Let's dig into SQLFire
A year ago, I promised in a previous (French) article to test the ability to migrate a standard Hibernate/SGBRD application to a NewSQL technology. It is now time to give you the results of our investigation. Don't worry I will first sum up this previous article and explain why I strongly believe that NewSQL is an important subject. Then I will present the hypothesis of our POC. And finally I will give you the results of this POC, our conclusions about what we will do the same way and what we will do differently on a real project.
NewSQL: What is it? In what way is it different from NoSQL? Why study NewSQL now?
What is it?
Many of you will think of NoSQL. Experiences from the web giants have shown that NoSQL proposes a new way to think about storage. NoSQL architectures are new kind of storage architectures that are distributed i.e. data are spread over several computers, without schema so without SQL querying capability, and without transactional guaranty. In return to such limitations NoSQL architectures have shown very high scalability over commodity hardware. NewSQL, as presented by InfoQ is at the intersection of 3 architectures: relational, NoSQL and data grid.
In what way is it different from NoSQL?
Indeed NewSQL is a distributed storage, with a scalability purpose like NoSQL, potentially stored totally in memory, but queryable through a SQL interface. NewSQL makes several fundamental different choices from NoSQL. The first choice is the choice of the SQL language which is the lingua franca of the Information System. The second one is the choice of a relational schema with some limitations on the possible transactions. E.g. in SQLFire only requests with colocalized execution plans are authorized and transactions are limited to the READ_COMMITTED mode. And finally the choice is made to use the distribution and data replication to carry out the scalability and resiliency of the data. SGBDR have been designed 30 years ago with the technological constraint at that time. Disruptive architectures like NoSQL have taken better advantage of the fundamental researches and technical improvements of the last 30 years than the SGBDR whose core is very similar to the original one. 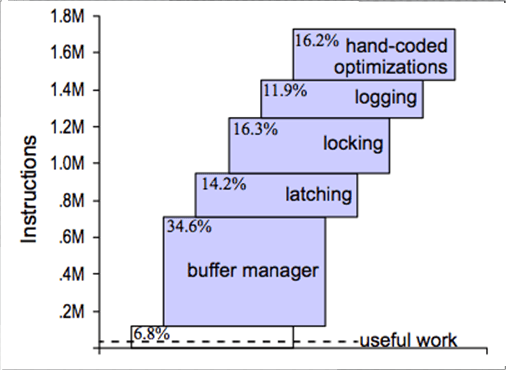
Why study NewSQL now?
I am convinced that NewSQL can build a synthesis between these two worlds. With its better proximity to existing SGBDR architecture, it could offer an easier solution to take benefit from these novelties.
So, is today the end of the relational database? Probably not as they have proved their efficiency for 30 years and existing application will continue to use them. But in virtualized environments like the cloud, a distributed storage, being able to use commodity hardware and using primarily the RAM can be a concurrency advantage.
Hypothesis for our research study
Previous architectural considerations let predict a scalability gain and a better behavior on commodity hardware. But we have learned from experience that purely theoretical considerations can be very misleading. So we have decided to compare the behavior of an application on a MySQL database and on a SQLFire database: the NewSQL product by VMWare.
The hold use case
The hold use case is a sale application. One of our client had a scalability limit on such use case with its SGBDR. This application is multi-country and multi-Point of Sale. Each point of sale owns its stock which is updated during each transaction. Currency conversion, Value Added Taxes are computed by the application according to country specific parameters. Each sale operation is recorded and grouped in a sale transaction at the end of which the customer will pay. The mental image of a supermarket cash desk is the easier way to keep in mind these concepts. 
Constraints for each implementation
We have set the following constraints for each implementation:
- Operation logging and inventory updates must be transactional
- All data related to a same shop must be consistent
- The original applicative code should be changed as little as possible
The characteristics of the SQL schema
We chose to set our own rather than use an existing benchmark so that we could precisely define the database schema characteristics. In distributed storage systems, data partitioning is crucial. Schemas with simple relations (or schemas foregoing them altogether) are easy to partition and do not model the real complexity of the task. Our schema is described below:
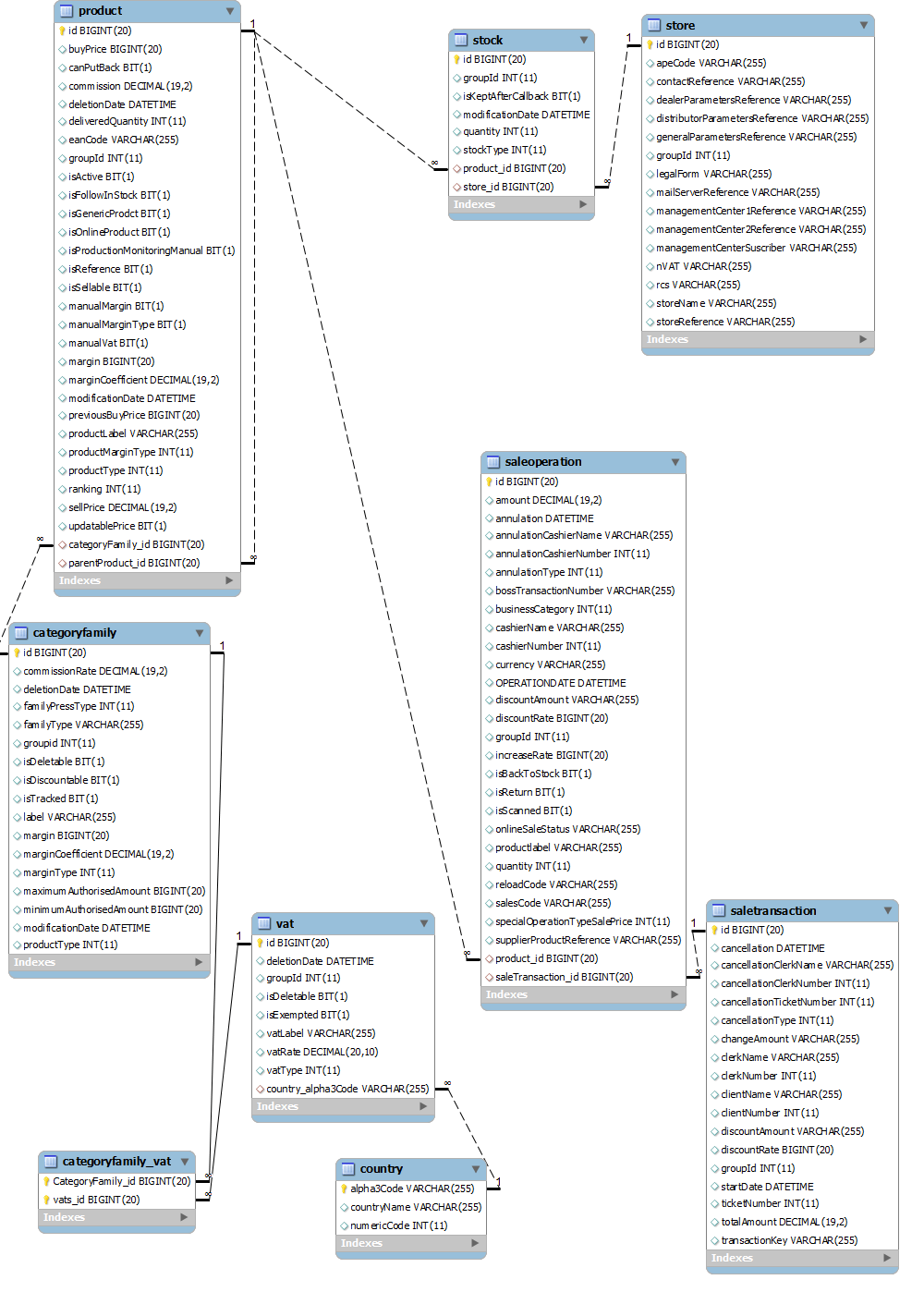
Several sale operations are grouped into a sale transaction which is identified by a payment of the customer. Each time a customer buys an article, a line is inserted in the SaleOperation table and the stock of the corresponding article is decremented by 1. If this operation is the first one of the transaction, a line is inserted in the SaleTransaction table which will contain the total for the transaction. This line will be updated by each new operation. This schema is particularly hard to partition due to the numerous relations between tables that are used by these transactions. Indeed, colocation is a key property for a transaction in a distributed storage system. If a transaction requires to read or write data on more than one computer - one node - the performance will suffer.
The characteristics of the transactions
In order to challenge this we have queried this schema using four different transactions as described in the following diagram:
- Buy: a new line is inserted in
SaleOperation, the correspondingStockline is decremented and theSaleTransactiontotal is updated. This query goes along with another one not represented in this schema. This second query involvesCountryandCategoryFamilyandVATin order to identify the corresponding VAT rate to apply. - Total: the corresponding
SaleTransactionline is queried to display the grand total to be paid. - Inventory: is an operational request to get an overview of
Stockfor a givenStore - Turnover: does a
group byoverSaleOperationin order to display the turnover for a given store over the last period

Different ways to distribute data
We will finish this article by summing up our experience migrating these types of schemas to SQLFire. Some of our readers will probably argue that database technology has allowed the partitioning of data since the mid-90's, so why has it suddenly become so interesting now? Distributed databases are based on either shared-nothing pattern, where two databases are put side by side and the application has to deal with the limitation, or shared disk / shared cache, where an extra layer synchronizes the nodes.

NewSQL databases try to offer a new approach. SQLFire in particular is based on a shared nothing approach with some constraints given to the queries. Extra SQL language keywords define how data are spread across the different nodes. By default, lines of a partitioned table are spread across nodes by hashing the primary key. If searching for a line by the primary key, the node that gets the request can immediately identify the node where the data is located. Conversely if you look for a line with another filter, the first node has to send the queries in parallel to all the nodes and then has to merge the results. When joins come into play, searches between tables are frequent so it is far more efficient if data frequently queried together are collocated on a same node. That what's allowed by SQLFire with such keywords.
CREATE TABLE Account (… client_id int constraint FK4A[..] references BankClient …)
PARTITION BY COLUMN (client_id)
COLOCATE WITH (BankClient);
In this example, Account will be located on the same node as the related BankClient.
How to distribute data with SQLFire
So, back to our example, how do we choose the partition strategy for our schema? French reader can find further details in the original French article by Sebastian de Bellefon.
The tables of our schema are all of very different sizes. The following diagram describes the size of each table. 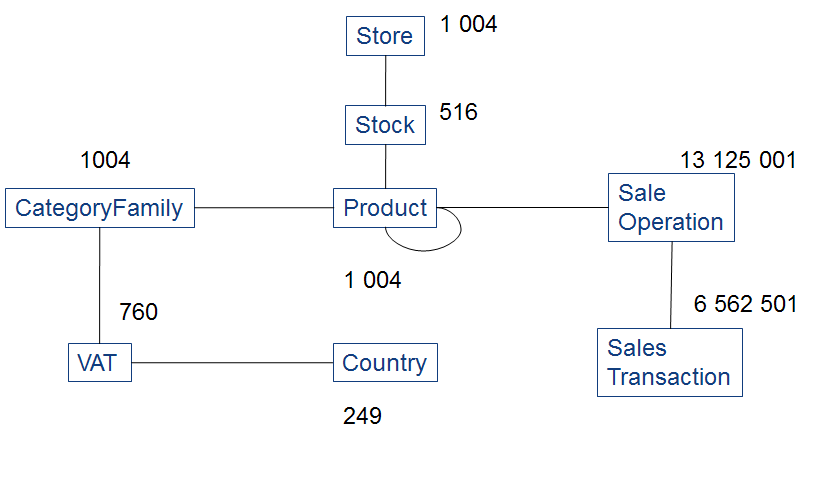
Partitioning strategy
In order to be representative a scalable architecture, we hypothesize that the bigger table cannot be contained in a single node. Partitioning serves to define how data should be stored. To do so, we segregated the tables in two groups:
- Large tables with a many modifications and few large queries
- Small tables with few modifications but many reads
The first group had to be partitioned to spread data over several nodes. Updates can be performed in parallel on several nodes. However, large queries which require global searches will be ineffective as they require access to several nodes. The second group requires replication on each nodes. In this case, every read access is very quick but each modification requires synchronization of every nodes. I learned of these concepts during Ben Stopford's talk at QCon 2011; they are also clearly explained in SQLFire documentation.
| Partitioning | Replication |
|---|---|
 | 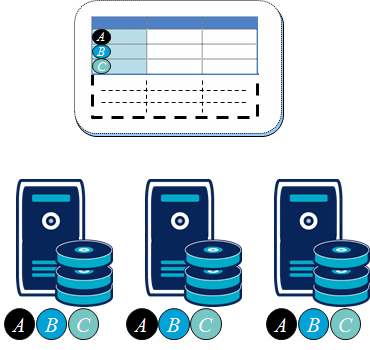 |
| Large volume of data can be stored | Data size inflates |
| Write effective | Write is not very effective |
| Read can be distributed <br>but with a high latency | Read is effective |
Choice of the pivot
In order to apply these concepts, the first task is to identify the main concept that will be used as a pivot to organize other large tables. In our case, SaleTransaction is clearly this pivot table. Clients transactions can be spread over different nodes and transactions can be inserted concurrently in those nodes. We must then identify the auxiliary data (i.e. the numerous data that can be collocated with the transactions).
One important point: the partition key of the auxiliary data should be the same as the partition key of the principal table. Each collocated table has to contain the columns of the partition key. Then data of the partition key should be properly distributed. In our case, this means putting the SaleTransaction primary key in the SaleOperation table and studying the distribution of the operations by transaction. SQLFire can specify the distribution policy by hashing or by range but here a hashing strategy is sufficient.
Stock, and Store could be seen as other candidates for a second main concept. However, notice the problem on the Product table: if you look back to the database schema you will see that one line in of the Product is related to several inventories (Stock) and several transactions. How to partition such a table? It is impossible. Why not replicate it? Another limitation of SQLFire is that for standard SQL queries, execution plans including joins have to be collocated (a stricter definition of these limitation is described in the documentation). We had to use an alternative syntax for queries between Store and Product. Moreover the transaction design is highly optimized for collocated data as explained here. But the best and most simple argument is that Store and Stock are very small compared to SaleOperation and SaleTransaction tables and they will never grow. We therefore decided to replicate them.
The other data are clearly referential data, rather static and with very low volume (e.g. VAT rates). These data will be replicated on each node. Each modification will require to synchronously update the data on the network but this is neither a frequent nor a response time sensitive operation.
Impact of the access pattern
Lastly we have to check the selected access pattern to validate the choice made on the schema. Here clearly, both the Buy and Calculation of Total transactions can be collocated. The Inventory Transaction will be collocated because all of the data involved are replicated. The Turnover transaction will have to query several nodes and aggregate the results. As there are no joins involved this functionality is provided by SQLFire.
select SUM(op.amount), op.currency from SaleOperation op where op.groupId=:groupId and op.date >= :date group by op.currency order by SUM(op.amount) desc
This allows to distribute the query over several nodes.
As such the final repartition model we have chosen is as follows: 
Implementation
The implementation of this model is quite simple. I will show you the difference that exists between a schema for Derby and a distributed schema for SQLFire.
create table CategoryFamily (...) REPLICATE;
create table CategoryFamily_VAT (...) REPLICATE;
create table Country (...) REPLICATE;
create table Product (...) REPLICATE;
create table SaleTransaction (... primary key (id)) PARTITION BY PRIMARY KEY;
create table SaleOperation (... saleTransaction_id bigint constraint FK4ACCC4C04589BBE4 references SaleTransaction, primary key (id)) PARTITION BY COLUMN (saleTransaction_id) COLOCATE WITH (SaleTransaction);
create table Stock (...) REPLICATE;
create table Store (...) REPLICATE;
create table VAT (...) REPLICATE;
Are there limitations? Yes obviously. The most visible limitation that is to not be able perform joins on non-collocated data. But this choice is clearly what allows SQLFire to have joins that are as efficient as a standard SGBDR while having an architecture as scalable as NoSQL - at least in theory.
Conclusion and thanks
NewSQL brings scalability and resiliency by partitioning and replicating data over several commodity hardware nodes. We have seen in SQLFire, our test product, how we can program it, somewhat restricted. We have also seen that it means we need a better conception on the schema. In the next article of this series I will give you our operational results for this POC.
Many thanks to Sebastian de Bellefon whose work inspired this article. And the entire NewSQL team who participate in the implementation of this Proof of Concept (in alphabetical Order): Nicolas Colomer, Nicolas Landier, Borémi Toch and Djamel Zouaoui.