Liveness et readiness probes: Mettez de l'intelligence dans vos clusters
Au cours du temps, la philosophie autour du traitement des serveurs par les administrateurs système a évolué. Au commencement, chaque serveur était choyé et chouchouté individuellement : petit nom, réparation et mise à jour individuelle en cas de dysfonctionnement. Il s’agit de l’approche Pet (animal de compagnie en anglais). Cependant, cette approche a ses limites car la charge de travail (humaine) pour gérer chaque machine en limite le nombre.
Cependant, avec l’arrivée des services IaaS et du cloud, les moeurs ont changé. De plus en plus d’administrateurs ont délaissé l’approche Pet pour une approche plus industrielle : l’approche Cattle. Cette dernière consiste à créer un grand nombre d’instances virtuelles du serveur permettant au système répartir la charge accumulée au travers de loadbalancer. Si une machine a un problème, les mécanismes vérifiant son bon fonctionnement vont être activés et l’instance va être abattue puis recréée. Ces mécanismes, appelés health check, utilisent des probes (sondes). Pour plus d’information, je vous invite à jeter un oeil à l’article “Pet vs Cattle”.
Il était une fois... les probes
Le travail d’une probe est très simple. Elle va être envoyée depuis un service gérant le bon fonctionnement des instances, le service de health check, afin d’effectuer une action spécifique et renvoyer un résultat permettant d’identifier si l’instance est en bonne santé. Cela peut aller d’un simple ping à la vérification du résultat d’une requête.
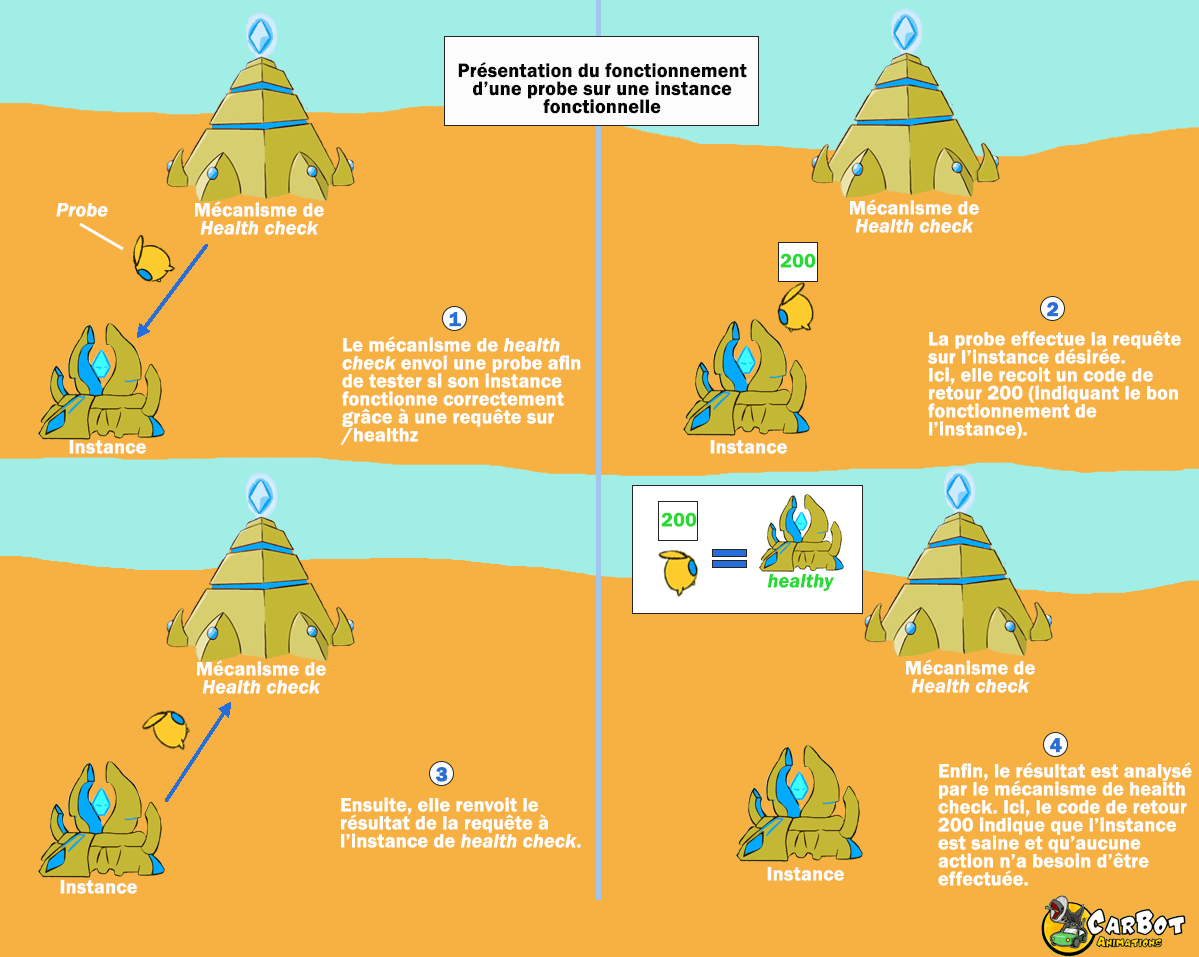
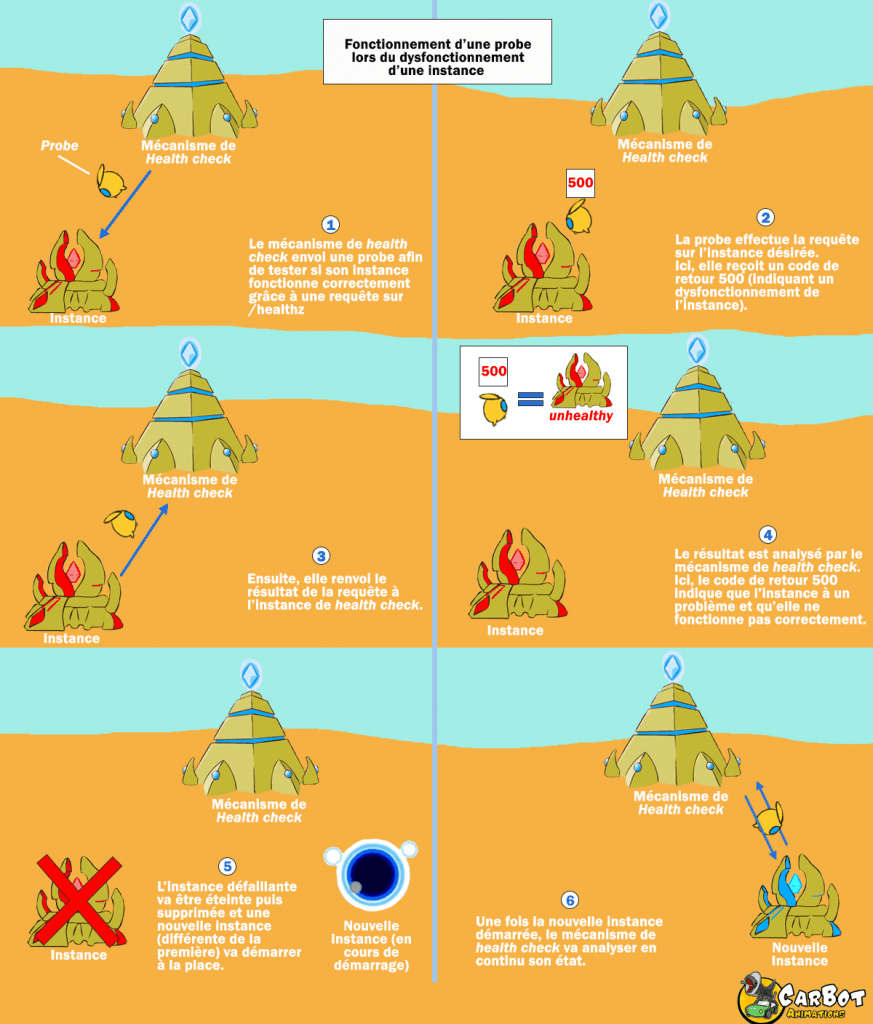
Si une instance a un problème et que la probe ne revient pas ou affiche un résultat incorrect, le système de healthcheck va alors détruire l’instance puis va en faire apparaître une nouvelle.
L'évolution d'un concept
Ce système “marche ou meurt” a cependant évolué au cours de ces dernières années. Il existe désormais deux types de probes : les probes liveness et les probes readiness.
La probe liveness
Cette probe a une approche très proche des anciennes probes. Si le pod (c.a.d un groupe de conteneur disposant d’un réseau et d’un stockage partagé) ne répond pas correctement à la requête envoyée, il est considéré comme corrompu et est instantanément redémarré.
On peut simuler le fonctionnement de la liveness probe de manière très simple. Pour cela, on va créer une probe qui va interroger toutes les trois secondes une URL (ici /healthz) et s’assurer qu’elle retourne le code HTTP 200.
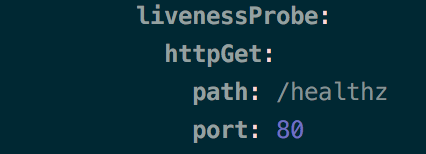
YAML qui représente une probe qui effectue un check à l’adresse /healthz sur le port 80 déployé sur un cluster Kubernetes
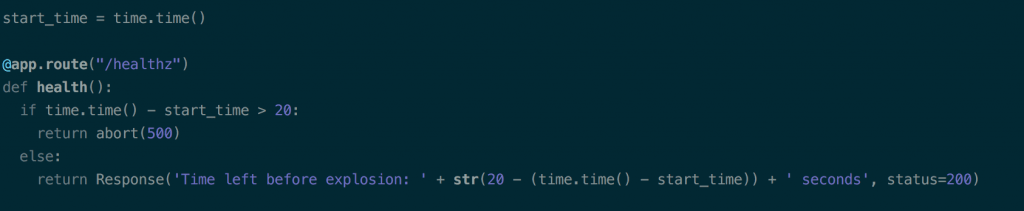
Le site sur lequel est effectué le test a été codé de sorte que l’adresse /healthz (adresse défini dans l’application) renvoie le code HTTP 500 vingt secondes après avoir reçu la requête.
En déployant un pod dans Kubernetes avec ce code, on peut voir qu’il redémarre (comme espéré) toutes les vingts secondes car le Kubernetes Controller Manager estime que le pod en question est défaillant.


On voit ici que les pods ont redémarré car le système a jugé les pods défaillants.
La probe readiness
Cette probe, elle, a une approche plus exotique. Si le pod répond mal, il est alors détaché temporairement du service (il est sorti du loadbalancer) jusqu’à ce que celui-ci soit de nouveau opérationnel. Cela permet d’éviter que le pod soit redémarré et qu’il perde ainsi les traitements en cours d’exécution.
Pour tester le comportement de cette probe, on peut imaginer un système de buffer. On donne un nombre de tâches au pod qui va ensuite renvoyer un code de retour 500 à une adresse spécifique quand il aura atteint un nombre de requête défini. Une fois ce nombre atteint, il va se remettre dans l’état normal au bout de vingt secondes (simulant le temps de traitement que pourrait prendre le traitement de l’information) et renvoyer correctement des codes de retour 200.
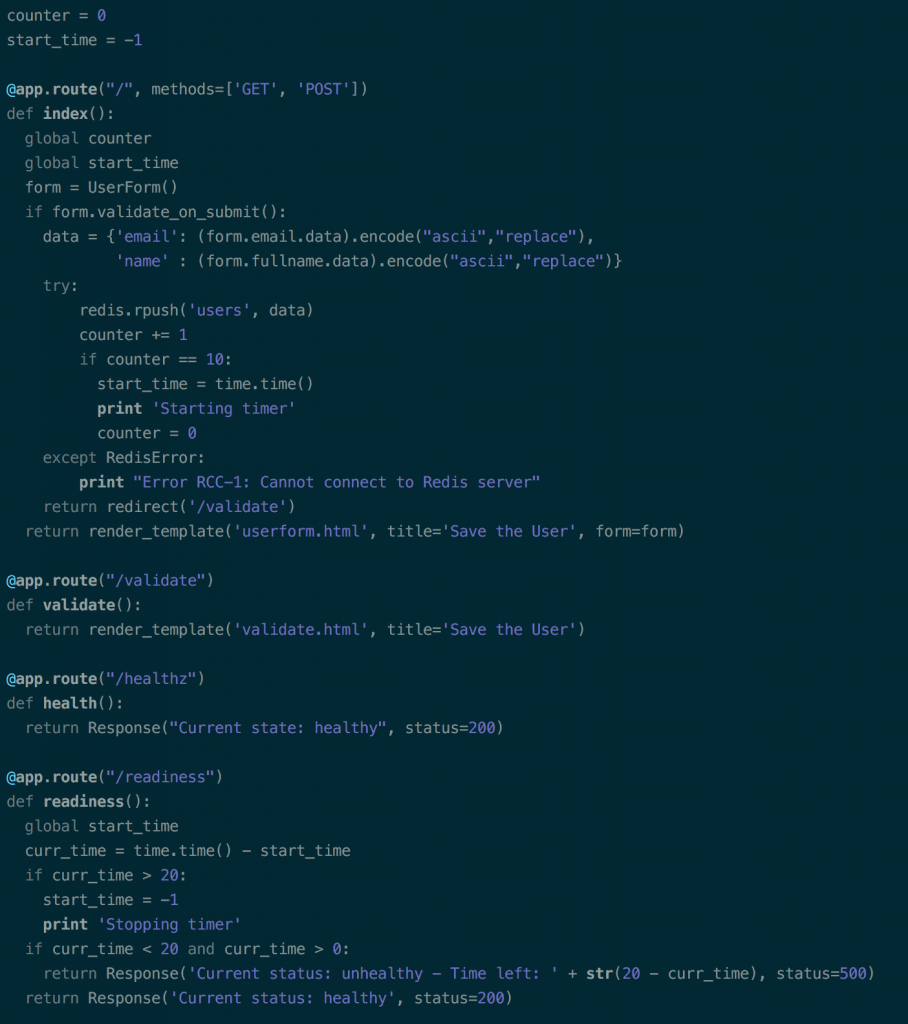
On configure le système de check associé dans le code du pod et nous pouvons bien voir que le pod se met en état indisponible le temps qu’il finisse ses “traitements”.
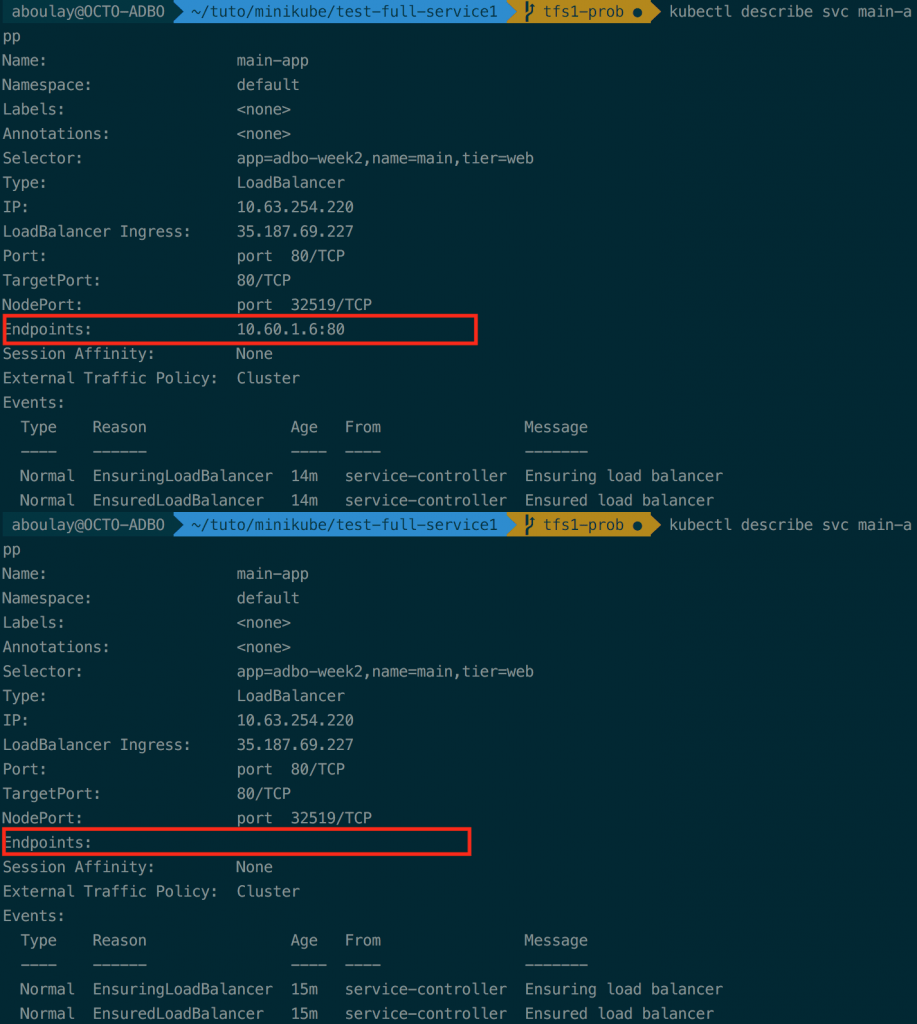
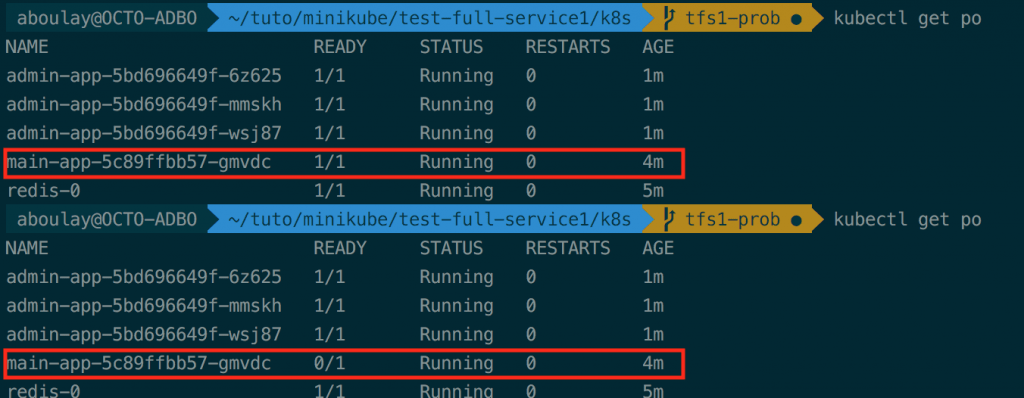
Ici, on peut voir que le pod à bien été retiré de la liste des endpoints du loadbalancer. Cependant, on peut également constater qu’il n’a pas été redémarré. Il n’est simplement plus dans l'état READY (disponible pour traiter une connexion).
Il faut savoir que les deux types de probes continue de contacter le pod même si celui-ci n’est plus dans l’état READY. En cas de problème avec un pod dans cet état, c’est à l'application de disposer d’un mécanisme permettant d’identifier une défaillance dans celle-ci et de modifier le retour de la liveness probe afin de faire en sorte de redémarrer le pod.
En appliquant correctement ces deux concepts, il est possible de créer un système de vérification complet permettant de gérer plus intelligemment son ensemble de pods. Cela suppose que le développeur a parfaitement intégré la différence entre les deux types de sondes et est en mesure de proposer, par le biais de l’application, des codes de retour différents en fonction de l’état du pod. La documentation sur les Container Lifecycle Hooks vous permettra d’aller plus loin sur la question.
Un des usages que l’on pourrait envisager est l’utilisation d’une base de données avec un service back-end. Si la base de données n’est pas prête, l'application peut renvoyer un mauvais code de retour afin de déclencher le mécanisme de la readiness probe afin de faire en sorte qu’il ne soit pas visible depuis le service jusqu’à ce que celle-ci soit disponible.
Dans cet article, nous avons vu qu’il est possible de faire des checks sur une adresse particulière. Les probes peuvent également effectuer des lignes de commande, faire des requête HTTP plus complexe ou des requêtes TCP. Avec une bonne utilisation de ces probes, de nouveaux usages s’ouvrent dans la façon de gérer les différents éléments qui composent le système.
Que ce soit pour :
- Tester si les applications répondent correctement.
- Laisser une instance finir leurs flux de travail sans leur imposer de charge supplémentaire.
- Tester le bon fonctionnement de l’application en continue.
Ainsi, si vous désirez simplement préserver votre système de dysfonctionnements ou permettre une gestion intelligente des différentes briques métier, nous vous recommandons chaudement d’implémenter ces mécanismes de health checking dans vos applications.

Merci à Carbot Animation pour nous avoir laissé utiliser ses sprites pour illustrer cet article.