L’IA embarquée : entraîner, déployer et utiliser du Deep Learning sur un Raspberry (Partie 3)
Dans cette série d’article, on se propose d’étudier le cas d’usage de reconnaissance de dessins grâce à un raspberry. L’idée est d’utiliser la caméra d’un raspberry pour capturer une image représentant un dessin, et déterminer grâce à un réseau de neurones s’il s’agit d’une voiture ou non. Dans un premier article, on a entraîné un réseau de neurones performant à l’aide du framework Keras. Le second article porte sur le déploiement maîtrisé du modèle dans un environnement de production. Il ne nous reste plus qu’à incorporer le modèle dans une application python qui détermine, à partir d’une photo de la caméra, s’il s’agit d’un dessin de voiture ou non.
Partie 3 : inférence sur les images d’une caméra de Raspberry Pi
Nous avons d’ores et déjà commis une erreur dans la démarche d’industrialisation de notre modèle. En effet, l’intégration du modèle est étudiée uniquement en fin de chaîne de développement. Cette étape cruciale est celle qui conditionne le plus la mise en production, et nous la considérons seulement après d’autres étapes à la complexité élevée. D’expérience, l’intégration d’un modèle est ce qui prend le plus de temps et ce qui révèle le plus de points de friction ; c’est d’ailleurs le sujet d’une matinale d’OCTO : Levez la malédiction du passage de l’IA en production. En revanche, la “malédiction” ici ne provient pas de difficultés à s’intégrer à un système d’information existant ou de potentiels problèmes dûs au flux d’acquisition de la donnée. Elle s’exprime par le vecteur d’acquisition des données que nous manipulons ; elles diffèrent en effet légèrement de ce que nous comptions obtenir. Comme souvent, le diable réside dans la data.
Données de production vs. Données d’entraînement
Notre postulat de départ est d’utiliser la caméra du Raspberry comme source de données. La difficulté technique à simuler une caméra sur un raspberry émulé semble trop importante pour un gain discutable. Il est donc temps de sortir de la virtualisation et revenir sur un Raspberry physique. Les types de caméras disponibles sont nombreux, et nous utilisons ici le module caméra V2. Pour la modique somme de 30€, le module nous permet de prendre des photographies à une résolution native de 8 MPx tout de même !
Par ailleurs, il existe plusieurs utilitaires pour faciliter la prise de photo : via la ligne de commande avec l’outil raspistill, ou en Python avec la librairie dédiée PiCamera.
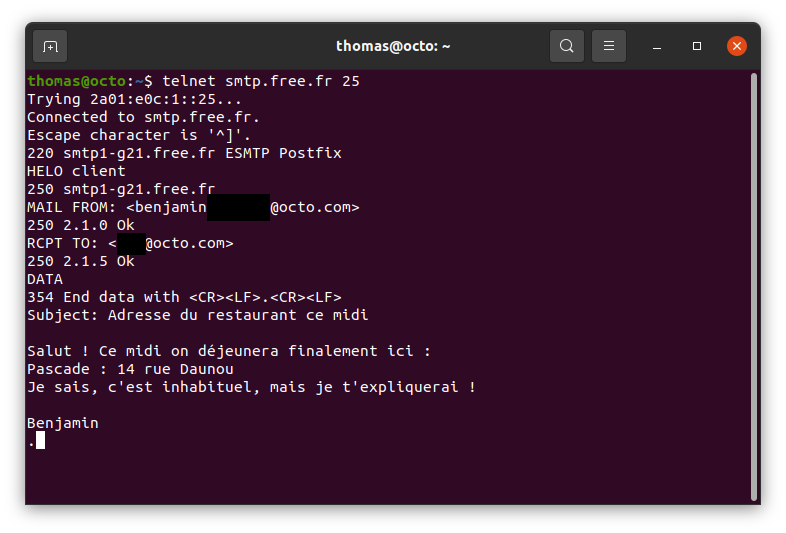
Grâce à cette dernière, prenons deux premières photos : un dessin de voiture et un dessin de brosse à dent par exemple. On laissera au lecteur le soin de déterminer quelle figure représente quel dessin.
On obtient les images en figure 2 :
Fig 2 : Exemples de photographies issues de la caméra
Par défaut, les images sont de dimension (160, 120, 3), mesures qui correspondent à la largeur, la hauteur et les trois niveaux de couleur RGB de la photo. Comme les dimensions d’image en entrée de notre réseau de neurones est de (128,128,3), nous proposons de redimensionner les deux images obtenues précédemment et essayons de faire une inférence.
Si le modèle prédit la bonne classe pour la brosse, il n’arrive pas à détecter la voiture, malgré la qualité indéniable du dessin. Pour comprendre ce défaut, il nous faut regarder les différences entre les données de production (la photo) et les données d’entraînement (les images QuickDraw).
La figure 3 compare les niveaux de gris d’une photo à ceux d’une image d’entraînement. Rappelons que le dataset d’entraînement est composé de traits noirs effectués sur le fond blanc d’un écran mobile. Ainsi, l'image qui en résulte sera composée majoritairement de pixels blancs (valeur 255) et de quelques pixels noirs (valeur 0). En revanche, les images à l’inférence proviennent d’une photo de dessins. En fonction de la luminosité ambiante, et quand bien même le dessin est sur fond blanc, le rendu propose plusieurs nuances de gris. En effet, on constate sur la figure 3 que l’image de production n’a pas du tout la même distribution de nuances de gris qu’une image d’entraînement ; elle est globalement plus sombre, et n’a pas vraiment de pixel blanc.
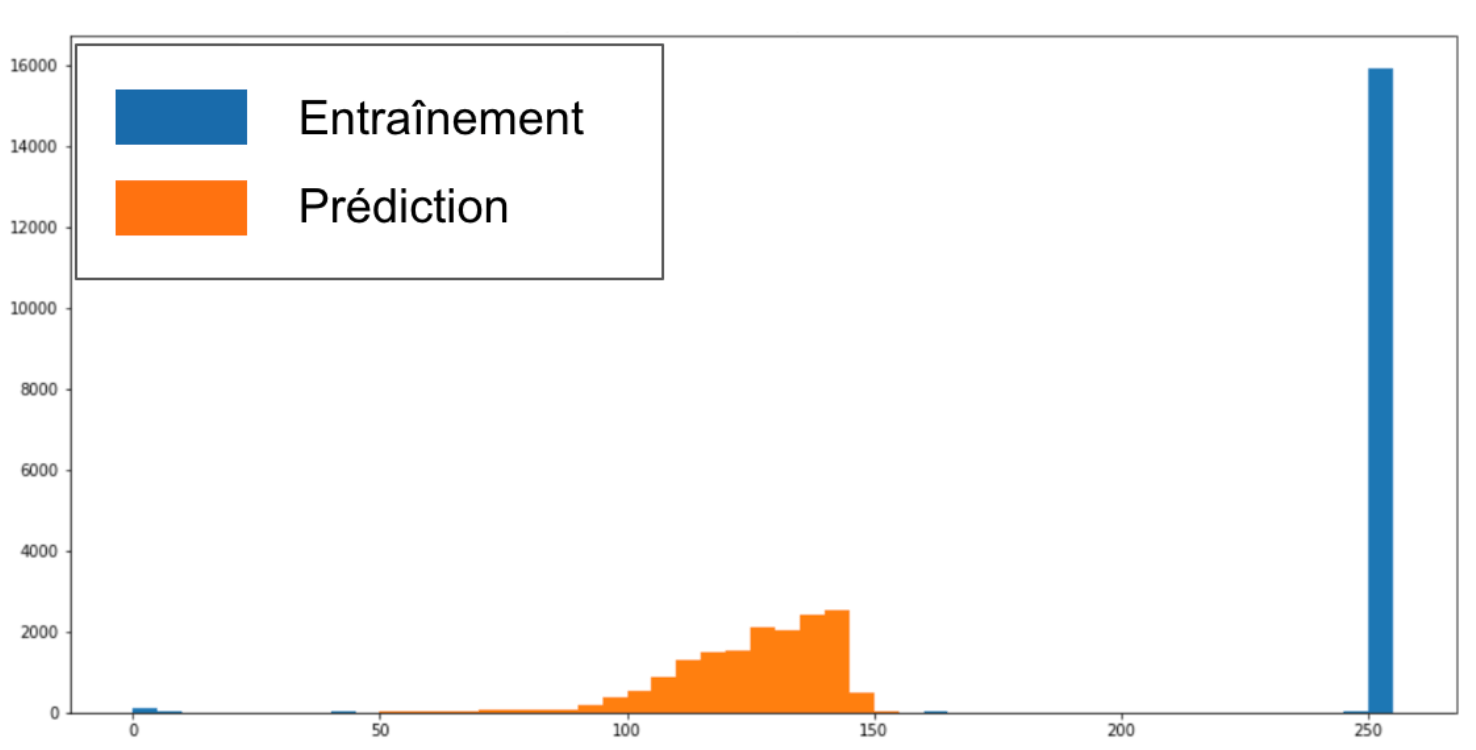
Fig 3 : Histogramme des valeurs de pixel entre une image d’entraînement et une image de production
Or le modèle ne peut pas généraliser sur des données trop éloignées par rapport à ce qu’il a vu en entraînement. Un dessin de voiture trop sombre ne saurait être inféré en “voiture” si le modèle n’a pas eu accès à ce type d’exemple durant la phase d’entraînement. On propose donc un preprocessing simple : convertir la photo en noir et blanc et déterminer une valeur seuil pour le noir et le blanc. Les pixels dont la valeur est inférieure (respectivement supérieure) à ce seuil auront comme nouvelle valeur 0, c’est à dire noir (respectivement 255), c’est à dire blanc.
En appliquant au dessin de voiture ce traitement avec un seuil empiriquement défini à 100, la distribution correspond à celle des données d’entraînement et notre modèle donne la bonne réponse. Nous appliquons alors le même seuil pour toutes les photos prises.
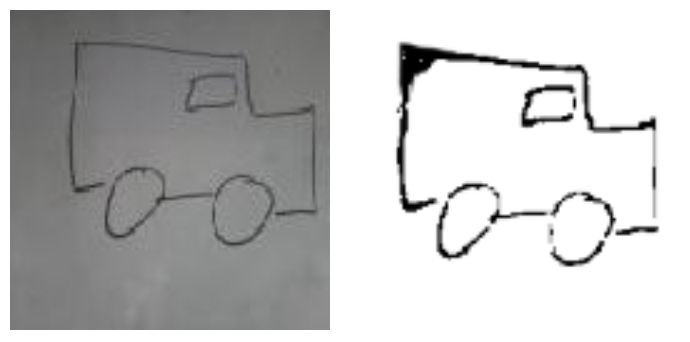
Fig 4 : Le modèle se trompe sur l’image de gauche et prédit correctement pour l’image traitée à droite
L’intégration est aussi une affaire de User Experience
L’utilisation du modèle nécessite des connaissance sommaires en python et ne propose pas une intéraction fluide. Idéalement, nous souhaiterions avoir une petite application. Cela nous permettrait de calculer des inférences sans avoir recours à une ligne de code, ce qui peut rebuter un utilisateur peu technophile, ni en développant tout un frontend, ce qui s'avère coûteux. Les écrans applicatifs, pour ce parcours utilisateur, sont représentés figure 5.
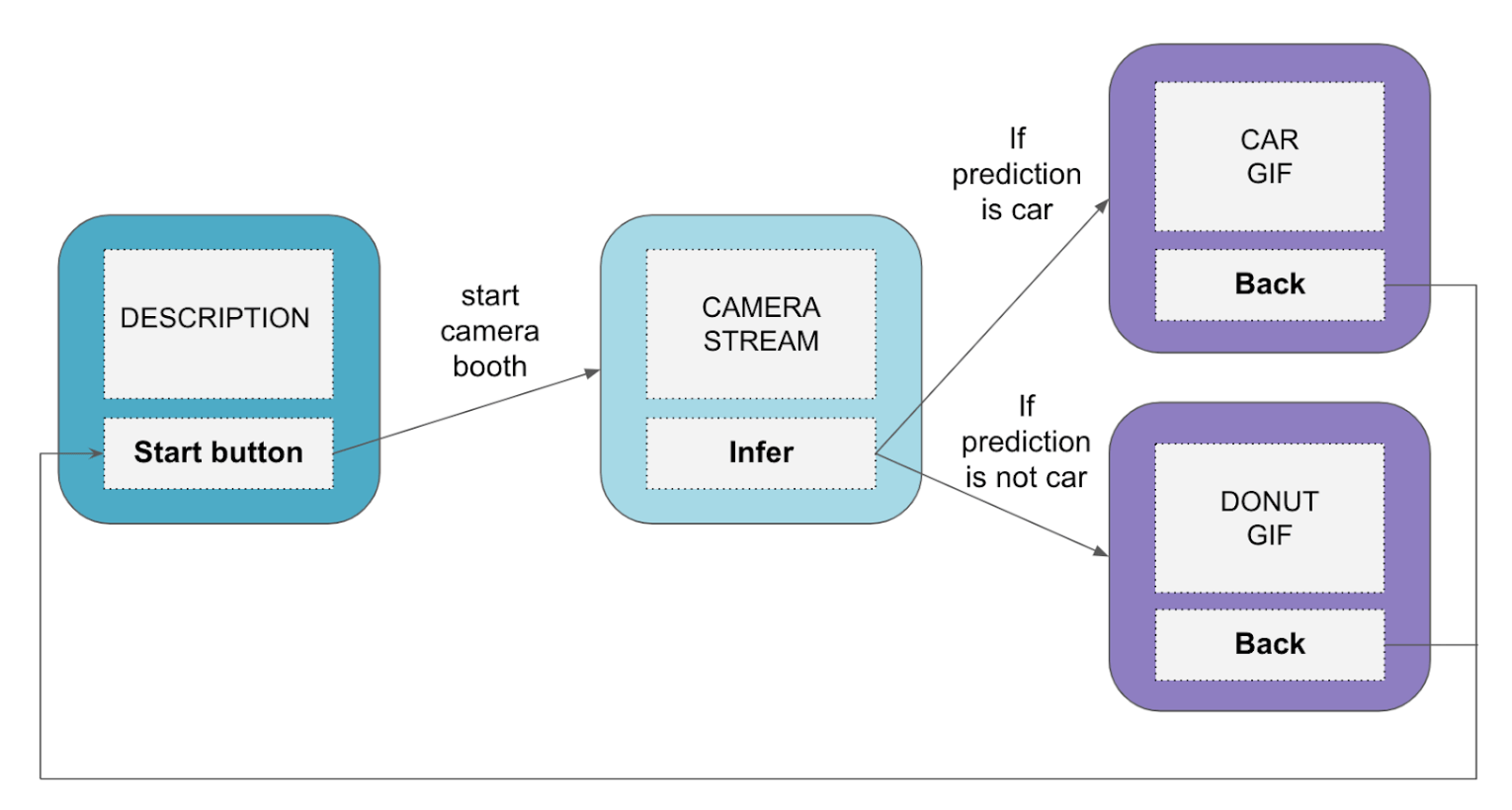
Fig 5 : Schéma des écrans et des dépendances
Il y a trois écrans :
- Une page d’accueil : Elle a pour but d’expliquer le fonctionnement et le but de l’application. Elle propose un bouton “start” qui permet de passer au second écran
Fig 6 : Un accueil en Comic Sans
- Un photo booth : Une fenêtre affiche le flux vidéo en provenance de la caméra. L’utilisateur peut bouger la caméra et voit le flux correspondant à l’écran. Il positionne la caméra au dessus du dessin qu’il souhaite photographier, et une fois prêt, il peut cliquer sur un bouton “infer” qui renvoie au troisième écran

Fig 7 : Flux vidéo positionné sur la feuille avec dessin (de tour Eiffel)
- Un GIF : Le modèle fait une inférence sur la photographie et si la prédiction est “voiture”, le troisième écran affiche un GIF de voiture. Sinon, il affiche un GIF de donut. Un bouton “back” permet de revenir à la page d’accueil
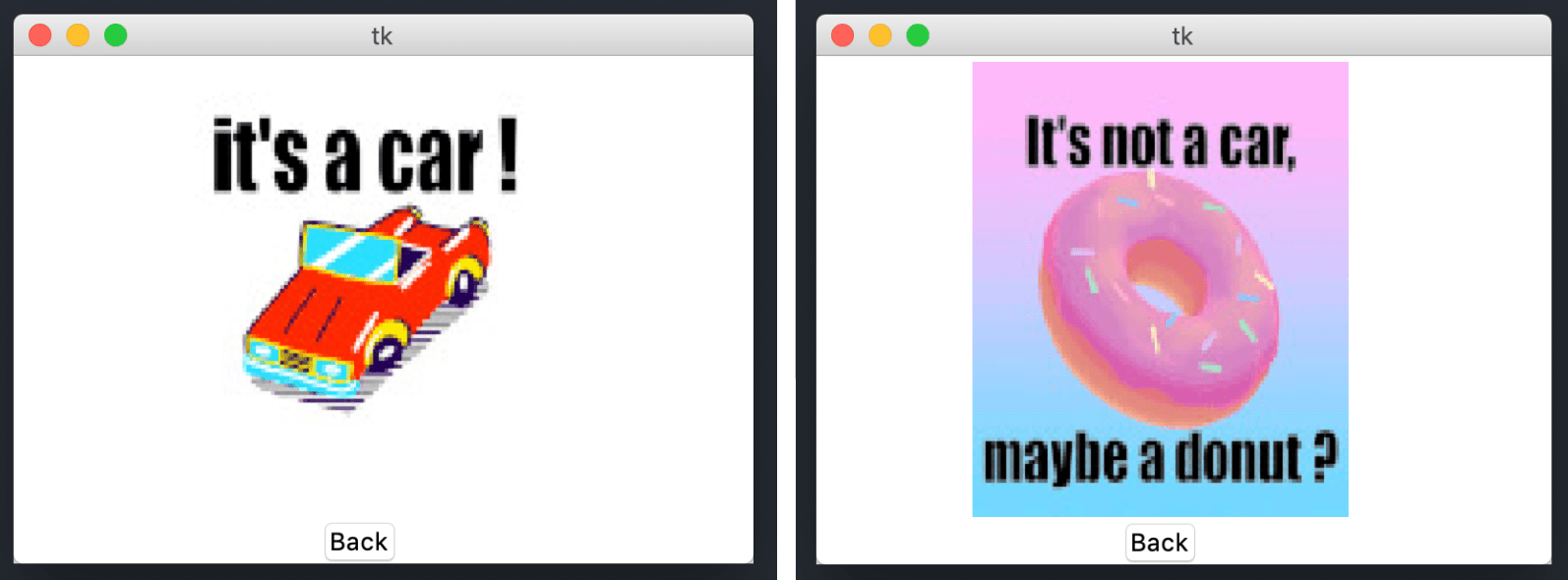
Fig 8 : Un aperçu des deux GIF
En déployant le modèle directement sur le Raspberry, nous avons pris le parti de l’embarqué. Suivant cette logique, nous allons développer l’application en client lourd.
Le code est disponible et open source sur ce repo github. Si vous le souhaitez, vous pouvez cloner le repo, et tester en local si votre ordinateur est muni d’une webcam. Le but n’est pas de rentrer dans l’ensemble des détails de l’implémentation. Il s’agit en revanche de notre premier projet sur Tkinter et nous souhaitons nous attarder sur plusieurs points précis.
- Les frames. Avec Tkinter, chaque écran est chargé par l’application. En revanche, seul l’écran au premier plan est visible via l’interface. Ainsi, nous changeons l’ordre de superposition des planches, via la commande raise
- La caméra. Nous l’évoquions précédemment, il existe de multiples façons d'interagir avec la caméra du Raspberry. L’inconvénient majeur de la librairie Picamera réside dans le fait qu’elle fonctionne difficilement avec d’autres caméras que celle du Pi. Nous avons décidé d’utiliser la librairie OpenCV et sa fonction VideoCapture. Elle nous permet de travailler avec toute caméra définie par défaut sur le système qui exécute le code. Cela nous permet de développer avec la webcam d’un ordinateur portable par exemple
- Le flux vidéo : le rafraîchissement du flux vidéo n’est pas géré dans un thread à part. Toutes les millisecondes, on capture une photo de ce que voit la caméra, que l’on stocke en mémoire vive, et on l’affiche (Il n’y a pas d’écriture sur le disque, ce qui dégraderait significativement les performances). Ce fonctionnement n’est certes pas optimal mais permet d’avoir un flux vidéo suffisamment fluide, tout en permettant une bonne exécution du reste du code
- L’affichage des GIF : au départ, l’affichage des GIF devait se faire sur deux pages différentes. Pour chacun, il fallait gérer un affichage permanent avec mise en boucle des images du GIF. Nous avons pensé utiliser la même méthode que pour le flux vidéo. Cependant, avoir trois boucles vidéos ralentissait sensiblement chacun des affichages. Une solution consiste à n’afficher qu’un seul GIF, le choix de celui ci étant déterminé par l’inférence au moment du “chargement” du troisième écran
Limites du modèle et de l’approche
Nous avons pu tester de nombreuses configurations pour voir les limites du modèle et éprouver ses limites.
Tout d’abord, comme il est coutume de dire en Machine Learning, suivant l’intuition du statisticien George Box : “Tous les modèles sont faux, certains sont utiles”. Compte tenu de la diversité de dessins que le modèle a eu en entraînement, notamment pour des exemples de non voitures, il est assez simple de trouver un dessin qui le mette en défaut. Un de ces exemples est en figure 7. Ce dessin de lunettes, avec des verres ronds, pousse le modèle à prédire qu’il s’agit d’une voiture. Il semblerait que l’agencement et la forme des verres induisent le modèle en erreur.
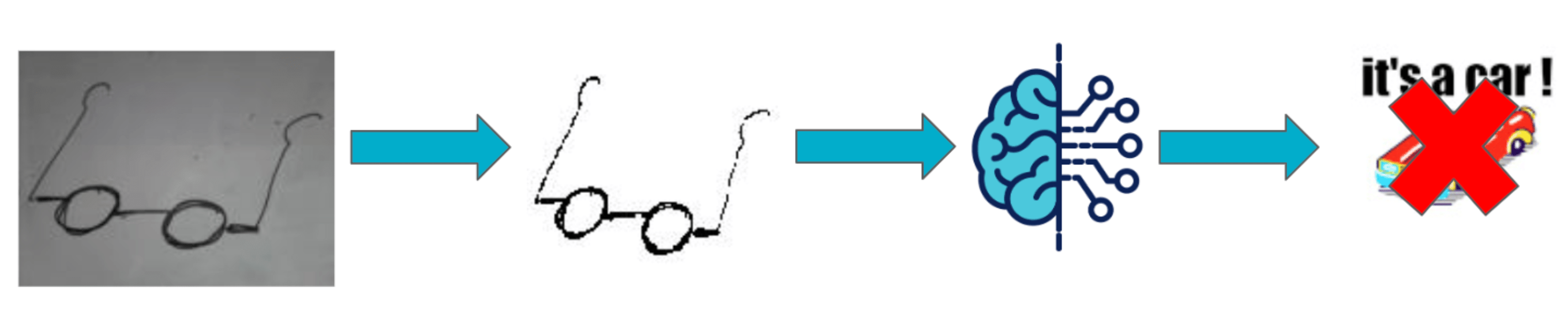
Fig 9 : Un dessin de lunettes met en défaut le modèle
En revanche, nous avons pu constater que le modèle pouvait être mis en défaut par des problèmes de mise en scène. Sur la figure 10, on constate que le dessin en entrée est une voiture. En revanche, le preprocessing tend à rendre les traits trop fins. À certains endroits, ils ont même disparu ! Pour ce même dessin, en forcissant les traits, nous obtenons une prédiction correcte. Ainsi, l’épaisseur des traits est un paramètre influant la prédiction.

Fig 10 : Un dessin de voiture avec des traits trop fins met en défaut le modèle
Enfin, la conversion de l’image peut introduire des artefacts indésirables. Comme le seuil de conversion en noir et blanc est arbitraire, il se peut que certaines zones sombres soient converties en noir. La figure 11 illustre cela sur le quart haut droit de l’image après preprocessing. Le modèle prédit qu’il ne s’agit pas d’une voiture. À l’inverse, une photo mieux éclairée du même dessin conduit le modèle à prédire la bonne classe.

Fig 11 : Une mauvaise luminosité met en défaut le modèle
Pour le premier type d’erreur, nous ne pouvons pas faire mieux que trouver davantage de données d’entraînement (par exemple ajouter des exemples variés de dessin “non voiture”). Néanmoins, nous constatons qu’avec les deux autres types d’erreur, le mode d’acquisition de la donnée n’est pas robuste. Enrichir le dataset par ce biais est donc dangereux puisqu’on pourrait introduire du bruit. Comment peut-on s’approcher au mieux des données d’entraînement en production ?
Le Pi a aussi droit à son écran tactile
Nous n’avons pas résisté à la tentation de tester ce cas d’usage avec un autre accessoire du Raspberry : un écran tactile. Surtout qu’il coûte moins de 30 euros ! L’installation demande un peu de configuration, mais reste somme toute accessible.
Le lecteur curieux aura remarqué que le code est disponible au même repo github. L’ossature de l’application étant la même, il suffit simplement d’adapter la page qui affiche le flux vidéo à un canevas qui permet de dessiner avec la souris (ou le stylet pour l’écran tactile). L’acquisition de donnée et son rendu sont illustrés en figure 12.
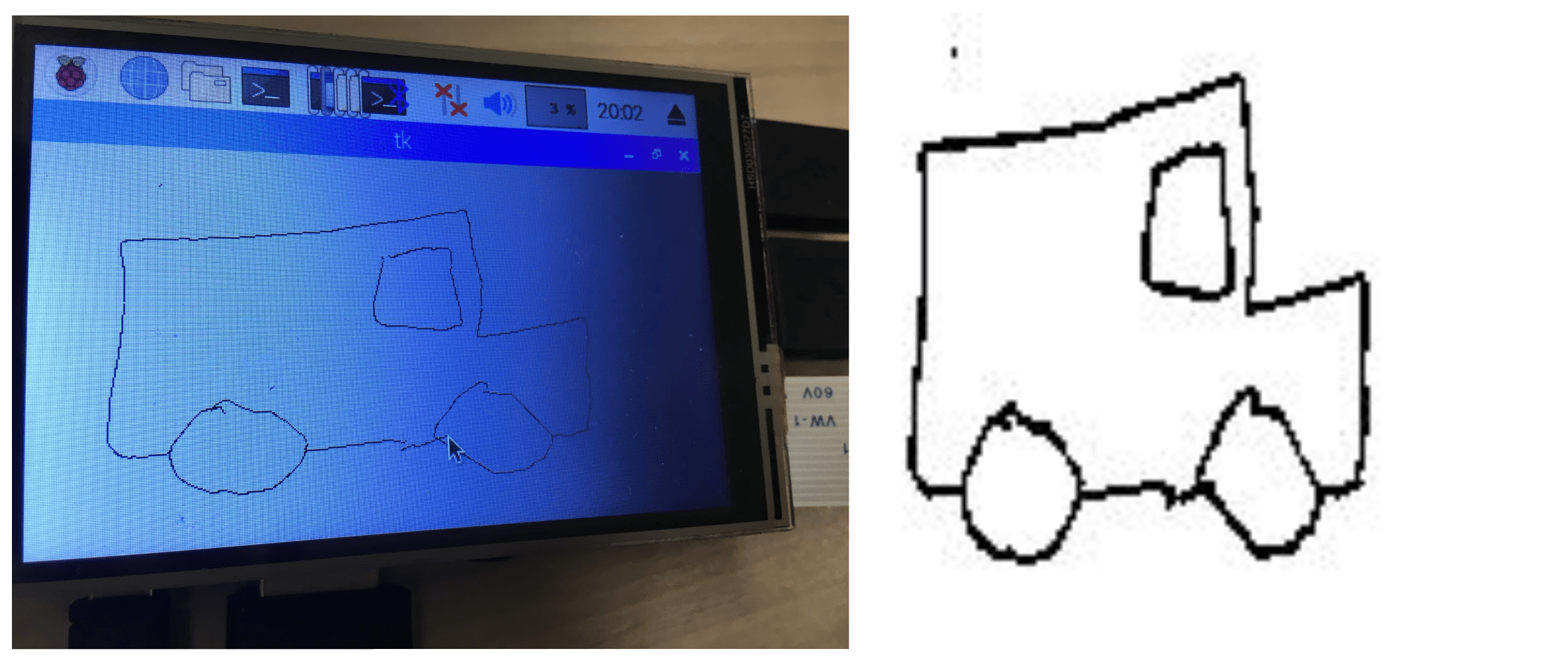
Fig 12 : Un exemple de dessin sur l'écran tactile, et le rendu
Nous n’avons donc plus les problèmes d’ajustement de la luminosité ! Nos conditions de génération de données en production semblent être proches de nos conditions de génération de données d’entraînement. Et pourtant… le modèle semble encore faire des siennes, comme illustré en figure 13.
Fig 13 : Ceci n’est pas une brosse à dent
Investiguer les limites du modèle
La visualisation est consubstantielle à notre problème puisque nous travaillons avec des images. Nous avons pu découvrir une démarche pour interpréter la prédiction d’un réseau de neurones sur la base d’image, et nous vous proposons les prémisses de cette démarche. L’API de Keras permet d’aller chercher les poids des paramètres (i.e. les valeurs comprises entre 0 et 1 déterminées grâce à la phase d’entraînement) pour chaque neurone. Ainsi on peut afficher la sortie de chaque couche de convolution (ce sont des filtres pour notre image d’entrée), qu’on appellera activations.
Pour ne pas s’embêter à effectuer les calculs tensoriels à la main, Keras préconise de créer un modèle ayant en sortie chacune des couches puis de calculer la prédiction pour image en entrée.
from keras.models import Model
layer_outputs = [layer.output for layer in self.model.layers]
activation_model = Model(inputs=self.model.input, outputs=layer_outputs)
activations = activation_model.predict(image)
Les résultats obtenus pour un dessin de saxophone sont les suivants :
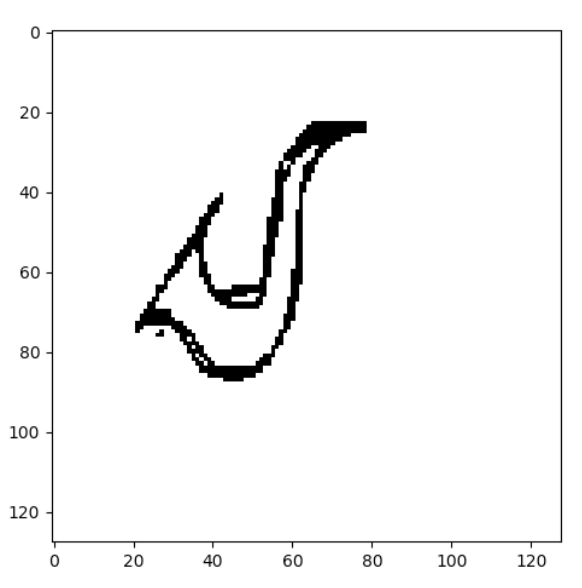
Fig 14 : Image en entrée du réseau


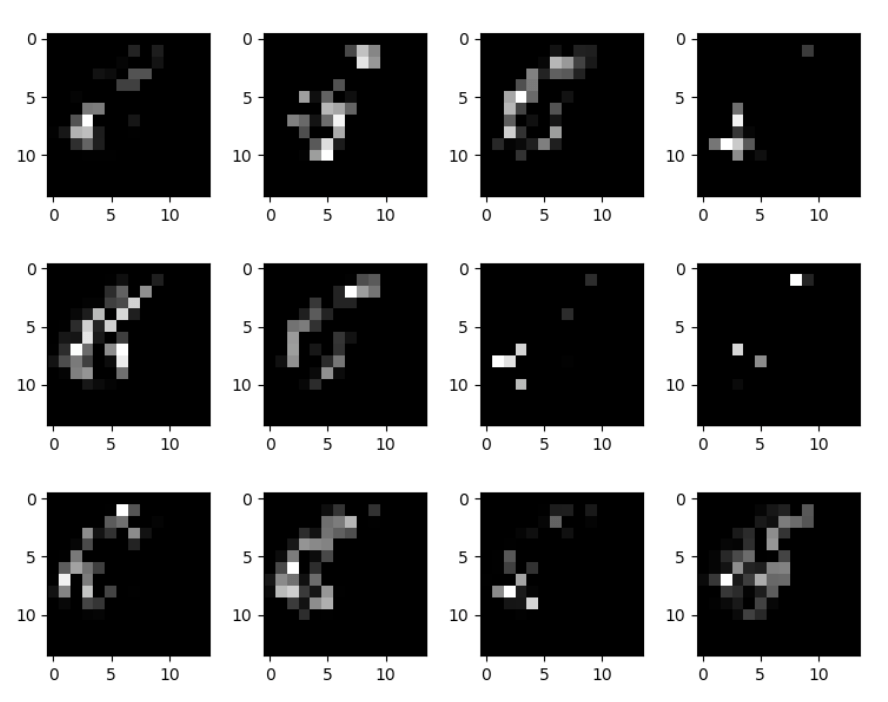
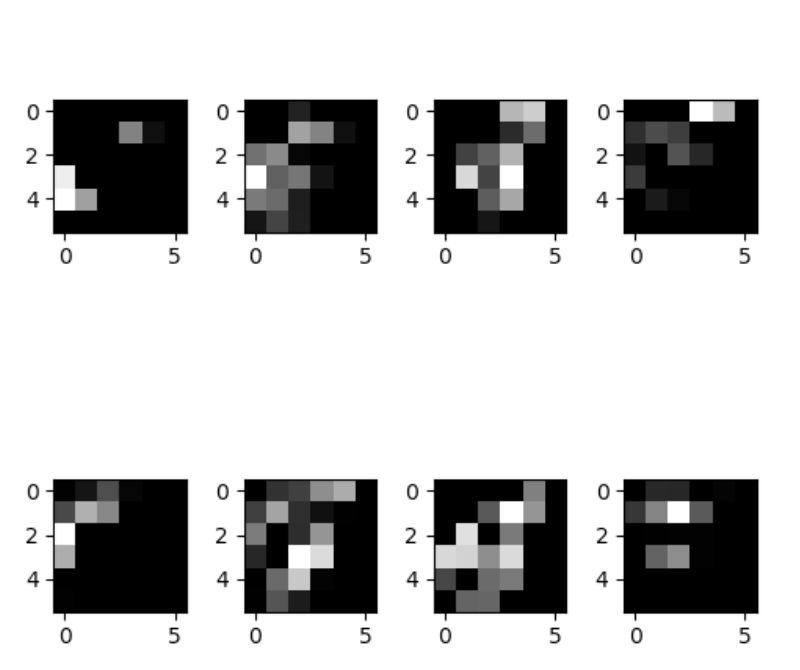
Fig 15 : Les activations de l’image Fig. 14
On remarque que dans la première couche, les activations retiennent presque toute l’information contenue dans le contours du saxophone. Plus on descend profondément dans le réseau, plus les activations deviennent abstraites et de ce fait plus difficilement interprétables. Ce sont des features haut niveau qui permettent au réseau de déterminer par activations successives que le saxophone n’est pas une voiture. On voit apparaître certaines zones. Il y a de moins en moins d’information sur le contenu visuel de l’image et de plus en plus d’information agrégée. Le réseau est entraîné pour que ces réductions de dimensions (les features maps successives ci-dessus) apporte une représentation d’information discriminante pour déterminer la classe de l’image en entrée. Finalement, la dernière couche est composée d’un seul neurone représentant la probabilité d’être ou non une voiture.
En jouant avec différentes images en entrée, on pourrait chercher à identifier les patterns qui induisent en erreur le modèle. Par exemple, les deux ronds des lunettes peuvent activer les neurones ayant retenu l’information des roues de voitures et donc “pousser” la prédiction vers “voiture”.
Le mot de la fin
En conclusion de cette troisième partie, nous avons vu qu’un modèle de Deep Learning est aussi bon que la diversité et la qualité des données d’entraînement le lui permettent.
L’intégration d’un modèle à une application est relativement simple. En revanche les données sur lesquelles nous souhaitons faire des inférences, en production donc, peuvent être sensiblement différentes des données d’entraînement. Nous l’illustrons ici avec des dessins réalisés sur des téléphone mobiles par rapport à des photos de dessins faits à la main. C’est aussi vrai dans un processus industriel où les variables descriptives d’un problème peuvent évoluer au cours du temps. Cette évolution de la distribution des données en entrée peut perturber le modèle. Il n’y a pas de magie en Machine Learning : le modèle générera sa prédiction en se basant sur ce qu’il a vu en entraînement. Ici l’adage garbage in, garbage out prend tout son sens.
Nous avons cherché à utiliser une méthode d’acquisition qui fournissent des données de production plus proches des données d’entraînement, en utilisant un écran tactile. Il est intéressant de noter qu’il s’agit du même modèle utilisé par les deux applications. Malheureusement, le modèle semble toujours avoir du mal avec certain type de prédiction. Par exemple, il a l’air d’être très sensible à la représentation d’une brosse à dent ! S’offrent à nous deux solutions :
- Investiguer ce qui fait dans l’architecture neuronale que la prédiction est fausse. Cela permettrait de nous aiguiller sur une évolution de l’architecture. Bien que séduisante, cette solution n’est pas la plus simple
- Fournir davantage d’images d’entraînement au modèle. Avec ce déploiement, il est facile de faire évoluer l’application : on peut proposer comme écran “le modèle pense que c’est une voiture/que ce n’est pas une voiture. Êtes vous d’accord ?”. Ainsi l’utilisateur donnerait son feedback immédiat, ce qui permettrait de labelliser un nouveau dataset. Nous pourrions ensuite réentraîner le modèle en combinant ce nouveau dataset à celui existant ; il y aurait ainsi des données d’entraînement issues directement de la production.
Ce troisième article conclut la série “L’IA embarquée : entraîner, déployer et utiliser du Deep Learning sur un Raspberry”. Nous avons pu découvrir les différentes difficultés à déployer un réseau de neurones sur un Pi ne sont pas nécessairement celles que l’on pense. Entraîner un modèle est finalement assez anecdotique avec les frameworks actuels. En revanche, il est nettement plus compliqué de maîtriser l’environnement de déploiement. Nous vous donnions le secret de la réussite lors de notre matinale Levez la malédiction du passage de l’IA en production : commencer par intégrer des modèles simples, voire des moteurs de règles ! En utilisant le découpage logique et la méthodologie décrite, il est désormais possible d’itérer rapidement sur le modèle pour améliorer la performance de prédiction, par exemple en enrichissant le dataset d’entraînement.