Les stratégies de gestion de pression – Partie II
Les stratégies de gestion de pression sont exploitées de longue date dans divers domaines, allant des chaînes de production industrielles aux technologies réseau en passant par les méthodologies agiles. Elles exploitent en général des techniques de remontée de l’information en amont, dites back-pressure. Ces stratégies sont nombreuses en informatique, et plus précisément dans les architectures réactives (suite de la Partie I).
Stratégies locales de gestion de pression
Nous nous sommes intéressés dans le précédent article (Partie I) aux stratégies existantes pour parvenir à remonter l’information de back-pressure du consommateur vers le producteur (zone rouge dans la figure 1). Nous allons aborder, dans ce qui suit, les différentes stratégies utilisées au niveau du producteur pour gérer la pression, qu’elle soit constatée ou identifiée a priori de manière préventive (zone verte).
{kind=link}
La plupart des approches nécessitent la gestion d’un tampon, sur le producteur, le consommateur, voire les deux. Ces derniers peuvent avoir soit une taille limite arbitraire (bounded buffer), soit une taille qui grandit progressivement suivant les besoins (avec le risque de saturer la mémoire).
Il existe différentes stratégies pour gérer la saturation des tampons. Plus précisément, que le composant soit un producteur ou un consommateur, il est souvent nécessaire d’établir une stratégie de gestion de la pression locale avant de remonter à nouveau en amont la pression sous forme de back-pressure. Cette stratégie devient carrément impérative lorsqu’il s’agit du premier maillon de la chaîne de traitement.
En effet, le premier producteur réceptionne tous les messages entrants dans le système. Il reçoit ou non de la back-pressure de ses consommateurs directs. Il se retrouve dans l’obligation de gérer localement la pression car il lui est souvent impossible de remonter de la back-pressure, mis à part couper la communication avec son client.
Les stratégies possibles prennent en compte, ou pas, la back-pressure remontée par les consommateurs, de manière explicite ou implicite. Elles sont appliquées localement, pour certaines de manière proactive, pour parvenir à mieux gérer la répartition de la pression sur les consommateurs, voire la diminuer.
Ces stratégies peuvent être :
- Répartition de charge
- Purger / Ignorer
- Bloquer le producteur
- Agrégat, échantillonnage, conflation
- Délestage
- Capacité supplémentaire
- Coupe circuit
- PID
Répartition de charge
La plus commune des stratégies de gestion de pression, la répartition de charge (Load Balancing), est un ensemble de techniques visant à distribuer la charge entre différents consommateurs. Différents algorithmes existent et sont de complexité / intelligence variées, tels que :
- le Round-Robin : le plus basique, les éléments sont envoyés successivement vers chaque consommateur en boucle
- l’aléatoire : les éléments sont envoyés aléatoirement vers les consommateurs, avec une distribution normale garantissant qu’en moyenne tous les consommateurs reçoivent autant de messages
- le Round-Robin pondéré : les consommateurs se voient affecter une pondération; les éléments sont envoyés davantage vers les consommateurs avec le poids le plus fort
- la distribution par hashage : selon une clé de hash qui peut dépendre de la source, du contenu de l'élément ou encore du consommateur
- les répartitions les plus complexes prennent en compte la back-pressure remontée par les consommateurs sous forme de XON/XOFF
Ces algorithmes peuvent être combinés pour réaliser des schémas plus complexes. L’objectif de ces stratégies est d’éviter qu’un consommateur ne se retrouve noyé sous une trop grande charge et qu’il mette en danger le fonctionnement nominal de l’ensemble.
On peut par exemple retrouver certains de ces algorithmes dans le serveur web Apache ou dans nginx, où le Round-Robin (ou “byrequests” dans Apache) est choisi par défaut.
Purger / ignorer
En cas de saturation d’un tampon, l’idée est de simplement ignorer les nouveaux messages, voir à effacer l’intégralité du tampon afin de partir sur un tampon vierge (il s’agit alors d’une purge). L’absence d’acquittement par exemple, entraînera rapidement une nouvelle tentative par le producteur. Cette approche est efficace si la perturbation est momentanée.
L’approche de purge est notamment utilisée dans les applications liées à la sécurité des connexions ou des données, telles que les pare-feu ou les outils de sécurité. Les stratégies ignorant des éléments du flux entrant sont souvent utilisées dans les technologies de compression vidéo et audio : en cas de lenteur des consommateurs, certaines trames vidéo, par exemple, peuvent être sacrifiées et non traitées pour favoriser la fluidité et profiter de la limitation des performances visuelles de l’utilisateur (persistance rétinienne de l’ordre de 1/25 secondes). Le flux audio est alors à prioriser sur le flux vidéo.
Conflation, agrégation, échantillonnage
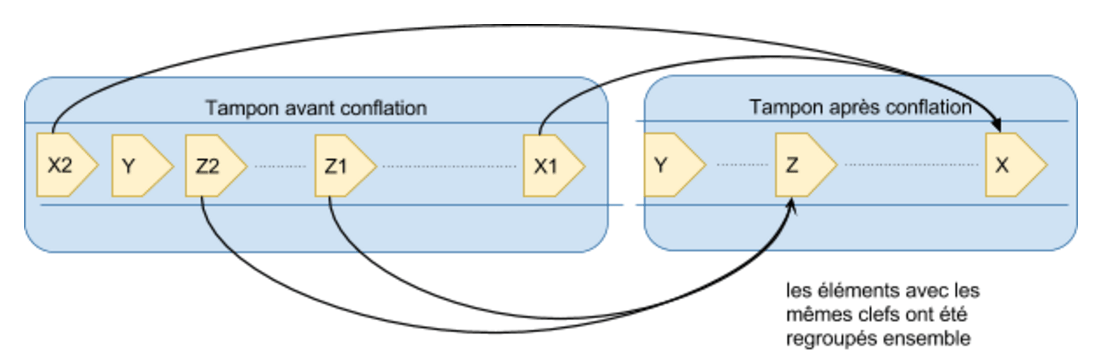
La conflation et l’échantillonnage ont un objectif commun : analyser les éléments présents dans le tampon pour appliquer une stratégie de nettoyage. Cette dernière peut adopter différents comportements selon le type de contexte à maintenir entre les éléments.
L'agrégation et l'échantillonnage sont introduits dans RxJava sous le nom d’opérateur (cf. figures 13 et 14). Le choix de la méthode d’échantillonnage ou d’agrégation est très lié à la partie métier associée.
Une première famille de stratégies, la conflation, consiste à réduire le nombre d’éléments, et se décline soit en une agrégation, soit en une suppression d’éléments.
- Agrégation : consiste à regrouper des messages entres eux pour n’en former qu’un seul (deux mutations disjointes d’un enregistrement peuvent devenir une mutation de plusieurs attributs simultanément). On agrège ensemble des messages selon le contexte et le métier pour simplifier le traitement.
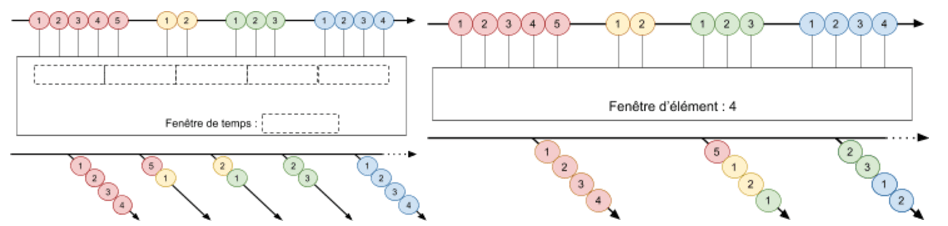
- On peut par exemple grouper les éléments reçus par unité de temps (par exemple 1 ms, 5 s ou 1 jour),
- ou bien par quantité, par recréation d’un nouveau message à partir d’un nombre prédéfini d’éléments.
- Suppression : consiste à éliminer des message inutiles (comme dans l’exemple du cours d’une action qui aurait encore évolué entre le premier et le dernier message et où le premier peut être supprimé)
Les outils de trading ou de Real-time Business Intelligence (RTBI) sont des bons exemples d’utilisation de l’agrégation. En effet, les données entrantes sont rassemblées pour en calculer des moyennes, des tendances ou pour fournir des indicateurs de prise de décision selon des variations.
Dans Akka Streams, un flow (implémentation du processeur de Reactive Streams) peut être intercalé entre un consommateur et un producteur. Il est possible d’y invoquer la fonction conflate qui permet, lorsque le producteur est plus rapide, d'appliquer de la conflation par agrégation ou par suppression.
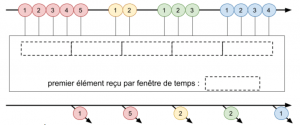
L’échantillonnage est une autre forme de réduction d’éléments : les messages sont sélectionnés selon une règle déterministe mais désintéressée du contexte (context free), pour ne garder qu’une proportion des messages, sur différents critères (ne garder que certaines mesures de capteurs permet d’obtenir des évaluations raisonnables à défaut d’être exactes).
Délestage
Le délestage consiste à déporter les messages en excès vers une zone temporaire (disque, base de donnée, file JMS, Kafka). Les éléments ne sont plus traités en temps réel. Ils seront repris plus tard, lorsque les sollicitations du SI seront devenues raisonnables. Cette stratégie est intéressante lorsque les messages n’ont pas vocation à être traités le plus rapidement possible.
Capacité supplémentaire
Cette approche consiste à déporter le surplus de travail en ajoutant de nouvelles capacités. Les approches proposées par le cloud permettent d’ajouter dynamiquement de nouveaux workers afin d’encaisser une surcharge de travail. La difficulté de cette approche est que le temps nécessaire à l’ajout d’un worker n’est pas toujours compatible avec le débit des messages à traiter. Pour éviter cela, l’idée est de provisionner des workers supplémentaires dès le dépassement d’un certain débit. Dans le sens inverse, en deçà d’un certain débit, les workers non utilisés peuvent être supprimés.
Cela permet de gérer des montées progressives de débit, mais ne permet pas de résister à un déni de service violent par exemple.
A titre d’exemple, Mesos dans son intégration à Spark 1.5 (et les versions suivantes) utilise cette stratégie pour ajouter des executors lorsque le tampon de tâches augmente au delà d’un seuil. L’inverse est vrai avec le kill d’un executor si ce dernier se retrouve sans activité.
Coupe circuit
L’approche coupe-circuit (circuit-breaker), basée sur le pattern du même nom, consiste à réagir à la pression en dégradant les fonctionnalités et/ou l’efficacité tout en évitant de solliciter continuellement un maillon de la chaîne de traitement sous pression ou défaillant. Certaines activités ne sont plus disponibles le temps que la pression soit redevenue raisonnable. Par exemple, il n’est plus possible d’écrire des données mais seulement de les lire.
Lorsque le circuit est ouvert, il n’y a plus de sollicitation du consommateur. Périodiquement, une requête est à nouveau envoyée vers ce dernier afin de vérifier s’il est redevenu exploitable. Si c’est le cas, le circuit est refermé pour reprendre un fonctionnement nominal. L’intégralité des fonctionnalités est alors disponible.
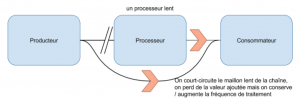
Un dérivé du coupe circuit (c.f. figure 15) propose, dans le cas où un des maillons d’une chaîne provoque de la lenteur sur l’ensemble de cette chaîne, de couper le lien avec ce maillon et de solliciter directement le maillon suivant. De la valeur est perdue, mais on augmente la capacité de traitement, ce qui peux être utile sur des périodes d’importante sollicitation d’une durée assez longue (l’affluence d’utilisateurs sur les sites de journalisme suite à une catastrophe naturelle).
Cette approche est indispensable dans une architecture en micro-services. Elle permet d’éviter les échecs en cascade lorsque de nombreux composants communiquent. On la retrouve également dans Apache Camel comme une alternative aux algorithmes de répartition de charge, ainsi que dans Hystrix, lui même basé sur le framework RxJava.
Régulateur PID
Un régulateur PID (pour actions Proportionnelle, Intégrale, Dérivée) est un algorithme de contrôle de systèmes permettant de moduler l’entrée d’un système pour qu’il atteigne de manière optimale la valeur désirée en sortie. Il est particulièrement répandu dans l’industrie (stratégie de régulation) pour lisser le contrôle du comportement de systèmes ou procédés non linéaires.
Cet algorithme peut être utilisé pour calculer le débit optimal que peut produire le producteur, suivant la capacité constatée de traitement par le(s) consommateur(s).
Cette stratégie peut s’appliquer à différents niveaux. Par exemple, elle peut intervenir sur le tampon d’un consommateur fonctionnant en pull afin de contrôler son comportement et d’améliorer ses réactions face à certaines sollicitations.
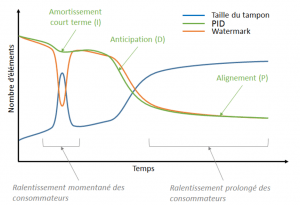
Autre exemple : toujours dans le cadre d’un pull, en comparaison avec le comportement de la stratégie Watermark vis à vis de l’évolution du tampon, le PID offre (figure 16) :
- de l’amortissement à court terme des variation importantes (action Intégrale)
- de l’anticipation sur les modification de vitesse (action Dérivée)
- de l’alignement sur le long terme (action Proportionnelle)
Le PID est néanmoins un algorithme amenant de la complexité car son paramétrage pour un fonctionnement optimal (minimiser les erreurs d’alignement, latence optimisée, minimisation des oscillations) est typiquement empirique et relève de l’approche essai / erreur.
Synthèse
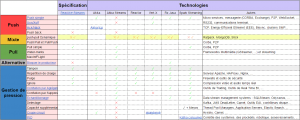
La Table 1 présente un recensement des stratégies de back-pressure et de gestion locale de pression vues précédemment ainsi que de leurs implémentations dans différentes technologies réactives. Il s’agit d’une vision à date, où les cases non renseignées représentent une incertitude sur la présence d’implémentation de la stratégie. Les coches vertes indiquent que l’implémentation native est effectivement constatée, alors qu’une croix rouge signifie l’inverse sans pour autant préjuger de la possibilité d’implémentation par l’utilisateur.
La colonne spécification, correspondant à Reactive Streams, donne les stratégies mises en avant par cette dernière. Les cases vides sont les stratégies qui peuvent être adaptées en plus sans perturber son fonctionnement. Les coches rouges représentent celles qui, au contraire, sont à prohiber, comme le fait de recourir au blocage du producteur.
La dernière colonne liste, pour chacune de ces stratégies, des exemples d’autres stacks techniques ou domaines utilisant nativement ces stratégies. L’acquittement avec le TCP ou le protocole RS232 pour le Xon/Xoff explicités plus haut dans le texte sont deux de ces exemples. Le constat immédiat est que la majorité des stratégies citées ont été utilisées ailleurs que dans les applications réactives.
Il est intéressant de noter que les technologies réactives abordées ont choisi d'utiliser des stratégies locales différentes. Akka Streams_,_ par exemple, a choisi de proposer de la conflation, RxJava implémente une stratégie d’échantillonage et Spark Streaming utilise un PID pour gérer les consommateurs Kafka. Seules les stratégies les plus basiques sont implémentées plus généralement, notamment celles destinées à réduire la taille du tampon ou à répartir la charge.
La spécification Reactive Streams est implémentée dans la majorité des stacks techniques réactives, dans la table 1, elles correspondent aux cases en jaune. Chacune d’entre elles utilisant son mode de fonctionnement (à base d’acteurs pour Akka, pause/resume d’Observable pour Vert.x). Cependant, elles ne mettent pas en oeuvre les mêmes modes d’échange voire les mêmes stratégies.
Spark Streaming est la technologie qui intègre le plus de possibilités pour la gestion de pression locale et peut être utilisée en compatibilité avec la spécification de Reactive Streams. Elle s’en inspire sur certains points, pour le concept de push-pull dynamique par exemple.
Si vous démarrez un nouveau projet réactif, il est conseillé d’adopter la spécification Reactive Streams pour gérer les échanges entre composants, les stratégies de gestion de pression en tirent un net avantage. Si vous êtes obligés de vous interfacer avec des stacks qui fonctionnent en mode push, vous êtes mieux armé pour identifier les bonnes stratégies de gestion locale de pression.
Bibliographie
- (reactive-streams.org). « Reactive Streams. » http://www.reactive-streams.org/
- (Typesafe). « Akka Streams Documentation, Scala. » http://doc.akka.io/docs/akka-stream-and-http-experimental/2.0.1/scala.html
- Bonér J., Farley D., Kuhn R., Thompson M. « Le Manifeste Réactif. » http://www.reactivemanifesto.org/fr
- (Wikipedia). « Push–pull strategy. » https://en.wikipedia.org/wiki/Push%E2%80%93pull_strategy
- (Vertx.io). « Vert.X Documentation. » http://vertx.io/docs/
- (Netflix). « Back-pressure in RxJava. » https://github.com/ReactiveX/RxJava/wiki/Backpressure
- François G. « Spark Streaming back-pressure signaling. » https://docs.google.com/document/d/1ZhiP_yBHcbjifz8nJEyPJpHqxB1FT6s8-Zk7sAfayQw/edit
- (spark.apache.org). « Spark 1.5.2 Documentation. » http://spark.apache.org/docs/1.5.2/index.html
- (Typesafe). « Back-pressure — Akka Documentation. » http://doc.akka.io/docs/akka-stream-and-http-experimental/2.0-M2/scala/stream-flows-and-basics.html#back-pressure-explained-scala
- (Typesafe). « Akka Documentation, Scala. » http://doc.akka.io/docs/akka/2.4.1/scala.html
- (projectreactor.io). « Reactor. » http://projectreactor.io/docs/
- (Wikipedia). « Backpressure routing - Wikipedia, the free encyclopedia. » https://en.wikipedia.org/wiki/Backpressure_routing
- Gregoire J., Qian X., Frazzoli E., De La Fortelle A., Wongpiromsarn T. « Capacity-Aware Backpressure Traffic Signal Control ». IEEE Trans. Control Netw. Syst. 2015. Vol. 2, n°2, p. 164‑173.
- Stone J. The impact of supply chain performance measurement systems on dynamic behaviour in supply chains. Aston University, 2012.
- Vernon V. Reactive Messaging Patterns with the Actor Model: Applications and Integration in Scala and Akka. Addison-Wesley Professional, 2015.