Les tests automatisés en Delivery de Machine Learning
Cet article fait partie de la série “Accélérer le Delivery de projets de Machine Learning” traitant de l’application du framework Accelerate dans un contexte incluant du Machine Learning.

Un Data Scientist heureux d’avoir des tests automatisés qui ont détecté un problème avant qu’il ne devienne critique
Introduction
Parmi les leviers garantissant la qualité d’un produit logiciel, on trouve les tests automatisés. Ces tests, lorsqu’ils sont rédigés de manière effective, doivent permettre de détecter des problèmes dans la base de code et empêcher le déploiement d’un défaut, plus souvent appelé bug.
Les tests automatisés sont une des capacités dont parle le livre Accelerate, qui les place dans la famille “Continuous Delivery”, considérant que ces tests doivent s’exécuter de façon continue, et que leur validation est une condition nécessaire à toute livraison d’un produit logiciel en production.
Si en génie logiciel (ou Software Engineering) le sujet des tests automatiques est très mature, comme on peut le voir par exemple en parcourant le blog OCTO, où on peut trouver un très grand nombre d’articles couvrant le sujet comme la série La pyramide des tests par la pratique, la série Un test peut en cacher un autre ou encore l’article TDD contre les montagnes russes, force est de constater que cette capacité n’est pas aussi bien développée dans le Delivery de produits incluant des briques de Machine Learning.
Dans cet article, nous allons discuter des principales spécificités qui font que les tests automatisés en Machine Learning (ML) sont en partie différents des tests automatisés en génie logiciel, tenter de répondre à la question “Qu’est-ce qu’un bug en Machine Learning?” et proposer une liste de tests à automatiser pour assurer la fiabilité d’un produit ayant une composante ML.
Tests automatisés en génie logiciel
Avant de parler de tests automatisés en Machine Learning, nous devons d’abord définir ce qu’est un “test”.
Wikipédia définit les tests en informatique comme suit :
Un test désigne une procédure de vérification partielle d'un système. Son objectif principal est d'identifier un nombre maximum de comportements problématiques du logiciel… [et] d'en augmenter la qualité.
Écrire et maintenir un test permet donc de fiabiliser une base de code, dans la portée de la couverture fonctionnelle de ce test.
En règle générale, toute fonctionnalité devrait être couverte par un ensemble de tests s’assurant que le code “marche” dans le plus grand nombre de cas possible (aussi appelés cas de tests ou test cases).
Cette couverture permet de réduire les chances que les changements apportés au fil du temps ne “cassent” pas de fonctionnalités précédemment développées, fournissant un filet de sécurité pour les développeurs qui auront moins peur d’apporter des changements au produit.
Un autre effet bénéfique des tests est la documentation que cela produit. Par exemple, en lisant les titres des cas de tests, s’ils sont nommés de façon claire et explicite, on peut comprendre le comportement attendu de chaque partie testée du produit.
def test_prepare_coffee_should_make_a_sugarless_coffee_when_0_sugar_spoons_is_given_as_input():
# Given
number_of_sugar_spoons = 0
# When
coffee = prepare_coffee(number_of_sugar_spoons)
# Then
assert coffee.sugar == 0
Exemple de test d’une fonction de préparation de café
Dans l’exemple ci-dessus, on peut voir grâce au nom du test, que la fonction prepare_coffee a pour comportement de préparer un café sans sucre si 0 cuillère de sucre lui est donnée en entrée.
Pour couvrir efficacement la base de code, il existe plusieurs types de tests. La catégorisation la plus connue est celle qui les découpe en pyramide. Cette pyramide est appelée “Pyramide des Tests”.

La pyramide de tests
De la base vers le sommet, on trouve :
- Les tests unitaires qui testent un cas très précis sur une petite portion de code (Un comportement d’une fonction ou d’une méthode), peu coûteux à écrire et à maintenir, très rapides à l'exécution, indépendants les uns des autres, répétables et déterministes.
- Les tests d’intégration qui valident que les différentes briques testées unitairement fonctionnent bien ensemble et avec des systèmes externes (des bases de données, APIs…). Ceux-ci sont déjà plus difficiles à écrire et à maintenir, et leurs temps d’exécution peuvent être bien plus longs que ceux des tests unitaires.
- Les tests de bout en bout, le sommet de la pyramide, sont les tests qui valident le fonctionnement global d’une fonctionnalité du produit. Ceux-ci sont les tests les plus coûteux, les moins ciblés et ceux qui couvrent le moins les cas à la marge, donc les moins nombreux, mais restent néanmoins nécessaires.
Pour plus de détails à propos de la Pyramide des Tests n’hésitez pas à consulter l’article La pyramide des tests par la pratique.
Jusque-là, nous avons parlé de tests, mais la capacité dans Accelerate parle bien de tests automatisés.
L’automatisation des tests passe par l’implémentation de ceux-ci de façon à ce qu’ils soient exécutables par une machine i.e. écrire du code de test.
Ces tests sont ensuite exécutés à chaque changement dans le code :
- Par le développeur, sur son ordinateur, lorsqu’il développe une fonctionnalité ou corrige un bug.
- Dans un pipeline d’Intégration Continue (CI). Intégration Continue qui fait d’ailleurs partie des capacités Accelerate, et sera abordée dans un autre article de cette série.
Chez OCTO, on considère qu’un produit logiciel non testé n’est pas un produit de qualité. Mais qu’en est-il en Machine Learning ?
En quoi c’est différent en Machine Learning ?
Tout d’abord, il est utile de rappeler que le Delivery de Machine Learning reste avant tout du Software Engineering, en tant que tel il est soumis au même devoir de rigueur et besoins d’assurance qualité. Par conséquent, cela tombe sous le sens de vouloir rédiger et maintenir des tests automatisés qui nous aident à détecter d’éventuels bugs avant qu’ils ne soient introduits en production.
C’est à partir de cette notion de bug que les spécificités du Machine Learning commencent à rentrer en compte. Wikipédia définit un bug comme étant un défaut de conception à l'origine d’un dysfonctionnement, or en ML un modèle a par définition des défauts acceptés.
“Tous les modèles sont faux, mais certains sont utiles” - George Box
Ces défauts peuvent au fil du temps être exacerbés par la mécanique de dérive (ou Model Drift), jusqu’à ce que les prédictions émises soient trop éloignées de la réalité, et que le produit soit inutilisable.
Plus globalement, en Machine Learning le très fort couplage avec le contenu de la donnée conduit à des changements non-contrôlés du comportement du système lors de l’évolution de la donnée.
Un exemple concret de ces changements est l’introduction d’une nouvelle valeur possible pour une variable statistique de type catégoriel.
Souvent, ces variables sont encodées sous la forme de nombres entiers de 1 à N, où N est le nombre de valeurs possibles prises en compte. Si une nouvelle valeur possible est ajoutée aux données, et si l’encodage ne gère pas ce cas, une erreur se déclare et peut mettre en péril la pérennité du produit.
Un autre cas courant est celui du changement de la distribution d’une variable statistique, quand celle-ci est utilisée comme caractéristique discriminante d’un individu par un modèle de ML. Plus l’importance de cette variable dans la décision du modèle est grande, plus les changements de sa distribution impacteront les prédictions du modèle.
En plus de ces changements dans la donnée conduisant à une perte d'efficacité mesurable du modèle, il existe d’autres risques inhérents à la nature stochastique du ML, plus difficiles à détecter, comme l’introduction de biais discriminatoires nuisant à une partie des utilisateurs ou de la population plus large.
L’un des moyens de se protéger contre ces différents dysfonctionnements est la mise en place de tests automatisés spécifiques.
On teste quoi en Machine Learning ?

Concrètement, lorsqu’on travaille dans le Delivery d’un produit qui contient une brique de Machine Learning, de la même façon que pour un produit qui n’en contient pas, on teste le code, ou plus précisément son comportement, en implémentant des tests unitaires, des tests d’intégration et des tests de bout en bout.
Le périmètre du code testé comprenant le code d’entraînement de modèles et le code d’inférence utilisant des modèles précédemment entraînés.
Tester le code d’entraînement
Le code d’entraînement peut dépendre grandement des données, il est donc d’usage de prêter une attention particulière à la gestion des données utilisées pour tester le comportement du code, appelées Test Data dans Accelerate, pour qu’elles reflètent un maximum les données de production, tout en conservant la lisibilité des tests, particulièrement les tests unitaires.
Note : Accelerate parle d’ailleurs de la capacité Test Data Management, qui est intimement liée au sujet des tests automatisés et qui fera l’objet d’un article dédié dans cette série.
Un code d’entraînement est souvent constitué d’une multitude de transformations apportées à la donnée, dans le but de créer des variables caractérisant au mieux les individus étudiés, puis d’un entraînement de modèle de Machine Learning.
Les transformations de données sont généralement implémentées en utilisant des bibliothèques et frameworks spécialisés en la matière (pour des raisons de performance, mais aussi pour ne pas réinventer la roue). La majorité de ces bibliothèques offrent des utilitaires pour l’implémentation de tests.
Par exemple, Pandas, une bibliothèque Python très utilisée en Machine Learning, propose des méthodes de test dans le sous-package nommé testing, permettant de réaliser des assertions, notamment sur l’égalité de Data Frames (structure de données tabulaire). Ce sous package permet d’implémenter des tests validant la sortie d’une transformation de donnée implémentée, en la comparant à un résultat attendu.
Considérons l’exemple suivant, où l'on veut tester le comportement d’une fonction permettant le remplissage de valeurs manquantes d’un Data Frame :
def test_fill_coffee_table_missing_values_should_fill_all_na_coffee_brands_with_generic_while_setting_variety_to_java():
# Given
coffee_table_with_missing_values = pd.DataFrame({
'id': [0, 1, 2, 3, 4],
'brand': ['OCTO Coffee', None, 'Drink me to Accelerate', None, 'Test us'],
'variety': ['mocha', None, 'k7', None, 'mocha']
})
expected_filled_coffee_table = pd.DataFrame({
'id': [0, 1, 2, 3, 4],
'brand': ['OCTO Coffee', 'generic', 'Drink me to Accelerate', 'generic', 'Test us'],
'variety': ['mocha', 'java', 'k7', 'java', 'mocha']
})
# When
filled_coffee_table = fille_coffee_table_missing_values(coffee_table_with_missing_values)
# Then
assert filled_coffee_table == expected_filled_coffee_table
Ce test ne fonctionne pas en l’état, car l’égalité assertée est ambiguë du fait que les Data Frames sont des objets complexes qui contiennent des index, des types… etc
Il est possible de comparer les deux Data Frames en comparant chacun de leurs composants séparément, mais au lieu que chaque projet voulant tester l’égalité de deux Data Frames implémente son “égalité maison”, testing.assert_frame_equal offre un outil fiable, complet et standard pour le faire. Voici ce à quoi l’implémentation du test voulu peut ressembler :
def test_fill_coffee_table_missing_values_should_fill_all_na_coffee_brands_with_generic_while_setting_variety_to_java():
# Given
coffee_table_with_missing_values = pd.DataFrame({
'id': [0, 1, 2, 3, 4],
'brand': ['OCTO Coffee', None, 'Drink me to Accelerate', None, 'Test us'],
'variety': ['mocha', None, 'k7', None, 'mocha']
})
expected_filled_coffee_table = pd.DataFrame({
'id': [0, 1, 2, 3, 4],
'brand': ['OCTO Coffee', 'generic', 'Drink me to Accelerate', 'generic', 'Test us'],
'variety': ['mocha', 'java', 'k7', 'java', 'mocha']
})
# When
filled_coffee_table = fille_coffee_table_missing_values(coffee_table_with_missing_values)
# Then
pd.testing.assert_frame_equal(filled_coffee_table, expected_filled_coffee_table)
Un autre point positif lorsqu’on utilise les fonctions tels assert_frame_equal est la lisibilité des résultats de tests en cas d’échec de l’assertion. Voici la sortie d’un exemple d’une assertion non validée :
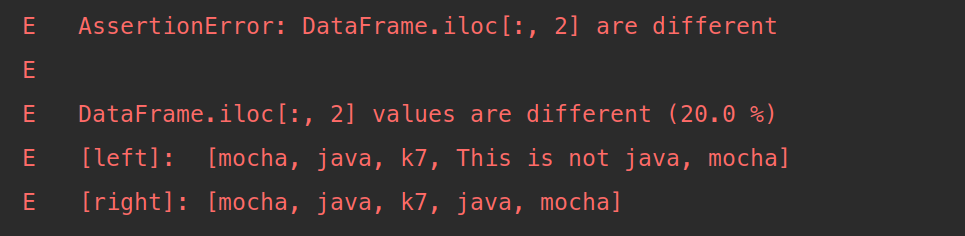
Raison explicite de l'échec d'un test utilisant assert_frame_equal
Ces utilitaires inclus dans les bibliothèques de transformation de données sont à utiliser avec parcimonie (parfois il est mieux de vérifier une seule valeur scalaire plutôt que tout un Data Frame par exemple), et en tandem avec les outils natifs au langage de programmation utilisé.
Il est également à noter que les tests unitaires de fonctions utilisant certaines de ces bibliothèques ou frameworks ont tendance à être plus lents que des tests unitaires de fonctions ne les utilisant pas. C’est notamment le cas quand on utilise Apache Spark qui met du temps à démarrer l’exécution effective du code.
Tester le code d’inférence
En ce qui concerne le code d’inférence, tout comme le code d'entraînement, il est fortement dépendant des données entrées, mais pas uniquement.
Le code d'inférence encapsule le pré-traitement des données en entrée du modèle, le calcul des prédictions, ainsi que d'éventuelles transformations post-prédiction (e.g. décisions métiers)
À partir de cette définition, une nouvelle dépendance apparaît : celle au modèle précédemment entraîné.
Souvent, cette dépendance au modèle est simulée lors de l’écriture de tests unitaires, car le but n’est pas de tester la bibliothèque utilisée mais le code que l’on produit, et que les tests unitaires doivent être rapides, or les interactions avec un modèle de ML ne le sont pas toujours.
Pour simuler la dépendance au modèle lors des tests unitaires, on peut par exemple se servir des simulacres (Mocks). L’exemple suivant montre l’utilisation d’un Mock en Python pour simuler une dépendance à un modèle de Machine Learning :
def test_will_my_coffee_be_hot_enough_when_my_meeting_ends_should_return_true_if_the_meeting_room_is_hot():
# Given
coffee = Coffee(sugar=0)
meeting = Meeting(room_name="The hottest room")
hot_cold_model = Mock(return_value=1)
# When
coffee_is_hot = will_my_coffee_be_hot_enough_when_my_meeting_ends(coffee, meeting, hot_cold_model)
# Then
assert coffee_is_hot is True
Exemple d’utilisation de simulacres en Python pour simuler un modèle de ML
Les interactions avec l’objet modèle doivent être effectivement testées pendant les tests d’intégration et tests de bout en bout.
Parmi ces tests de bout en bout, il existe des tests dits de recette qui doivent être, selon le cas d’usage, implémentés et automatisés ou non. Par exemple, on peut citer le fait de tester que les temps de prédiction sont en dessous d’un seuil donné, ou encore que la prédiction sur des cas importants redondants est correcte… Il est bon d’en discuter avec les experts métier et les utilisateurs pour les définir.
Tester l’absence de biais discriminatoires
Outre le code d'entraînement et d’inférence, il n’est pas rare de vouloir ajouter des tests qui valident automatiquement l’absence de biais discriminatoires dans le produit.
En entrant les mot-clés “biais IA” dans un moteur de recherche, on obtient un très grand nombre d’articles relatant les mésaventures de personnes noires utilisant des systèmes embarquant des algorithmes de vision par ordinateur.
Ce n’est malheureusement que la partie émergée de l’iceberg. Un grand nombre de biais ne sont pas aussi flagrants.
Les causes de présence de ces biais sont multiples :
- Le manque de diversité dans la communauté Intelligence Artificielle/Machine Learning
- La présence de biais dans les données
- Le manque de maîtrise des modèles de Machine Learning
- La complexité grandissante des produits embarquant une brique ML
- …
Il y a, aujourd’hui, un grand nombre d’efforts qui visent à éliminer ces facteurs précédemment cités. En parallèle, on peut utiliser des tests automatisés servant à capturer ces biais, avant qu’ils ne soient déployés.
Les tests à implémenter diffèrent d’un cas à un autre. Il est bon d’en discuter avec les experts du métier, en s’inscrivant dans une démarche « Ethical by Design ».
Il est possible d’appliquer ces tests à deux endroits distincts :
- Sur les prédictions en sortie du processus d’inférence, en vérifiant par exemple que le processus donne de bons résultats sur un éventail inclusif d’individus et de contextes.
- Sur les données en entrée du processus d’entraînement, en s’assurant par exemple qu’une population n’est pas sous représentée dans cet ensemble de données. Ceci peut permettre d’éviter des dysfonctionnements du produit sur une population minoritaire. L’automatisation de ces tests est nécessaire pour l’automatisation d’un réentraînement de modèle.
Ces tests automatisés sur les données sont atypiques et ne rentrent dans aucun des niveaux de la pyramide de tests (bien qu’inclus dans la pyramide de tests étendue, proposée dans l'article CD4ML), pour cause ils sont exécutés au runtime et frôlent la frontière, parfois floue, avec le Monitoring.
Tester les données
Les tests de validation de la donnée peuvent par ailleurs servir à s’assurer de la qualité de la donnée au-delà de l’absence de biais discriminatoires, on peut aussi vouloir s’assurer de la stabilité de la distribution de certaines variables, ou encore de la validité d’hypothèses du type “Ma variable catégorielle x ne peut prendre que 3 valeurs”.
Là encore il existe des outils pour faciliter l’implémentation de ces tests. On peut citer en exemple la bibliothèque Python Great Expectations, qui propose différentes vérifications sur la donnée déjà implémentées, et en bêta un moyen d’ajouter, de façon déclarative, d’autres vérifications.
Prenons le cas du changement de la distribution d’une variable statistique dans les données que nous avons mentionné au début de l’article, et illustrons ça avec les données suivantes
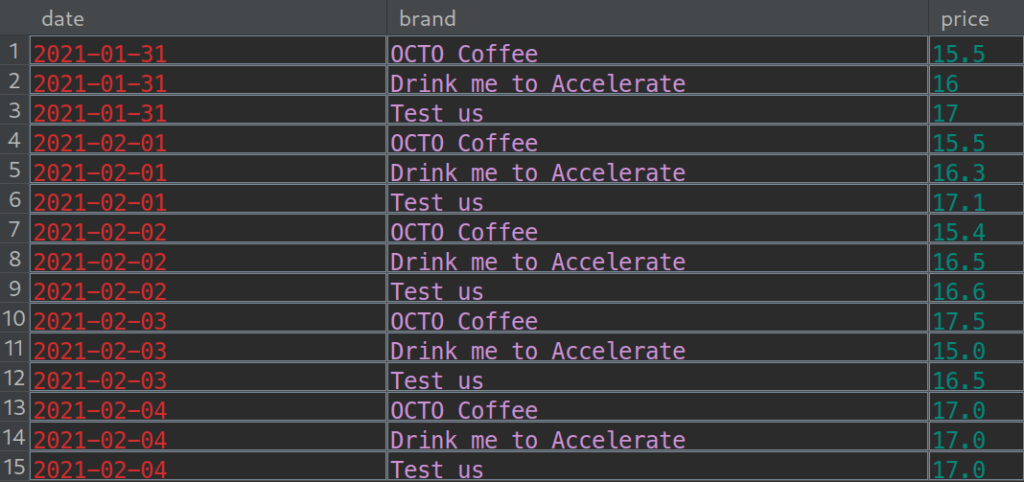
Données sur les prix journaliers de différentes marques de café
Si un modèle de ML dont la principale variable explicative est le prix est en production, il est bon de savoir quand la distribution de cette variable évolue en dehors des hypothèses formulées pendant la modélisation.
Pour faire cela, après avoir créé un et configuré un Data Context (Répertoire contenant la configuration de Great Expectations), on peut créer des Expectations (des assertions sur les données), dans le sous-répertoire expectations/ sous forme de fichier JSON.
Parmi les Expectations que propose Great Expectations on retrouve l’assertion expect_column_quantile_values_to_be_between que l’on peut utiliser pour tester si les valeurs des quartiles Q1, Q2 et Q3 sont bien dans des intervalles attendus. Le fichier JSON dans notre cas est :
{
"data_asset_type": "Dataset",
"expectation_suite_name": "coffee_prices.warning",
"expectations": [
{
"expectation_type": "expect_column_quantile_values_to_be_between",
"kwargs": {
"column": "price",
"quantile_ranges": {
"quantiles": [
0.25,
0.5,
0.75
],
"value_ranges": [
[
15.0,
16.0
],
[
15.75,
16.5
],
[
16.5,
17.0
]
]
}
},
"meta": {...}
}
],
"meta": {...}
}
Fichier JSON de l’Expectation sur Q1, Q2 et Q3
Il existe plusieurs moyens d’exécuter la vérification, mais celle recommandée par la documentation de Great Expectations est de créer un checkpoint et de valider celui-ci à en exécutant le snippet de code Python suivant :
import great_expectations as ge
from great_expectations.checkpoint import LegacyCheckpoint
context = ge.data_context.DataContext()
batch_kwargs = {
"path": "/home/samy/workspace/pro/octo/test_automation/data/coffee_prices.csv",
"datasource": "data__dir",
"data_asset_name": "coffee_prices",
}
my_checkpoint = LegacyCheckpoint(
name="my_checkpoint",
data_context=context,
batches=[
{
"batch_kwargs": batch_kwargs,
"expectation_suite_names": ["coffee_prices.coffee_price_warning"]
}
]
)
results = my_checkpoint.run()
validation_result_identifier = results.list_validation_result_identifiers()[0]
context.build_data_docs()
context.open_data_docs(validation_result_identifier)
Création et lancement d’un checkpoint Great Expectations
Les trois dernières lignes de code sont optionnelles et servent uniquement à construire une Data Doc (Documentation sur la donnée et la validation de ses caractéristiques, issue des tests), puis affichent la page de cette documentation qui contient entre autres choses les résultats de notre assertion sur la donnée du prix des marques de café :
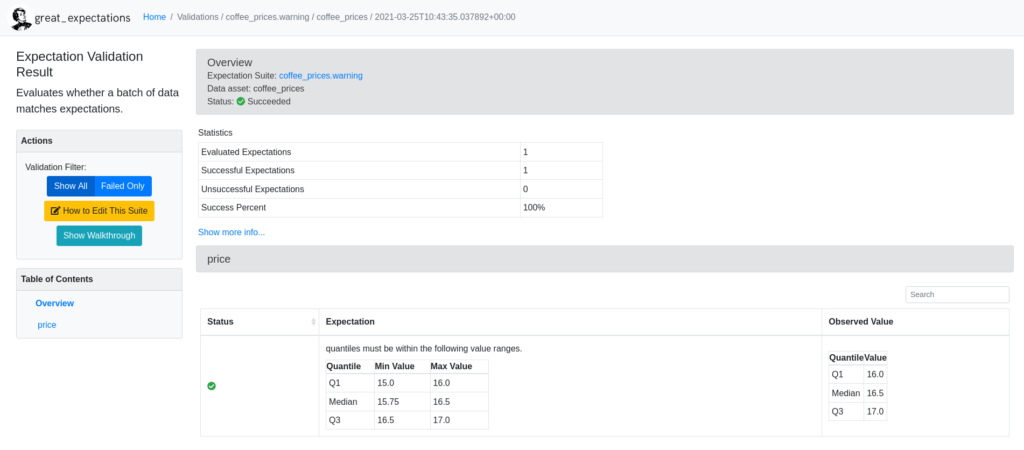
Page de validation d’Expectation sur la Data Doc
On peut voir que la donnée respecte notre assertion grâce au statut vert dans la colonne Status.
Si maintenant les valeurs de la colonne changent, par exemple en prenant des valeurs bien plus élevées que la normale au-delà de la médiane, l’exécution du même script Python produit le résultat suivant :

Invalidation d’une Expectation sur la Data Doc
Au-delà de la validation visuelle des résultats, il est possible de vérifier le contenu de l’attribut booléen success de la variable result, qui vaut True lorsque les données valident les Expecations et False autrement.
De cette façon, il est possible de déclencher une alerte avant une prédiction par exemple, et peut-être renvoyé des valeurs qui n’utilisent pas le modèle de Machine Learning qui se base sur des hypothèses falsifiées par les nouvelles données.
Pour plus de détails sur l’utilisation de Great Expectations, la documentation est assez riche et contient des tutoriels pour prendre en main la bibliothèque.
Tester les autres briques logicielles
Finalement, tester la partie Machine Learning du produit ne dispense en aucun cas le besoin d’implémenter des tests automatisés pour le reste des briques du produit.
Si par exemple la brique ML fait partie d’une application web, il faut tester cette application web. Si la brique ML fait partie d’une application mobile, le code de cette application mobile doit aussi être testé.
Un autre pan du produit qui est souvent présent quand on fait du Machine Learning concerne la partie ETL (Extract Transform Load), que l’on retrouve souvent en amont des briques ML, mais parfois aussi en aval. La partie ETL doit donc aussi être testée.
La brique ML du produit doit s’interfacer avec ces autres briques, et ces interfaces sont également à tester. Ces tests peuvent être déjà présents dans les tests d’intégration/bout en bout des codes d'entraînement et d’inférence.
TL;DR
Pour résumer, en Machine Learning on teste automatiquement :

- Le code d'entraînement
- Le code d’inférence
- L’absence de biais discriminatoires
- La qualité de la donnée
- Les hypothèses sur la donnée
- Les briques logicielles non ML (Web, mobile, ETL, …)
Et cette liste n’est bien sûr pas exhaustive, selon le produit, on peut être amené à implémenter et automatiser d’autres tests.
Maintenant que l’on sait quoi tester en ML, la question suivante est : quand sont exécutés ces tests automatisés ?
On teste quand en Machine Learning ?
Quand on développe un produit avec une brique ML, on peut distinguer 2 types de tests selon le moment où ils sont exécutés.
D’abord les tests qui sont exécutés à l’évolution du code, soit d’entraînement, soit de prédiction. Ces exécutions peuvent être résumées dans le schéma suivant :
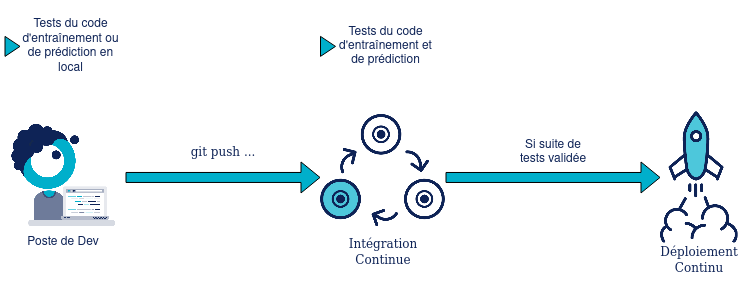
Tests exécutés à l’évolution du code
Sur ce schéma nous avons les développeurs qui exécutent les tests unitaires, d’intégration et de bout en bout (quand c’est possible) sur leurs machines.
Ce code est ensuite automatiquement validé par l’intégration continue, qui se charge d’exécuter tous les tests du code dans des environnements répliquant au mieux possible les environnements de production.
Le second type de tests rassemblent les tests qui sont lancés pendant l’exécution, que l’on peut retrouver sur la figure ci-dessous :
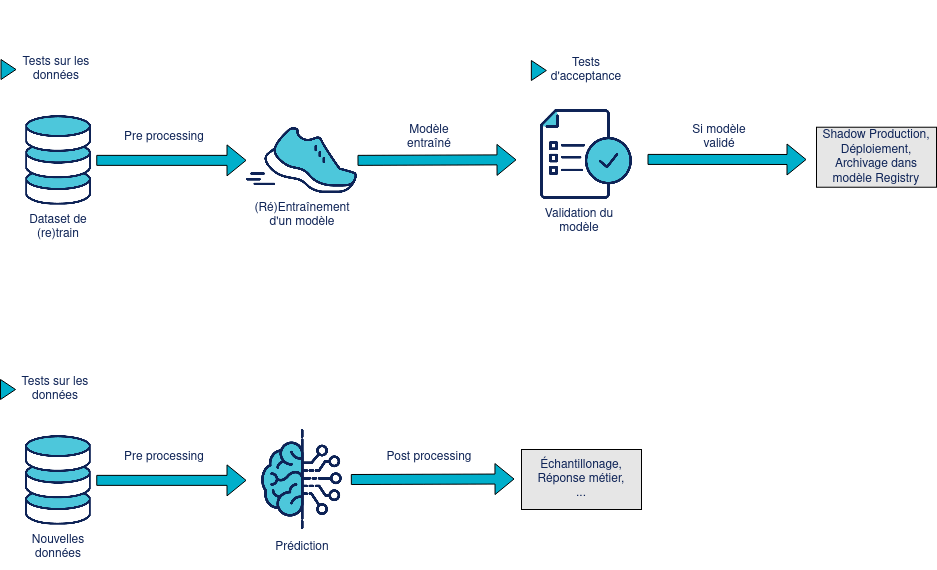
Tests exécutés au runtime
On distingue ici les tests sur les données, tels que les tests sur les distributions ou la qualité de l’échantillon, et les tests de recette du modèle une fois entraîné, comme par exemple la validation de la prédiction sur une sous-population ciblée.
Selon le produit on peut avoir aussi des tests de seuils de performance pendant cette phase, même si ceux-ci peuvent être délégués à la Shadow Production, qui contient déjà des méthodes d’évaluation de modèles.
Et comme vu précédemment on peut aussi proposer des tests sur la donnée en entrée du processus d’inférence pour se prémunir de certaines erreurs issues de la donnée.
Remarque : Le déploiement du code de prédiction ou d’un nouveau modèle doit toujours passer par la validation des tests d’intégration et de bout en bout du code d’inférence. Ceci permet de valider que le nouveau modèle fonctionne bien avec le code d’inférence, et vice versa.
Finalement, une réponse pertinente à la question « On teste quand en Machine Learning ? » peut être « On écrit les tests d’abord puis le code après ».
En effet les méthodologies Test First comme le Test Driven Development (TDD), se marient bien avec l’implémentation de fonctions mathématiques complexes, en s’appuyant sur les principes KISS (Keep It Simple, Stupid). La méthodologie nous évite la sur-ingénierie, en faisant émerger l’implémentation la plus simple.
Conclusion
Un produit contenant une brique Machine Learning est un produit logiciel, en tant que tel, pour s’assurer de sa qualité, la mise en place de tests automatisés s’impose, malgré la complexité inhérente à la nature stochastique des modèles de Machine Learning, et la jeunesse des outils utilisés.
Une importante spécificité du ML est son fort couplage au contenu de la donnée. Ceci nous impose la mise en place de tests au runtime validant des hypothèses, sans lesquelles le produit ne peut plus fonctionner correctement.
La thématique des tests automatisés en Machine Learning rend la question de la gestion des données de test encore plus importante. C’est d’ailleurs une capacité du livre Accelerate. Elle fera l’objet d’un prochain article.
Stay tuned !