Microservices et transactions distribuées - Compte-rendu du talk de Julien Stainer et Bertrand le Foulgoc à La Duck Conf 2019
La révolution DevOps a introduit une gestion des applications au cycle de vie plus court (des mises en production plus fréquentes) et plus complexes (rollbacks, blue/green, canary deploy, A/B testing…). Elles sont aussi introduit une nouvelle tendance: les micro-services.
Dans ce nouveau monde, on cherche à séparer les responsabilités non plus par des critères techniques mais par des critères fonctionnels. Afin de rendre les mises en production indépendantes entre elles et ainsi autonomiser les équipe, on cherche aussi à réduire et isoler les développements.
Ce qu’il va se passer, ce sont des transactions qui vont se distribuer dans le SI à travers plusieurs briques, et pour cela il va falloir apprendre à résoudre de nouveaux problèmes : les transactions distribuées.
Les transactions distribuée: de nouveaux problèmes
On parle de transaction distribuée pour un évènement unique qui change deux sources de donnés différentes. Lorsque ces deux sources de données différentes ne peuvent pas communiquer (par exemple en cas de pannes), alors on perd l’atomicité. Autrement dit, avant il n’y avait pas d’état intermédiaire, maintenant ce sont des choses qui arrivent: le premier système peut avoir son état de changé alors que le second n’a pas encore reçu la mise à jour.
On parle donc de cohérence à terme par opposition à la cohérence immédiate auxquels les SGBD traditionnels nous ont habitués.
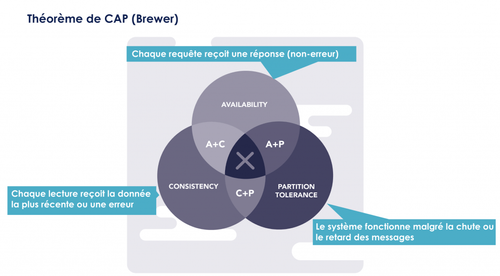
Le théorème CAP a prouvé qu’on devait à tout moment réfléchir en terme de compromis entre la disponibilité (puis-je répondre à la requête), la cohérence (ma requête aura-t-elle le même résultant dans tous mon système), et la tolérance au partionnement (est-ce que mon système supporte une déconnexion). Mais c’est un faux choix : en sacrifiant la tolérance au partionnement, le système ne tolèrera plus les pannes et donc sera indisponible. En réalité il s’agit de choisir entre disponibilité et cohérence à terme.
Un papier récent sur le théorème CALM essaie d’exprimer ces contraintes en terme de cohérence et monotonie logique, mais il s’est retrouvé décevant par rapport aux choix pratiques qu’il propose.
Comment construire sa tolérance aux fautes ?
Deux grands patterns existent: le pattern Chorégraphie et l’Orchestrateur.
La Chorégraphie consiste à repérer les les transactions dans le système et de chercher à définir des sous-transactions et des compensations en cas d’échec. En cas d’erreur, on dépile les transactions en appliquant la compensation, c’est une forme de rollback.
Dans ce cas il faut énumérer les erreurs possibles et demander au métier de définir ce qu’est la transaction pour pouvoir la compenser de manière correcte.
Ce pattern est naturel, et nécessite peu d’efforts pour être mis en place. Il profite aussi d’un faible couplage avec le reste du système.
Attention néanmoins: ce pattern ne scale pas. La difficulté de modélisation, compréhension, et design est exponentielle avec le nombre de composants avec lequel on interagit. Il ne permet pas non plus de résoudre les dépendances cycliques.
Entre le second pattern: l’Orchestrateur.
L’Orchestrateur va établir et suivre un journal de transactions. En cas d’erreur, il est capable de reprendre le journal et arriver à savoir quelle compensation jouer ou déjouer.
Certes, il introduit un léger délai qu’il va falloir compenser (attention au travail sensible à la performance), mais c‘est aussi ce qui permet de résoudre les dépendances cycliques, le rend plus facile à tester que le pattern Chorégraphie, et sa complexité est linéaire du nombre de composants.
Utiliser un Orchestrateur permet aussi à chaque composant d’être indépendant des équipes externes (modulo la complexité de l’outil).
Il faudra cependant être vigilant à ne pas en faire un ESB en y pensant la résistance aux fautes, en y mettant que le minimum de logique décentralisée, et en le gardant interne et privé à l’équipe (ne pas l’ouvrir au SI). L’Orchestrateur ne doit pas être trop intelligent.
Un autre point de vigilance: ce composant est un SPoF (Single Point of Failure) pour votre service. S’il tombe, vos transactions ne seront pas dépilées. Il va donc falloir penser tout particulièrement à la résilience de ce composant.
Alors, comment choisir ? Chorégraphie ou Orchestrateur ?
Préférez la Chorégraphie lorsque vous avez peu de composants dans vos transactions et l’Orchestrateur lorsqu’ils sont nombreux. La Chorégraphie est plus facile à raisonner et ne demande pas la mise en place d’un composant supplémentaire SPoF dans votre service.
Voir la présentation complète sur slideshare.
Comment tester ?
Les techniques de test pour les transactions distribuées ne sont pas encore nombreuses, et se séparent en deux parties: le chaos engineering et le test aux limites.
Le chaos engineering a l’avantage d’être relativement simple à mettre en place, mais les scénarios dans lesquels les erreurs surviennent sont nombreux: il va falloir trier, prioriser, et réfléchir !
Dans le cas des tests aux limites, on cherche à provoquer la défaillance exactement à l’endroit où on veut tester la contre-mesure qu’on cherche à mettre en place. À l’inverse du Chaos Engineering qui est aveugle, on cherche ici à maîtriser exactement les conditions de la défaillance. Pour cela il va falloir utiliser les debuggers, des scripts pour déclencher les events, et un moyen de créer et actionner des scénarios. Vous gagnez ainsi la possibilité de vérifier les comportements de vos composants dans des situations réalistes.
# Take aways
- Préférer le pattern Chorégraphie lorsqu’on a peu de services, et le pattern Orchestrateur lorsqu’ils sont nombreux
- La disponibilité est le produit des disponibilités des sous-services: si une API loin dans votre SI tombe, les services en bordure de SI qui en dépendent peuvent aussi tomber
- Les arrêts vont arriver. Il faut un design adéquat depuis le début et un bon monitoring
- Attention à l’over-engineering, c’est facile d’abandonner et le C et le A de CAP sans s’en rendre compte
- Implémentez des tests aux limites et réfléchissez aux scénarios