Mise en application de DVC sur un projet de Machine Learning
Introduction
DVC (Data Version Control) est un package Python qui permet de gérer plus facilement ses projets de Data science. Cet outil est une extension de Git pour le Machine Learning, comme l’énonce son principal contributeur Dmitry Petrov dans cette présentation. DVC est à la fois comparable et complémentaire à Git. Il va s’occuper de synchroniser vos données et votre code. Il est donc particulièrement intéressant dans le cadre d’un projet de Machine Learning où le modèle et les données évoluent au fil du développement. Un autre point intéressant est la capacité de DVC à permettre un retour en arrière des données et du modèle. Il est possible de choisir une version du modèle, et de retourner au code et aux données qui ont permis de l’obtenir. Dans un contexte d'entraînement, c’est particulièrement intéressant pour explorer une branche de notre modèle mais aussi pouvoir revenir en arrière si ce nouveau modèle ne correspond pas à nos attentes.
A travers cet article nous avons souhaité faire un retour d'expérience sur l'utilisation de DVC dans un projet concret de Machine Learning. L’accent a été mis sur la conception d’un modèle en équipe pour tirer partie des fonctionnalités de DVC, l’objectif étant d’en identifier les avantages et les inconvénients (à noter que nous sommes actuellement à la version 0.52.1). Dans un premier temps, nous allons exposer les difficultés rencontrées dans les projets de Machine Learning et pourquoi un outil tel que DVC peut améliorer la productivité d’une équipe Data, avant de vous montrer comment utiliser efficacement l'outil dans un projet concret.
Pourquoi avoir recours à DVC ?
Partage des données volumineuses
Dans un projet, il est nécessaire d’utiliser des VCS (Version Control System), autrement dit des outils de gestion de versions. Le plus utilisé, Git, répond aux besoins dans le cadre de projets logiciels, mais est loin d’être optimal pour les projets de Machine Learning. En effet, le workflow est totalement différent entre ces deux types de projets. Dans le premier, il est question d’ajouts de nouvelles fonctionnalités, donc si le développement se déroule comme attendu, chaque nouvelle version est meilleure que la précédente. Dans le cadre d’un projet de Machine Learning, ce sont les métriques choisies qui témoignent de la performance des expérimentations. Plusieurs critères font varier les scores obtenus : le modèle choisi, le feature engineering réalisé sur les données d’entrées mais avant tout, le dataset utilisé. Il devient donc indispensable de versionner non seulement le code source qui a permis de générer le modèle, mais aussi des données potentiellement très lourdes.
Le réflexe serait de se tourner vers un outil tel que Git-LFS qui a pour vocation de versionner des fichiers lourds. Le principe de fonctionnement est simple : les fichiers volumineux sont stockés sur un serveur distant et seules les références pointant sur ces fichiers sont partagées via Git. Le principal problème est qu’en utilisant cette solution, nous sommes contraints de sauvegarder nos données sur un repository GitHub, GitLab ou Atlassian, et que la taille maximale d’un fichier ne peut pas excéder 2Gb (cf. doc Git)
Reproductibilité
Dans un projet de Machine Learning, il est rare de créer le meilleur modèle du premier coup. Il faut souvent ré-exécuter plusieurs fois le code en faisant varier plusieurs paramètres :
- le jeu de données utilisé
- le type de modèle utilisé
- les hyper paramètres choisis
- les features construites
- etc.
Il existe une infinité de combinaisons, et créer une nouvelle expérimentation peut prendre du temps en fonction de la charge de travail et des ressources mises à disposition. C’est pourquoi nous conseillons de séparer les différentes étapes pour ainsi ne ré-exécuter que ce qui est nécessaire. Un tel graphe de dépendances peut être implémenté à travers un Makefile.
DVC est un outil qui permet de répondre à ces deux besoins. L’avantage est que la création du graphe de dépendances et celle des références pointant sur les données se fait via le même outil et dans la plupart des cas dans le même temps. Nous vous proposons de voir comment à travers un exemple concret d’implémentation.
Les étapes d’un workflow avec DVC
Pour tester l'utilisation de DVC, nous avons choisi de travailler sur toutes les étapes classiques d’un projet de machine learning : réception des données, construction des features, des modèles, leur évaluation… Par ailleurs, nous avons travaillé à deux sur ce projet pour mettre à l’épreuve l'utilisation de DVC en équipe. L’idée étant de vous donner une idée des avantages mais aussi des inconvénients de DVC sur un projet de Machine Learning.
Pour notre exemple, nous avons choisi de travailler sur un dataset proposé par UCI où l’objectif est de prédire le nombre de personnes qui vont prendre le métro chaque heure entre Minneapolis et St Paul. Certes, ce dataset n’est pas très volumineux mais nous avons testé avec des données beaucoup plus lourdes et n’avons pas remarqué de ralentissement (DVC pouvant mettre quelques secondes pour calculer un hash de 2Go). Cependant, il faut noter qu’avec un grand nombre de données le pipeline prend aussi plus de temps à s'exécuter, le calcul de hash devient donc négligeable.
Initialisation
Que ce soit pour intégrer DVC dans un nouveau projet ou dans un projet existant, il faut savoir que le coût de mise en place est très faible. En effet, il suffit d’installer le package via pip install dvc avant d’exécuter un dvc init. Tout comme Git, cette commande va automatiquement créer un dossier .dvc qui contient un fichier de configuration (la plupart des commandes DVC sont semblables à celles de Git, ce qui permet de prendre très rapidement l’outil en main). Dans ce fichier il faut indiquer le chemin vers le cloud externe qui permettra à DVC de sauvegarder et récupérer les données. Il est possible de le faire manuellement mais nous vous conseillons d’utiliser la commande adéquate dvc remote add -d <remote_name> <remote_path>. Ce fichier de configuration doit être partagé via Git pour que les autres membres de l’équipe puissent accéder aux données, ou si vous souhaitez revenir à une version antérieure des données.
L’objectif est de garder une trace du modèle, des métriques et du dataset utilisé pour chaque version que l’on souhaite sauvegarder. Pour cela il est possible d’exécuter dvc add <file>. Cette commande crée un fichier de métadonnées .dvc qui fait référence au fichier d’origine. Nous utilisons cette commande uniquement pour stocker le dataset. Pour le reste, c’est-à-dire le modèle et les métriques nous conseillons de les sauvegarder via un pipeline (suite d’étapes qu’il faut réaliser pour créer un modèle). L’avantage de passer par un pipeline et DVC est de pouvoir suivre les sorties de chaque étape tout en créant un graphe de dépendances très utile pour la reproductibilité.
Construction du pipeline de travail
Nous sommes partis sur un schéma classique : récupération des données, feature engineering, entrainement du modèle puis évaluation de celui-ci. En sachant les dépendances et les fichiers de sortie de chaque étape, DVC crée un graphe orienté acyclique (DAG). Pour cela, chaque noeud de notre graphe est défini via un fichier DVC. Ce noeud est défini avec des entrants, des sortants et un script à exécuter pour générer ces sortants.
DVC permet la création de ce DAG via la commande run :
dvc run -f step.dvc \
-d input_folder \
-d script.py \
-o output_folder \
python script.py
Via le terminal, la création du pipeline est relativement rapide mais demande de la rigueur. Il faut faire attention à ne pas confondre les entrants et les sortants entre chaque noeud. Dans le cas linéaire, les données sortantes sont les données entrantes de la prochaine étape. Il faut aussi noter qu’il est plus simple de définir le pipeline une fois qu’elle a déjà été exécuté à la main. En effet, les fichiers étant déjà créés, il est possible d’utiliser l’auto-complétion du terminal pour ne pas oublier certaines dépendances.

Figure 1 : Schéma de notre pipeline de base
DVC est capable de gérer des fichiers comme dépendances mais aussi des dossiers. Cela s’avère plutôt pratique car vous n’avez pas besoin de spécifier toutes les dépendances d’une étape mais seulement le dossier où elles se trouvent. Cela évite par exemple de redéfinir une étape lorsque l’on utilise un K-fold plutôt qu’un simple split.
Reproduction du pipeline
Une fois le pipeline défini, la reproduction du pipeline est complètement gérée par DVC. Il suffit de lui donner un noeud du graphe à ré-exécuter et l’outil cherche les dépendances qui ont changé dans le graphe et ré-exécute seulement les étapes nécessaires. Pour réaliser cela, la commande à exécutée est : dvc repro <step_name>
DVC vérifie à chaque étape que les dépendances ont changé et seulement si c’est le cas alors l’étape est ré-exécutée. Par exemple si vous ne modifiez que l’étape d’entraînement afin de générer un nouveau modèle, toutes les étapes de pré-processing ne seront pas ré-exécutées mais celles d’entraînement et d’évaluation le seront (si train.py a bien été déclaré en tant que dépendance). Cette gestion du graphe vous permet de vous abstraire des diverses dépendances d’une étape, au niveau du code et des données. Ainsi, si vous arrivez sur le projet, vous avez juste à reproduire le pipeline pour avoir vos données à jour. Plus de risque d’oublier une étape ou de les exécuter dans le mauvais ordre - à condition bien entendu que le graphe de dépendances ait été bien défini. D’où la rigueur nécessaire à la définition du graphe.
Nous avons testé DVC avec des graphes plus complexes. Par exemple, nous avons implémenté un pipeline de production parallèle au pipeline d'entraînement. Dans ce cas, il faut que DVC gère le fait que le modèle doit d’abord être entraîné pour ensuite seulement faire une prédiction sur les données de production.
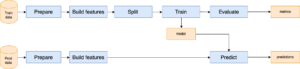
Figure 2 : Schéma des pipelines d’entraînement et de production
Pour gérer la parallélisation des deux pipelines, nous avons pris le parti de diviser notre projet en sous-modules par étape exécutable via commande click. Ce package python permet d’ajouter des options dans les appels d’exécution et donc permet d’isoler le code pur de traitement et les différents entrants du pipeline qui sont fonctions de DVC. Ici par exemple, nous souhaitons effectuer les mêmes étapes de préparation : dans le premier cas avec les données d’entrainement (python prepare.py --train) et dans le deuxième avec les données de production (python prepare.py --prod).
Même si la reproduction d’expérimentations est facilitée, nous recommandons tout de même de réaliser la phase d’exploration dans un notebook. Cette phase d’exploration est indispensable pour mieux comprendre les données que l’on traite (voir cet article). Cependant, mettre en place le pipeline DVC avec du code en dehors du notebook est trop coûteux pour une simple exploration des modèles. Nous vous conseillons de l’utiliser lorsque vous souhaitez pouvoir reproduire votre expérimentation, ce qui n’est pas le cas de chaque modèle d'exploration.
Sauvegarder et partager le pipeline
Une fois votre pipeline défini et votre modèle entraîné, il est maintenant possible d’utiliser DVC pour sauvegarder votre expérimentation. Pour cela, on utilise DVC en complément de Git. Git va stocker les fichiers sources (.py) ainsi que les fichiers de notre pipeline (.dvc). DVC quant à lui va stocker uniquement les données. En détail, les fichiers .dvc contiennent des références vers les données utilisées pour cette expérimentation. DVC n’a besoin que de ses références pour récupérer les données de l’expérimentation. Pour éviter les conflits avec Git, DVC met automatiquement ces données dans le .gitignore. Par la suite, DVC va s’occuper de les envoyer sur le service de stockage que vous aurez configuré. La plupart des services classiques sont disponibles : Amazon S3, GCP, Microsoft Azure, etc. Si vous le souhaitez vous pouvez tester la fonctionnalité en local (voir doc).
Une fois le service choisi configuré, il suffit de commiter votre code et les fichiers .dvc avec Git puis de faire un simple dvc push. Avec cette commande vos données ont été envoyées vers votre service de stockage. La vitesse du push dépend de votre réseau mais pour des données légères (dans notre cas 5Mo), c’est relativement imperceptible.
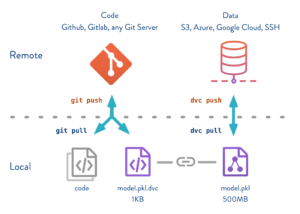
Figure 3 : Schéma du versioning du code et des données
Source : dvc.org
Vous avez maintenant votre expérimentation sauvegardée via Git et DVC. Pour y revenir il faudra soit se souvenir de l’identifiant du commit, soit placer un tag sur le commit. Ainsi, il vous suffira de connaître le tag pour revenir à ce modèle. Nous avons pris le parti de nommer nos tags de la manière suivante <date>-<type_de_modèle> (par exemple : 06/25-RandomForest) . Ce format permet d’avoir les tags triés par ordre chronologique quand on souhaite les afficher dans la console. Ainsi, il est plus facile de suivre les différents modèles générés.
Tout cela paraît relativement simple à faire, seulement quelques commandes mais il est important de les faire dans le bon ordre pour que la sauvegarde soit correcte. Par exemple, si vous commitez les dvc file avant d’avoir exécuté votre pipeline, les références dvc pointeront toujours vers l’ancien modèle et non vers le modèle nouvellement entraîné. Par expérience c’est quelque chose qui nous est arrivé souvent et on se retrouve avec une sauvegarde sans le bon modèle. Pour cela, nous avons créé un Makefile simplifiant la création d’une nouvelle tentative en étant sûr de ne pas oublier une étape (cf make experiment sur le repository Git)
Passer d’une expérimentation à une autre
A ce stade vous avez toutes vos expérimentations associées à un tag. Vous pouvez voir vos tags avec un simple git tag. Pour revenir à une expérimentation spécifique, il vous faut d’abord retourner au tag souhaité avec Git : git checkout <tag_name>. Avec cela, Git vous a rapatrié les fichiers Python mais aussi les fichiers de métadonnées DVC. Ainsi, il n’y a plus qu’à rapatrier les données référencées par ces fichiers DVC. Pour cela, deux manières :
- Si vous avez déjà vos fichiers dans le cache DVC, dans ce cas un simple
dvc checkoutsuffira. - Si c’est une expérimentation d’un de vos collègues, alors il vous faudra récupérer les données de votre serveur. Pour cela, il faudra faire un
dvc pull, qui à la manière de Git récupérera les données (git fetch) et les mettra dans votre repository (git merge).
Normalement si votre tag pointe vers les données en accord avec vos sources (les fichiers Python), DVC devrait vous dire que votre pipeline is up to date. Cela signifie qu’aucune étape doit être ré-exécutée : les données sont en accord avec le code. Pour vérifier cela faites un dvc status, DVC vous montrera les dépendances qui ont changées et les étapes à ré-exécuter.
Il faut noter que même si le code est en dépendance de chaque étape, il n’est pas sauvegardé par DVC. En effet, DVC ne sauvegarde que les sorties de chaque étape, le code n’étant jamais une sortie d’une étape mais une dépendance. Ainsi pas de danger, votre code ne sera pas remplacé par DVC lors d’un checkout, seul Git gère ces fichiers si le pipeline est bien défini.
Ce point est le grand point fort de DVC. En arrivant sur un projet, il est possible en moins de deux commandes de revenir au stade d’une expérimentation. Vous pouvez tout de suite faire vos modifications à une étape et ré-exécuter le pipeline avec DVC. Ainsi vous ne perdrez plus de temps à retrouver les performances d’un de vos anciens modèles, ce qui peut représenter un gain de temps très important. Finalement, DVC vous garantit un point de sauvegarde reproductible.
Comparer les expérimentations avec des métriques
Afin de comparer les différentes tentatives, il est indispensable de sélectionner de bonnes métriques. A la fin de l’évaluation, nous vous conseillons d’écrire dans un fichier (.txt, .csv, .json, …) les différents scores obtenus et de définir ce fichier comme métrique lors de la définition de l’étape :
dvc run -f step.dvc \
-d input_folder \
-d script.py \
-m metrics_file \
python script.py
En ayant bien placé un tag par expérimentation, il est ainsi possible de facilement les comparer via la commande DVC : dvc metrics show -T

Figure 4 : Visualisation des expérimentations sans sélection
Plus il y a d’expérimentations, plus la visualisation des résultats est difficile. Pour remédier à cela, il est possible de sélectionner seulement les métriques que nous souhaitons comparer. Dans notre projet, nous avons sauvegardé le résultat des différentes expérimentations dans un fichier JSON et avons décidé de garder les métriques suivantes : RMSE (Root Mean Square Error), Explained Variance Score et le R2 score. Si seule la RMSE obtenue nous importe, il est possible de visualiser uniquement cette métrique pour toutes les expérimentations en exécutant : dvc metrics show -T --xpath rmse
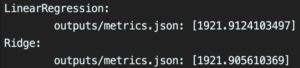
Figure 5 : Visualisation des expérimentations avec sélection
-T pour tous les tags --xpath (ou -x) pour sélectionner la métrique qui nous intéresse
Bien que cette fonctionnalité de sélection soit pratique, nous avons trouvé la comparaison entre les différentes expérimentations compliquée : les résultats s’affichent en fonction du nom du tag (tri alphabétique), et il est impossible de trier les tentatives réalisées en fonction de la valeur d’une métrique.
Conclusion
Dans le cadre d’un projet de Machine Learning, la reproductibilité est un élément-clé. Il est nécessaire de pouvoir expérimenter librement avec les données sans craindre de les perdre. DVC répond à cette problématique à travers les 3 points que nous avons cités : gestion du DAG, des données et des métriques. En fusionnant, ces fonctionnalités DVC permet de simplifier le workflow. Pour peu que vous ayez un cloud externe, le partage de votre projet sera grandement simplifié. Effectivement, il faut prendre du temps pour prendre en main l’outil et pour connaître toutes les options utiles des différentes commandes, mais la configuration est relativement rapide.
Est-ce que DVC va devenir l’outil de versioning de référence pour les projets de Machine Learning ? Il est encore trop tôt pour y répondre, même si certains indicateurs ne trompent pas :
- la fréquence des releases est élevée : hebdomadaire.
- la communauté ne cesse de grandir : 74 contributeurs, 3 550 étoiles Github.
Nous vous encourageons donc à essayer DVC, vous devriez pouvoir le prendre en main rapidement avec cet article. Vous avez à votre disposition un repository Git pour tester l’outil avec un DAG de base.