Les stratégies de gestion de pression - Partie I
Les stratégies de gestion de pression sont exploitées de longue date dans divers domaines, allant des chaînes de production industrielles aux technologies réseau en passant par les méthodologies agiles. Elles exploitent en général des techniques de remontée de l’information en amont, dites back-pressure. Ces stratégies sont nombreuses en informatique, et plus précisément dans les architectures réactives.
Introduction
Pour toutes les technologies que vous seriez amenés à utiliser, la revue effectuée dans cet article vous aidera à identifier les stratégies à adopter et à les combiner au mieux. Les nouvelles solutions de développement proposent généralement des approches destinées aux architectures réactives. Les architectures micro-services généralisent les communications entre de nombreux composants. Chaque événement émis déclenche un traitement asynchrone. Sans gestion de débit, il y a un risque de saturation d’un programme par une charge de travail trop importante (déni de service). Il est indispensable de proposer des stratégies de gestion de la pression pour chaque maillon, et idéalement, de propager la détection d’une contention sur toute la chaîne de traitement. Il existe de nombreuses stratégies de remontée de pression et de gestion de celle-ci, chacune étant plus ou moins adaptée à chaque situation, avec ses avantages et ses inconvénients. Il est difficile, voire impossible, de définir une solution universelle, mais on peut établir des comportements typiques associés à des cas d’usages métier. Lors d’une communication entre deux entités, le producteur (producer) construit des messages numériques, et les envoie vers le consommateur (consumer). Les messages transitent entre le producteur et le consommateur via différentes technologies de communication, sur des distances variables, avec plus ou moins de latence et de qualité. En réalité, les systèmes mettent très souvent en oeuvre un ou plusieurs producteurs alimentant plusieurs consommateurs chacun. Dans le présent article, nous nous focaliserons principalement sur le duo formé par un seul producteur et un seul consommateur, les principes évoqués demeurant conservés.
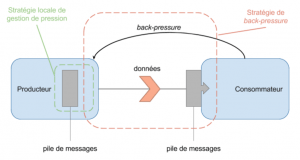
De manière générale, il y a une pile de messages à transmettre du producteur vers une pile de messages dans le consommateur (figure 1). Idéalement, les deux piles de messages ne doivent jamais saturer. A cet effet, deux types de stratégies peuvent sont utilisées :
- Les stratégies de back-pressure proprement dites, appliquées par le consommateur et qui permettent d’évaluer et de remonter l’information de pression vers le producteur. Ces stratégies peuvent prendre en compte notamment le flux de données reçues, la taille de la pile de messages du consommateur et l’efficacité du traitement de ces derniers.
- Les stratégies locales de gestion de pression, mises en oeuvre par le producteur, et qui permettent de gérer la pression identifiée. Cette dernière peut se baser sur des considérations a priori, en exploitant entre autres la taille de la pile de messages ainsi que le débit de données délivré. Elle peut également intégrer l’information de pression remontée par le consommateur.
Dans cette première partie, nous allons commencer par aborder les stratégies de back-pressure.
Dans la partie suivante, nous nous intéresserons aux stratégies locales de gestion de pression existantes.
Les stratégies de back-pressure
Principes
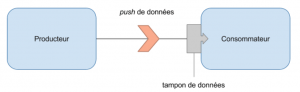
Le push
Le “push” est la méthode classique de communication entre deux entités. La donnée est émise par un producteur vers un consommateur. Ce dernier est responsable d’être en capacité de gérer tous les messages émis par le producteur. A défaut, il doit avoir une stratégie pour gérer le surplus. Dans ce mode, c’est le producteur qui contrôle la fréquence d’émission. Il émet un message dès qu’il le juge nécessaire, indépendamment des capacités de traitement du consommateur. Aucune stratégie permettant de gérer la pression sur le consommateur n’est prévue. Cette pression peut engendrer la saturation du tampon de données de ce dernier, voire un dépassement de capacité.
Le pull
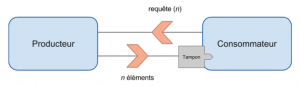
Dans le cas du “pull”, c’est le consommateur qui envoie une demande de n éléments pour le producteur. Ce dernier lui retourne de zéro à n éléments suivant ce qu’il possède en stock, ou bien il calcule à la demande les messages à communiquer. Dans ce mode de fonctionnement, on remarque que le consommateur n’est jamais sous pression puisqu’il est maître du nombre d’éléments émis par le producteur. C’est le producteur qui doit gérer un stock de messages en attente ou calculer les messages à la demande.
La “back-pressure”
Pour éviter les problèmes de pression, il est nécessaire d’utiliser des stratégies de gestion de la pression, pour avoir une rétroaction vers le producteur. Ainsi, ce dernier peut réduire le volume et le nombre de message émis, le temps que le consommateur puisse récupérer une capacité à les traiter. Ce sont ces différentes stratégies que l’on appelle la “back-pressure”. Nous allons voir dans cet article, différentes approches, stratégies et composants pour traiter les problématiques de gestion de pression. La back-pressure consiste à signaler en amont (explicitement ou implicitement), à son ou ses producteurs, que le consommateur est en surcharge. La pression est reportée plus en amont dans la chaîne de traitement, vers un endroit plus adapté, plus proche du client du système / application. De nombreuses approches existent dans d’autres domaines depuis longtemps, adaptées à l'électronique, aux réseaux, les processus industriels, etc. Les difficultés surviennent lorsque le débit du producteur est plus rapide que le débit du consommateur. L’approche pull ci-dessus est une première stratégie de back-pressure. Le principal enjeu de la back-pressure est de permettre aux applications de bénéficier d’une meilleure élasticité (ou scalabilité) et d’améliorer leur résilience. Dans ce but, on cherche à :
- optimiser l’échange de messages afin de mieux utiliser les ressources
- répartir la charge plus efficacement (en prévenant les points individuels de défaillance)
- améliorer la latence globale de l’application / système (en évitant ces même points individuels de défaillance).
La spécification “Reactive Streams”
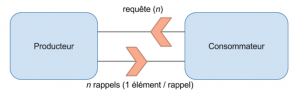
Dans les architecture réactives, le besoin d’obtenir de la back-pressure dans les échanges entre consommateurs et producteurs a vite émergé. Un collège d’experts issus de plusieurs entreprises (RedHat, Netflix, Typesafe, etc…) a créé une spécification : Reactive Streams. Son but est de définir un ensemble d’interfaces et de méthodes pour gouverner les échanges de données dans les communications asynchrones afin d’offrir un système de gestion de la back-pressure efficace et normalisée. Elle repose notamment sur la généralisation de l’utilisation du mode pull avec fourniture des n éléments requis par le consommateur par appels séquentiels réalisés par le producteur (figure 4), permettant ainsi de mieux gérer la disponibilité des éléments requis côté producteur. Cette spécification introduit également la notion de processeur qui possède à la fois les caractéristiques du producteur et du consommateur. Il s’agit typiquement d’un élément intermédiaire de la chaîne de traitement, et peut être implémenté fonctionnellement sous forme de pipeline de traitements.
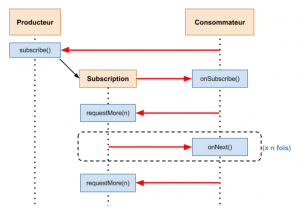
Cette spécification permet ainsi de relier différentes technologies qui ont choisi de la respecter, telles qu’un producteur utilisant Akka Streams et un consommateur dans Spark Streaming. L’information de pression peut remonter la chaîne de traitement pour propager la gestion de la pression au delà des frontières de la brique technologique à l’origine de la back-pressure.
Reactive Streams propose une version 1.0 de son API en Java. Des versions Javascript et protocole réseau sont également disponibles. Nombre d’éditeurs Open Source ont déjà adopté cette spécification, et certains en ont déjà releasé une implémentation. Parmi eux, nous citons : Akka Streams, Vert.x, Reactor, Spark Streaming, RxJava. Cette spécification suggère par ailleurs l’utilisation d’un push-pull dynamique pour répondre aux problèmes posés par un système en pur pull ou en pur push. Ce mode sera abordé plus en détail plus bas dans l’article.
Stratégies de Push
Comme indiqué précédemment, pour éviter une surcharge du consommateur dans une communication en push, il est nécessaire d’utiliser des stratégie de back-pressure. Ce modèle étant éprouvé depuis longtemps, notamment dans les chaînes de traitement et dans certains protocoles, on y trouve plusieurs stratégies, dont les plus utilisées sont :
- Approche protocolaire (Xon/Xoff)
- ACK/NACK
- Push-back
Le Xon/Xoff
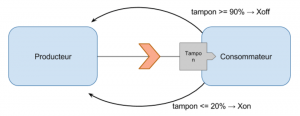
Cette stratégie repose sur l’exploitation de deux messages spéciaux, envoyés par le consommateur vers le producteur. Par exemple, lors d’une communication physique via un câble série (RS232 par exemple), il existe un tampon qui accumule les caractères reçu avant qu’ils ne soient consommé par les applications. Ce tampon ayant une taille fixe, il y a un risque de le remplir et de perdre les caractères suivant. Pour éviter cela, un protocole consiste en envoyer un caractère XOFF (Ctrl-S, 0x13) dès que 80% du tampon est plein. Cela laisse le temps à l’information à arriver vers le producteur, avant la saturation du tampon. Ce dernier cesse alors d’envoyer des caractères. Lorsque la taille du tampon tombe à 20%, un caractère XON (Ctrl-Q, 0x11) est envoyé pour informer qu’il est possible d’envoyer les prochains caractères. Cela doit être traité avant l'assèchement du tampon. Cette approche de gestion logicielle du flux de traitement est une approche de back-pressure, gérée par le consommateur. L’idée pour appliquer cette stratégie dans le modèle push est de définir deux niveaux pour le tampon : haut et bas, fixés empiriquement selon la vitesse remplissage de ce dernier. Le tampon ne doit pas saturer avant que le producteur n’ait reçu le message d’arrêt. De la même façon que pour le protocole RS232 défini ci-avant, lorsque la taille du tampon dépasse la valeur haute, le consommateur envoie un message à son producteur pour demander l'arrêt de l’émission de nouveaux éléments. Une fois le tampon redescendu sous la valeur basse, il envoie un message de reprise au producteur. Parmi les impacts à noter pour ce mode, on relève qu’une perte de messages est possible dans le transit si la communication est rompue entre producteur et consommateur (le Xoff n’est pas reçu par le producteur et ce dernier continue à envoyer des messages qui ne seront donc potentiellement pas traités). Par ailleurs, de la latence peut être constatée lorsque les messages de Xon ou Xoff ne sont pas traités immédiatement une fois réceptionnés par le producteur en raison de l’encombrement de son propre tampon.
Le ACK/NACK
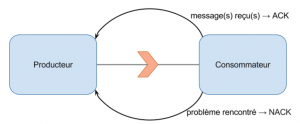
Le modèle ACK, pour ACKnowledgement (acquittement), consiste à envoyer au producteur un message spécifique pour valider la réception d’autres messages (un par un, les x derniers messages, etc). C’est une approche où la gestion de la pression est effectuée conjointement par le producteur et le consommateur et où l’acquittement sert de vecteur de gestion de la pression. Cette stratégie est notamment utilisée dans le protocole TCP (ce qui fait partie des différences avec le protocole IP). Dans les piles TCP/IP, il y a des tampons ayant une taille limitée (backlog de connections, comment le backlog TCP fonctionne). Le producteur de la donnée utilise un tampon local des paquets en cours d’émission. Chacun doit être acquitté par le consommateur. Cela permet la réémission du paquet après un délai arbitraire sans attendre l’acquittement (méthode ARQ). Cela permet également de gérer la pression dans le TCP au niveau du consommateur. Lorsque tous ses tampons sont pleins, il ignore les nouveaux paquets et envoie un NACK (Negative-ACKnowledgement) où aucun acquittement n’est alors émis. Le paquet sera réémis plus tard par la pile IP du producteur. Différentes stratégies permettent au producteur d’identifier le débit maximum toléré par le consommateur et les différentes erreurs potentielles. Suivant les stacks IP, les stratégies sont composées.
- Slow start - pour identifier le débit possible en l’augmentant progressivement
- Congestion avoidance - pour ajuster le débit rapidement
- Fast retransmit - pour identifier des erreurs rapidement par la multiplication des ACK
- Fast recovery - pour reprendre rapidement un débit nominal
Il est à noter que les approches utilisées par Windows et Linux sont différentes. En ajustant dynamiquement les fenêtres de réception et/ou d'émission (cwin), une application peut propager à sa pile IP une situation de pression applicative. Ainsi, les clients réduiront naturellement le débit réseau grâce au protocole sous-jacent. Certains algorithmes ne sont pas adaptés pour des réseaux rapides et disposant d’une importante bande passante (plusieurs gigabits par seconde). D’autres algorithmes permettent alors de garder le débit le plus proche possible de la bande passante disponible pour des réseaux rapides. Dans le framework d’acteurs Akka, Lightbend (ex. Typesafe) a rajouté un module TCP pour gérer les connexions TCP : Akka TCP. Il est basé sur un modèle de communication par acquittement décliné en trois variantes :
- ACK : à chaque commande d’écriture sur le socket, un message arbitraire est envoyé en plus, si l’écriture est réussie, ce message est renvoyé par le consommateur et le producteur peut alors envoyer une nouvelle commande
- NACK : si un message que le consommateur ne peut traiter arrive, ce dernier retourne un message d’échec qui peut également contenir le message provoquant cet échec (similaire à du push-back, abordé ci-après)
- NACK avec suspension : lorsque le consommateur renvoie un message d’échec, le producteur n’émet plus de commande tant que le consommateur n’envoie pas un message de reprise lorsqu’il aura traité toutes les commandes déjà reçues (proche du mode XON/XOFF)
De manière plus générale, le mode ACK/NACK a l’avantage de ne pas risquer la perte de messages en raison de rupture éventuelle de communication. Inversement, il occasionne l’échange et le traitement d’un plus grand nombre de messages, d’où un overhead réseau et CPU.
Le Push-back
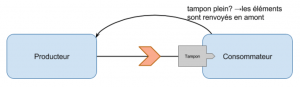
Le principe du push-back repose sur le rejeu des éléments. Une fois que le tampon du consommateur est plein, les messages “poussés” suivants sont renvoyés au producteur. Cela a plusieurs impacts :
- Il est alors possible de renvoyer le message vers un autre consommateur, sous le contrôle du producteur
- Le producteur est également un consommateur en mode push des messages qui reviennent
- Le producteur n’a pas de garantie qu’un message ne va pas revenir, ou qu’il va être effectivement traité
- Si un problème survient dans la couche transport, pendant le transit, un message peut être perdu (déjà publié par le producteur, mais perdu en route ver le consommateur ou refusé par le consommateur et perdu sur le retour)
Les éléments renvoyés peuvent dépendre du cas d’usage ou du métier. On peut par exemple choisir de renvoyer les plus vieux, les plus récents, les moins prioritaires ou encore le tampon en entier. Cette approche présente l’avantage d’injecter plus de spécificité métier dans la stratégie du consommateur, ce qu’on ne retrouve pas dans les autres stratégies de push. Le consommateur peut également déléguer le message vers un autre consommateur, si cette stratégie n’est pas trop gourmande en ressources. Mais cela relève plutôt de la mauvaise pratique car la gestion des consommateurs devrait être centralisée au niveau du producteur pour une gestion plus efficace de la pression.
Stratégies de Pull
De même que dans le push, il existe plusieurs stratégies de back-pressure dans le mode pull, dont les principales sont :
- Le Pull simple
- Le Watermark
- Le Max in flight
Le Pull simple
Le modèle le plus simple du pull, consiste à demander les éléments un par un. C’est l’équivalent de l’approche ACK mais en sens inverse : la transmission du message est ici initiée par le consommateur. Le principal défaut de ce modèle est le nombre de messages émis et la latence. Pour chaque donnée produite, deux messages ont été émis : la demande et le message. Une quantité supplémentaire de communication et de bande passante est nécessaire relativement à un push simple. Le second problème réside dans le fait qu’entre le moment où une nouvelle requête est émise et le moment où la donnée associée arrive, le consommateur n’a rien à faire. Ce temps d’inactivité est perdu et n’est pas mis à profit pour traiter d’autres messages. Les autres approches de pull se proposent de demander le plus de messages possible dans la même requête, en mode “micro-batch”. Cela permet d’une part de remplir rapidement le tampon du consommateur pour minimiser les chances qu’il soit oisif et, d’autre part, de réduire le round-trip ainsi que le volume réseau.
Le Watermark
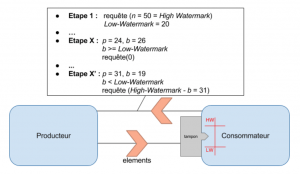
La stratégie Watermark est typiquement adaptée à des consommateurs effectuant eux-mêmes le traitement des messages (sans délégation à d’autres entités). A la façon d’un Xon/Xoff, on définit deux valeurs limites. Ces limites peuvent être ajustées dynamiquement par le consommateur selon son niveau de saturation. La High-Watermark correspond à la taille maximale à requéter, alors que la Low-Watermark est une limite basse servant à tenter de garantir un apport constant d’éléments pour le consommateur. La figure 10 présente le fonctionnement typique de la stratégie Watermark, où sont définies les quantités suivantes :
- p : les éléments reçus
- b : les éléments restants à recevoir
La demande de messages au producteur prend alors en compte le nombre de messages en transit (demandés mais non encore reçus, b). Le nombre d’éléments requétés à tout moment au producteur ne dépasse jamais la High-Watermark. Aucune nouvelle demande n’est lancée tant que le nombre de requêtes en transit dépasse la Low-Watermark. C’est le cas notamment dans le framework Akka Streams, où le tampon se trouve être la mailbox des acteurs et est dissocié du fonctionnement de cette stratégie. A chaque élément reçu, on attend de finir son traitement avant d’évaluer la prochaine requête, qui peut être nul. Ce fonctionnement tente de garantir au consommateur d’avoir constamment des éléments à traiter.
Max in Flight
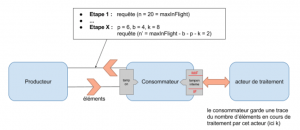
Le fonctionnement du “Max in Flight” est plus évolué que celui de la stratégie précédente, où on considère de plus la quantité :
- k : ce qui est considéré comme étant “In Flight” et représente ce qui est en cours de traitement voire à traiter, typiquement spécifique au métier du consommateur
Cette stratégie est typiquement adaptée à un consommateur n’effectuant pas lui-même tout ou partie du traitement des messages reçus. Par exemple, les éléments “In Flight” peuvent correspondre aux éléments en cours de traitement en aval du consommateur (par des acteurs de traitement), voire des éléments à traiter et stockés dans le tampon interne. Dans les couches Akka Streams, l’implémentation du calcul de cette valeur est d’ailleurs librement adaptable. Si le nombre d’éléments à demander est n’, la somme ( b + p + k + n’ ) ne doit à aucun moment dépasser la valeur “maxInFlight”. Les éléments en cours de traitement sont alors également pris en compte dans le calcul des éléments à demander. Cette stratégie permet d’intégrer la capacité instantanée de traitement des éléments et d’adapter à celle-ci le nombre d’éléments demandés. Elle permet également d’optimiser l’utilisation du consommateur en veillant à provisionner des éléments à traiter et éviter les temps d’attente pour effectuer les traitements.
Stratégies mixtes
N’utiliser qu’une approche push n’est pas efficace lorsque le consommateur est lent. L’approche pull n’est pas efficace lorsque que le consommateur est rapide. Il existe des stratégies qui combinent les deux approches push et pull. La difficulté consiste à choisir les conditions de basculement d’une approche à une autre et d’éviter de basculer trop régulièrement.
Le Push-Pull Dynamique
Le concept de base du push-pull dynamique consiste à passer dynamiquement d’un mode pull à un mode push selon le rapport de vitesse entre consommateur(s) et producteur. L’idée est de pouvoir adapter des stratégies différentes dans chacun des deux modes. Par exemple un push avec un ACK et un pull en Watermark. Dans le cas où le producteur est plus lent que le consommateur, on privilégie le mode push. A l’inverse dans le cas d’un producteur plus rapide, on choisi le pull qui permet de gérer naturellement la pression, en laissant les messages en attente dans le producteur. Dans la pratique, le (rare) push-pull dynamique que l’on peut trouver (Akka Streams), est une implémentation en pur pull avec une demande sans limite pour passer à en mode “équivalent à un push”. Si le consommateur est plus rapide que le producteur, le nombre d’éléments requétés sera toujours plus important que le nombre d’éléments que peut fournir le producteur. Le producteur n’aura donc pas à attendre pour émettre la donnée et l’émet immédiatement, ce qui se rapproche du mode push mais reste conceptuellement du pull. Ce fonctionnement peut donc être qualifié de push-pull dynamique. Reactive Streams propose également la solution “request(Long.MaxValue)” (requête du nombre maximal d’éléments autorisés par le langage), ce qui représente conceptuellement une requête d’un nombre infini d’éléments et provoque implicitement un fonctionnement en push. Dans ce cas, le consommateur semble condamné à subir ce mode indéfiniment. Il est alors conseillé de prévoir une implémentation du producteur permettant de débrayer ce mode. Cela pourrait être un retour au mode pull à la réception d’une requête d’un nombre inférieur d’éléments.
Push/Pull et Pull/Push Hybrides
Certaines stacks techniques, telles que CORBA (Event Service) et les technologies P2P, des stratégies mixtes de type hybride sont utilisées :
- le Push/Pull, où les consommateurs demandent en mode pull des évènements à un Event Channel, qui est lui même alimenté en mode push par un producteur
- le Pull/Push, où les consommateurs sont alimentés en mode push avec des évènements à provenant d’un Event Channel, qui récupère ces derniers en mode pull à partir d’un producteur
Il n’y a pas de bascule dynamique d’un mode à l’autre, le choix d’un mode est définitivement adopté à la conception des services.
Stratégies alternatives
Il existe des solutions qui ne sont pas basées sur les principes de push ou de pull.
Bloquer le producteur
Une approche proposée par RxJava comme alternative à la back-pressure consiste à bloquer le thread du producteur, avec un verrou classique, et de le relâcher une fois que la pression devient acceptable. Elle a cependant le désavantage d’aller a l’encontre du Manifeste Réactif et de mobiliser des ressources.
Conclusion
Nous avons identifié dans cette partie les différentes formes de back-pressure possibles ainsi que les différentes stratégies qu'il est possible d'utiliser. Concrètement, une chaîne de processus dont des maillons reçoivent des informations de pression par back-pressure doit prendre des mesures pour faire baisser la pression. Oui, mais comment ? Nous donnerons les réponses dans la Partie II de cet article_._
Bibliographie
- (reactive-streams.org). « Reactive Streams. » http://www.reactive-streams.org/
- (Typesafe). « Akka Streams Documentation, Scala. » http://doc.akka.io/docs/akka-stream-and-http-experimental/2.0.1/scala.html
- Bonér J., Farley D., Kuhn R., Thompson M. « Le Manifeste Réactif. » http://www.reactivemanifesto.org/fr
- (Wikipedia). « Push–pull strategy. » https://en.wikipedia.org/wiki/Push%E2%80%93pull_strategy
- (Vertx.io). « Vert.X Documentation. » http://vertx.io/docs/
- (Netflix). « Back-pressure in RxJava. » https://github.com/ReactiveX/RxJava/wiki/Backpressure
- François G. « Spark Streaming back-pressure signaling. » https://docs.google.com/document/d/1ZhiP_yBHcbjifz8nJEyPJpHqxB1FT6s8-Zk7sAfayQw/edit
- (spark.apache.org). « Spark 1.5.2 Documentation. » http://spark.apache.org/docs/1.5.2/index.html
- (Typesafe). « Back-pressure — Akka Documentation. » http://doc.akka.io/docs/akka-stream-and-http-experimental/2.0-M2/scala/stream-flows-and-basics.html#back-pressure-explained-scala
- (Typesafe). « Akka Documentation, Scala. » http://doc.akka.io/docs/akka/2.4.1/scala.html
- (projectreactor.io). « Reactor. » http://projectreactor.io/docs/
- (Wikipedia). « Backpressure routing - Wikipedia, the free encyclopedia. » https://en.wikipedia.org/wiki/Backpressure_routing
- Gregoire J., Qian X., Frazzoli E., De La Fortelle A., Wongpiromsarn T. « Capacity-Aware Backpressure Traffic Signal Control ». IEEE Trans. Control Netw. Syst. 2015. Vol. 2, n°2, p. 164‑173.
- Stone J. The impact of supply chain performance measurement systems on dynamic behaviour in supply chains. Aston University, 2012.
- Vernon V. Reactive Messaging Patterns with the Actor Model: Applications and Integration in Scala and Akka. Addison-Wesley Professional, 2015.