Memcached : une alternative aux caches classiques
Depuis l'émergence des infrastructures Cloud et la communication autour des architectures hautes disponibilités comme Amazon ou Google, difficile de passer à côté de solutions comme memcached : une solution Open Source permettant de stocker, en mémoire uniquement, de l’information.
Memcached : un cache mémoire distribué et non répliqué
Memcached est un cache objet distribué :
- il permet de stocker des objets sous la forme clé/valeur
- Ces objets peuvent être répartis (ie. distribués) sur un nombre variable d'instances, de serveurs. Ainsi chaque instance sera responsable d’un certain nombre de données
- ces données ne sont ni persistantes, ni répliquées entre les différentes instances. Formulé autrement, si une des instances tombent, les données qui étaient hébergées par cette instance sont perdues et le code applicatif devra à nouveau solliciter la source (la base de données par exemple…) pour récupérer les dernières valeurs.
Memcached se différencie de plus d’une solution de cache classique type ehcache dans sa mise en œuvre plus que dans ces APIs. Classiquement, une solution type ehcache est embarquée dans chacune des applications ; en quelque sorte, le cache est local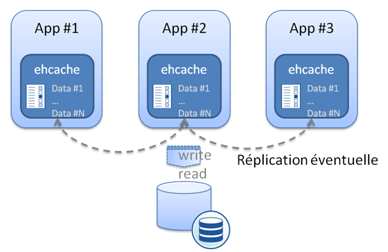
- Le nombre d’éléments qu’il est possible de stocker dans le cache. Si l’intégralité du cache est répliquée, l’ensemble des serveurs contient l’ensemble du cache en RAM. Peu gênant sur certaines applications, un peu plus impactant si l’infrastructure met en jeu un volume important de données ou un grand nombre de serveurs. C’est en quelque sorte un frein à la scalabilité horizontale puisque tous les serveurs atteindront la même limite de RAM et que le salut se trouvera, dans ce cas, dans l’ajout de ressources et dans la scalabilité verticale. Les différentes stratégies d’éviction des caches permettent certes d’optimiser l’utilisation que le cache fait de la mémoire (Memcached utilise LRU) mais ne permettent pas de dépasser la limite de stockage en mémoire.
- La volatilité des données mises en cache. Au plus les données seront volatiles, au plus la réplication est un problème car le temps nécessaire à la réplication (qui se fera en asynchrone et en background) amènera des problèmes de fraicheur de la donnée. Pousser à l’extrême, cette solution peut amener à des cas où les applicatifs passeront plus de temps à remplacer et à répliquer la donnée dans les caches qu’à l’utiliser
Memcached propose lui une approche différente où chacune des applications utilise et se connecte (via tcp très souvent) à des serveurs de cache qui conservent les données en mémoire ; en quelque sorte un cache « remote ».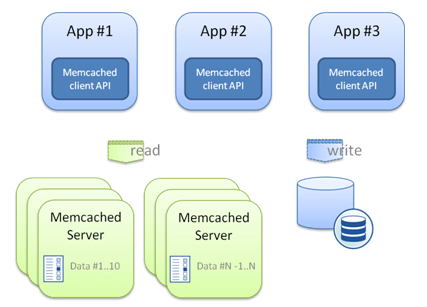
- chacune des instances a la responsabilité d’un espace de données particulier. Il ne s’agit en revanche pas de partitionner fonctionnellement les données (par exemple, les clients sont stockés sur ce serveur, les contrats sur tel autre serveur…) mais plutôt de répartir techniquement (selon les clés) les données. Ainsi les données de 1-10 seront sur le premier serveur, les données de 11 à 20 sur le second serveur et ainsi de suite…En bref, il s’agit de répondre à la question : comment répartir les objets uniformément entre les différentes instances ?
- Pour répondre à des évolutions de volumétrie (ponctuelles ou régulières) memcached permet de rajouter, ou d’enlever dynamiquement des instances. Cette problématique n’est pas simple à adresser et consiste à répondre à la question suivante : comment faire pour que cette répartition ne soit pas trop sensible à l’ajout ou à la suppression dynamique d’instances ?
Memcached et la « sécurité » ?
Par défaut, memcached ne propose aucune fonctionnalité autour de la sécurité. Ainsi,
- il n’existe pas de mécanismes d’authentification. Limiter les accès extérieurs doit donc se faire, si nécessaire, au niveau réseau (Firewall + filtrage IP)
- les données ne sont pas encryptées. Est-ce nécessaire ou pas de les crypter est un débat à part entière dans lequel je ferai bien attention de ne pas me lancer. Reste que memcached ne fait rien à ce niveau et que c’est donc à la charge des applicatifs clients.
Pour conclure…
Memcached est un cache distribué et ne prétend pas rendre d’autres services. Dès lors il existe des limitations. On peut par exemple reprocher l’absence de persistance ou même plus simplement de réplication des données entre les instances (pour augmenter la résilience du cache). Il est possible d’enrichir (en fait d’autres l’ont déjà fait ;)) memcached pour rajouter:
- La réplication de données avec la solution http://repcached.lab.klab.org/
- La persistance, la réplication et la gestion des transactions avec http://memcachedb.org/. qui agrège memcached pour l’aspect distribution et performance, et berkeleyDB pour la persistance.
Mais ajouter ces fonctionnalités transforment un « simple » cache en un espace de stockage distribué type Google Big Table ou Amazon Dynamo (un sujet fantastique dont nous aurons peut-être l’occasion de reparler…).
Ensuite, au niveau « exploitation », il n’existe pas d’administration centralisée et il est nécessaire de gérer unitairement les instances, les statistiques d’utilisation…
Enfin, au niveau développement, il existe quelques limitations sur la longueur des clés, la taille des objets qu’il est possible de stocker ou même les APIs (pas de recherche possible, pas de possibilité d’itération…)
Mais au-delà de l’aspect scalabilité, le caractère distribué de memcached ouvre la porte à différents cas d’usage. La plus classique reste certes celle d’un cache et vise à soulager la base de données en récupérant les informations dans la ou les instances memcached plutôt qu’en interrogeant la base de données (à ce titre, il faut noter l’initiative hibernate-memcached). Un autre cas d’usage consiste à l’utiliser pour conserver un état. Google l’utilise comme un moyen performant d'implémenter la notion de Session HTTP du container web. D’autres l’utilisent pour conserver d’autres formes d’information comme les clients en ligne, leur nombre…D’autres enfin l'utilisent comme un moyen simple et performant de partager de la donnée entre plusieurs processus, entre plusieurs applications.
Reste alors deux questions :
- Quid du positionnement de ces solutions au regard d’alternatives commerciales comme Gigaspaces ou Coherence. Un exercice délicat que d’essayer de les positionner en quelques lignes mais ces approches sont en quelque sorte à mi-chemin entre une réplication de cache et un memcached. Vu de très haut, Coherence stocke la donnée dans la JVM (locale ou distante) met en œuvre des mécanismes de partitionnement et de réplication (et est plus résilient à la panne). Le cache distribué de Gigaspaces va plus loin en proposant globalement une vision mémoire de la base de données (et donc des langages de requêtages…). Reste que comme le souligne nos amis de Xebia, il y a un curseur à trouver entre solutions artisanales demandant des compétences en interne et solutions industrielles plus coûteuses (a minima en terme licences)
- Pourquoi des solutions type memcached ont trouvé une place de choix dans les architectures des grands du web et pas dans nos architectures ? Difficile de connaitre la vérité mais les deux éléments suivants fournissent, à mon sens, un premier niveau de réponse. Tout d’abord, la volonté farouche qu’ont des acteurs comme Amazon ou Google de conservé la maitrise et de ne pas s’en remettre à un éditeur. Et il y a fort à parier que là dessus, l’investissement sur les hommes, leurs compétences est sans commune mesure. Ensuite, l’optimisation des coûts (infrastructure, licences…) : La Scalabilité n’est pas simplement la capacité qu’à une architecture à absorber une augmentation du volume. C’est la capacité qu’à une architecture à absorber une augmentation des volumétries (ie. augmenter son throughput) à performance (ie. trés souvent assimilable au temps de réponse) constante tout en recherchant l’optimisation des coûts
.