Les méthodes ensemblistes pour algorithmes de machine learning
Lorsqu'il faut prendre une décision importante, il vaut souvent mieux recueillir plusieurs avis que de se fier à un seul. Utiliser un modèle de machine learning pour prédire un comportement ou un prix, c'est un premier pas. Mais agréger des milliers de modèles ayant des avis divergents mais pouvant être chacun spécialisés sur des parties de la data donne le plus souvent de meilleurs résultats. Nous parlons alors de méthodes ensemblistes, dont les plus connues sont le bagging et le boosting. Afin d'expliquer ce type de méthode, considérons un problème simple, comme celui posé par le challenge Kaggle du Titanic "Who has survived ?"
1. Challenge du Titanic
Lors du naufrage du Titanic en 1912, 1502 personnes sont décédées sur un total de 2224 personnes. Pouvons-nous prédire pour chaque voyageur s'il a survécu, cela à partir de ses caractéristiques de voyage ? Pour répondre à cette question, nous procédons en deux phases :
- Une phase d'apprentissage - Le modèle est construit
- Une phase de validation - Le modèle est évalué
Nous disposons pour cela de deux datasets dits "train set" et "test set". Le train set se constitue de 891 personnes, de leurs caractéristiques ainsi que du booléen indiquant s'ils ont survécu. Il est utilisé par l'algorithme pour construire le modèle de prédiction.
Le test set se constitue de 418 personnes avec leurs caractéristiques dont il va falloir prédire le booléen indiquant si la personne a survécu. Sa vocation est de vérifier que le modèle produit est suffisamment juste. On obtient ainsi un vecteur de 418 booléens que nous pouvons soumettre sur la plateforme Kaggle (qui dispose des réponses pour ce test set), ce qui donne lieu à un score.
On distingue deux types de caractéristiques pour décrire un visiteur :
- Les caractéristiques nominales qui forment des catégories (nom de famille, classe du ticket, port d'embarquement etc...)
- Les caractéristiques numériques (prix du ticket, âge, nombre d'enfants etc...)
L'objectif premier est donc de produire des modèles qui prédisent la survie. La seconde étape sera de les combiner pour gagner en justesse.
2. Le classifieur faible
De nombreux types d'algorithmes peuvent être utilisés pour mettre en relation les caractéristiques des passagers avec le booléen indiquant s'il a survécu.
Chaque algorithme peut produire plusieurs modèles ayant chacun une capacité à classifier les passagers entre ceux qui survivent et ceux qui ne survivent pas. Chacun de ces modèles sera appelé ici un classifieur faible. Plus généralement, on appellera un classifieur faible tout modèle permettant de classifier un petit peu mieux que s'il était complètement aléatoire. Il porte d'une certaine façon un minimum d'information.
Voici quelques concepts de statistique importants pour comprendre pourquoi un algorithme générant un classifieur ne doit pas s'adapter totalement aux données du set d'apprentissage :
- BIAIS : Un algorithme est biaisé si lorsqu'on moyenne les prédictions de survie de ses modèles générés un grand nombre de fois, la valeur moyenne prédite sera asymptotiquement différente de la valeur moyenne réelle qui est par exemple ici, ma moyenne réelle de survie des passagers du Titanic (égale à 722/2224). Cet algorithme génère alors des classifieurs trop simples qui ne prédisent pas parfaitement le train set. Ceci n'est pas foncièrement aberrant car le classifieur se doit d'une part de généraliser pour anticiper le test set qu'il ne connait pas, et d'autre part de ne pas être induit en erreur par le bruit dans les données (un exemple de "bruit" peut être quelqu'un a eu une crise cardiaque pendant le naufrage et dont nous ne disposons pas des données de santé pour espérer prédire cet événement ; c'est donc une composante aléatoire imprédictible).
- VARIANCE : L'algorithme peut également avoir une très forte variance, à savoir une très grande sensibilité aux jeux de données qui modifient radicalement sa prédiction. Typiquement l'algorithme qui considère que pour classifier un point il suffit de prendre la classe du point le plus proche (plus proche voisin ou 1-NN) a une forte variance. L'algorithme produit alors des classifieurs trop complexes. Par exemple, pour prédire la survie d'un passager, il est possible de regarder la survie du plus "proche" connu dans le train set (par exemple quelqu'un portant le même nom de famille, quelqu'un ayant le même type de ticket ou le même port d'embarquement, plus généralement quelqu'un proche au sens d'une distance sur les features) Ce type de modèle fortement non linéaire génère donc des découpages d'espace très fragmentés et "arbitraires" qui prédisent parfaitement le train set (y compris sa composante aléatoire/bruitée par définition imprédictible), sans que cela soit nécessairement une bonne chose pour les prédictions futures.
Ces deux caractéristiques sont à l'origine du fameux trade-off biais/variance dont une bonne illustration est disponible dans [Bias variance]. Il est difficile d'obtenir un algorithme peu biaisé tout en gardant une faible variance.
Un algorithme générant des modèles moins sensibles aux données d'apprentissage sera plus général et donc à priori mieux adapté aux futures prédictions. Mais ses modèles seront peut être trop simples et car il aura été peu performant sur le train set.
A l'inverse, si l'algorithme généré est très sensible aux données d'apprentissage, l'erreur sur le train set sera faible, mais utilisé sur un nouveau jeu de données à prédire, l'erreur sera bien trop grande. Il aura été trop spécifique aux sets d'apprentissage, c'est le sur-apprentissage.
3. L'ensemble de classifieurs faibles
Considérons plusieurs classifieurs issus d'un algorithme. Est-il possible de combiner l'information que chacun porte afin d'obtenir un super-classifieur plus performant ? Oui, et de ce fait, nous réduisons la variance de l'algorithme car moyenner les classifieurs diminue la sensibilité aux données et sans augmenter son biais puisque le super-classifieur produit devrait disposer de l'information de chaque classifieur seul. Quelles sont les techniques les plus utilisées ?
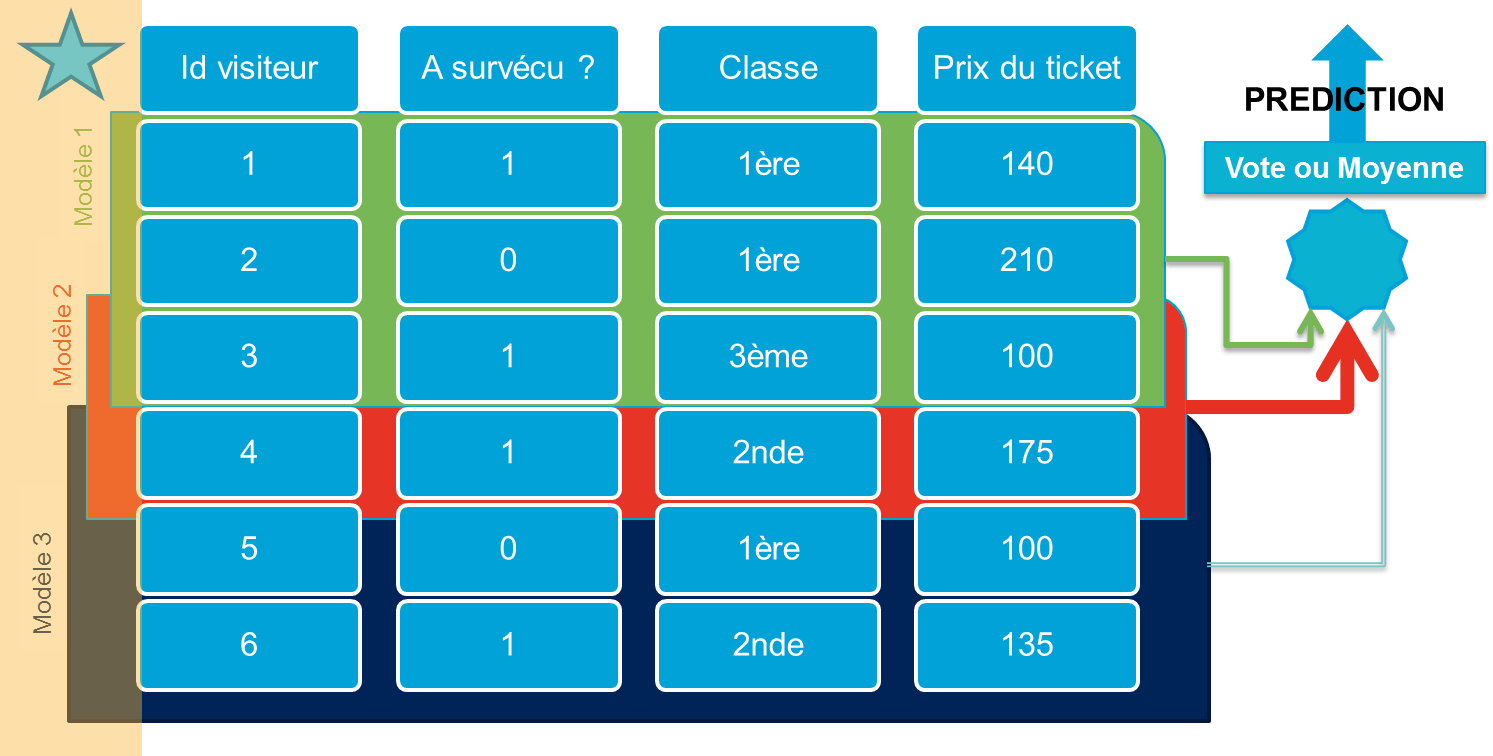
3.1 Bagging ou Bootstrap aggregating
Il consiste à sous-échantilloner (ou ré-échantilloner au hasard avec doublons) le training set et de faire générer à l'algorithme voulu un modèle pour chaque sous-échantillon. On obtient ainsi un ensemble de modèles dont il convient de moyenner (lorsqu'il s'agit d'une régression) ou de faire voter (pour une classification) les différentes prédictions.
L'utilisation du bagging est adaptée aux algorithmes à fortes variance qui sont ainsi stabilisés (réseaux neuronaux, arbres de décision pour la classification ou la régression...), mais il peut également dégrader les qualités pour des algos plus stables (k plus proches voisins avec k grand, régression linéaire). On générera par exemple des dizaines de classifieurs au total qu'il va falloir "bagger". L'avantage principal de ces procédures est que la génération de ces modèles peut être naturellement parallélisée.
Avec Scikit-learn, il est simple de produire de tels modèles baggés, par exemple : Un bagging d'arbres de décision sera généré sur scikit-learn ou weka à partir des classes suivantes: sklearn.ensemble.RandomForestClassifier(n_estimators=10) weka.classifiers.meta.Bagging
3.2 Boosting
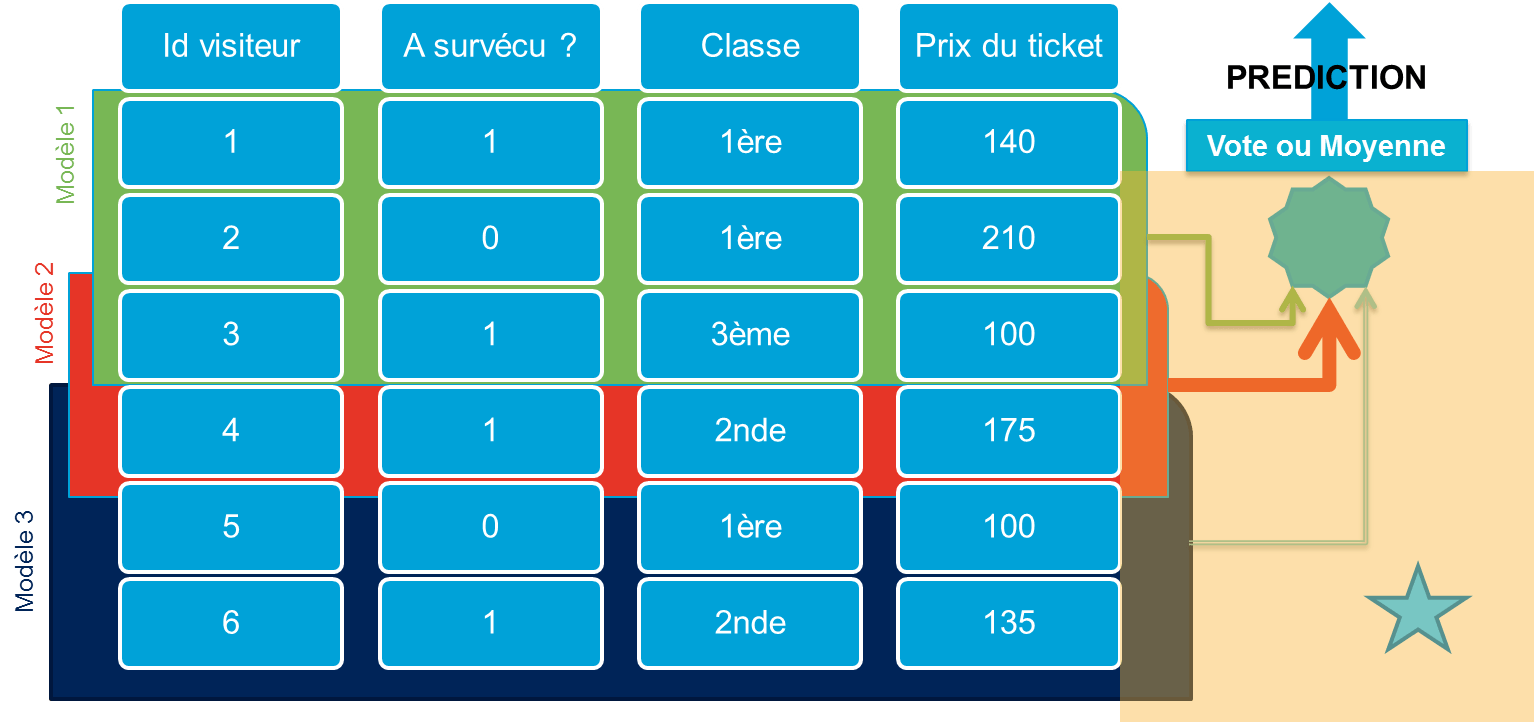
Le principe du boosting est quelque peu différent du bagging. Les différents classifieurs sont pondérés de manière à ce qu'à chaque prédiction, les classifieurs ayant prédit correctement auront un poids plus fort que ceux dont la prédiction est incorrecte.
Adaboost est un algorithme de boosting qui s'appuie sur ce principe, avec un paramètre de mise à jour adaptatif permettant de donner plus d'importance aux valeurs difficiles à prédire, donc en boostant les classifieurs qui réussissent quand d'autres ont échoué. Des variantes permettent de l'étendre à la classification multiclasses. Adaboost s'appuie sur des classifieurs existants et cherche à leur affecter les bons poids vis à vis de leurs performances.
Scikit-learn par exemple propose par défaut Adaboost avec : sklearn.ensemble.AdaBoostClassifier(n_estimators=100) weka.classifiers.AdaBoostM1
3.3 Gradient Boosting
Cette technique de boosting est majoritairement employée avec des arbres de décision (elle est alors dite Gradient Tree Boosting) L'idée principale est là encore d'agréger plusieurs classifieurs ensembles mais en les créant itérativement. Ces "mini-classifieurs" sont généralement des fonctions simples et paramétrées, le plus souvent des arbres de décision dont chaque paramètre est le critère de split des branches. Le super-classifieur final est une pondération (par un vecteur w) de ces mini-classifieurs.
Une approche pour construire ce super-classifieur est de :
- Prendre une pondération quelconque (poids wi) de mini-classifieurs (paramètres ai) et former son super-classifieur
- Calculer l'erreur induite par ce super-classifieur, et chercher le mini-classifieur qui s'approche le plus de cette erreur (ce qui revient à le chercher dans l'espace des paramètres)
- Retrancher le mini-classifieur au super-classifieur tout en optimisant son poids par rapport à une fonction de perte
- Répéter le procédé itérativement
Le classifieur du gradient boosting est donc au final paramétré par les poids de pondération des différents mini-classifieurs, ainsi que par les paramètres des fonctions utilisées. Il s'agit donc d'explorer un espace de fonctions simples par une descente de gradient sur l'erreur.
Scikit-learn et weka disposent d'implémentations du Gradient Boosting disponible via : sklearn.ensemble.GradientBoostingClassifier() weka.classifiers.meta.AdditiveRegression()
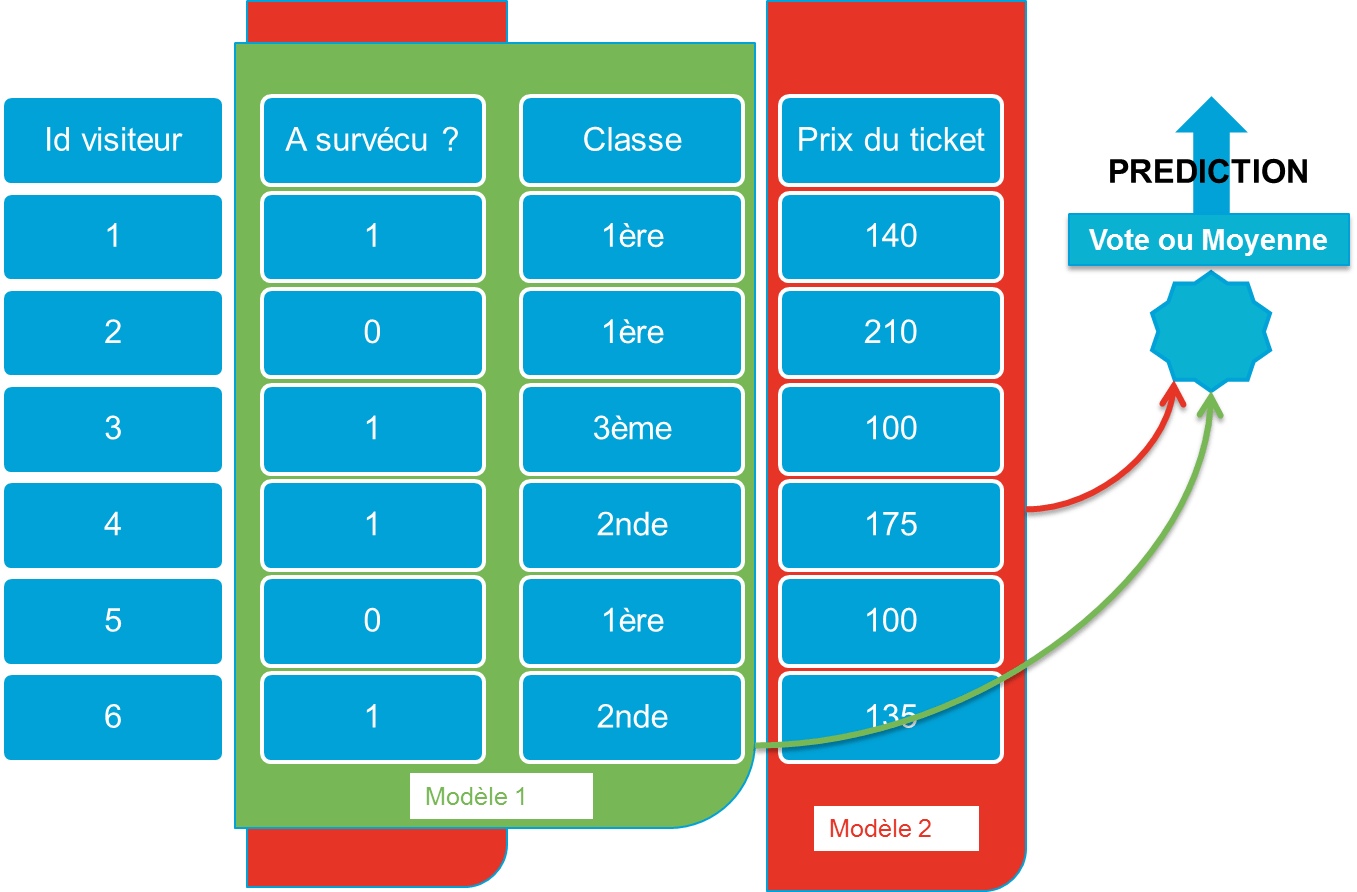
3.4 Feature sampling
Plutôt que de faire du sampling sur la data avec les techniques de bagging, il est également possible d'adopter une démarche orthogonale en échantillonnant les features. Cette technique a notamment été utilisée pour reconnaître des patterns de volcan sur Mars, et est expliquée et implémentée dans l'article [Feature sampling].
3.5 Classification multi-classes (ECOC algorithm)
Lorsqu'on est face à un problème de classification avec un grand nombre de classes, nous pouvons adopter les techniques du One-vs-All ou One-vs-One (une classe contre les autres ou une classe contre une classe [OAO,OAA]). Une autre technique peut être de faire des regroupements moins triviaux de ces classes. Par exemple s'il faut prédire le type d'une plante parmi 10.000 en fonction de ses caractéristiques visuelles, on peut découper de manière aléatoire les 10.000 types en deux classes principales A et B, re-labelliser la data en input et régénérer un modèle de classification binaire.
Ce modèle est donc spécialisé dans la distinction entre les classes A et B. En répétant ce procédé un grand nombre de fois, on obtient plusieurs classifieurs qu'on agrège avec un vote classique. Ce type de technique permet d'améliorer les performances des arbres de décision et de réseaux neuronaux pour des problèmes de classification où le nombre de classe est important.
Pour mieux comprendre la théorie sous-jacente, il faut voir cette re-labellisation comme le fait d'assigner à chaque classe un vecteur de 0 et de 1, où les 0 correspondent au fait d'être dans le groupe A, et 1 celles pour lesquelles il est dans le groupe B. Par exemple si nous avons 3 classes "Cactus", "Sapin" et "Géranium". Nous allons faire par exemple 3 découpages A et B avec :
- Premier découpage : Dans A, il y aura cactus et sapin et dans B géranium
- Second découpage : Dans A, il y aura cactus et géranium et dans B s_apin_
- Troisième découpage : Dans A, il y aura géranium et sapin et dans B cactus
Donc les vecteurs correspondant sont
- Cactus : 110 (présence dans les premier et second découpages)
- Sapin : 101 (présence dans les premier et troisième découpages)
- Géranium : 011 (présence dans les second et troisième découpages)
Si l'output de notre super-classifieur est par exemple un vecteur 001 (correspondant à trois prédictions "0", "0" et "1" pour les trois colonnes voulues), ceci signifiera que les premier et second classifieurs ont prédit B, et le troisième a prédit A.
On cherche alors parmi les trois vecteurs de nos classes celui qui se rapproche le plus de l'output, au sens de la distance de Hamming. Cette transformation des classes d'output permet donc de se ramener à des problèmes classiques de codes correcteurs d'erreur en théorie de l'information. L'analogie qui en découle est que l'erreur (traditionnellement un flip de bit 0-1 dans nos canaux de transmission) est ici le mauvais choix d'un de nos classifieurs.
3.6 Stacking
Le stacking (ou dit parfois blending) est un procédé qui consiste à appliquer un algorithme de machine learning à des classifieur générés par un autre algorithme de machine learning.
D'une certaine façon, il s'agit de prédire quels sont les meilleurs classifieurs et de les pondérer. Cette démarche a l'avantage de pouvoir agréger des modèles très différents et d'améliorer sensiblement la qualité de la prédiction finale, le challenge NetFlix à 1 million $ en est la meilleure preuve. Pour pouvoir évaluer les différents modèles à stacker, on utilise des poids constants permettant de pondérer les différents modèles. C'est du stacking linéaire standard.
La principale limitation est qu'on a perdu la dépendance des modèles à leur data et plus particulièrement leur spécialisation. On va donc utiliser des poids variables qui dépendent des données ; soit des méta-features. Le stacking est cette fois-ci dépendant du poids des features.
En effet, un modèle peut être performant pour une catégorie de voyageurs, et il convient de récupérer cette information de spécialisation. Etant donné un nouveau point x dont il faut prédire l'output y, pour les meta-feature fi et les modèles gj précédemment généré.
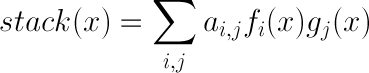
Exemple : Nous avons produit deux modèles g1 et g2 prédisant avec plus ou moins de réussite la survie des passagers du Titanic. Il se trouve que lorsque le passager est une femme, le modèle g1 est plus précis. Le modèle g2 est lui spécialisé lorsque l'information du port d'embarquement du passager est disponible. Par conséquent, nous utiliserons deux méta-feature décrivant la spécialisation de chaque modèle.
- f1 vaudra par exemple 1 lorsque le vecteur x décriant le passager indique que c'est une femme et 0 ailleurs.
- f2 vaudra de la même façon 1 lorsque l'information du port d'embarquement est disponible et 0 sinon.
Il reste à ajuster a{1,1}, a{1,2}, a{2,1} et a{2,2} avec une régression linéaire pour optimiser la fonction stack.
Ainsi du fait de cette pondération, stack sera fortement ressemblant à g1 pour certains x et à g2 pour d'autres. Le choix des meta-features reste ardu et nécessite beaucoup de tests et d'intuition.
La liste des 24 meta-features non triviales utilisées pour le challenge NetFlix est publiée dans [Stacking]. Ce type de stacking est considéré aujourd'hui comme étant à l'état de l'art. Le stacking est disponible dans weka avec la classe : weka.classifiers.meta.Stacking
Conclusion
L'utilisation de méthodes ensemblistes est nécessaire dès lors qu'on veut passer un cap dans l'obtention de meilleurs résultats de prédiction. L'utilisation d'Adaboost ou du gradient boosting est courante et offre des résultats honorables au regard de la simplicité de ces deux algorithmes. Résoudre un problème comme celui du Titanic passera nécessairement par cette étape.
Ceux-ci sont disponibles dans la librairie scikit-learn. Pour les problèmes complexes, il est fort à parier qu'il n'existe pas de méthode magique, sinon la compréhension profonde de chacune des méthodes ensemblistes combinée à toujours plus de feature engineering.
Références :
[Titanic] http://www.kaggle.com/c/titanic-gettingStarted [Bag1] Bagging Predictors -- Leo Breiman [Bag2] Heuristics of instability and stabilization in model selection -- Leo Breiman [Adaboost] A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting -- Yoav Freund and Robert E. Schapire [Boosting] http://www.deetc.isel.ipl.pt/sistemastele/docentes/AF/Textos/RT/SurveyBoosting.pdf [Feature Sampling] Human expert-level performance on a scientific Image Analysis task by a system using combined artifical neural networks -- Cherkauer [Bias variance] http://scott.fortmann-roe.com/docs/BiasVariance.html [Relabelling] Solving multiclass learning problems via error-correcting output codes -- Dietterich, Bakiri [Stacking] Feature-Weighted Linear Stacking -- Sill, Takacs, Mackey, Lin [OAO,OAA] "One Against One" or "One Against All" : Which One is Better for Handwriting Recognition with SVMs?