Melhorando o Desempenho dos Jobs Hadoop no HDInsight
H
Importante esclarecer que este artigo não se trata especificamente de uma comparação de desempenho e sim de uma experiência empírica, deliberadamente subjetiva, explicando a minha visão e as soluções que encontrei para otimizar o desempenho dos Jobs na plataforma BigData da Microsoft.
Meu caso de uso é simples: uma POC com um cluster Hadoop instanciado no Azure, consistindo basicamente em filtrar informações de uma base de informações com um volume estimado em 1.3 TB ao ano.
Se você ainda não está familiarizado com o ecossistema de processamento paralelizado Hadoop, mas quer saber mais sobre o assunto, basta escolher a pílula vermelha, mas eu devo te advertir: esse é um caminho sem volta...

Voltando a POC, meu cluster é composto de 4 nós, totalizando 24 núcleos e 24 GB de RAM. Meus dados estão sendo recuperados da Wikipédia: Page view statistics for Wikimedia projects. Mais especificamente, o cluster contém 1,3 TB de dados correspondentes a 2014. Eu coloquei todos esses dados em um armazenamento Azure Cloud chamado Azure Storage Vault (ASV). Este armazenamento é «ligado» em um cluster Hadoop.
A versão HDInsight usado para esta POC é 3.0 que integra Hadoop 2.2. Aqui está a documentação das versões no HDInsight.
Dois pontos a se destacar:
- O uso da ASV como sistema distribuído em vez de HDFS me permite enviar dados para este sistema de arquivos distribuído mesmo sem um cluster Hadoop instanciado. Isso me permitiu fazer uma grande economia de dinheiro.
- É possível visualizar os resultados dos meus Jobs Hadoop de outra maneira do além dos comandos "fs hadoop" ou via interface WebHDFS. Para isso existe uma API de acesso a ASV em diversas linguagens e plataformas (Java, .Net, JavaScript, PHP, Python, etc.), bem como navegadores de arquivos. Aqui está um que eu recomendo: CloudXplorer
Pensando em Desempenho quando os dados atravessam a rede
O princípio básico do paradigma Map Reduce é a co-localização dos dados binários. Passando por dados na nuvem, como a plataforma não está fisicamente presente nos nós (se estiver usando ASV em vez de HDFS, que é o padrão), mas em um sistema de arquivos externo. Dessa forma, nós perdemos o benefício de mover o código para os dados e não o inverso (Moving data to compute or compute to data? That is the Big Data question).
Mas a Microsoft teve uma iniciativa para rearquiteturar O Azure ASV há dois anos antecipando a chegada do serviço HDInsight.
No diagrama, O HDInsight está localizado nos «nós computacionais» enquanto os dados estão localizados na ASV Blobs como explicado Denny Lee no seu post Why use Blob Storage with HDInsight on Azure.
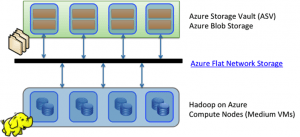
O Azure implantou um sistema chamado Azure Flat Network Storage (ou Q10) em 2012 para propiciar alta disponibilidade dos dados. O resultado é um desempenho «semelhante» ao HDFS (isto é: 800 MB/s) sendo mais rápido para a escrita. Quando um novo arquivo é inserido no HDFS, ele é enviado ao primeiro nó, em seguida, se replica três vezes (por padrão). O ASV também replica três vezes os dados no datacenter local, a diferença é que ele trabalha com a replicação de forma assíncrona. Isso explica a "reatividade" de escrever sobre ASV (na verdade escrita física é mais rápida). Em seu estado da arte de armazenamento em nuvem, a empresa explica que o sistema Q10 Nasuni escolhido pela Microsoft é de 56% mais rápido em gravação e 39% em leitura de acordo com seus benchmarks.
Qual é o Job?
Com os registros da wikmedia recuperados, temos um arquivo de texto de aproximadamente 400MB por hora no dia. Este arquivo contém o nome das páginas da Wikipédia, o idioma dessas páginas e o número de visitas a essas páginas. Uma linha de exemplo:
br Protestos_antigovernamentais_no_Brasil_em_2015 1032585
O nome do arquivo contém a data e a hora a que se refere.
Exemplo: pagecount-20150623-1800000.txt => 18H, 23 de junho de 2015
O algoritmo
Meu programa tem três filtros:
- Filtrar por idioma de interesse (afinal, eu ainda não sei ler mandarim)
- Filtrar por data e, assim, restringir a análise a um dia, um mês ou um ano.
- Filtrar alguns nomes de página Wikipédia desinteressante no nosso caso. Por exemplo: índice, casa, indefinido.
Dois GroupBy:
- Agrupar itens por nome da página, para o número total de visitas por página.
- O agrupamento por idioma, para o top 10 de cada língua.
A OrderBy Desc:
- Classificar itens na ordem do número total de visitas para cada idioma de forma decrescente.
A Top:
- Limitar o resultado que parece ser essencial para um dia, sabendo que o número de registos é igual a 180 milhões.
O script PIG:
REGISTER wikipedia.jar;
DEFINE CustomInput wikipedia.pig.FileNameTextLoadFunc('20140605');
DEFINE SIM wikipedia.pig.SimilarityFunc();
records = LOAD $in USING CustomInput AS (filename: chararray, lang: chararray, page: chararray, visit: long);
filterbylang = FILTER records BY lang == 'fr' OR lang == 'en' OR lang == 'de';
restrictions = LOAD $restrictionFile USING TextLoader() AS (page: chararray);
joinbypage = JOIN filterbylang BY page LEFT OUTER, restrictions BY page USING 'replicated';
deleteRestrictedWords = FILTER joinbypage BY SIM(filterbylang::page, restrictions::page) == false;
groupbypage = COGROUP deleteRestrictedWords BY (filterbylang::page, filterbylang::lang);
sumrecords = FOREACH groupbypage GENERATE group.lang, group.page, SUM(deleteRestrictedWords.filterbylang::visit) AS visit_sum;
groupbylang = GROUP sumrecords BY lang;
top20 = FOREACH groupbylang {
sorted = ORDER sumrecords BY visit_sum DESC;
top = LIMIT sorted 20;
GENERATE group, flatten(top1);
};
store top20 into $out;
O CustomInput é uma UDF (Função Definida pelo Usuário) do Tipo Load que eu implementei para analisar o nome do arquivo de log e recuperar a data. Além disso, nesse CustomInput eu coloquei uma InputPathFilter para filtrar desde o início uma janela de tempo especifica (um dia, uma semana, um mês, etc.). Evitando assim a recuperação de todos os dados de forma única (ou seja, muito menos rede de trânsito).
A função SIM é um tipo de UDF Eval (usado para filtrar registros que não queremos no resultado final). Ele testa a semelhança entre expressões. Há um pouco de cálculo nesse processo.
Lançamento do script no cluster
Eu executei o script PIG direcionado para um dia, o que corresponde a aproximadamente 8,5 GB de dados. E então era só esperar... eu esperei ainda mais para obter um ótimo resultado do Job PIG... cerca de 45 minutos !!

Recuperando os logs do console do PIG para análise, obtive belos gráficos!
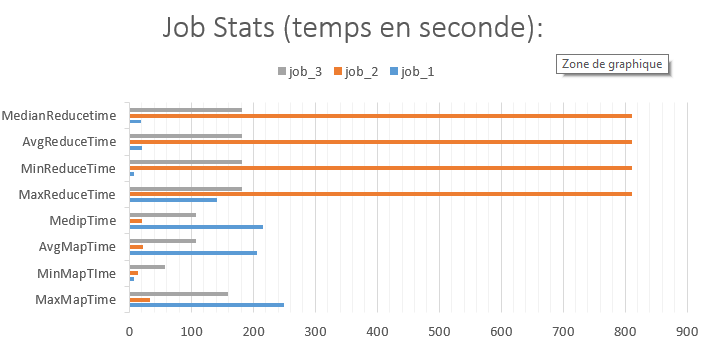
O PIG criou três Jobs Map Reduce:
- 1^º ^ Job: filtrar por idioma, é a junção entre os registros e restrições, filtra páginas válidas;
- 2 ^ º^ Job: opera o agrupamento de páginas com o mesmo nome e totaliza visitas;
- 3 ^ º^Job: inclui páginas para cada idioma e cada língua com limite para 20 páginas;
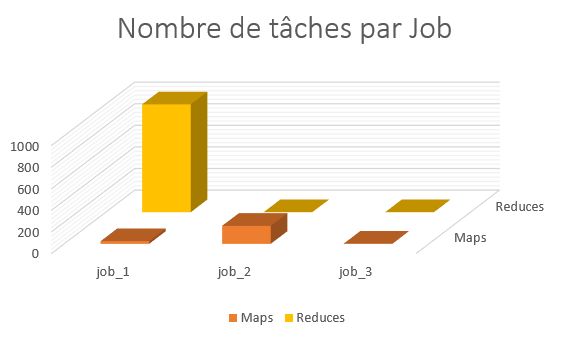
A partir do gráfico acima percebi que o Pig cria um número considerável de reducers nas tarefas do primeiro Job (999!). Na verdade, o PIG realiza um tipo de associação « Reduce side » entre os dois conjuntos de dados (aquele com os logs Wikipédia e aquele com as restrições, muito menor). O cluster tem 4 nós, com 22 containers. O PIG é inteligente o suficiente para setar os redutores ao máximo possível. Portanto, as 999 tarefas são processadas pelos 22 containers. Fazendo a média do tempo das tarefas para JOB_1 (no gráfico do Job_Stats), que é de 20 segundos:
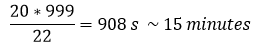
Portanto, encontrei o meu "gargalo". Diante disso, eu decidi abandonar o script PIG, eu fiz a escolha de não o otimizar (o que seria possível) para obter melhores resultados, e no lugar disso, preferi fazer meu próprio MapReduce e excluir esses 999 redutores.
Voltando à estaca zero
Escrevendo o meu próprio código Java "do zero", consegui produzir rigorosamente o mesmo resultado para comparar, e é aqui que a coisa fica interessante. Para os mais curiosos, esse é o link do código no Github (Você pode recuperar no repositório o script PIG e os dois UDFs que são utilizados neste script).
Primeira otimização: mudando para um código MapReduce
Em conformidade com o artigo do Ilya Katsov, MapReduce Patterns, Algorithms, and Use Cases (Eu recomendo essa leitura), eu escolhi uma mistura de tipos de algoritmos de filtragem, GroupBy e Agregação .
Aqui estão alguns pontos na escolha:
- Colocar restrições no cache local com método job.addCacheFile () para filtrar as tarefas no mapa diretamente(Join Map Side).
- Filtrar os idiomas com o mesmo método que para as restrições.
- A saída do mapper chave é o idioma. Os registros serão destinados para a chamada de cada língua HashPartitioner em reducers (durante o shuffle). Um redutor será encarregado de tratar um idioma.
- O valor do mapper de saída é um objeto que contém o nome da página e o número de visitas aos atributos.
- O reducer é um top 10 registros por idioma que ele possui.
Lancei sucessivamente 5 vezes o mesmo Job durante a medição do tempo de execução e, em seguida, analisei o tempo de execução média.
Indo direto ao ponto, o mínimo que posso dizer é que o tempo poupado foi considerável.
| Jó (no dia 1) | tempo (s) de execução |
| Job 1 | 402 |
| Job 2 | 385 |
| Job 3 | 406 |
| Job 4 | 393 |
| Job 5 | 383 |
| Média (min) | 6,5 |
BOOM! Este Job apresenta uma média de 6 minutos e 30 segundos para processar o que o PIG fez em 45 minutos (quase 7X mais rápido). O ganho é óbvio, mas eu ainda não estava satisfeito. Então, eu abri o dashboard monitorização Web do HDInsight, chamado de Hadoop Yarn Status.
Segunda otimização: Utilizando um Combiner
Eu selecionei um dos cinco Jobs (o Job foi iniciado 5 vezes) na seção "Aplicativos", e então eu clique em Tracking Url.
No resumo da Job, acessando Counters podemos ver:
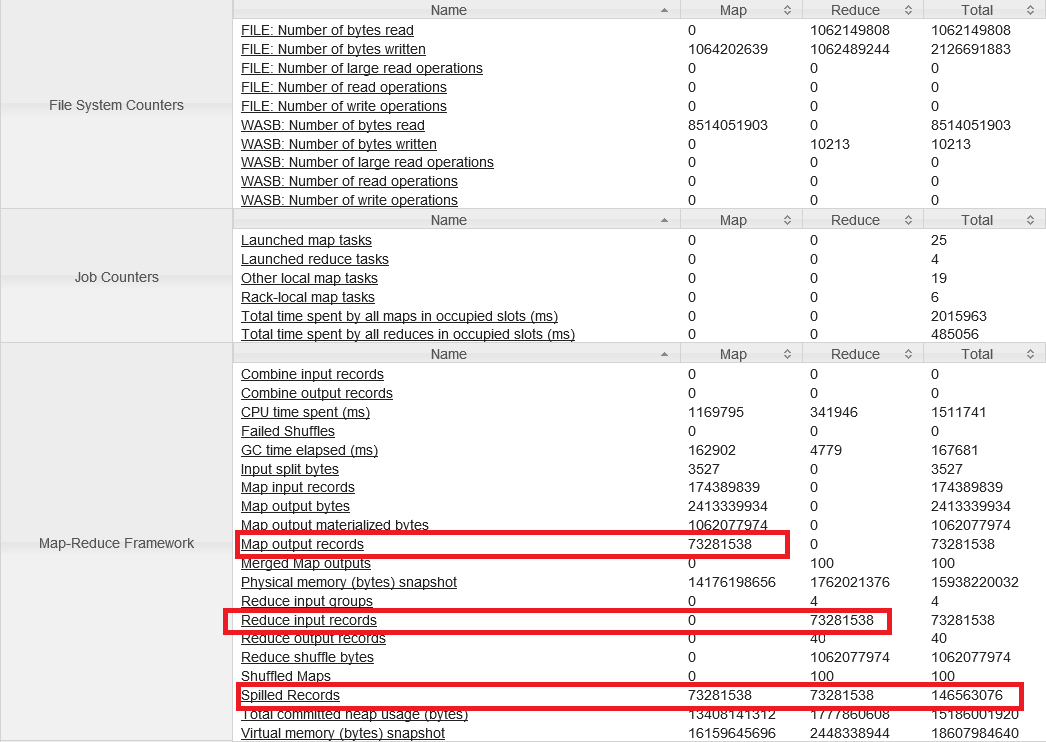
O cluster tem 4 máquinas e 24 núcleos, fazendo 23 « task containers » (24-1). Meu Job analisou 4 idiomas, por isso eu mudei o número de reducers para 4. Portanto, há apenas 19 containers para os mappers.
Os Mappers podem absorver uma grande quantidade de dados, enquanto os reducers devem receber 2,5 vezes menos dados afinal em termos de quantidade eles são 5 vezes menores. A fase de map recupera 174 milhões de registros e filtra 73 milhões de registros válidos para os reducers. Existe, portanto, um fator de 2,4 que diminui os registos de volume. Há, além disso, que 73 milhões de registros que são "Spilled", no map ou no Reduce. Isso equivale a um total de 146 milhões de registros gravados no disco (o “Spilles” é o momento em que o ContextBuffer está sobrecarregado e os dados são liberado para o disco para poder continuar).
De acordo com o Hadoop Definitive Guide: Third Edition, usar um “combiner” seria uma solução para minimizar o número de registros que passam durante a fase de Shuffle & Sort para os reducers. A segunda solução seria fazer um top 10 intermediário nos dados, e escrever apenas no contexto dos 25 top10 = 250 registros (uma vez que existem 25 divisões por um dia, por isso mappers com 25).
Eu optei pela primeira solução, com um Combine na classe Reducer que eu escrevi. Isso me poupa o tempo de implementar a lógica adicional no Mapper, além disso, isso não seria o papel de um mapper!
Os resultados ainda estão melhorando, alcancei a faixa abaixo de 4 minutos para processar um dia.
| Jó (no dia 1) | tempo (s) de execução |
| Job 1 | 205 |
| Job 2 | 201 |
| Job 3 | 198 |
| Job 4 | 195 |
| Job 5 | 197 |
| Média (min) | 3,32 |
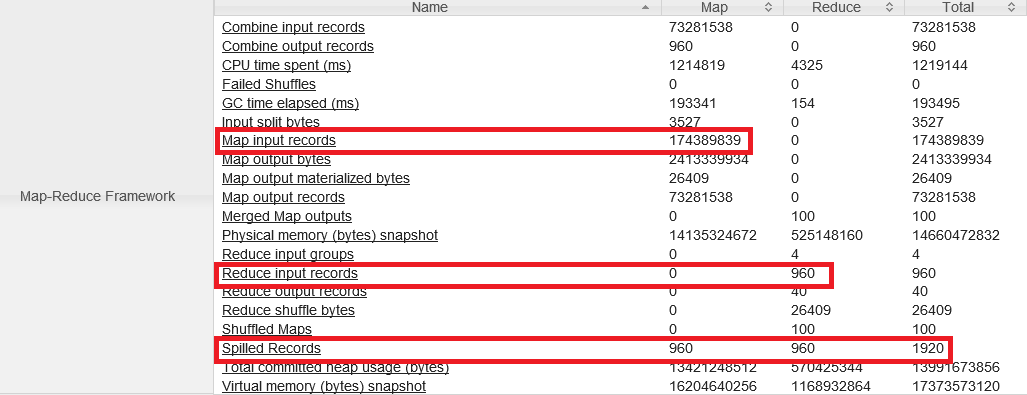
Repare que o número de registros nos últimos Reducers foi realmente reduzida, assim como o número de registros Spilles.
Terceira Otimização: mais containers para as tarefas de map
Com o uso do combine, minha estratégia requer poucos recursos para o reduce. A maioria dos tratamentos são feitos pelo map, o algoritmo é mais eficiente porque se tornou melhor paralelizável. No entanto, quando eu vi o painel de execução dos Jobs, notei que nem todos os recursos eram usados. Na verdade, em vez de 22 mappers para preencher a capacidade máxima do cluster, eu tinha 18.
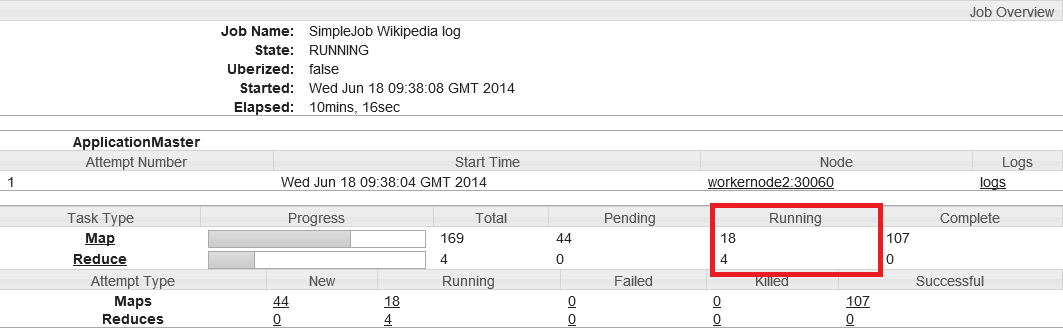
Na verdade, o Hadoop reserva os containers para as tarefas de reduce no fim do primeiro map de modo a que os reducers podem começar a baixar os registros e “mesclar” enquanto outros mappers ainda terminam seu trabalho. É pouco interessante em nível de desempenho quando há muitos registros na saída dos mappers para serem transferidos pela rede para os reducers e há muitas divisões para completar os cálculos em uma única passagem.
Aviso: é preciso distinguir duas coisas quando se fala de reducers. Como explicado Ed Mazure na sua resposta no grokbase, a fase de redução consiste em três partes.
- Recuperando registros na saída mapa (de 0 a 33%)
- Mesclar registros com a mesma chave (33 a 67%)
- Aplicação do método de "reduzir" sobrecarregados pelo utilizador (de 67 a 100%)
Uma vez que existiam poucos registros fora dos mappers com combine, então eu achei melhor usar o máximo de containers para a fase de map ao invés de usar os containers apenas para os reducers.
Duas propriedades na configuração do cluster foram úteis para mim:
- jobtracker.maxtasks.perjob=> esta propriedade pode ser definida como -1 para indicar que o cluster terá muitos containers disponíveis para a fase de map.
- job.reduce.slowstart.completedmaps=> essa propriedade é usada para especificar a porcentagem (entre 0 e 1) a conclusão de mappers da qual os reducers são instanciados e começam a recuperar os registros.
Eu alterei o valor de mapreduce.job.reduce.slowstart.completedmaps a 1.0 (valor padrão é 0,05), de modo que os reducers só iniciam uma vez todas os map Jobs foram concluídas.
Testando novamente:
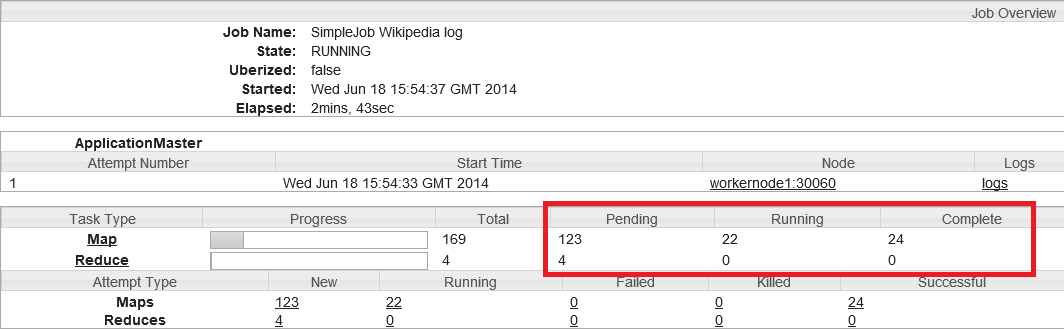
Podemos ver na coluna complete 24 tarefas map processadas (mais de 5%), assim o cluster reserva containers para as 22 tarefas de map. Com isso consegui um tempo abaixo dos 3 minutos por dia... mas ainda dá pra melhorar!
| emprego | tempo (s) de execução |
| Job 1 | 183 |
| Job 2 | 168 |
| Job 3 | 172 |
| Job 4 | 170 |
| Job 5 | 164 |
| Média (min) | 2,856666667 |
Quarta otimização: o tamanho de um Split
O Azure streamer leva aos dados do nosso ASV aos DataNodes, embora Q10 tenha bons resultados, isto pode ser uma desvantagem para o desempenho. De fato, o conceito de blocos de dados no HDFS é a base da distribuição de cálculo nos nós. Os dados são divididos em “splits”, tendo em conta os blocos nos quais os dados são distribuídos. Seria melhor, salvar os dados com um tamanho de bloco específico para antecipar o tratamento. Um nó local processaria o bloco, a partir do momento que ele identifica o tamanho especificado.
Com o ASV, eu estou supondo que de alguma forma meus nós terão que baixar os dados onde quer que estejam: a co-localização do código e os dados não é mais necessária. Portanto, usando um TextInputFormat 25 splits são gerados, para cada dia 25 arquivos.
Com a quantidade de splits semelhante a quantidade de mappers, os tratamentos serão realizados em uma única onda. Para isso, basta direcionar o número total de bytes na entrada do Job, então dividi-lo por 22 containers (ou um múltiplo do número de possíveis containers).
A vantagem obtida: todos os grupos serão tratados de uma só vez, evitando o comportamento padrão: os primeiros 22 splits são tratados na primeira onda, em seguida, 3 divisões são processadas no segundo turno, com 19 containers não utilizados. Isto indicou a seguinte captura:
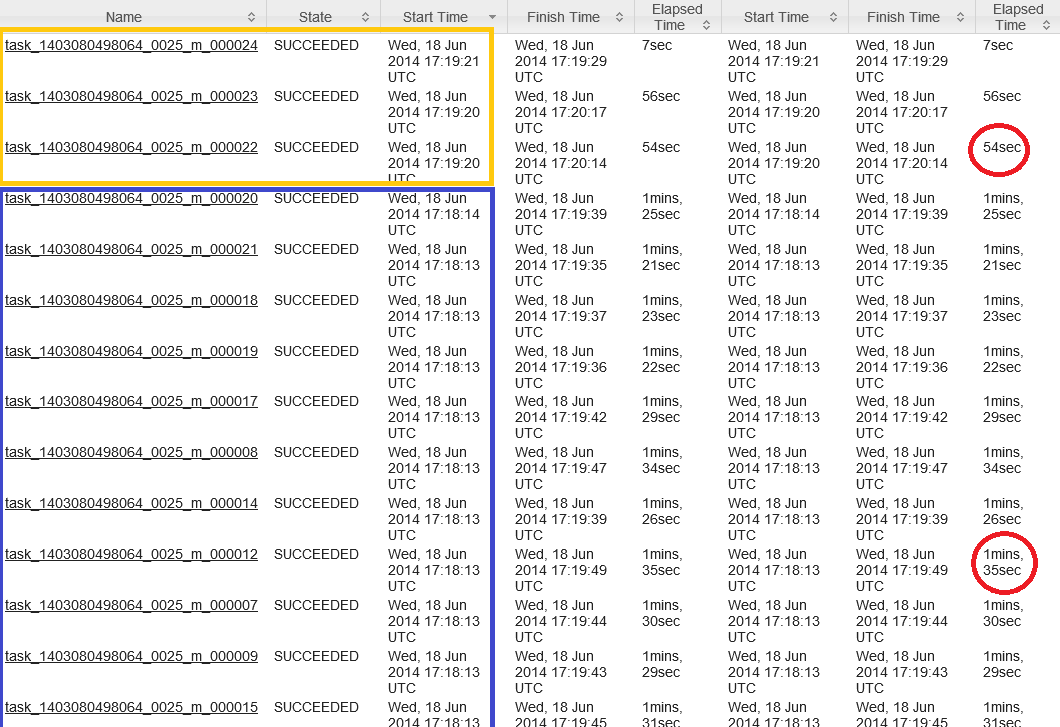
O tempo total de execução de tarefas map é equivalente à mais longa tarefa da primeira onda adicionado à tarefa mais longa na segunda onda (em laranja):
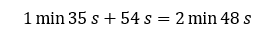
Lamentavelmente, ter apenas uma onda, gasta-se um pouco mais (2 minutos). Para lidar com esse detalhe, usei um InputFormat especial: CombineTextInputFormat. Ele permite que você mescle vários arquivos de entrada, sendo especialmente usado para jobs com muitos arquivos pequenos, para evitar a sobrecarga de um novo corpo para mapper.
Eu utilizei esse recurso apenas para especificar o tamanho da divisão, afinal é ele quem vai cuidar de agregar os arquivos e cortá-los na divisão dada. Então os mappers « streameront » utilizam diretamente o número de bytes equivalentes a 1/22 do tamanho global necessário.
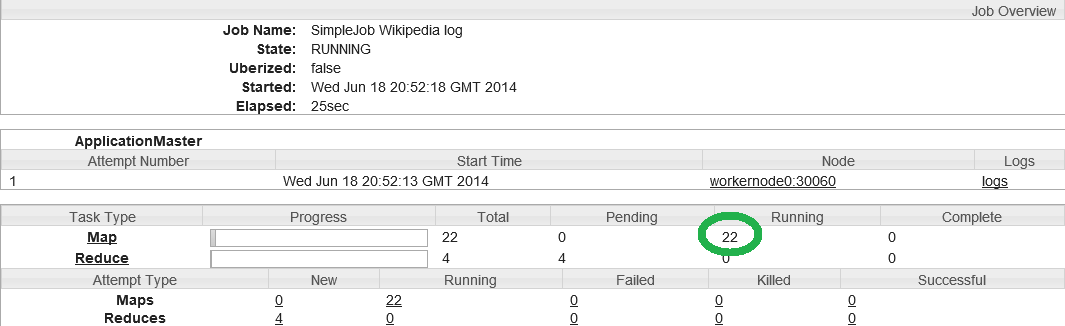
E os resultados:
| Jó (no dia 1) | tempo (s) de execução |
| Job 1 | 162 |
| Job 2 | 161 |
| Job 3 | 171 |
| Job 4 | 159 |
| Job 5 | 157 |
| Média (min) | 2,7 |
Fazendo um gráfico com a curva de evolução percebemos a progressão da performance:
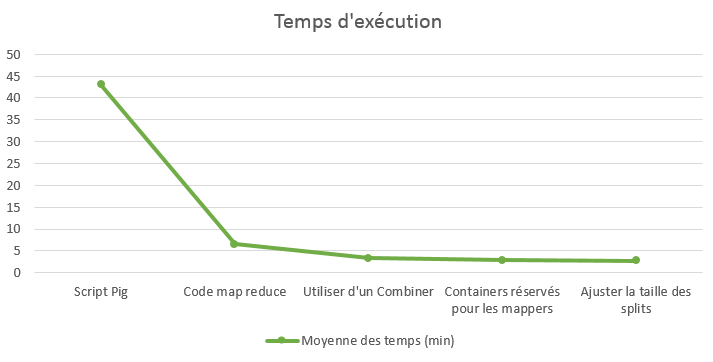
Ganhando 10% sobre um Job que dura 3 minutos não é muito representativo, mas na escala de um dia, representaria duas horas e meia.
Pode ser interessante para tirar alguns por centos quando você tem muitos Jobs em paralelo com um alto uso do cluster. As otimizações permitem acompanhar a evolução de performance da aplicação, e fazendo a comparação em uma semana:
- Com a utilização de apenas um Combinar: 16 minutos e 45 segundos em média
- Com ajuste do tamanho da separação: 12 minutos 28 segundos em média
Chegamos ao fim
Eu acredito que meu algoritmo está suficientemente otimizado para o seguinte passo: processar o ano inteiro. A análise poderia ser iniciada com 220 mappers para processar 1.3TB, que (teoricamente) lançaria sucessivamente 10 ondas de mappers. Com essa prerrogativa, o trabalho seria executado em 3:00.
Indo além, eu poderia trabalhar no equilíbrio dos mappers, então tudo se moveria na mesma velocidade que eles (há alguns que levam 10 minutos a menos do que outros). Pode ser mais apropriado para cortar o número de separações por registos em vez de número de bytes, esta técnica iria, por conseguinte, ter em conta o efeito dos arquivos. Mas isso é assunto para outro artigo. =)
Lições aprendidas:
- O desempenho de estratégias de paralelização depende muito da infraestrutura em que eles ocorrem. No nosso caso, fizemos ajustes para adaptar o código para a infraestrutura.
- A eficácia de um algoritmo MapReduce está na capacidade de colocar o máximo de cálculos e processamento nos mappers.
- Mesmo que o trabalho é executado rapidamente, explore sempre dashboard de métricas do Hadoop para descobrir as condições possivelmente mascarados antes de se mudar a escala.
- Sem medidas, otimizações são inúteis! Eu não contei aqui, mas este é o primeiro erro que cometi: tentar otimizar o código quando o problema estava em outro lugar.
Com todas essas dicas, mais as referências abaixo, você será invencível!

Referências:
- Arquivo de configuração MapReduce mapreduce-default.xml;
- MapReduce Patterns, Algorithms, and Use Cases e Highly Scalable Blog;
- 10 MapReduce Tips no blog Cloudera;
- 12 keys to keep your Hadoop Cluster running strong and performing optimum, d’Avkash Chauhan;
- Hadoop Performance Tuning ;
- Why use Blob Storage with HDInsight on Azure de Brad Sarsfield e Denny Lee;
- The State of Cloud Storage de Nasuni ;
- Tuning Hadoop on Dell PowerEdge Servers por Donald Russell ;
- My recent experience with Hadoop ;
- http://www.youtube.com/watch?v=fXW02XmBGQw