Les nouvelles approches d’optimisations
Le code le plus rapide est le code qui n’est jamais exécuté. Comment réduire au maximum le nombre d’instructions pour exécuter un traitement ? Il faut utiliser des chemins rapides, extrêmement courts, remettant en cause quelques fondamentaux.
Après avoir optimisé votre code, exploité au mieux les caches de niveaux 1 et 2 des processeurs, utilisé des algorithmes lock-free, que reste-t-il à optimiser ? Le temps d’exécution dans l’OS.
Un OS est conçu pour distribuer et isoler la CPU vers différentes applications, distribuer la mémoire physique, permettre la communication avec les composants électroniques via des drivers et proposer un gestionnaire de fichiers. Les approches utilisées sont généralistes, afin de répondre convenablement à la très grande majorité des applications. Mais être généraliste est souvent incompatible avec “performant”.
Prenons l’exemple de la récupération d’un flux réseau via un socket. Que se passe-t-il dans les faits ?
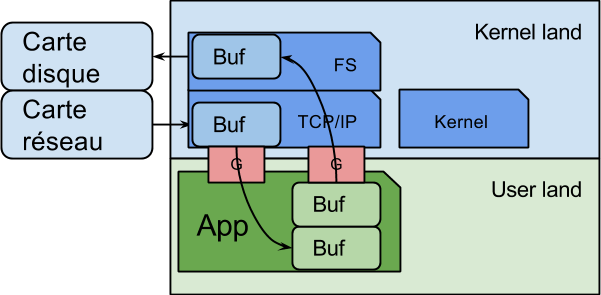
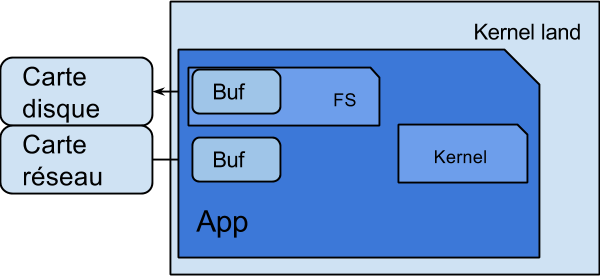
La carte réseau reçoit un paquet. Il est gardé dans un tampon dans la carte ou directement écrit dans une zone mémoire dédiée du kernel (en DMA), et une interruption est déclenchée sur le processeur. Un code du noyau se charge de traiter cette interruption pour récupérer le paquet réseau dans sa mémoire. Puis le tampon est recopié dans une zone mémoire de l’espace utilisateur pour qu’il puisse consulter les données. L’application peut alors lire les données du réseau, produire d’autres paquets avant d’en informer le kernel. Ce dernier duplique la mémoire de l’espace utilisateur vers un tampon de l’espace mémoire du noyau, et demande à la carte réseau de se charger d’envoyer le paquet sur le réseau.
Si vous utilisez un langage avec gestion automatique de la mémoire, il y a généralement encore une copie de la zone mémoire utilisateur vers la zone mémoire gérée par le ramasse miette. C’est souvent le cas dans le code des JVM. Puis l’application extrait des différents paquets, un tableau de bytes avec l’intégralité d’une page par exemple ou extrait les en-têtes dans des chaînes de caractères. Encore des copies de tampon.
Nous constatons que pour un seul paquet réseau, il y deux, trois voire plus de copies de la mémoire, dans des endroits différents.
La même approche est utilisée pour lire ou écrire des données sur le disque.
Et à chaque fois qu’il faut passer de l’espace utilisateur à l’espace kernel, il faut traverser une gateway qui consomme de la ressource (interruption, sauvegarde des registres, suppression des caches L1 et L2, etc.)
Pour une écriture disque, le flux de traitement peut être résumé ainsi avec une JVM:
- Alimentation d’un tampon à écrire sur disque
- Appel de l’API write()
- Passage par JNI pour invoquer une fonction java_io_write(JNIObject*,...)
- Appel de la glibc
- Appel de syscall() avec un numéro d’API système (passage par un handle système)
- Context switch (flush des caches des processeurs, des TLB, etc.)
- Sélection du traitement par le kernel
- Copie du tampon de l’espace utilisateur dans un tampon de l’espace kernel
- Calcul de la position physique sur le disque
- Invocation du contrôleur disque pour lui demander d'écrire le tampon
- Attente de l’acquittement
- Retour de l’acquittement à l’application
- Context switch pour retourner en espace utilisateur
- Retour du JNI pour informer l’API Java
- Prise en compte par l’API Java
Cela fait pas mal de boulot. S’il est possible de supprimer des étapes, on gagne en performance. Oui, mais comment ?
Supprimer les VM
Comme les ressources sont souvent mutualisées dans les mêmes serveurs physiques, à l’aide de machines virtuelles, il y a autant d’OS que de VM. Les OS sont eux-mêmes sous le contrôle de l’hyperviseur qui joue le rôle de meta-OS.
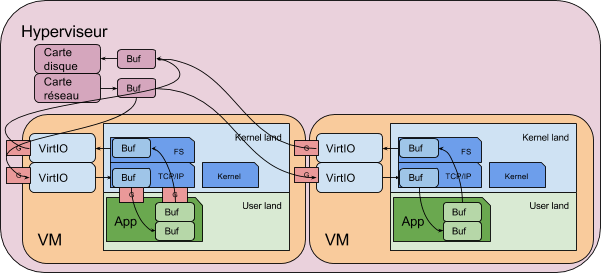
Notez que ce dernier peut ajouter une réplication des buffers et qu’il y a un franchissement de Gateway supplémentaires via les VM_Exit.
Pour améliorer cela, il faut mutualiser le kernel de l’OS, en containerisant les applications. Cela permet de supprimer la couche de virtualisation.
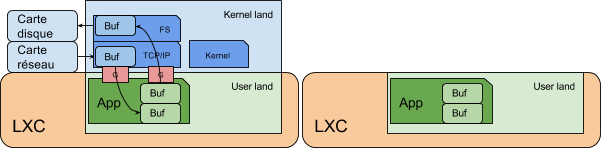
Des solutions comme LXC, LXD ou Docker (limité à un seul processus) permettent cela. En dédiant des cartes réseaux à chaque conteneur, il n’y a aucun impact sur les performances.
Zéro copy
Un autre contournement de l’OS consiste à utiliser des API spécifiques pour éviter ces copies vers les zones mémoires applicatives. Cela est possible dans certaines conditions, lorsque le paquet du réseau peut être directement copié sur disque, où l’inverse. L’idée est d’indiquer la source et la destination, et laisser le kernel s’occuper de transférer les données, sans que l’application ne puisse voir le contenu des zones mémoires.
Les données du disque étant cachées dans le kernel, cela permet d’exploiter astucieusement le cache kernel, pour éviter les copies en espace utilisateur.
Par exemple, le logiciel Kafka (kafka.apache.org) utilise stratégiquement cette approche. Le code est intégralement conçu pour exploiter autant que possible du Zero copy. Ce composant se charge de gérer des fils de messages binaires. Il gère des clusters et de gros volumes de données avec des performances foudroyantes.
Notez qu’en architecture ARM (Android, iPhone, etc.) il est possible d’utiliser le DMA pour un transfert direct entre périphériques, sans passer par la mémoire !
Mais cette approche n’est pas possible s’il est nécessaire de consulter les données.
Contourner la stack IP
Une autre approche pour éviter les copies, de réduire le code dans l’OS et mieux contrôler les flux réseaux, consiste à proposer une nouvelle stack IP s’exécutant en espace utilisateur. Pour cela, il faut réserver des zones mémoires dans l’OS à des adresses fixes, et manipuler le driver des cartes réseaux pour lui indiquer où déposer les paquets manipulés sur le réseau.
Le code applicatif est alors capable de s’appuyer directement sur ces tampons, et de réagir dès l’arrivée des paquets. Avec un peu d’astuce, il n’est pas nécessaire de reconstruire un flux pour les sockets avec les contenus des différents paquets. Un accès directement à chaque portion est plus efficace. C’est bien entendu plus compliqué à coder.
Par exemple, l’API DPDK est utilisée par la base de données Scylla DB (www.scylladb.com) pour optimiser la couche réseau si besoin. Une pile IP simplifiée est alors utilisée en espace utilisateur en lieu et place de la pile de l’OS.
Garder l'hyperviseur et supprimer l’OS
Plus radical encore, il est possible de supprimer complètement l’OS. Au même titre que Docker propose un modèle d’exécution basé sur un seul processus, la solution OSv (osv.io) propose de lier physiquement le code de l’application avec le code d’un OS simplifié.
L’idée est de s’appuyer sur la glibc pour en proposer une autre implémentation. Au lieu de passer par une gateway pour chaque appel système, la solution effectue un link classique directement avec la librairie système. L’application ne possède plus d’espace mémoire séparé du kernel. Elle fait intégralement partie du kernel. La couche réseau est également directement liée au code applicatif.
Des outils simples permettent de créer des images OSv avec vos applications. Il existe également de nombreuses images pour les serveurs les plus courus.
Notez qu’un utilitaire permet une conversion Docker vers OSv.
Pour ne pas avoir à gérer les différents drivers matériels, et proposer des images génériques, OSv s’appuie sur les API des hyperviseurs pour s’occuper de la colle avec le physique. Lancer un composant applicatif dans l’hyperviseur c’est lancer une instance de OSv linké avec l’application.
Dans ce schéma, il n’y a pas de SSH disponible ou autre processus. Les appels systèmes fork() et exec() ne sont pas disponibles. Il n’existe que des threads. C’est pour cela qu’une API REST de supervision est proposée. Elle permet la consultation de tous les indicateurs, de gérer les fichiers, etc.
Des JVM peuvent tourner dans ce modèle, afin de faire exécuter toutes les applications Java. JMX sert alors à exposer les indicateurs de production. Les gains de performances peuvent atteindre 20% à 400% suivant les cas.
La dernière étape : supprimer OS et l’hyperviseur
L’étape ultime est de se passer de l’hyperviseur et d’installer une stack logicielle directement en connexion avec le physique. Ce sont les UniKernel.
Le projet RumpKernel propose de construire un OS sur mesure. Des paramètres lors de la construction de l’OS permettent d’ajouter au coeur de l’OS : une pile IP, un gestionnaire de fichier, plus ou moins d’utilitaires Linux, etc. L’idée est de partir du minimum et de construire un OS sur mesure, en relation direct avec l’application. Ainsi, il n’y a que le nécessaire et rien d’autre.
Il faut alors produire une image dédiée à chaque cible matérielle ou pour une cible virtuelle.
Pour conclure
Chaque étape réduit la souplesse de l’OS, au bénéfice des performances. Il est en effet parfois possible de brancher un remote debugger mais impossible d’ajouter des sondes d’analyses, de connecter une console, etc. Il est très difficile de faire une analyse post-mortem avec ces architectures.
- Les gains de performances sont indéniables dans les applications à fort I/O, rien que par l’économie des copies de buffers. Néanmoins, il est difficile d’estimer, a priori, les gains réels. En effet, cela dépend grandement des spécificités des applications. Certaines auront des gains faibles d’une dizaine de pourcent, d’autres de plusieurs ordres de grandeur.
- L’ajustement du code de l’OS permet d’améliorer notablement la sécurité, en réduisant la surface d’attaque. Pourquoi garder des drivers USB pleins de vulnérabilités dans un OS tournant sur le cloud ? Pourquoi garder un shell, un agent SSH ou autre cron et pool d’impression ? L’isolation est gérée par l’hyperviseur.
- L’empreinte mémoire est également réduite. Ainsi, l’exploitation des capacités de chaque serveur est optimisée.
Les OS des VM sont maintenant souvent immuables. Il faut provisionner des instances de VM à la demande, sans les modifier. Il n’est plus question de maintenir un serveur mais de le remplacer. En cas de problème on supprime la VM et on en crée une nouvelle vierge et immuable. L’essentiel est de pouvoir construire une instance à partir de rien et de l’ajouter dynamiquement au cluster. Les approches de réplications des bases de données NoSQL se chargent d’initialiser les données dans la nouvelle instance si nécessaire.
La souplesse apportée par un OS est indispensable en développement, mais n’est plus nécessaire en production. Il est possible de s’en passer à condition d’avoir des remontées d’indicateurs (JMX par exemple pour une JVM ou d’autres consoles WEB comme le propose OSv à fin de remplacer iostat ou d’autres outils). Les solutions d’UniKernel sont attendues sur ces points. Il est indispensable d’avoir une vue fine de la production. Mais plus besoin des nombreux outils conçus pour un OS.
La technologie Jitsu (Just-in-Time Summoning of Unikernels) propose d’instancier une VM en 20ms. Il est possible de monter une instance le temps de chaque requête HTTP !
Les développeurs doivent intégrer la création des images lors des builds, afin de tester les applications dans un environnement ISO production. Vingt millisecondes de plus pour lancer un serveur est parfaitement acceptable dans la chaîne de développement.
Les architectures à base de micro-services peuvent bénéficier de cette souplesse en provisionnant les VM suivant la charge réelle.
La simplification de la production des images OS+Application est la clé de la généralisation de ces modèles. Les migrations des scripts contribueront également à leurs diffusions. Par exemple, convertir un script Docker vers OSv, RumpKernel ou MirageOS permettra de vulgariser ces modèles.
Les approches de contenérisation sont complémentaires aux approches UniKernels. Un scénario classique consiste à déployer les bases de données SQL avec LXC ou Docker. Pour les Workers ou les serveurs d’applications, les UniKernels permettent une élasticité quasi immédiate. Certains serveurs resteront probablement dans l’ancien modèle, pour faciliter quelques tâches de maintenance.
Pourquoi utiliser ces approches ? Pour améliorer les performances et la sécurité tout en réduisant l’OPEX (dépenses d'exploitation) sur plusieurs axes : Nombre de serveurs (meilleure exploitation des ressources disponibles), énergie (green IT), réduction de la maintenance de la production (Serveur immuable).
Nous pensons qu’avec la multiplication des serveurs répondant à l’explosion du nombre de requêtes, il est pertinent de s'intéresser à ces approches. Indéniablement, les UniKernel vont jouer un rôle de plus en plus important dans les infrastructures réseaux de demain. Il s’agit de la prochaine étape de l’isolation des applications.
Philippe PRADOS et l'équipe "Réactive"