L’Internet pour les nuls (partie 2 sur N)
Introduction
Cet article est le deuxième d'une série sur les protocoles réseaux contemporains.
- Partie 1: Historique et modélisation
- Partie 2: Ethernet
Nous avons, lors de l'article précédent, établi un état des lieux global des problématiques de réseau, notamment à travers les modélisations en couches d'OSI et de TCP/IP. Aujourd'hui, nous nous focalisons uniquement sur la couche 2, celle responsable de l'établissement d'un réseau local et de la communication des machines au sein de ce réseau. Seront donc hors sujet le temps de cet article les problématiques d'accès à une machine appartenant à un réseau distant, ainsi que toute forme d'adresse IP.
Toutes les technologies de réseau local sont aujourd'hui standardisées par l'IEEE, Institute of Electrical and Electronics Engineers. Vous connaissez peut-être le groupe de travail IEEE 754, qui a standardisé le fonctionnement de l'arithmétique pour les nombres flottants ; mais le groupe de travail qui nous intéresse aujourd'hui est IEEE 802, lui-même divisé en sous groupes dédiés à différents protocoles. De tous ces groupes, les seuls encore actifs aujourd'hui sont 802.3 pour Ethernet, 802.11 pour le Wi-Fi, 802.15 pour les réseaux personnels tels que Bluetooth, et enfin 802.1, qui s'occupe des considérations plus génériques et transverses. La lecture de ces standards, bien que laborieuse, est un point de pèlerinage obligatoire si vous cherchez à approfondir le sujet, et vous trouverez les liens nécessaires dans la bibliographie de fin d'article.
Après une passe de définition des concepts propres à cette couche, nous étudierons enfin le protocole Ethernet, son histoire, sa standardisation sous IEEE 802.3 et son implémentation actuelle. Si vous êtes curieux, la classique bibliographie en fin d'article vous fournira les ressources nécessaires pour étudier les autres protocoles de couche 2.
Le réseau local (LAN)
Topologie des réseaux locaux
Vous l'aurez compris, ce qui caractérise un réseau local, c'est la capacité à interconnecter des machines physiquement proches. Dès lors, il est intéressant en premier lieu de se demander quelles sont les différentes formes que peut prendre cette interconnexion.
Réseau point à point
La topologie triviale est la liaison point à point, où seulement deux machines sont reliées par un lien dédié. Votre bon vieux modem de l'époque pré-ADSL établissait notamment une connexion point à point entre votre ordinateur et le fournisseur d'accès à Internet.
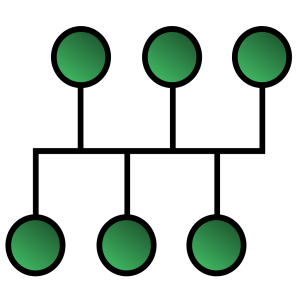
Topologie en bus
Dans une topologie en bus, les machines sont reliées par un câble commun, sur lequel tout le monde est connecté. Dans ce cas, le médium (le câble) est partagé, et deux machines ne peuvent donc pas parler en même temps.
La première version d'Ethernet utilisait notamment cette topologie.
Topologie en anneau
Une topologie en anneau est une sorte de bus, mais qui forme un cercle fermé. Les données se déplacent dans une seule direction, et sont retransmises par chaque nœud intermédiaire.
Un protocole populaire à l'époque utilisant cette topologie était Token Ring,
qui disparut petit à petit face à Ethernet.

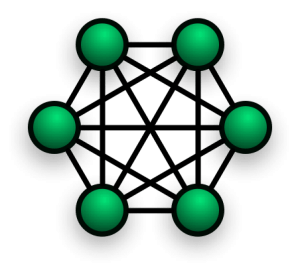
Topologie en maille
Dans un réseau maillé, tous les nœuds sont connectés deux à deux. Si cette approche n'est pas pertinente pour un grand nombre de nœuds, on retrouve cette topologie dans des technologies sans fil de radio, ainsi que dans certains protocoles militaires, qui permettent notamment à des appareils de se connecter directement entre eux sans dépendre d'une infrastructure sous-jacente dans un théâtre d'opérations.
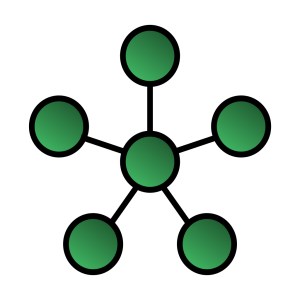
Topologie en étoile
Enfin, la topologie avec laquelle vous êtes probablement les plus familiers est la topologie en étoile, où tous les nœuds sont connectés à un appareil central qui redistribue les messages aux interlocuteurs adaptés.
En prenant l'exemple de la box se trouvant chez vous, c'est très probablement le type de réseau qui est présent dans votre maison. Le mode wi-fi AP (Access Point), ainsi que la version moderne d'Ethernet utilisent cette topologie depuis les apparitions successives du hub et du switch.
Modes de transmission et problématiques de collision
Dans les topologies étudiées plus haut, chaque liaison est faite par un medium, qui possède un certain nombre de propriétés, telles que la vitesse de transfert, la taille maximale d'une trame (la fameuse MTU), et si ce medium est en simplex, half-duplex ou full-duplex :
Simplex
Dans un mode de communication simplex, l'information ne transite que dans un sens : l'émetteur est toujours émetteur, le récepteur toujours récepteur. Un exemple de canal de communication simplex est votre téléviseur ou votre poste de radio : vous pouvez recevoir de la donnée sur votre récepteur, mais vous n'avez pas la possibilité d'en envoyer à l'émetteur.
Half-duplex
Dans un mode half-duplex, l'information peut se déplacer dans les deux sens, mais seulement dans un seul sens à la fois. En d'autres termes, il faut attendre que l'interlocuteur en face ait fini de parler pour pouvoir parler à son tour : il est impossible pour les deux nœuds de communiquer en même temps.
L'exemple classique est celui de deux talkie-walkies : les deux appareils utilisant la même fréquence, un seul peut être émetteur à la fois sous peine de collision, et l'utilisateur utilise un mot clé comme "over" pour indiquer qu'il a fini de parler et se place en position d'écoute.
Full-duplex
Enfin, le full-duplex est en quelque sorte le mode le plus puissant, puisqu'il permet aux deux appareils d'émettre et de recevoir simultanément, sans aucun risque de collision.
On peut simplement voir une liaison full-duplex comme deux half-duplex collées l'une contre l'autre, ce qui présente des avantages considérables : utilisation maximale de la bande passante pour chaque direction, garantie de non collision...
Adresses, domaines de broadcast et de collision
Enfin, pour nous aider à raisonner facilement, nous définissons une adresse matérielle propre à la couche 2, ainsi que deux types de "domaines", c'est-à-dire de sous-ensembles de noeuds :
Adresses matérielles
La couche 2 fournit pour chaque interface réseau une adresse matérielle, normalement immutable et unique à cette interface. C'est cette adresse qui sera utilisée pour identifier les émetteurs et destinataires des différents messages au sein du réseau local. Plus tard, nous étudierons d'autres formes d'adresses comme l'adresse IP qui peuvent identifier une machine appartenant à un réseau distant. Prenons l'exemple d'Ethernet, le protocole étudié par la suite: chaque adaptateur réseau est identifiée par une adresse matérielle appellée Hardware Address, MAC address ou tout simplement Ethernet address, composée de 48 bits. Ces 48 bits sont généralement représentés par 6 blocs de deux chiffres hexadécimaux, par exemple 01:23:45:67:89:ab. Lorsqu'un message est envoyé, il contiendra entre autres l'adresse du destinataire, afin que les autres appareils puissent l'ignorer s'ils ne sont pas concernés.
Domaine de broadcast
Le domaine de broadcast, ou "domaine de diffusion" en bon français, d'un réseau est l'ensemble des noeuds concernés lorsqu'un message est envoyé en broadcast, par exemple avec l'adresse Ethernet spéciale ff:ff:ff:ff:ff:ff. Comme un broadcast concerne toutes les machines présentes sur le lien, on peut facilement caractériser un réseau local par ce domaine : un réseau est son domaine de broadcast, c'est-à-dire l'ensemble des machines accessibles par un broadcast.
Domaine de collision
Plus variable, un domaine de collision est une partie du réseau où plusieurs paquets peuvent rentrer en collision. Qu'est-ce qu'une collision ? C'est ce qui arrive quand deux paquets se retrouvent sur le même support physique (câble, fréquence, ...) et s'interfèrent entre eux, typiquement parce qu'un médium d'accès est partagé entre plusieurs machines. Les domaines de collision forment en quelque sorte des "sections critiques", où plusieurs machines ne peuvent communiquer simultanément sans un protocole de contrôle d'accès au médium (Media Access Control: MAC !). Bien entendu, un tel protocole aura nécessairement un impact sur la performance de la communication, et la minimisation des domaines de collision gouvernera l'évolution des algorithmes que nous allons étudier.
Ethernet
L'état des lieux des concepts théoriques étant fait, nous pouvons finalement nous attaquer à la fameuse famille des protocoles Ethernet, à commencer par sa forme ancestrale, au doux nom de CSMA/CD.
CSMA/CD
Le protocole trouve ses origines chez Xerox PARC, le département de R&D de Xerox (à qui on doit par ailleurs l'invention de la souris et des interfaces graphiques, entre autres), en particulier chez Robert Metcalfe, qui publie en 1973 le premier mémo décrivant Ethernet^<a id="ref1" href="#fn1">[1]</a>^, un système permettant l'interconnexion de plusieurs machines et imprimantes.
Ici, rien à voir avec les câbles RJ45 branchés dans des freeboxes ou tout autre appareil magique loué par un fournisseur que nous imaginons aujourd'hui : toutes les machines sont reliées par un gros câble coaxial qui offre un médium partagé par toutes les machines. Si vous avez bien suivi les parties précédentes, il s'agit ici d'une topologie en bus ; et en conséquence le domaine de collision est égal au domaine de broadcast : une seule machine ne peut parler à la fois sur le câble, et la présence d'un algorithme de partage d'accès est primordial. Ça tombe bien, puisque c'est très exactement le coeur de ce que propose R. Metcalfe : un protocole capable de sentir ce qui se passe sur le câble, et permettant d'offrir un accès simultané dessus tout en détectant les collisions. Ce protocole, après quelques évolutions de nom comme de fonctionnement (Aloha, Slotted Aloha,...) s'appelle Carrier-Sense Multiple Access with Collision Detection, ou plus simplement CSMA/CD.
Nous pouvons alors comprendre pourquoi le réseau basé sur ce protocole s'appelle Ethernet : similaire à l'Éther des philosophes grecs, le câble coaxial agit comme un support omniprésent qui transmet toutes les informations pour tout le monde.
Le fonctionnement théorique de CSMA/CD est extrêmement simple, et peut être résumé en quelques lignes de pseudocode :
1) Est-ce que quelqu'un d'autre est en train de parler ? Si oui, attendre et réessayer plus tard
2) Commencer à transmettre la trame, tout en surveillant si une collision apparaît (en regardant la différence entre ce qui est envoyé et ce qu'on détecte sur le câble)
3) Si une collision a lieu, appliquer la sous-procédure suivante :
a) Envoyer un "jam signal", un message spécial qui indique à tout le
monde qu'une collision a été détectée. L'envoi de ce signal sert
à garantir que tous les acteurs cherchant à communiquer prennent
conscience de la collision.
b) Attendre une période aléatoire avant de retenter l'envoi. Le
caractère aléatoire est primordial, car sinon tous les acteurs vont
renvoyer leur message en même temps, causant une nouvelle collision
ad infinitum. De plus, ce temps aléatoire est proportionnel au
nombre de tentatives : plus on a essayé, plus on attend entre chaque
tentative.
c) Au bout d'un trop grand nombre de tentatives, annuler la transmission
Cet algorithme, presque trivial, a amené des performances spectaculaires face à ses concurrents, tels que Token Ring et Token Bus, et de fil en aiguille, le succès d'Ethernet se confirma en 1983 avec sa standardisation sous l'IEEE 802.3.
C'est l'époque des superbes connecteurs 10BASE5 et 10BASE2, extrêmement populaires dans les années 80. Si vous êtes curieux, cela ressemblait à ça :

Adaptateur 10Base-2 (source: retroracunala)
Comme vous pouvez le voir, le petit connecteur en T permet à chaque appareil de se connecter à ses voisins.
Ethernet over Twisted Pair
Un dernier problème restait : les entreprises, clientes potentielles, ne possédaient pour la plupart pas de câblage coaxial pour leur infrastructure. Cependant, elles avaient à leur disposition un câblage de paires torsadées, utilisées pour la téléphonie. Il fallait donc adapter le protocole pour ce support physique, ce qui fut chose faite avec EoTP, Ethernet over Twisted Pair, qui est le format avec lequel vous êtes probablement le plus familier.
Nous arrivons enfin à quelque chose qui ressemble aux cartes Ethernet que nous avons l'habitude de voir, avec le premier adaptateur 10BASE-T et sa superbe vitesse de 10Mbit/s.

Adaptateur 10BASE-T / 100BASE-TX (source: ebay)
Comme son nom l'indique, le T représente Twisted pair, des paires torsadées qui sont terminées par des adaptateurs 8P8C, que tout le monde appelle RJ45 à tort, même si c'est techniquement faux.

Connecteur 8P8C (et non pas RJ45 !) (source: wikipedia)
Plus tard, ce format évoluera pour des vitesses de 100Mbit/s ("fast ethernet"), puis 1Gbit/s et 10Gbit/s, avec plein de noms techniques ressemblant à des vaisseaux de Star Wars, comme 100BASE-TX, 1000BASE-T et 10GBASE-T.
L'étude approfondie de cette version ainsi que ses variantes serait aussi passionnante que longue, aussi nous nous attarderons uniquement sur le changement majeur apporté : contrairement au format initial, EoTP offre une topologie en étoile, tous les nœuds étant reliés par un composant central : le hub, qui fut rapidement remplacé par le switch.
Hub et switch
Le hub ("concentrateur" en bon français) a aujourd'hui entièrement disparu, le switch étant une amélioration en tout point dont les seules réticences étaient le coût plus élevé. Aujourd'hui, bien qu'il n'existe aucune raison d'utiliser un hub, il reste intéressant d'étudier rapidement son comportement pour comprendre ses limites.

Un hub Ethernet à 10Mbit/s (10BASE-T) avec 4 ports (source: amazon)
Le fonctionnement du hub est extrêmement simple : à la réception d'un message sur l'un de ses ports (c'est-à-dire l'une de ses pattes, rien à voir avec les ports des protocoles sur la couche 4), il réplique ce message sur toutes les autres pattes. Ainsi, le destinataire du message, étant forcément sur l'une des pattes, recevra le message, tandis que les autres nœuds pourront simplement ignorer ce message qui ne les concerne pas. On peut donc noter sa caractéristique principale : le hub n'analyse absolument pas les paquets transitant par lui.
On pourrait naïvement croire que le problème du hub est un simple problème de bande passante, qu'il génère du bruit inutile qui pollue le traitement des noeuds non concernés, mais la conséquence est bien plus sournoise : en répliquant le moindre message à toutes les machines, le hub étend le domaine de collision à l'intégralité du domaine de broadcast, comme dans une topologie en bus ! Ainsi, même avec une trentaine de machines connectées, il suffit qu'une seule décide d'envoyer un message pour que tout le monde soit contraint à patienter, sous peine de collision !
Il était donc nécessaire d'avoir un appareil plus puissant, qui pouvait analyser les trames transitant à travers lui pour ne l'envoyer qu'aux destinataires concernés, et cet appareil était le switch ("commutateur").

Un switch à 24 ports (source: souq)
Son fonctionnement n'est pas non plus très compliqué : le switch apprend petit à petit les adresses de toutes les machines qui lui sont connectées, en inspectant le champ d'adresse source des trames entrantes, ce qui lui permet de ne les transmettre qu'aux ports des destinataires concernés. Dans le cas où l'adresse associée à un port n'est pas encore connue, un broadcast est effectué, mais ce cas n'arrive normalement que dans les phases initiales de communication. La structure en mémoire dans laquelle le switch enregistre ces associations est appelée FIB, Forwarding Information Table.
Bien sur, il est possible de relier directement deux switch, qui formeront alors un "super switch" partageant leur domaine de broadcast. L'impact de ce type de connections sur la FIB est un exercice laissé au lecteur.
Sans trop de surprise, le switch a très vite remplacé le hub, et est aujourd'hui un appareil fondamental dans tout réseau local à base d'Ethernet : si vous avez une box chez vous, sachez qu'un switch se cache dedans !
Que deviennent les domaines de collision ? Un regard rapide montre qu'ils n'existent plus qu'entre chaque nœud et son switch, les premiers câbles Ethernet fonctionnement en half-duplex. Mais en 1997, l'extension du standard 802.3X est publiée, décrivant un mode d'opération full-duplex. Désormais, CSMA/CD n'est plus du tout nécessaire : nul besoin de Carrier Sense car chaque machine peut envoyer un paquet dès qu'elle le souhaite ; il n'y a pas de Multiple Access car chaque nœud forme une liaison point à point avec le switch ; et enfin nous n'avons pas besoin de Collision Detection car la liaison avec le seul interlocuteur direct est en full-duplex !
Il est intéressant de regarder le parcours effectué par Ethernet : originellement appelé comme tel car fournissant une topologie en bus sur un câble coaxial partagé, devenu populaire grâce un algorithme de détection de collision ; son nom renvoie aujourd'hui à une topologie en étoile, supportée par des paires torsadées, sans détection de collision nécessaire. C'est beau le progrès.
La terrible tempête de broadcast
Si vous avez bien suivi, il est possible et même courant de connecter plusieurs switches directement entre eux, ce qui permet d'étendre le domaine de broadcast. Dès lors, il faut faire très attention à ne pas créer de boucle, par exemple avec deux câbles différents reliant les mêmes switches. Si c'est le cas, le moindre broadcast causera des résultats effroyables, car le switch transmettant un tel message à tous les autres ports que sa source, le message alternera à l'infini entre les deux switches, le protocole Ethernet ne définissant pas de durée de vie pour les paquets. C'est le fameux "broadcast storm", et ça peut mettre à genoux votre infrastructure en un clin d'œil si vous ne faites pas attention. Absolument terrifiant.
Pour se protéger, deux solutions sont possibles. La plus simple serait d'éviter sagement toute forme de boucle, mais plus une infrastructure devient grande, plus ce risque augmentera. De plus, nous souhaitons potentiellement relier deux switches avec plusieurs câbles afin d'augmenter la résilience, ce qui nous amène forcément à des boucles.
La deuxième solution est d'activer sur vos switches le protocole STP (Spanning Tree Protocol), ou son successeur moderne, SPB (Shortest Path Bridging), standardisés respectivement par 802.1D (puis incorporé dans 802.1Q-2014) et 802.1aq. Sans trop rentrer dans les détails, ce protocole permet au switch de construire un arbre de recouvrement (spanning tree) et de désactiver automatiquement les liens causant une boucle. Si vos souvenirs d'algorithmique sont vagues, le Cormen^<a id="ref2" href="#fn2">[2]</a>^ reste une excellente ressource.
Implémentation et utilisation
La trame Ethernet
Trêve de bavardages, nous pouvons désormais regarder à quoi ressemble une trame Ethernet moderne selon 802.3, ce qu'on appelle la trame Ethernet II ou DIX :

Les éléments en rouge existent sur la première couche du modèle OSI, c'est-à-dire qu'il s'agit de considérations uniquement physiques et traitées par la carte réseau. Votre noyau ne voit donc pas ces champs là dans le traitement du paquet (en pratique, le champ FCS est également traité par la carte réseau est n'est pas mis en mémoire, mais le standard précise bien que ce champ appartient à la couche 2). On distingue trois champs, que nous pouvons expliquer rapidement :
Le préambule et le SFD (Start Frame Delimiter) servent à synchroniser les horloges de l'émetteur et ses récepteurs, afin que chaque bit soit lu au même "rythme" (et qu'une série comme "1111" ne soit pas interprétée comme un seul "1" lu très lentement). Pour ce faire, le préambule est une succession de 1 et 0 alternés sur 7 octets. Le SFD est similaire, mais se conclut par "11" au lieu de "10" pour marquer la fin de la synchronisation et le début du message.
L'IPG est l'InterPacket Gap, un message vide servant de tampon d'une longueur minimale de 12 octets qu'une carte réseau doit envoyer avant de passer au message suivant.
Les éléments en vert sont les champs caractéristiques d'Ethernet sur la couche 2, et sont pour l'ensemble assez simples à comprendre :
L'adresse MAC de destination est l'adresse du destinataire. Ce champ sera inspecté par le switch pour transmettre la trame au bon destinataire. Si une machine terminale reçoit une trame dont l'adresse de destination ne correspond à aucune de ses cartes réseau, le comportement prescrit est d'abandonner le message.
L'adresse MAC de source est celle de l'émetteur. Cette information est notamment utilisée par les switchs pour remplir leur Forwarding Information Base, c'est-à-dire leur table d'association entre les adresses MAC des appareils connectés et les ports correspondants.
L'EtherType est, en faisant abstraction de ses anciens usages, un nombre sur deux octets qui indique le format du payload contenu dans le paquet. Souvenez vous que si les couches OSI sont parcourues du haut vers le bas à l'émission d'un paquet, elles sont dépilées du bas vers le haut à la réception, et il est donc nécessaire de savoir quelle routine de traitement utiliser pour chaque couche ! Quelques exemples de valeurs classiques : 0x0800 indique que le payload est un paquet IPv4, 0x86DD représente IPv6 et 0x0806 est l'ARP. (Si l'on devait être exhaustif, nous devrions préciser qu'une valeur inférieure à 1500 indique une autre utilisation de ce champ, qui représente alors la taille du payload, mais cette précision nécessiterait l'explication des différentes variantes possibles de la trame selon les différentes entités ayant offert une standardisation, ce que je vous propose de garder hors sujet afin de nous concentrer sur l'essentiel)
Le Frame Check Sequence est un checksum fait avec CRC32 des champs de la trame (MAC source, MAC dest, EtherType et payload), permettant de détecter si la trame a été corrompue en transit. Détailler son calcul serait de l'ordre de l'acharnement pédagogique, aussi nous en resterons là. Pour aller plus loin, un excellent article de Ross Williams sur le sujet est disponible dans la bibliographie.^<a id="ref3" href="#fn3">[3]</a>^
Enfin, nous avons le payload, c'est-à-dire le contenu des couches supérieures encapsulé dans notre trame. C'est dans ce payload qu'on retrouvera entre autres les notions d'adresse IP, de port, ainsi que le message applicatif en lui même. Notons sa taille maximale : 1500 octets. C'est la fameuse MTU, Maximum Transmission Unit. En comptant les autres champs, une trame ne peut donc pas être plus grande que 1538 octets (Les champs de la couche 1 n'appartiennent techniquement pas à la trame qui est un concept de couche 2 et ne sont parfois pas comptés, c'est pourquoi vous verrez parfois le nombre de 1522, voire de 1518 en ignorant le FCS). Tout message supérieur à la MTU devra être fragmenté en amont par les couches supérieures (en pratique par le protocole IP). Notons que, bien que non standardisé par IEEE 802.3, une extension implémentée par de nombreuses NICs (Network Interface Card) est la jumbo frame, qui étend la MTU à 9000 octets. Ce type de trame n'est généralement utilisé que dans des cas spécifiques, par exemple l'interconnection de noeuds de stockage dans un cluster.
La définition d'une trame dans le noyau Linux
Histoire de vous prouver que tout ce que nous venons de voir n'est ni magique, ni fantaisiste ; je vous propose de jeter un œil rapide à l'implémentation de la trame au sein du noyau Linux. Pas de panique, le fichier source qui nous intéresse est on ne peut plus simple : plein de définitions de nombre magiques, suivi de la définition de la structure, qui correspond aux premières cases vertes étudiées plus haut.
Il s'agit de include/uapi/linux/if_ether.h, que vous pouvez consulter ici. Si son emplacement vous paraît arbitraire, le raisonnement est simple : include contient les headers, uapi signifie Userland APIs, c'est-à-dire les définitions du noyau qui sont accessibles depuis les programmes utilisateurs, et if signifie tout simplement interface.
Sans surprise, le point clé de ce fichier est la définition de la structure suivante :
struct ethhdr { unsigned char h_dest[ETH_ALEN]; /* destination eth addr */ unsigned char h_source[ETH_ALEN]; /* source ether addr */ __be16 h_proto; /* packet type ID field */ } __attribute__((packed));
On y retrouve les trois premiers champs de la couche 2 (je vous le rappelle, les champs rouges ont été traités directement par l'adaptateur réseau), qui seront traités par le noyau par la fonction netif_receive_skb qui se trouve dans net/core/dev.c. Ici, le code fait certes un peu plus peur (nous sommes dans la fonction de traitement des paquets reçus du noyau, rien que ça), mais, conceptuellement, tout ce que fait ce bout de code est initialiser une structure struct sk_buff (socket buffer, la structure fondamentale de la pile réseau du noyau, étant la représentation mémoire d'une socket), remplir ses premiers champs de couche 2 et faire l'équivalent d'un gros switch sur skb->protocol pour passer la main à la bonne routine de traitement de la couche 3 (dans la fonction deliver_skb).
Si vous vous demandez pourquoi le FCS n'est pas présent, c'est tout simplement parce que votre noyau ne le voit pas, ce champ étant intégralement traité par la carte réseau.
802.1Q : Les VLANs
Comme nous l'avons vu, toutes les machines connectées à un switch partagent le même domaine de broadcast, et appartiennent donc au même réseau local. Nous pouvons parfaitement imaginer une situation où cela ne serait pas désirable, par exemple pour des raisons de sécurité. Une solution naïve, si nous cherchions à isoler notre parc en trois réseaux distincts, serait d'acheter trois switchs. Mais un bon switch coûte cher, et il serait dommage de dépenser une fortune pour trois appareils qui ne seront chacun utilisés que partiellement. La solution ici est de permettre à un switch de sous-découper un réseau physique en plusieurs réseaux virtuels (VLAN, Virtual LAN), et garantir que ces réseaux ne peuvent communiquer entre eux (du moins, à ce niveau du modèle OSI). Pour ce faire, l'IEEE a standardisé l'extension 802.1Q en 1999, qui permet aux trames Ethernet de supporter cette fonctionnalité.
Comme son nom l'indique, cette extension a été développée par le groupe de travail 802.1. La lettre Q ici tient pour QoS (Quality of Service), qui est une autre fonctionnalité apportée par cette extension, à savoir un champ de priorité au sein des trames. Regardons à quoi ressemble une trame supportant cette extension :
Comme vous pouvez le voir, cette extension ajoute un nouveau jeu de champs entre l'adresse MAC source et l'EtherType. Heureusement, cet ajout ne casse pas la rétrocompatibilité, car le premier champ ajouté est le Tag Protocol Identifier, qui contient toujours la valeur 0x8100. On peut donc le voir comme une valeur particulière de l'EtherType qui entraîne un traitement des champs ajoutés avant de revenir au traitement classique. C'est ce que nous pouvons notamment voir dans la fonction __netif_receive_skb_core de net/core/dev.c :
if (skb->protocol == cpu_to_be16(ETH_P_8021Q) || skb->protocol == cpu_to_be16(ETH_P_8021AD)) { skb = skb_vlan_untag(skb); if (unlikely(!skb)) goto out; }
Analysons maintenant en détail ces nouveaux champs :
Le PCP n'est pas (que) une drogue, mais le Priority Code Point, qui indique la priorité relative de la trame par rapport aux autres dans le cadre d'une QoS.
Le DEI est le Drop Eligible Indicator, qui indique si la trame peut être jetée dans le cas d'une congestion (quand l'autoroute est pleine et qu'il y a des bouchons).
Enfin, le VID, VLAN Identifier, est l'information qui nous intéresse : elle représente l'identifiant d'un VLAN. Cette information est également appelée le tag, car on peut marquer l'appartenance ou non d'une trame à un VLAN particulier en modifiant ce champ. Un petit calcul rapide montre que sur 12 bits, 4096 valeurs sont possibles, auxquelles on soustrait les valeurs 0x000 qui représente l'absence de VLAN et 0xFFF qui est réservée.
Comment ce tag est-il utilisé ? La chose importante à retenir est que ces informations sont uniquement manipulées au niveau du switch, et ne sont pas censées apparaître dans les trames reçues par les machines finales : une machine n'a pas conscience d'être dans un VLAN !
En pratique, un switch sachant utiliser les VLAN peut configurer chacun de ses port de deux manières :
En mode trunk, le switch ignore les tags qui transitent et laisse rentrer et sortir tous les paquets sur ce port. Bien évidemment, cette option n'est pas adaptée si le port est connecté à un noeud terminal, mais permet de connecter deux switches entre eux qui partagent la même politique.
En mode tag, on associe un numéro de VLAN à ce port, et le switch va surveiller les paquets transitant sur ce port :
Si un paquet arrive en provenance de ce port, c'est qu'il est émis d'une machine qui appartient à ce VLAN (mais ne le sait pas), on modifie donc la trame pour ajouter ce tag. Si un tag était déjà présent, il y aura double tagging, ce qui a moins de savoir très exactement ce que vous faites est probablement le signe que tout va exploser à un moment.
Si un paquet sort vers ce port, on regarde d'abord la présence du tag. S'il est présent et correspond au bon numéro, on retire le tag et laisse passer le paquet. S'il n'y a pas de tag ou qu'il a le mauvais identifiant, le paquet est refusé.
Un petit schéma pour illustrer tout cela :
Comme vous pouvez le voir, toute la logique de gestion des tags est faite au niveau des switches, et les machines finales ne voient même pas le header qui a été ajouté. Du moins, ceci est vrai dans le mode de fonctionnement canonique. Il existe des cas où une machine autre qu'un switch recevra des trames taggées sur un port trunk, que ce soit pour agir comme switch de misère ou parce qu'elle héberge des machines virtuelles sous différents VLAN. Comme vous l'avez vu, le noyau Linux permet de traiter ces cas s'ils s'avèrent nécessaires.
Premières manipulations
Pour conclure cet article, qui était assez théorique, quelques informations pratiques sont les bienvenues. Nous allons donc jeter un oeil à l'outil ethtool, qui permet d'inspecter et de modifier la configuration de votre NIC (Network Interface Card). Et enfin, nous aborderons pour la première fois une suite d'outils qui deviendra votre couteau suisse tout au long de cette série, avec son sous-ensemble dédié à la deuxième couche.
Ethtool
Ethtool est le remplaçant de mii-tool, et s'il nous permet de modifier certaines options de configuration de votre adaptateur réseau, je préfère passer cette fonctionnalité sous silence car il est rare de devoir le faire, l'auto-négociation faisant généralement son affaire. Par contre, vous pouvez voir qu'il est très facile de s'en servir pour inspecter, en regardant l'exemple ci-après tiré de l'un de mes serveurs :
$ ethtool eth0 Settings for eth0: Supported ports: [ TP ] Supported link modes: 10baseT/Half 10baseT/Full 100baseT/Half 100baseT/Full 1000baseT/Full Supported pause frame use: Symmetric Supports auto-negotiation: Yes Advertised link modes: 10baseT/Half 10baseT/Full 100baseT/Half 100baseT/Full 1000baseT/Full Advertised pause frame use: Symmetric Advertised auto-negotiation: Yes Speed: 1000Mb/s Duplex: Full Port: Twisted Pair PHYAD: 0 Transceiver: internal Auto-negotiation: on MDI-X: on (auto) Supports Wake-on: pumbg Wake-on: g Current message level: 0x00000007 (7) drv probe link Link detected: yes
La signification de chaque ligne est laissée comme exercice au lecteur, s'il souhaite aller plus loin dans l'étude de ce protocole.
Iproute2
Le voilà, le fameux, je vous présente iproute2 ! Ne vous fiez pas à son nom, cet outil permet de manipuler presque tous les aspects de la pile réseau. Toutes les commandes dérivent du binaire ip (dont vous pouvez regarder la documentation avec le man ip(8), mais la sous-commande qui nous intéresse ici est ip link (man ip-link(8)), qui peut être abrégée en ip l. Un appel sans autre paramètre nous affiche la liste de nos interfaces ainsi que leur caractéristiques. Regardons un extrait issu de mon serveur :
$ ip l 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 0c:c4:7a:0e:d5:24 brd ff:ff:ff:ff:ff:ff 3: eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 0c:c4:7a:0e:d5:25 brd ff:ff:ff:ff:ff:ff 4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default link/ether 02:42:2d:92:5a:d9 brd ff:ff:ff:ff:ff:ff
D'autres interfaces virtuelles peuvent apparaître dès qu'on commence à s'amuser avec de la virtualisation, aussi nous nous contenterons de cet extrait. La première interface est lo, l'interface de loopback. Il s'agit d'une interface virtuelle pour les paquets qui n'existent pas en dehors de notre machine, par exemple lorsqu'on accède à un serveur local. eth0 et eth1 représentent des interfaces réelles, qui comme leur nom l'indique sont pour de l'Ethernet (certaines distributions, depuis le passage à systemd, utilisent une nouvelle règle nommage prédictible et constante à travers les redémarrages, comme enp0s2^<a id="ref4" href="#fn4">[4]</a>^). Enfin docker0 est une interface virtuelle utilisée pour représenter la connexion aux conteneurs sur le serveur. Vous en saurez plus lors de la partie concernant le NFV.
Chaque interface possède une adresse MAC ainsi qu'une adresse de broadcast (brd) qui est, sans surprise, ff:ff:ff:ff:ff:ff. Les autres informations derrière sont déjà plus intéressantes :
Les informations en majuscules entre chevrons sont les ifr_flags, et représentent l'état et les capacités de l'interface. Pour vous épargner un inventaire à la Prévert, vous pouvez trouver la signification de ces flags sur la manpage de netdevice(7).
Des informations suivantes, nous pouvons en retenir quelques unes en particulier:
la MTU, qui ne devrait plus avoir de secret pour vous
qdisc est la queuing discipline, c'est à dire la manière dont le noyau traite la file de paquets en attente de traitement.
qlen est justement la taille de cette file.
Le reste devrait pouvoir se déchiffrer sans trop de problème, si vous êtes munis d'un bon moteur de recherche et de la curiosité nécessaire.
Je vous invite à lancer ces commandes et explorer leur résultat sur votre machine. Si elles ne sont pas disponibles, c'est de votre faute, vous n'aviez qu'à pas utiliser un système d'exploitation propriétaire (les gens qui utilisent *BSD n'existent pas, c'est bien connu).
Petit exercice : VLAN untagging
Les autres commandes peuvent s'étudier sans trop de difficulté à l'aide de la fameuse iproute2 cheat sheet^<a id="ref5" href="#fn5">[5]</a>^, mais histoire de ne pas vous laisser sur votre faim je vous propose une dernière manipulation à l'aide de cette commande :
Supposons, pour une raison arbitraire, que votre machine soit connectée à un switch par l'interface eth0 via un port trunk, qui dessert notamment les VLANs 42 (comme le sens de l'univers) et 51 (comme le pastis). Vous souhaitez dépiler ces deux tags pour envoyer les flux à deux applications différentes. Comment faire ? Pas de panique, iproute2 à la rescousse ! Nous pouvons créer deux interfaces virtuelles, représentant le flux après traitement du tag :
$ ip link add name eth0.42 link eth0 type vlan id 42 $ ip link add name eth0.51 link eth0 type vlan id 51
Nous avons donc créé deux nouvelles interfaces, eth0.42 et eth0.51 (le choix du nom est libre, mais ce style de nommage reste assez traditionnel), que nous pouvons voir sur un ip link show:
680: eth0.42@eth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 0c:c4:7a:0e:d5:25 brd ff:ff:ff:ff:ff:ff 681: eth0.51@eth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 0c:c4:7a:0e:d5:25 brd ff:ff:ff:ff:ff:ff
Notons que l'adresse MAC est bien évidemment la même que celle de l'interface physique sous-jacente. Dès lors, il suffit de faire écouter nos applications sur ces interfaces, leur attribuer des adresses IP, bref, ce que vous voulez !
Conclusion
À l'issue de cet article, le fonctionnement général d'un réseau local ne devrait normalement plus avoir de secret pour vous. Nous avons notamment pu défricher les concepts généraux propres à la couche 2, avant de nous attarder sur son protocole le plus populaire, Ethernet. Bien sur, cette introduction, aussi copieuse que je le souhaite, ne traite pas l'intégralité du sujet, et il reste de nombreux points qu'il est possible d'aborder, tels que l'agrégation de liens, l'auto-négociation, et la liste des nombreuses variantes pouvant exister.
De plus, nous n'avons pas du tout étudié les autres protocoles de couche 2 encore existants, notamment le Wi-Fi, qui mériterait un sujet à part entière. Je vous invite, si vous êtes curieux, à fouiller dans la bibliographie fournie en fin d'article pour aller plus loin, toujours plus loin.
Le troisième article abandonnera la couche 2 pour s'attarder à la suivante, à travers le légendaire protocole IPv4. Nous parlerons également en détail des règles de routage utilisés par votre noyau pour envoyer des paquets au-delà du réseau local, ainsi qu'une multitude d'autres joyeusetés.
Références et bibliographie
Ethernet: Distributed Packet Switching for Local Computer Networks." [2]: Cormen, Thomas H., Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. 2009. Introduction to Algorithms, Third Edition. 3rd ed. The MIT Press. [3]: Williams, Ross N. 1993. A painless guide to CRC error detection algorithms [4]: Freedesktop. n.d. Predictable Network Interface Names. [5]: Baturin, Daniil. 2013. Iproute2 Cheat Sheet
Institute of Electrical and Electronics Engineers. IEEE GET program, section 802(R) Stevens, W. Richard. 1993. TCP/Ip Illustrated (Vol. 1): The Protocols. Boston, MA, USA: Addison-Wesley Longman Publishing Co., Inc. Kozierok, Charles. 2005. TCP/Ip Guide: A Comprehensive, Illustrated Internet Protocols Reference. No Starch Press. Spurgeon, Charles E. 2000. Ethernet: The Definitive Guide. O'Reilly Media, Inc. Rosen, Rami. 2013. Linux Kernel Networking: Implementation and Theory. 1st ed. Berkely, CA, USA: Apress.