Les principes du data mesh en 2021
Le data mesh est un paradigme, et en tant que tel, il propose une modélisation technique, méthodologique, et organisationnelle pour appréhender les nouveaux défis que pose la gestion de la donnée à grande échelle. C'est un concept innovant et encore en évolution. Cet article dresse un état des lieux des principes du data mesh en ce début d'année 2021.
À la différence des approches classiques d’entrepôts de données ou des data lakes, ce paradigme repose sur une gestion et exposition décentralisée de la donnée. Les données analytiques et opérationnelles sont gérées conjointement dans un périmètre délimité appelé domaine de données.
Le but de cet article est de présenter les fondements du data mesh et de poser quelques convictions issues d'expériences du terrain.
Dans un premier temps nous chercherons à comprendre à quels défis le data mesh tente de répondre. Ensuite nous définirons le data mesh en exposant et détaillant les principes sur lesquels il repose.
En conclusion, nous verrons en quoi le data mesh est un atout pour les entreprises qui veulent s'orienter vers un prisme data-driven grâce à son modèle qui optimise l'accès à la donnée et à sa valorisation.
Nous verrons que l'organisation en réseau de domaines de données permet de :
donner de l'autonomie en permettant une gestion locale des données ;
faire grandir le système en y ajoutant facilement des nœuds de manière décentralisée ;
conserver une cohérence forte de la plateforme de données (technique et organisationnelle).
La donnée, cet élément fondamental des SI modernes.
Commençons par poser un peu de vocabulaire. Ainsi, nous définissons :
une donnée comme étant un ensemble de bits ;
une information comme étant une donnée dont le sens est défini par un ensemble de règles.
Les conséquences de ces définitions sont que:
la donnée n’est qu’un support d’information;
l’information que l’on peut extraire d’une même donnée peut varier en fonction des règles métier (par exemple, 32 degrés centigrade est une donnée, chaud/froid est une information car selon le contexte et les règles qui le régissent “32 degrés” sera tantôt chaud, tantôt froid)
La connaissance est l’ensemble de l’information structurée.
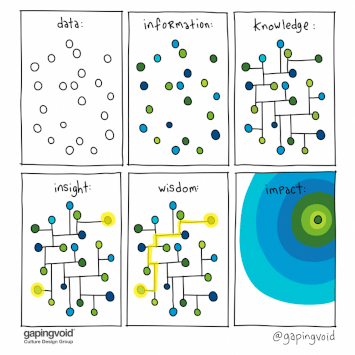
Ajoutons à présent deux définitions:
Nous qualifierons de données opérationnelles, les données nécessaires au fonctionnement du métier. Ce sont l’ensemble des données qui permettent aux applications de réaliser des opérations métier. Ces données sont en général adressées de manière transactionnelle au travers d'opérations élémentaires telles que Create, Read, Update, Delete (CRUD). Par exemple, la création d’un profil utilisateur ou d’une commande sur un site e-commerce sont des données opérationnelles.
Si on considère la dimension temporelle des données opérationnelles et que l’on ajoute des règles d'enrichissement, d'agrégation et de gestion métier, nous obtenons des données analytiques. Les données analytiques sont porteuses de promesses d’optimisation du métier (via la Business Intelligence ou BI) et d’avantages concurrentiels insufflés par l'ère du big data et du machine learning.
L’ensemble de ces données (ou informations), constitue la connaissance métier sous forme numérique.
Comment gérer cette mine d’information : le paradigme classique de la centralisation
Les données opérationnelles sont, de manière courante, gérées au plus près des applications. Ainsi, il est de plus en plus rare de voir de grosses bases de données centralisées qui regroupent l’ensemble des données opérationnelles (exception faite des systèmes monolithiques tels que les ERP).
Les données analytiques, quant-à elles, sont souvent regroupées dans des entrepôts de données, voire dans des lacs de données (data lake). Le but est de concentrer l’information pour rendre l’exploitation de la connaissance plus simple.
Les difficultés principales induites par les lacs de données sont:
La complexité d’inventorier un volume de type de données toujours croissant
Faire respecter les standards de qualité de la donnée par des sources de données, elles aussi, en croissance constante
En effet, plus on ajoute de sources de données, plus le désordre augmente, et plus on s'éloigne du standard de qualité de la donnée. En guise d'illustration, essayez de ranger toutes les pièces de légo dans un grand bac; plus on ajoute de pièces issues de constructions variées (1500 pièces de l’étoile noire, 400 d’une batmobile, ...), plus le désordre augmentera. Corollairement, plus nous aurons de pièces différentes, plus il nous sera difficile de les maîtriser pour réaliser une nouvelle construction...

Ces constats ont amené ce nouveau modèle de gestion de l'information qu'est le data mesh, dans le but de permettre aux entreprises de lever ces freins et d'accélérer grâce à la donnée.
Le data mesh, une gestion décentralisée de la donnée
Le data mesh propose de pallier les problèmes évoqués précédemment en proposant un modèle de gestion de la donnée décentralisé. Ce modèle, divide et impera, est bien connu des architectes logiciels qui prônent le microservice.
Nous allons voir que le data mesh est composé d'un ensemble d'éléments appelés domaines de données. C’est l'interconnexion de ces éléments qui forment le maillage (mesh en anglais).
Le but de ce maillage reste le même que celui des lacs de données: proposer une vision d’ensemble de la connaissance exploitable dans le but d’augmenter la valeur métier.
Les piliers du data mesh
Le data mesh répond au besoin d’assurer le plus efficacement possible le passage à l'échelle de l’exploitation de la donnée sur plusieurs axes:
la réponse au changement doit être rapide : les modèles de données évoluent constamment et de manière rapide ;
le nombre de producteurs de données est en croissance permanente : nouvelles applications, ouverture des API d’un SI sur l’extérieur, etc. ;
le nombre de consommateurs de données augmente : beaucoup d’initiatives de projets “data” voient le jour avec l’avènement du machine learning ;
Pour atteindre ces objectifs, le data mesh repose sur 4 grands piliers:
Découper la connaissance en un ensemble de nœuds élémentaires appelés domaines de données (Le terme domaine est emprunté au domain driven design (DDD) d’Eric Evans) ;
Gérer la donnée dans ce domaine comme un produit (data-product) en utilisant les méthodes de product thinking ;
Utiliser une infrastructure self-service en tant que support de ces data-products ;
Appliquer une gouvernance fédérée autour de la donnée.
Nous allons à présent détailler chacun de ces points.
Le domaine de données
Un domaine de données est un découpage logique de l’ensemble des données dont dispose une entreprise. Chaque domaine de données définit une frontière dans laquelle l'ensemble des données qu'il renferme servent à représenter une information (unique).
Ce domaine est déterminé en fonction des domaines métiers qu’il sert. Par exemple, si on considère un service de livraison de repas, il peut être intéressant de définir un domaine de données "adresse" pour le client final pour optimiser ou prévoir les déplacements, là ou l'adresse d'un fournisseur (restaurant) aura probablement moins d'intérêt et pourra faire partie de sa fiche d'identité.
Une fois le domaine de données déterminé, il faut aller plus loin dans la compréhension des besoins clients. Reprenons l'exemple des adresses. Le premier besoin est opérationnel : les livreurs doivent localiser le lieu de livraison. Cependant un second besoin d'analyse apparaît : pouvoir anticiper les livraisons et proposer des promotions aux clients d'une zone déjà bien desservie afin d'augmenter le nombre de commandes.
Ce qui est fondamental dans ce modèle est que les données analytiques et opérationnelles qui servent une même information sont gérées de manière conjointe au sein du même domaine et non de manière séparée (telle qu'un backend opérationnel et un data lake gérés par des entités différentes). Dans la conception du domaine de donnée, nous pouvons séparer les applications clientes en deux catégories :
les producteurs de données qui apportent de la valeur au domaine en échange de fonctions opérationnelles (par exemple, une station météo connectée peut fournir à un domaine la donnée de température du lieu courant, en échange ce dernier peut lui fournir la température d'un autre lieu, tel que le lieu de vacances qui aura été transmis par un autre thermomètre connecté)
les consommateurs de données qui extraient de la valeur des applications pour augmenter la valeur métier (par exemple, au vu des relevés des stations météo alentours, on peut prédire le temps qu'il va faire et la fournir aux applications des smartphones)
Un client peut être à la fois producteur et consommateur de données.
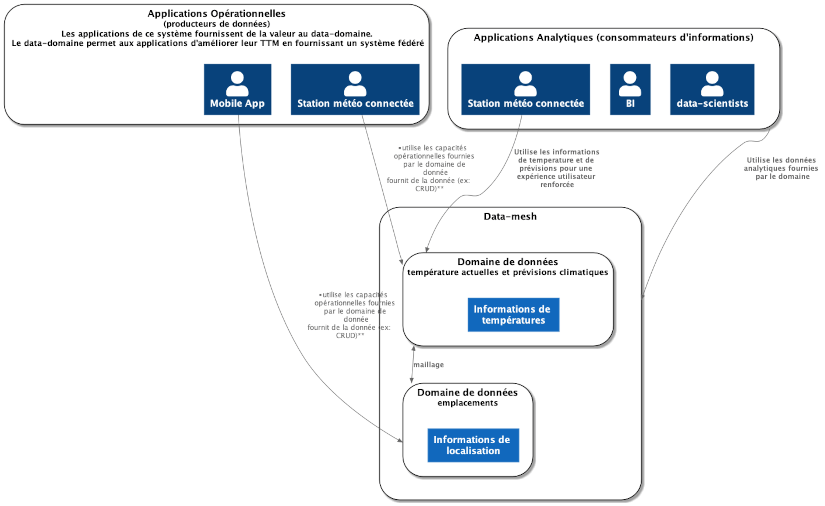
Exemple visuel qui représente un domaine de données du point de vue du macroscopique (data mesh).
Au vu de cette architecture, nous pouvons faire les constats suivants:
les pipelines de données sont absents de cette représentation car ils ne sont plus un système de gestion à part entière, mais un élément interne à chaque domaine ;
la décomposition des éléments n’est plus technologique (construit autour d’un système central de stockage objet), mais orientée autour de domaines pouvant être corrélés au métier.
Ce découpage autour de l’information permet de définir de manière rigoureuse:
la signification des données dans le contexte du domaine ;
la signification des informations en regard du contexte métier.
Tout comme le concept d_’ubiquitous language_ dans le DDD, ceci facilite la communication entre les développeurs et les producteurs/consommateurs des données et informations
La premier changement de paradigme se trouve dans le fait que les domaines de données vont faire coexister les données opérationnelles et les données analytiques.
Ainsi, la scission entre les procédés de gestions analytique et opérationnelle est supprimée. L’ensemble de l'information gérée dans le domaine est gérée par un data product owner dont le rôle sera de s’assurer que les capacités opérationnelles permettent d’obtenir de la donnée opérationnelle fiable, utile et propre dans le but d’obtenir et de fournir une information de qualité. Le service mis à disposition des applications opérationnelles clients du domaine de données est donc presque une conséquence et non une cause.
Ci-dessous, un exemple de représentation C2 (c4model.com) du domaine de données et de son data-product
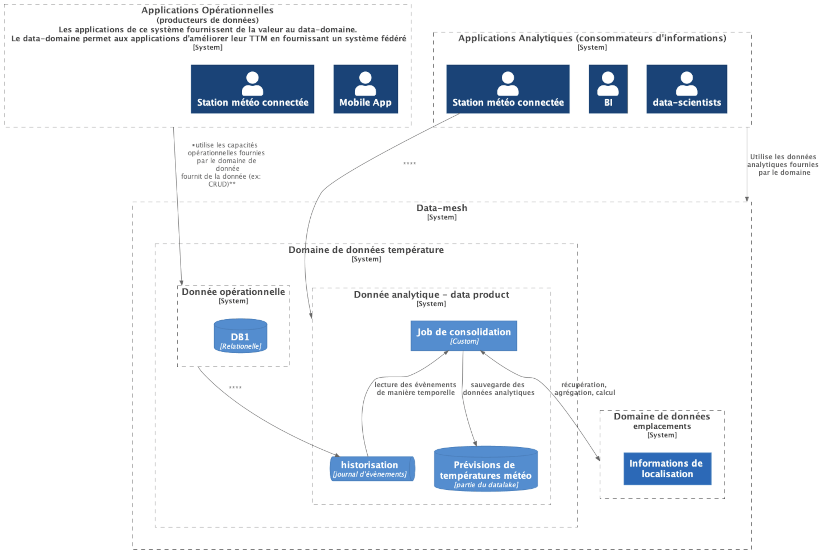
La donnée en tant que produit
Le domaine de données a permis de délimiter les frontières dans lesquelles la donnée a un sens, une valeur et une qualité précise. Voyons à présent comment représenter la donnée en tant que produit dans ce contexte.
Traiter la donnée en tant que produit va permettre d’appliquer les principes du product thinking à notre contexte. Le but est de permettre aux consommateurs d’informations de pouvoir découvrir, comprendre et utiliser des données hautement qualitatives.
Pour Marty Cagan (cf Product Is hard - video ou Inspired - livre), un bon produit doit:
apporter de la valeur - les clients choisissent le produit pour la valeur qu’il apporte ;
être utilisable - son utilisation doit être évidente ;
être réalisable - en utilisant les compétences et la technologie à disposition.
Ceci amène les caractéristiques techniques auxquelles devront répondre nos data-products:
être partagés et découvrables ;
être auto-suffisants (le produit peut être utilisé seul, sans avoir besoin d’autres données pour le comprendre et l’exploiter) ;
être utilisables ;
être inter-opérables (gouvernés par des standards d’échange) ;
exposer leur contrat de service et de qualité pour amener la confiance ;
être sécurisés (gouvernés et contrôlés par une instance vérifiable et globale).
Trust: a confident relationship to the unknown
Rachel Botsman
Afin de permettre la mise en place de ces différents data-products, il est donc important de disposer:
d’outils qui permettent de valider la qualité des données ;
de standards d'échanges inter-domaines ;
Ceci doit permettre aux data-products d'être autoportants (nous aborderons ce point par la suite dans la partie maillage et gouvernance).
Ainsi, dans un domaine de données, nous saurons qu'un data-product fournit des données portant une information précise. Corollairement, dans l'écosystème global, nous saurons que si nous avons besoin d'une certaine information, nous la trouverons gérée par un data-product spécifique.
Le but est de rentrer dans un cycle d’intelligence continue telle que décrite sur le site de Thoughworks par Ken Collier, Mark Brand et Pramod N
Comme dans toute architecture distribuée, un élément clé de réussite est d’assurer l’autonomie des nœuds et de maîtriser le couplage entre les éléments. Par conséquent, il est souhaitable de disposer d’informations autosuffisantes au sein d’un domaine. Ceci peut passer par une duplication ou une dénormalisation des informations entre les nœuds. Par exemple, si deux informations de deux domaines différents utilisent une même donnée, il est préférable de copier l'information d'un nœud vers l'autre plutôt que de travailler par référence.
Le maillage
Nous avons décrit comment repenser la gestion de l'ensemble des données d'une entreprise en la découpant et la regroupant dans des domaines de données.
Afin d'exploiter au mieux la connaissance d'un point de vue métier, et de transformer cet ensemble d'unités en un tout, il est nécessaire de donner de la cohérence à l'ensemble.
Le maillage est régi par un ensemble de règles communes issues d'un système de gouvernance fédéré, ainsi que par des standards technologiques communs.
Pour faire partie d'un mesh, les domaines de données doivent exposer la sémantique et la syntaxe des informations qu'elles gèrent dans un vocabulaire commun à l'ensemble du réseau.
Un système à base d'ontologie est un exemple de règles qui vont permettre aux personnes qui vont consommer les informations métier (telles que des knowledge-scientists par exemple) de comprendre la valeur de la connaissance contenue dans le réseau et d'en exploiter la valeur.
Une gouvernance de donnée fédérée
Chaque domaine de données agit comme une entité autonome au sein d’un tout qu’est le système data mesh. Afin de garantir cette autonomie, les règles qui s’appliquent aux différents data-products sont régies par les principes internes du domaine de données.
La gouvernance des données permet de définir, entre autres, les droits et devoirs concernant la mise à disposition des différentes informations au sein du SI. Elle est également responsable de la mise en place de métriques sur la qualité globale.
Le résultat des actions de la gouvernance fédérées sont un ensemble de règles qui définissent les standards d'accessibilité, de qualité et de sécurité de la donnée. La gouvernance pose un cadre de travail qui définit les principes constitutionnels du data mesh, tout en laissant la responsabilité aux domaines de données de définir et faire respecter leur règles dans le data mesh.
Par exemple, dans le cas des données à caractère personnel, la gouvernance imposera que l'ensemble des data products gérées dans le data mesh soient compatibles avec la réglementation en vigueur (telle que la RGPD par exemple). Chaque domaine appliquera ensuite sa propre politique d'accès en fonction de la nature des données qu'elle gère (données à caractère personnelle directe ou données pseudonymes par exemple).
Les principes du data mesh ne posent que les principes de gouvernance, sans, à l’heure de l’écriture de cet article, donner de recette de mise en place. Cependant, de nombreuses études se basant tantôt sur les principes érigés par le livre “team topologies” de Matthew Skelton et Manuel Pais, ou encore sur la sociocratie sont à l’étude. Elles feront l’objet d’un prochain article.
Un plateforme self-service
Donner de l'autonomie aux équipes qui gèrent les domaines de données ne signifie pas qu'il faut les laisser réinventer la roue sans capitaliser sur les outils et expériences.
Un des piliers du data mesh passe par la mise en place d'une plateforme self-service qui regroupe l'ensemble des éléments technologique atomiques.
Ces éléments technologiques, considérés comme des commodités eu égard aux domaines métier, doivent être agnostiques des domaines de données .
Le rôle de la plateforme de données est de fournir un catalogue de services utilisables par les développeurs des data-products afin d’accélérer le développement et le time to market.
Le succès d'une bonne data plateforme en support du data mesh se mesure, par exemple, grâce au niveau de satisfaction des équipes qui construisent les data products ou encore du temps entre lequel un data product est conçu et le moment où il devient utilisable.
la plateforme n'est pas un ensemble de pipelines de données
Synthèse et conclusion
Le data mesh n’est pas seulement une façon de modéliser et gérer les plateformes de données. C’est avant tout une façon de penser la donnée en tant que produit. Le produit n’est plus ce micro-service qui sert les opérations courantes du métier et qui en conséquence accumule de la donnée. La donnée est le produit. Les services ne sont qu'un moyen de récupérer cette dernière.
Ainsi les indicateurs de niveau de services (SLI/SLO) devront être adaptés pour refléter les exigences de qualité de données (par exemple, les indicateurs d'exactitude deviendront prépondérants, là où les indicateurs de disponibilité sont aujourd’hui les plus travaillés).
En conclusion, le data mesh n’est pas une version 2.0 du datalake. C’est un réel changement de paradigme qui doit être une conséquence de la politique d’exploitation de la donnée portée par une organisation. En effet, ce changement a un impact fort sur la conception de produit ainsi que sur l’organisation.
Néanmoins, il ne faut pas pour autant jeter toutes les pratiques technologiques existantes autour des datalakes. En effet, si votre système d’échange repose sur les piliers “Store/Share/Play” (avec des systèmes tels que AWS S3, Glue, Athena et cloudformation par exemple), la transition vers une organisation data mesh sera d’autant plus simple car votre lake propose déjà un cloisonnement logique des données ainsi qu’une gestion des habilitations.
Pour résumer: le cercle vertueux du data mesh consiste en plusieurs étapes:
délimiter un domaine de données ayant pour but de récupérer de la donnée et en extraire de l'information.
ce domaine de données devient un nœud du maillage de données grâce aux principes directeurs d'échange, d'interopérabilité et de l'ontologie…
tout ceci dans le but de produire des produits logiciels à forte valeur ajoutée pour le métier.