = "0.1"
service_cpu_limit = "1"
service_memory_request = "512Mi"
service_memory_limit = "768Mi"
# helper container
helper_cpu_request = "0.05"
helper_cpu_limit = "0.1"
helper_memory_request = "50Mi"
helper_memory_limit = "150Mi"
[runners.kubernetes.node_selector]
env = "gitlab"
[runners.kubernetes.node_tolerations]
"env=gitlab" = "NoSchedule"
Sauvegardez ce fichier sous le nom de fichier gitlab-runner-values.yaml.
Lancement de l’installation du Runner Gitlab
Tout est prêt. Il faut maintenant installer le runner Gitlab à l’aide de Helm. N’hésitez pas à consulter l’article suivant afin de procéder à son installation.
Ajoutez tout d’abord la source des charts Helm de Gitlab :
helm repo add gitlab https://charts.gitlab.io
Lancez ensuite l’installation du runner Gitlab :
helm upgrade --install gitlab-runner gitlab/gitlab-runner \<br> --namespace gitlab --create-namespace \<br> --values gitlab-runner-values.yaml
Ce dernier renvoie un ensemble d’indications sur l’installation. Vérifiez que le pod associé au runner démarre correctement :
kubectl -n gitlab get pods
Ci-dessous le résultat attendu en cas de succès :
NAME READY STATUS RESTARTS AGE
gitlab-runner-69db6f4f75-vsvzg 1/1 Running 0 6m
Vérifiez également que le runner apparaît bien dans la liste des runners disponibles pour le projet.
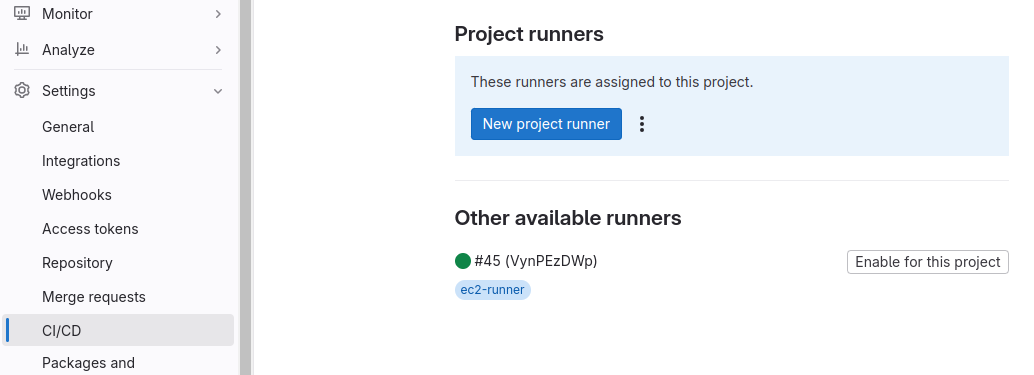
Profitez-en pour désactiver l’utilisation des runners par défaut depuis l’écran Settings → CI/CD → Runners (bouton Disable group runners et Disable Instance runners for this project). De cette façon, seul le runner associé au projet pourra lancer des travaux de construction.
Tout est prêt, il est temps de tester le système de build !
Création du pipeline de construction
Constitution du livrable de test
Afin d’illustrer un cas concret, une application va être créée à l’aide du CI de Gitlab. Pour faire au plus simple, cette dernière sera constituée d’une image de conteneur Nginx dans lequel sera déposé un fichier texte contenant la version courte du commit courant.
Le plus simple pour arriver à cette solution est de passer par un paramètre renseigné au moment de la construction de l’image. Ce dernier alimentera un fichier commit.txt à l’aide d’une étape RUN.
Ci-dessous le contenu du fichier Dockerfile permettant de remplir l’ensemble de ces indications :
FROM docker.io/library/nginx:1.28
ARG COMMIT
ENV COMMIT=${COMMIT}
RUN echo ${COMMIT} > /usr/share/nginx/html/commit.txt
Sauvegardez ce fichier puis lancez la construction de cette image à l’aide de Docker ou Podman :
# remplacez la commande docker par podman le cas échéant
docker build -t local.io/test --build-arg COMMIT=test .
Lancez maintenant l’image en écoutant sur le port 8080 :
docker run --publish 8080:80 --name test --detach local.io/test
Interrogez l’entrée http://localhost:8080/commit.txt à l’aide de l’instruction curl suivante :
curl http://localhost:8080/commit.txt
La commande renvoie normalement la valeur de l’argument COMMIT utilisé lors de la construction (test par exemple).
Construction de l’image
Les instructions de construction de l’image sont prêtes. Reste à ordonnancer sa construction à l’aide du CI de Gitlab et d’injecter le commit. Kaniko est plutôt bien indiqué pour remplir cette fonction du fait qu’il ne réclame que très peu de privilèges.
Ce dernier est disponible sous forme d’image (gcr.io/kaniko-project/executor:debug) et réclame les paramètres suivants :
- L’emplacement du fichier Dockerfile (option -f)
- L’emplacement du répertoire de travail (option -c)
- Le passage de paramètre COMMIT (option --build-arg)
- Le nom de l’image (option -d)
Pour la suite, l’image sera référencée sous deux tags :
- Le tag courant (variable $IMAGE_TAG)
- Le tag correspondant au commit courant (variable $CI_COMMIT_SHORT_SHA)
Le nom de l’image sera composé de la variable $CI_REGISTRY_IMAGE suivie de ‘/app’.
Il est également important d’alimenter le fichier /kaniko/.docker/config.json avec le contenu des variables suivantes sous forme de fichier JSON :
- $CI_REGISTRY : adresse du registre de Gitlab
- $CI_REGISTRY_USER : utilisateur permettant d’accéder au registre d’image
- $CI_REGISTRY_PASSWORD : token permettant d’accéder au registre d’image
Ci-dessous un exemple de déclaration permettant de remplir l’ensemble de ces indications :
build-app:
stage: build
variables:
IMAGE: $CI_REGISTRY_IMAGE/app
image:
name: gcr.io/kaniko-project/executor:debug
entrypoint: [ "" ]
before_script:
- echo "{\"auths\":{\"$CI_REGISTRY\":{\"username\":\"$CI_REGISTRY_USER\",\"password\":\"$CI_REGISTRY_PASSWORD\"}}}" > /kaniko/.docker/config.json
- IMAGE_TAG=`echo $CI_COMMIT_REF_NAME | sed 's/[\/+]/-/g'`
- echo $IMAGE
script:
- /kaniko/executor -f $CI_PROJECT_DIR/Dockerfile
-c $CI_PROJECT_DIR --build-arg COMMIT=$CI_COMMIT_SHORT_SHA
-d $IMAGE:$IMAGE_TAG -d $IMAGE:$CI_COMMIT_SHORT_SHA
Sauvegardez cette définition dans le fichier .gitlab-ci.yml à la racine du projet (attention de bien conserver le “.” au début du nom de fichier) et commitez-le avec le reste du code source.
Lors de la synchronisation du code source avec Git, Gitlab va procéder à la construction de l’image.
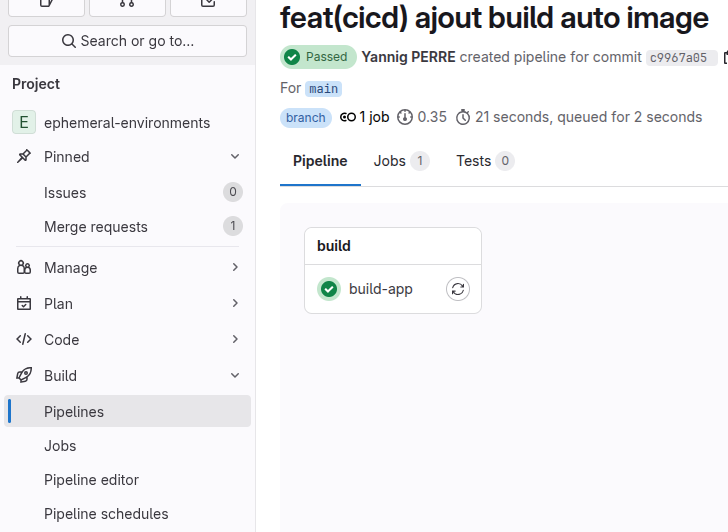
N’hésitez pas à scruter l’état du job de construction afin de vérifier que tout fonctionne correctement.
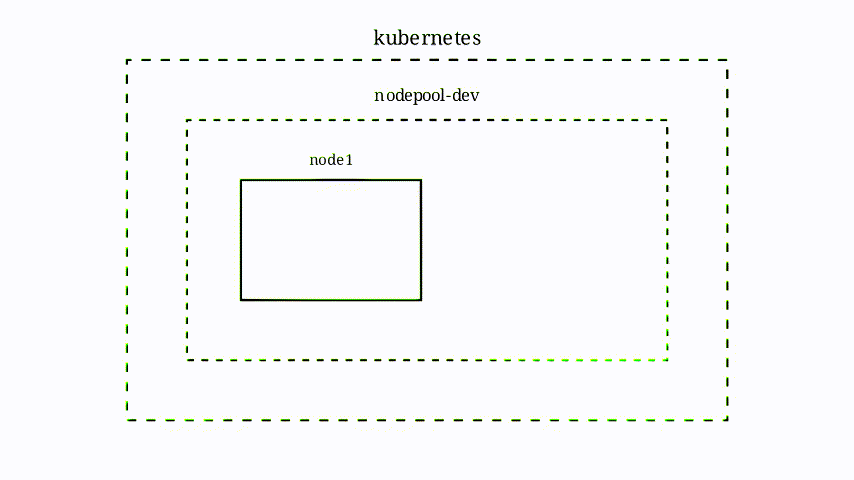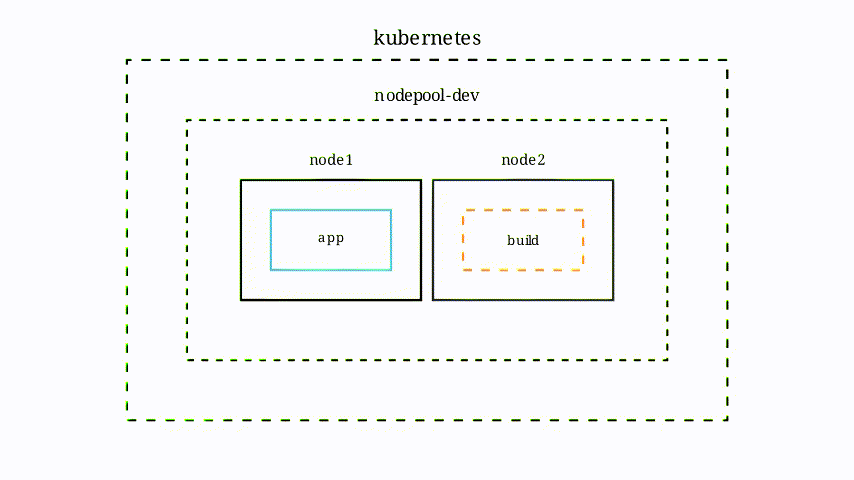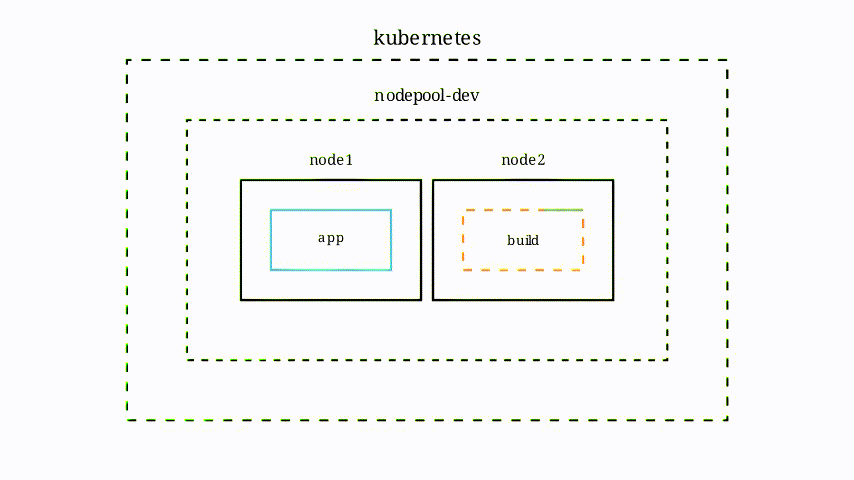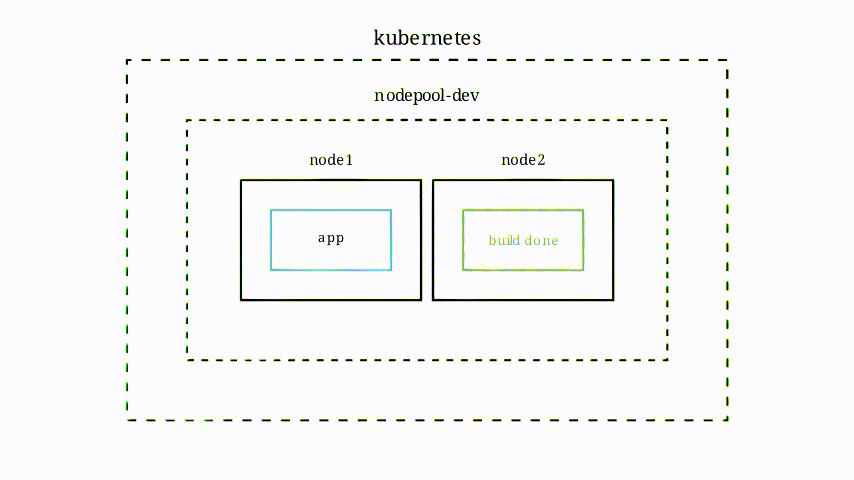
Cette animation illustre comment réagit le cluster Kubernetes (notamment lorsqu’il n’a pas assez de puissance de disponible) lorsque le projet construit une image.
Déploiement de l’application dans Kubernetes
L’image est prête. Reste à la déployer dans Kubernetes. Pour la suite, ce travail sera fait à l’aide de l’outil Helm.
Première étape : créer un chart Helm dans le répertoire deploy. Pour cela, lancez les instructions suivantes :
mkdir -p deploy
helm create app deploy/app
Le chart est prêt, reste à le déployer. Cette opération va réclamer les instructions suivantes :
- Le mot clé upgrade (couplé à l’instruction --install afin de gérer l’idempotence)
- Le nom de la release du Chart suivi de l’emplacement du chart (deploy/app)
- Le mot clé --wait afin d’attendre que l’application soit correctement déployée
- Le nom de l’espace de nom à l’aide de l’option --namespace
- L’instruction --create-namespace là-aussi afin de gérer l’idempotence
En plus de ces informations sur les caractéristiques du déploiement, il est important de renseigner l’emplacement de l’image (variable image.repository) ainsi que son tag associé (variable image.tag).
Ci-dessous l’instruction complète permettant de lancer cette opération localement :
helm upgrade --install app deploy/app --wait \
--namespace env-develop \
--create-namespace \
--set image.repository=$CI_REGISTRY_IMAGE/app \
--set image.tag=main # À adapter en fonction du nom de la branche
Vérifiez ensuite que le déploiement se passe bien à l’aide de l’instruction suivante :
kubectl -n env-develop get pods
Si tout se passe bien le système doit renvoyer la sortie suivante :
NAME READY STATUS RESTARTS AGE
app-6bf5946d5-9cphj 1/1 Running 0 27m
Intégration du déploiement dans Gitlab
L’application est correctement déployée. Reste à intégrer cette opération dans le pipeline de déploiement de Gitlab. Pour la suite, l’image docker.io/alpine/helm:3.18 sera utilisée afin de disposer de l’utilitaire Helm.
Autre aspect : le déploiement de l’environnement sera rattaché à la phase deploy afin de garantir que la construction de l’image soit bien lancée avant.
Ci-dessous un exemple de déclaration de déploiement dans l’espace de nom env-develop et répondant à l’ensemble des indications précédemment évoquées :
dev-deployment:
image:
name: docker.io/alpine/helm:3.18
entrypoint: [ "" ]
variables:
K8S_NAMESPACE: env-develop
stage: deploy
interruptible: false
script:
- helm upgrade --install app deploy/app --wait
--namespace ${K8S_NAMESPACE}
--create-namespace
--set image.repository=$CI_REGISTRY_IMAGE/app
--set image.tag=$CI_COMMIT_SHORT_SHA
Ajoutez cette définition dans le fichier .gitlab-ci.yml et intégrez-le dans un commit Git afin d’être pris en charge par Gitlab.
Vérifiez l’état du pipeline. Normalement ce dernier devrait tomber en erreur sur l’étape dev-deployment avec le message suivant :
…
$ helm upgrade --install --wait --namespace ${K8S_NAMESPACE} --create-namespace app deploy/app
Error: query: failed to query with labels: secrets is forbidden: User "system:serviceaccount:gitlab:default" cannot list resource "secrets" in API group "" in the namespace "env-develop"
Cleaning up project directory and file based variables
00:00
ERROR: Job failed: command terminated with exit code 1
Ici, le système indique que le ServiceAccount default de l’espace de nom gitlab n’a pas les droits de consulter l’état des objets Secrets dans l’espace de nom env-develop (ce qui est bien sûr attedu !).
Correction problème de droits
Disclaimer : les configurations utilisées ici sont données à titre indicatif. Elles n’ont pas vocation à être reporté en l’état sans adaptation. N’hésitez pas à prendre contact avec un administrateur Kubernetes ou Sécurité afin de valider que ces indications respectent les normes de sécurité en vigueur.
Afin de simplifier au maximum les choses, le compte de service du runner Gitlab va être repris et affecté aux jobs de déploiement.
Cette réaffectation se fait à l’aide du champ service_account associés au champ runner → config du chart Helm.
Ci-dessous l’extrait de configuration correspondant :
runners:
config: |-
[[runners]]
[runners.kubernetes]
service_account = "gitlab-runner"
En plus de cette association, il est nécessaire d’affecter des droits supplémentaires au compte de service de Gitlab permettant d’administrer le cluster. Cette fois-ci, cette affectation se fait au niveau du champ rbac et notamment avec les champs suivants :
- Champ clusterWideAccess : affectation de droits au niveau global du cluster
- Champ rules : liste de droits à affecter au compte de service
Ci-dessous un exemple de configuration possible à utiliser avec le chart Helm :
rbac:
create: true
clusterWideAccess: true
rules:
- apiGroups: ['*']
resources: ['*']
verbs: ['*']
Ajoutez ces indications dans le fichier gitlab-runner-values.yaml puis lancez la mise à jour du runner Gitlab :
helm upgrade --install gitlab-runner gitlab/gitlab-runner \<br> --namespace gitlab --create-namespace \<br> --values gitlab-runner-values.yaml
Vérifiez que le pod associé au Runner se lance correctement à l’aide de l’instruction kubectl -n gitlab get pods.
Relancez ensuite le job de déploiement en erreur. Cette fois-ci, le système déploie correctement le chart de l’application dans l’espace de nom env-develop.
Déclenchement du CI sur condition
Origine du problème
Le mécanisme de déploiement automatique est en place. Toutefois, aucun test n’est fait pour savoir si on doit réellement déployer ou non. Ainsi la simple création d’une branche procédera au déploiement sur l’environnement.
Dans le cas d’une personne seule, le problème n’a pas trop de conséquences. Toutefois, dès que ce système sera mis à disposition d’une équipe de développeurs, ce comportement devrait rapidement poser problème …
Déclenchement de traitement sur condition
Afin d’empêcher le mécanisme de build de se déclencher à tout bout de champ, des règles vont être introduites. Elles vont spécifier les conditions de déclenchement de nos travaux. Pour la suite, les règles seront les suivantes :
- Déclenchement des différentes étapes lors de la création d’une Pull Request ou sur la branche develop
- Déploiement de l’application sur l’espace de nom env-develop lors de modification sur la branche develop (suite à l’inclusion d’une Pull Request)
Dans Gitlab, ce mécanisme se définit à l’aide du champ rules et prend la forme d’un tableau référençant l’ensemble des conditions de déclenchement.
Ci-dessous un exemple de déclaration utilisable pour répondre aux contraintes évoquées précédemment :
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
- if: '$CI_PIPELINE_SOURCE != "schedule" && $CI_COMMIT_BRANCH == "develop"'
Reste maintenant à injecter ses conditions ad-hoc dans les étapes existantes. Ci-dessous un exemple d’implémentation faisant appel à la notion d’extension (mot clé extends) :
.dev-trigger:
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
- if: '$CI_COMMIT_BRANCH == "develop"'
build-app:
extends: .dev-trigger
stage: build
variables:
IMAGE: $CI_REGISTRY_IMAGE/app
image:
name: gcr.io/kaniko-project/executor:debug
entrypoint: [ "" ]
before_script:
- echo "{\"auths\":{\"$CI_REGISTRY\":{\"username\":\"$CI_REGISTRY_USER\",\"password\":\"$CI_REGISTRY_PASSWORD\"}}}" > /kaniko/.docker/config.json
- IMAGE_TAG=`echo $CI_COMMIT_REF_NAME | sed 's/[\/+]/-/g'`
- echo $IMAGE
script:
- /kaniko/executor -f $CI_PROJECT_DIR/Dockerfile -c $CI_PROJECT_DIR --build-arg COMMIT=$CI_COMMIT_SHORT_SHA -d $IMAGE:$IMAGE_TAG -d $IMAGE:$CI_COMMIT_SHORT_SHA
dev-deployment:
rules:
- if: '$CI_COMMIT_BRANCH == "develop"'
variables:
K8S_NAMESPACE: env-develop
image:
name: docker.io/alpine/helm:3.17
entrypoint: [ "" ]
stage: deploy
script:
- helm upgrade --install --wait --namespace ${K8S_NAMESPACE} --create-namespace app deploy/app
--set image.repository=$CI_REGISTRY_IMAGE/app --set image.tag=$CI_COMMIT_SHORT_SHA
On remarque que le déclenchement du déploiement utilise un cas particulier : il n’est déclenché que lors de la construction de la branche develop.
Dorénavant le système ne se déclenche plus que lors de la création de Pull Request et lors de l’intégration sur la branche develop pour déploiement continue.
Quelques réglages supplémentaires
En l’état, le mécanisme fonctionne très bien. Il peut arriver toutefois que lors de la première construction de la journée, le système mette un peu de temps à attribuer des machines au cluster.
Autre aspect, par défaut les jobs de Gitlab ne s’interrompt pas. Or, dans le cas de la préparation d’une PR, il peut arriver que les modifications s’enchaînent ne laissant pas le temps au système de finir sa construction avant d’en lancer d’autres en parallèle.
Dans ce cas là, le mieux est de pouvoir interrompre ces travaux qui n’ont de toute façon plus d’utilité.
Ci-dessous les déclarations correspondantes rattachées à la clé default :
default:
# Interrupt job if new modifications on current branch/MR/...
interruptible: true
retry:
max: 2
when: ["runner_system_failure", "stuck_or_timeout_failure"]
Conclusion
L’approche détaillée dans cet article permet de tirer pleinement parti de la flexibilité offerte par Kubernetes pour orchestrer dynamiquement la construction et le déploiement d’applications via GitLab CI. En exploitant un cluster capable de s’auto-dimensionner et en intégrant un GitLab Runner dédié, on optimise l’utilisation des ressources tout en garantissant l’isolation des environnements critiques.
Au-delà du simple gain de performance ou de coût, cette méthode permet aussi de bâtir un pipeline CI/CD robuste, reproductible, et prêt à évoluer vers une industrialisation plus poussée. Le recours à des outils comme Kaniko pour la construction d’images et Helm pour le déploiement renforce encore l’automatisation et la portabilité des environnements.
Il conviendra toutefois de veiller à l’alignement des droits et des pratiques de sécurité dans Kubernetes, notamment en production. Cette architecture constitue une excellente base pour explorer d’autres scénarios avancés, comme les environnements à la demande par branche, ou l’analyse dynamique des performances en post-déploiement.
Vous l’aurez compris, tout n’a pas encore été exploré. Un prochain article s’attardera sur la gestion des environnements éphémères 😅.