L’IA embarquée : entraîner, déployer et utiliser du Deep Learning sur un Raspberry (Partie 2)
Dans cette série d’articles, on se propose d’étudier le cas d’usage de reconnaissance de dessins grâce à un Raspberry. L’idée est d’utiliser la caméra d’un Raspberry pour capturer une image représentant un dessin, et déterminer grâce à un réseau de neurones s’il s’agit d’une voiture ou non. Dans un premier article, on a entraîné un réseau de neurones performant à l’aide du framework Keras. Le résultat est un objet Python - le modèle - sauvegardé en format .h5. Comment faire pour l’utiliser sur un Raspberry Pi ? C'est précisément ce qui nous a fait défaut lors d'une course IronCar. L'environnement d'entraînement du modèle ne correspondait pas à l'environnement de prédiction : le modèle était inutilisable ! Nous souhaitons présenter ici une approche que nous avons développée afin d'éviter de reproduire ce genre d'erreurs.
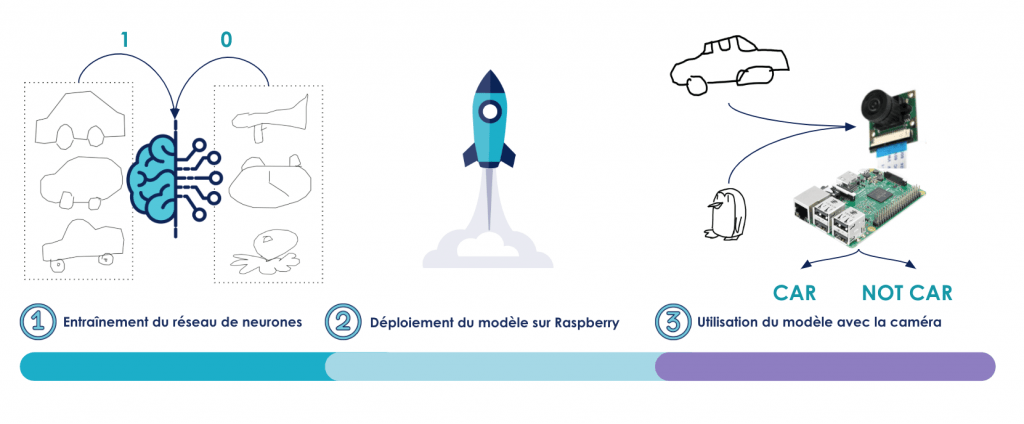
Fig 1 : Schéma de présentation du cas d’usage en trois étapes
Partie 2 : déployer un réseau de neurones sur Raspberry Pi
Déployer un modèle de deep learning sur une machine est une problématique qui montre qu’un projet de data science ne se limite pas à l’aspect modélisation / machine learning. C’est une tâche critique, et on souhaite que le déploiement soit au maximum automatisé pour assurer sa reproductibilité (par exemple lorsqu’on publie de nouvelles versions du modèle).
La complexité du déploiement est ici double puisque nous souhaitons exploiter le modèle sur un Raspberry Pi alors que l’entraînement s’est fait sur une machine totalement différente !
Le Raspberry Pi : un ordinateur pas comme les autres
Un Raspberry Pi est un ordinateur low cost (environ 35 euros pour le modèle utilisé) de la taille d’une carte de crédit. Il dispose des fonctionnalités principales de tout ordinateur à une échelle plus réduite. Cela entraîne un certain nombre de changements structurels sur ses composants pour répondre aux contraintes de prix, de taille et de consommation (l’appareil est alimenté par un chargeur micro-USB, comme la plupart des smartphones). Ainsi, lorsqu’on trouve habituellement des processeurs à architecture x86 dans les ordinateurs “classiques”, le Raspberry Pi embarque un CPU à architecture ARM. En effet, les processeurs ARM ont un mode de fonctionnement différent des x86. Ils privilégient les instructions simples minimisant le nombre de cycles CPU. En d’autres termes, un processeur ARM aura tendance à être moins performant mais aussi moins gourmand en énergie : c’est le parti pris du Raspberry Pi.

Fig 2 : Un Raspberry Pi 3 avec une PiCamera, l’appareil utilisé
Ce changement n’est pas sans conséquence pour l’utilisateur : faire tourner du code sur le Pi demande d’utiliser des bibliothèques adaptées pour le processeur ARM puisque ce n’est plus le même jeu d’instructions qui tourne dessous. Cela commence par le système d’exploitation utilisé par le Pi. La distribution la plus commune est Raspbian : distribution officielle dérivée de Debian et optimisée pour les spécificités du Raspberry. Elle est disponible par défaut à l’achat.
Assurer le bon fonctionnement des librairies utilisées pendant l’entraînement
Résumons un peu la situation : nous avons entraîné un modèle grâce à Keras sur Tensorflow tournant dans le cloud, sur une machine ayant un processeur x86 et nous devons à présent charger ce modèle sur une architecture de processeur qui n’est plus du tout la même. L’OS n’est pas non plus identique puisque nous avons désormais une distribution Raspbian. Cependant, cette distribution a l’avantage d’être très proche de celle utilisée pour l’entraînement puisque basée sur Debian. Il y a donc une première problématique sur la reproduction de l’environnement pour faire tourner Keras : inutile de tenter d’utiliser les mêmes paquets standards que sur la machine AWS, l’installation échouera.
Fig 3 : Notre problématique : deux systèmes différents, comment déployer un modèle de l’un vers l’autre ?
Heureusement pour nous, des outils ont été développés par la communauté pour permettre de compiler et installer nos paquets (notamment Tensorflow) de façon à pouvoir les utiliser sur un processeur ARM. En faisant attention au type de bibliothèques à installer et dans la mesure où la version ARM est disponible, il nous est possible d’utiliser des alternatives aux bibliothèques standards pour charger le modèle sur le Raspberry Pi.
Vers l’automatisation du déploiement avec Ansible
Le déploiement de l'environnement consiste en une suite de tâches à exécuter strictement séquentiellement. Il s’agit principalement d’installation de paquets Python, avec les versions correspondant† à l’environnement d’entraînement. Pour exécuter ces tâches, nous proposons d’utiliser Ansible, dans une logique d’Infrastructure as Code (IaC), présentée et illustrée dans le livre blanc Culture Devops 2. Ansible est un utilitaire qui permet d’automatiser l’exécution de tâches sur une machine distante via SSH. Pour décrire chacune de ces tâches, Ansible utilise des fichiers yaml : les playbooks. Ces playbooks sont du code ; on peut ainsi décrire les tâches par du code - que l’on peut versionner - pour pouvoir maîtriser dans le temps l’industrialisation du déploiement de notre environnement.
Ainsi nous allons utiliser une machine pour envoyer puis exécuter une succession de tâches d’un playbook Ansible sur une machine cible, en l’occurrence notre Raspberry Pi. Pour cela, nous devons disposer physiquement du Raspberry, qu’il soit allumé et connecté au même réseau que la machine de contrôle Ansible. Ces contraintes ne permettent pas un feedback rapide sur ce que nous faisons, dans une logique itérative. Nous nous sommes donc demandés s’il était possible de travailler sur une seule machine en créant un Raspberry virtuel sur le serveur Ansible.
Une boucle de feedback réduite en émulant et en configurant le Raspberry en local
L’une des solutions que nous proposons pour éviter de devoir sans arrêt interagir avec le Raspberry physique consiste à émuler son architecture et configurer directement l’image Raspbian en local. En effet, la seule chose qui nous intéresse, c’est que le file system soit correctement configuré pour le démarrer depuis notre Pi.
En clair, on se propose d’émuler l’architecture du Raspberry, démarrer une image Raspbian et la configurer via Ansible pour pouvoir la mettre ensuite directement sur la carte micro SD qu’on insérera dans le Raspberry physique. Il n’y aura plus qu’à booter sur cette image pré-configurée pour avoir le modèle prêt à l’emploi : plug and play.

Fig 3 : Schéma du pipeline de déploiement en émulant un processeur ARM en local
Cette approche a l’avantage de pouvoir exécuter tout le pipeline d’entraînement et de déploiement sur une machine et reporte la complexité sur un seul type de machine connu. Elle limite les interactions physiques avec le Raspberry en ne l’utilisant qu’en tant que système embarquant un file system pré-configuré. Il faut néanmoins commencer par l’émulation du Raspberry en local !
Émuler l’architecture ARMv7 avec QEMU
Pour réaliser cette première tâche, nous allons utiliser un outil, QEMU, qui permet d’émuler des processeurs aux architectures différentes depuis une machine x86. Sur Ubuntu, il s’installe à l’aide d’apt install et dispose d’un bon nombre d’utilitaires. Celui qui nous intéresse est : qemu-system-arm.
Pour émuler un système ARM avec cette commande, il faut lui fournir un certain nombre de paramètres :
- Un type de processeur à émuler (dans notre cas la famille de processeurs Cortex-A9 est adaptée puisqu’elle utilise un jeu d’instructions ARMv7)
- Un kernel
- Un fichier dtb (Device Tree Blob, il contient une description des composants hardware mis à disposition du kernel)
- Un file system, que l’on récupère ici dans le cas de Raspbian
- Des paramètres du système (la mémoire allouée, les redirections de ports, etc.)
On voit que cela fait un nombre conséquent de paramètres à préciser et de fichiers à fournir en entrée. Certaines implémentations disponibles sur Github pour émuler Raspbian sur ARM avec QEMU ont été réalisées par la communauté et fournissent les fichiers nécessaires. Cependant, ces commandes émulent des architectures ARMv6 alors que notre Raspberry (le modèle 3b+) fonctionne avec ARMv7 : un changement qui paraît mineur mais qui empêcherait en fin de pipeline d’installer la bonne version de Tensorflow pour ARM. Il va donc falloir trouver les fichiers appropriés pour émuler de l’ARMv7, en l’occurrence le kernel et le fichier dtb (le file system correspond à l’image Raspbian de base).
Fig 4 : Entrées et sortie de QEMU pour faire tourner Raspbian sur ARMv7
Un kernel ARMv7 pour QEMU sur-mesure grâce à Buildroot
Il est difficile, si ce n’est impossible, de trouver ces deux fichiers tels qu’on les attend sur Internet : nous sommes sur une utilisation très spécifique. Cependant, on parle ici de kernel Linux, rien ne nous empêche donc de construire notre propre kernel ! Un des utilitaires rendant facile la compilation de ces fichiers est Buildroot, spécialisé dans le build de systèmes Linux sur mesure pour l’embarqué. La deuxième bonne nouvelle, c’est qu’il vient avec de nombreuses configurations prédéfinies pour les systèmes les plus courants (y compris ARMv7 sur QEMU). Il suffit ainsi de deux commandes pour construire le kernel et le DTB nécessaires une fois l’archive téléchargée :
wget http://www.buildroot.org/downloads/buildroot-2019.02.tar.bz2
tar xf buildroot-2019.02.tar.bz2
cd buildroot-2019.02
# Commandes QEMU
make qemu_arm_vexpress_defconfig
make
Après un certain temps (on recompile tout un kernel Linux), plusieurs fichiers sont produits en sortie, notamment le kernel et le DTB. Il ne reste plus qu’à lancer QEMU en utilisant ces derniers :
qemu-system-arm \
-M vexpress-a9 \
-m 1024 \
-smp 4 \
-kernel files_to_use/zImage \
-dtb files_to_use/vexpress-v2p-ca9.dtb \
-sd files_to_use/2018-11-13-raspbian-stretch-lite.img \
-append "console=ttyAMA0,115200 root=/dev/mmcblk0p2" \
-serial stdio \
-net nic -net user,hostfwd=tcp::2222-:22
NB : Pour ce qui est des paramètres supplémentaires, une explication synthétique :
-M vexpress-a9: on émule une architecture Cortex A9 supportant ARMv7-m 1024: on alloue 1024 Mo de mémoire vive à notre système-smp 4: on alloue 4 coeurs à notre système-append "...": il s’agit des commandes à lancer au boot-serial stdio: on spécifie la sortie pour afficher dans notre terminal-net …: on permet l’accès à Internet et on redirige le port 22 (SSH) sur le port 2222 de l’hôte pour pouvoir s’y connecter en SSH.
Si tout se passe bien, Raspbian démarre en console (sans interface graphique). Nous pouvons nous connecter grâce aux identifiants par défaut. Vérifions que nous avons bien réussi à émuler un environnement ARMv7 :
Fig 4 : cat /proc/cpuinfo sur la machine émulée
On a bien un processeur de modèle ARMv7, notre image Raspbian tourne en local comme elle le ferait sur un Raspberry Pi. Il convient maintenant de la configurer proprement avec nos librairies et notre code avant de la mettre sur la micro-SD du Pi pour un test grandeur nature.
Configurer le Raspberry via Ansible
Il reste cependant une dernière étape avant de pouvoir lancer la configuration : notre machine virtuelle doit être accessible par SSH, c’est le protocole utilisé par Ansible pour exécuter les tâches en distantes. La démarche est la suivante :
- Activer le service SSH (soit via l’interface
sudo raspi-configsoit directementsudo systemctl enable ssh) - Mettre le mot de passe à jour (Raspbian refuse les connexions SSH tant que le mot de passe par défaut n’est pas changé).
Pour vérifier que la configuration est conforme, tentons de nous y connecter depuis l’hôte en utilisant la redirection du port 22 faite en lançant QEMU :
ssh -p 2222 pi@localhost
Après avoir entré le mot de passe, nous arrivons sur le bash de Raspbian : SSH est désormais activé et prêt à être utilisé par Ansible !
Le playbook Ansible que nous utilisons pour la configuration est disponible ici. Pour expliquer de manière succincte ce qu’il exécute, en voici les principales étapes :
- Installations des librairies C nécessaires aux librairies Python que nous allons ensuite installer
- Installation du wheel de Tensorflow, spécialement packagé pour un ARMv7
- Installation des librairies python, et notamment Keras dans la version 2.2.4, version de l’environnement d’entraînement. On installe également Pillow, pour permettre la lecture d’image stockées sur le filesystem.
Exporter et exploiter l'image construite
QEMU rend persistantes les modifications à l’image. Ainsi, à la fin de l’exécution de notre playbook, le fichier d’origine “2018-11-13-raspbian-stretch-lite.img” contient l’ensemble des paquets nécessaires à l’utilisation de notre modèle.
On peut donc également copier le modèle, ainsi que deux images, l’une représentant une voiture, l’autre représentant un avion, directement sur le Raspberry simulé. On peut le faire via une tâche Ansible, ou même scp.
Il nous faut admettre ici que nous avons rencontré un obstacle de taille : bien que l’environnement soit bon, et le modèle disponible sur le Raspberry, il nous a été impossible de faire une inférence sur le Raspberry simulé. L’exécution s’arrête avec un message énigmatique : “Illegal instruction”. Cela nous a empêché par exemple de tester via du code le déploiement de l’environnement. Nous avions à l’esprit d’écrire des tests Molecule, un framework de test pour les rôles Ansible, qui auraient vérifié la capacité à charger le modèle et à faire une inférence correcte.
En revanche, nous pouvons vérifier manuellement que tout fonctionne. L’utilitaire dd nous permet de copier le disque représenté par “2018-11-13-raspbian-stretch-lite.img” sur une carte SD, que l’on insère dans un Raspberry physique.
Test d’intégration : peut-on faire une inférence ?
À la mise en tension du Raspberry, le système d’exploitation boot et nous pouvons nous identifier. Le file system contient les fichiers que nous avons copiés. Nous exécutons alors le code suivant, grâce à un interpréteur python3.
import numpy as np
from PIL import Image
from keras.models import load_model
model = load_model('/path/to/model_tres_performant.h5')
img_car = Image.open('/path/to/car.jpg')
img_car_array = np.array(img_car).reshape((1, 128, 128, 3))
img_not_car = Image.open('/path/to/not_car.jpg')
img_not_car_array = np.array(img_car).reshape((1, 128, 128, 3))
# Should output 0
print(model.predict_classes(img_car_array))
# Should output 1
print(model.predict_classes(img_not_car_array))
Avec notre modèle, il faut changer la dimension du tableau de pixel d’une image : il nous faut en fait un tenseur à 4 dimensions, la première étant le nombre d’images dans le tenseur, la seconde la largeur d’une image, la troisième la hauteur d’une image et la dernière la valeur d’un pixel, ici un tuple RGB. C’est de cette représentation en tenseur que Tensorflow tire son nom.
Les librairies étant installées et disponibles, l’exécution du code ci-dessus se déroule comme convenu, et le modèle discrimine correctement une voiture d’un autre dessin !
Le mot de la fin
En conclusion de cette seconde partie, nous avons vu que le déploiement d’un modèle de Deep Learning nécessite de maîtriser le déploiement de l’environnement qui sollicite le modèle.
Dans notre cas d’étude, l’entraînement a été réalisé sur des machines à processeurs en architecture x86, alors que les processeurs du Raspberry sont en architecture ARM. Cette différence fondamentale dans les composants électroniques implique une complexité réelle dans l’adéquation entre l’environnement d’entraînement d’une part et l’environnement de production d’autre part, à savoir celui déployé sur le Raspberry. Pour faire correspondre ces deux environnements, nous avons d’abord envisagé d'interagir physiquement avec le Raspberry. Les contraintes qui en découlent, notamment sur la longueur de la boucle de feedback, nous ont poussés à émuler un Raspberry sur une machine hôte, grâce au logiciel QEMU.
Conformément aux bonnes pratiques d’Infrastructure as Code, nous avons choisi d’utiliser Ansible pour déployer la configuration idoine sur notre Raspberry et ainsi disposer d’un environnement de production conforme pour l’exploitation du modèle. Nous pouvons d’ailleurs le vérifier grâce à un test d’intégration exécuté manuellement.
Grâce aux techniques illustrées dans cette article, nous avons donc pu “mettre en production” dans un environnement particulier qui est celui du Raspberry, mais ce sujet d’environnements est un problème souvent compliqué à résoudre. On le retrouve ainsi fréquemment dans le cycle de développement puis d’industrialisation d’un projet de data science (et même de tout projet où interviennent des systèmes différents, comme lorsque le l’OS de développement en local diffère de l’OS de production).
Dans une troisième et dernière partie, nous vous proposons d’exploiter cet environnement et ce modèle dans une petite application de data science : est ce que mon dessin est un dessin de voiture ou non ?