Les fronts du futur avec les Agentic-Driven Interfaces
En 2026, tout le monde sait générer du texte, des images, des vidéos ou même du code avec l’IA générative. De nouveaux cas d’usages ont été introduits dans nos applications, et l’idée n'est pas de remettre en cause la valeur d’un bon vieux chatbot. Mais nos produits numériques ne sont pas simplement composés de texte ou d’images. Ils sont composés de formulaires, de cartes et de boutons. Il est temps de pleinement intégrer nos LLMs avec les interfaces de nos utilisateurs. Avec les Agentic Driven Interfaces, nous allons demander à notre LLM de retourner directement des composants graphiques de l’interface plutôt que du texte ou des images.
L’idée est d’utiliser la flexibilité et la personnalisation offerte par l’intelligence et de la restituer d’une manière plus structurée qui correspond à son utilisation habituelle.
À quoi ça ressemble une interface Agentic Driven ?
Pour ceux qui ont lu mon précédent article sur l’IA en local vous êtes déjà familier avec Coach Gnocchi, notre compagnon préféré qui essaie de nous faire voir la vie en rose. Pour tester les Agentic Drive Interfaces, nous allons rajouter une nouvelle fonctionnalité : proposer des activités permettant de répondre à une humeur donnée.
- L’utilisateur nous décrit la situation qu’il vit “Cette nuit j’ai fait un cauchemard ou j’ai perdu mon chien. Je n’arrive pas à me le sortir de la tête”
- L’IA va d’abord analyser l’humeur de l’utilisateur et lui présenter l’analyse dans une première carte.
- Puis elle va nous proposer 3 activités pour améliorer notre humeur parmis un catalogue
- Et si il est possible de “monétiser” cette activité, nous aurons un bouton permettant de rediriger vers cette fonctionnalité payante (on veut faire payer nos utilisateurs, on n’est pas des bénévoles)
- Les autres messages, simplement textuels, seront affichés dans des bulles de message classiques.
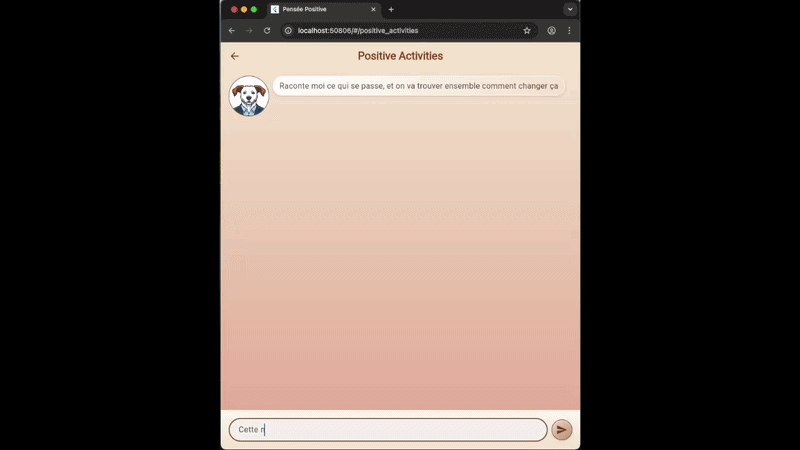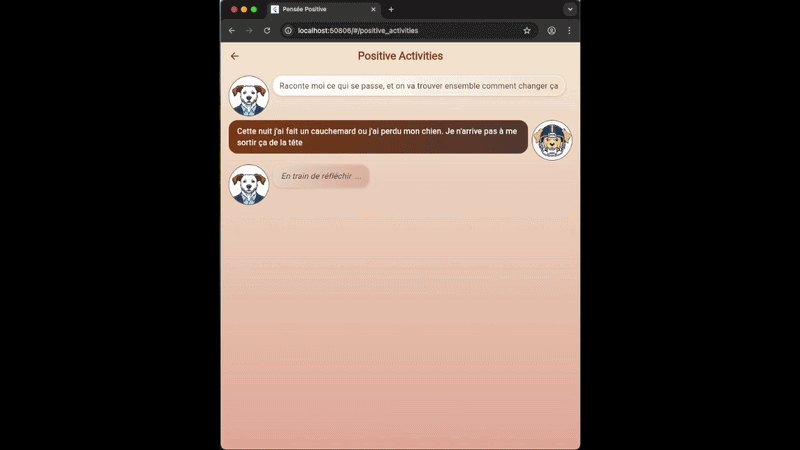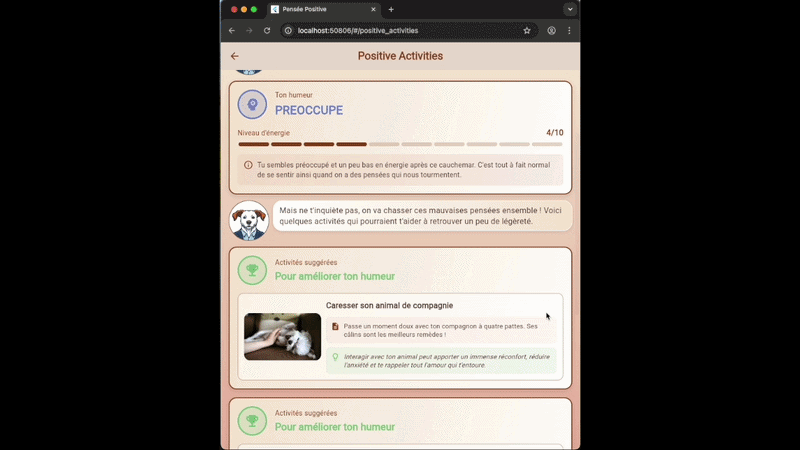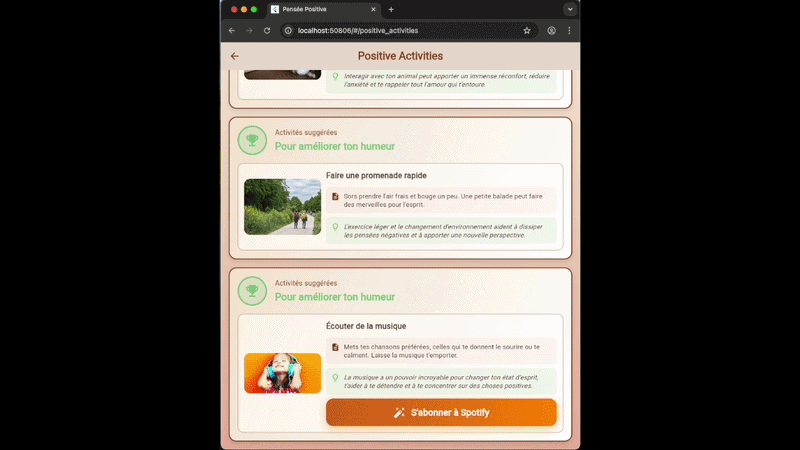
On peut donc voir ici du contenu généré qui se retrouve dans des composants classiques, qui peuvent par ailleurs utiliser du contenu “en dur”. Prenons l’exemple de la carte d’activité :
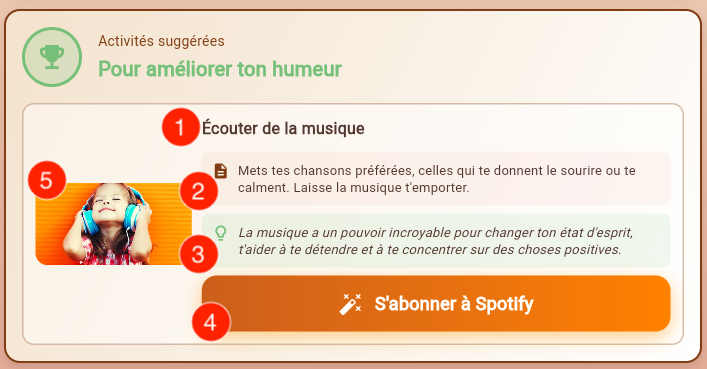
La description (2) et l’explication (3) sont des contenus générés, qui seront uniques et personnalisés à chaque demande de l’utilisateur pour coller au mieux à la situation décrite. En revanche, le titre (1) est généré, mais ne peut être choisi par l’IA que parmi une liste prédéfinie d’une trentaine d’activités. Et l’image (4) et le bouton d’action (5) sont “statiques” et sont affectés par notre code en fonction du titre de l’activité.
Et le plus important pour nous : l’utilisateur n’interagit pas simplement avec du texte ou de l’image. La suite de son parcours ne sera pas de répondre dans une zone de texte. On lui offre, en échange d’un simple clic sur un bouton, la possibilité de nous donner de l’argent !
Vous remarquerez également que les cartes sont tout à fait dans la charte graphique du reste du projet ! C’est normal, puisque nous verrons plus bas que ces composants graphiques sont implémentés à la main et non pas générés par l’IA au moment de la requête.
Alors bien sûr, ça ne ressemble pas non plus à une révolution. D'ailleurs, si vous avez lu notre dernier article sur les LLMs locaux, nous y avions déjà implémenté une fonctionnalité similaire pour proposer des activités en fonction de la météo du jour. Pas besoin de parler d’Agentic Driven Interface pour voir des fonctionnalités similaires. Malgré tout, si vous avez le courage de continuer cet article, regardons ensemble le fonctionnement interne.
Comment ça tourne sous la capot ?
Pour réaliser cette fonctionnalité, nous avons utilisé Flutter GenUI, qui est le nouvel arrivant dans la documentation officielle de Flutter ! Ce package est présenté comme une couche d’orchestration entre nos Widgets Flutter (nos composants graphiques) et des agents IA. Bien que le package soit inclu dans la documentation officielle de Flutter, ce qui montre qu’il est à priori là pour durer et qu’il sera mis en avant par les développeurs du framework, précisons tout de même qu’il est encore en phase d’alpha et donc que son utilisation est limitée, et qu’il faut s’attendre à des impacts forts dans les mois à venir.
Regardons un peu plus précisément comment tout cela fonctionne. Pour information, le code est disponible sur github.
1. Créer un schéma de données
Tout d’abord, nous devons définir le format des données que nous allons vouloir recevoir de notre modèle. Gardons pour cela en tête l’exemple de la carte d’activité au-dessus. Nous avons besoin :
- D’un titre faisant partie d’une liste prédéfinie
- D’une description de l’activité
- D’une explication de la corrélation entre l’activité et l’humeur de l’utilisateur
Pour indiquer ces informations, nous devrons créer un template de format JSON de retour à l’aide de json_schema_builder. Dans le code, notre schéma ressemblera donc à ceci :
final _activityCardSchema = S.object(
properties: {
'type': S.string(
description: 'Le type de l\'activité',
enumValues: possibleActivities,
),
'description': S.string(description: 'La description de l\'activité'),
'explication_humeur': S.string(
description:
'Pourquoi je pense que cette activité va améliorer ton humeur',
),
},
required: ['type', 'description', 'explication_humeur'],
);
2. Utiliser le schéma pour construire un widget
Nous allons maintenant pouvoir utiliser notre schéma pour construire un widget. Pour cela, le framework va nous demander de créer un CatalogItem dans lequel nous indiquerons un nom pour notre composant, un schéma (celui vu plus haut) et un builder qui prend en paramètre de la donnée au format du schéma et retourne un Widget :
final _activityCardWidget = CatalogItem(
name: 'ActivityCard',
dataSchema: _activityCardSchema,
widgetBuilder: (CatalogItemContext context) {
final data = context.data as Map<String, dynamic>;
final List<dynamic> activites = data['activites'] ?? [];
return Column(
children: [
_ActivityHeaderWidget(),
const SizedBox(height: 16.0),
...activites.map((activity) {
return _SingleActivityWidget(
type: activity['type'],
description: activity['description']',
explicationHumeur: activity['explication_humeur'],
);
}),
],
);
},
);
Ce CatalogItem doit ensuite être “rangé” dans un catalogue qui sera plus tard mis à disposition du LLM. En l’occurrence, le nôtre comporte trois composants : la carte d'activité, la carte d’humeur, et le message simple.
final catalog = CoreCatalogItems.asCatalog().copyWith([
_moodCardWidget,
_assistantMessageWidget,
_activityCardWidget,
]);
3. Créer une conversation utilisant nos CatalogItems
Passons maintenant à la création de la conversation avec le LLM. Nous aurons d’abord besoin de créer un ContentGenerator. Je ne m’attarderais pas trop dessus pour le moment d’autant que c’est probablement la partie la moins mature du package. Pour le moment nous n’avons globalement le choix qu’entre utiliser les APIs Gemini (qui limitent à 20 requêtes par jour en version gratuite) ou celles de Firebase Logic (qui sont encore plus limitées, je vous en parle plus bas). Notre ContentGenerator sera également le composant dans lequel nous allons déclarer notre contexte de conversation et notre catalogue de composant.
final contentGenerator = GoogleGenerativeAiContentGenerator(
catalog: catalog,
systemInstruction: """
Tu es un chien coach de vie. Ton but est d'analyser mon humeur pour ensuite trouver des activités pour m'aider à aller mieux.
Je veux que tu analyse mon humeur en générant une MoodCard.
Pour les autres messages, utilise un AssistantMessageCard et je voudrais que ces messages fassent moins de 100 mots.
J'aimerais ensuite que tu me fasses trois propositions d'activités en utilisant ActivityCard.
""",
modelName: 'models/gemini-2.5-flash',
apiKey: GEMINI_API_KEY,
);
Remarquons que dans le prompt initial, nous devons indiquer au modèle quel composant doit être utilisé pour quel usage, et si possible dans quel ordre il doit exécuter son raisonnement pour garantir un affichage cohérent.
Nous aurons également besoin de créer un MessageProcessor. Ici, pas trop le choix pour le moment, nous devrons utiliser le processeur A2UI qui est le framework d’échange poussé par Google (dont nous parleront également plus bas).
final messageProcessor = A2uiMessageProcessor(catalogs: [catalog]);
Et enfin, nous pouvons créer la conversation proprement dite :
conversation = GenUiConversation(
contentGenerator: contentGenerator,
a2uiMessageProcessor: messageProcessor,
onSurfaceAdded: _onSurfaceAdded,
onSurfaceDeleted: _onSurfaceDeleted,
);
4. Préparer une surface d’affichage et envoyer notre requête
Afin d’afficher nos futurs composants renvoyés par le LLM, nous allons devoir indiquer dans notre arbre de Widget à quel endroit il doit être affiché à l’aide de son id de surface qui nous sera retourné dans la callback du dessus _onSurfaceAdded :
Column(
children: [
MessageDeBienvenue(),
MessageUtilisateur(),
GenUiSurface(host: conversation.host, surfaceId: surfaceId),
],
);
Tout est en place, il ne nous reste plus qu’à transmettre la requête à la conversation lorsque notre utilisateur envoie son message :
conversation.sendRequest(UserMessage.text(messageUtilisateur));
Et voilà, derrière, le LLM va processer le message à l’aide du contexte initial qui lui a été donné. Contexte qui contient notamment notre catalogue de composants. Une fois la réponse prête, il nous répondra en retour une liste de composants au bon format de données, qui seront directement transformés en Widgets et affichés dans la surface indiquée. Tadaa !
A2UI, le protocole derrière la Flutter GenUI
Nous avons brièvement mentionné plus haut A2UI comme étant le processeur de message utilisé par la librairie Flutter GenUI. Alors A2UI c’est quoi ? Et bien c’est un protocole d'échange entre des applications front-end et des LLMs dans le but de produire des Agentic Driven Interfaces.
Google l’a introduit fin 2025 en tant que projet public et open source, ouvert à la contribution. Il contient notamment un format optimisé pour représenter des interfaces utilisateur mises à jour et générées par des agents, ainsi qu'un ensemble de moteurs de rendu, permettant aux agents de générer ou de remplir des interfaces utilisateur riches.
Son principe de fonctionnement est de partir d’une “spécification graphique” donnée par l’application sous forme d’un catalogue de composants utilisables et de borner le modèle à répondre en utilisant ce catalogue et uniquement ce catalogue.
Cette approche garantit au développeur de l’interface un contrôle total sur la sécurité et le style de ses composants et aide l’agent IA à produire un rendu complètement intégré à son application.
Pour être honnête, bien que j’ai essayé de plonger dans la documentation du protocole je n’en ai pas forcément retiré grand chose si ce n’est qu’en tant que développeur front, ce n’est pas là que mon expertise sera la plus utile. Libre à vous évidemment de ne pas abandonner aussi vite et d’aller creuser plus loin si l’envie vous y prend !
Qu’est-ce qu’on en pense alors de l’Agentic Driven Interface ?
En implémentant cet écran, je n’ai pas vraiment eu l’impression de participer à une révolution. Finalement, c’est surtout une tentative de structuration de concepts qui existent déjà et sont relativement répandus (au moins sous forme de POCs). C’est toujours sympa de jeter un œil aux nouvelles technologies qui sortent autour de la GenAI, la prise en main de l’outil est assez simple et le résultat est à la hauteur de ce que j’attendais. Mais rien d’incroyable non plus.
À noter également que nous avons rencontré deux limites fortes à l’implémentation de la fonctionnalité à l’aide de Flutter GenUI :
- La structure du JSON de chacun des composants est envoyée sous forme de contexte au modèle pour qu’il puisse l’utiliser. Il devient donc vite cher en termes de Tokens de multiplier les composants possibles pour la réponse.
- Il n’est pour le moment possible que de se connecter avec Gemini ou Firebase Logic de manière simplifiée ce qui limite clairement la possibilité de le déployer en production dans un horizon proche.
Ce qui est réellement intéressant pour moi c’est la volonté, au moins de la part de Google, de pousser un standard autour de l’Agentic Driven Interface. Par le protocole A2UI que l’on a déjà vu au-dessus. Mais aussi sur Flutter avec Flutter GenUI qui est entrée dans la documentation officielle et fait partie des points principaux de la roadmap 2026 du framework.
Difficile donc de dire aujourd’hui dans quel mesure ce concept, voir ce protocole, va s’imposer et dans quelle mesure il va changer notre manière de développer des fronts. En tous cas, c’est un bon exemple pour nous rappeler que rien n’est jamais figé dans nos pratiques de développement.