Les capacités d'alerting de Kapacitor
<span style="display: inline-block; width: 0px; overflow: hidden; line-height: 0;" data-mce-type="bookmark" class="mce_SELRES_start"></span><span style="display: inline-block; width: 0px; overflow: hidden; line-height: 0;" data-mce-type="bookmark" class="mce_SELRES_start"></span><span style="display: inline-block; width: 0px; overflow: hidden; line-height: 0;" data-mce-type="bookmark" class="mce_SELRES_start"></span><span style="display: inline-block; width: 0px; overflow: hidden; line-height: 0;" data-mce-type="bookmark" class="mce_SELRES_start"></span><span style="display: inline-block; width: 0px; overflow: hidden; line-height: 0;" data-mce-type="bookmark" class="mce_SELRES_start"></span><!-- pre { font-size: 80%; } code { font-size: 80%; } pre.commandline { padding:3px 8px; background-color: #002B36; color: #C0CCCE; overflow: auto;width: 98%; } span.hl { color: #c20c0c; font-weight: bold;} -->
Kapacitor est un outil de traitement de flux de données temps réel. Il permet d'analyser les données récupérées depuis plusieurs sources tel qu'un agent de collecte (Telegraf), une base de données TimeSeries (InfluxDB), via un service discovery (Consul)... Suite au traitement de ces données, il peut déclencher différentes actions telles qu'envoyer un mail ou exécuter un script shell.
Pourquoi Kapacitor ?
Nous avions étudié Telegraf et InfluxDb dans un article précédent. Ces outils font partie de la stack TICK (Telegraf, InfluxDB, Chronograf, Kapacitor) proposée par InfluxData. Nous allons étudier aujourd'hui les capacités d'alerting proposées par Kapacitor.
Contexte
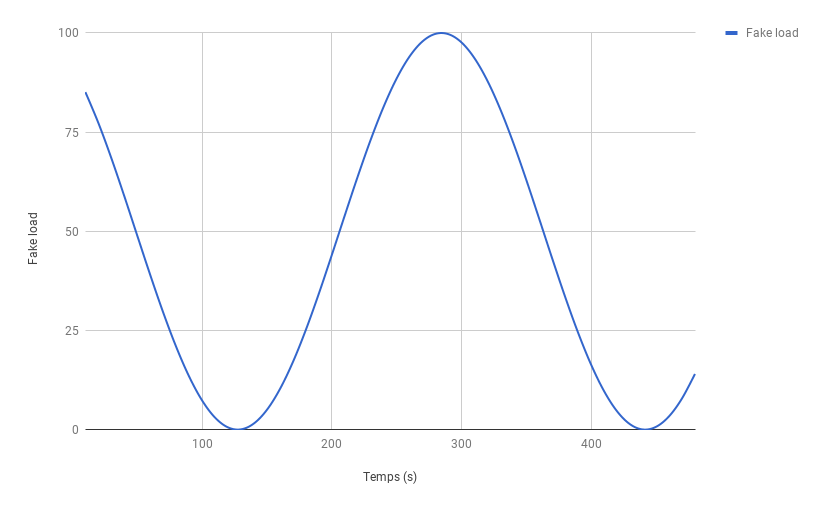
Pour les besoins de l'article, nous allons utiliser une application de test écrite en GO et qui expose des métriques au format prometheus sur l'url http://localhost/8080/metrics. La métrique fake_load exposée par l'application sur laquelle nous allons travailler est une sinusoïde dont la valeur varie entre 0 et 100 avec une période de l'ordre de 5 minutes. La collecte des mesures est effectuée toutes les 10 secondes.
Installation de Kapacitor
Télécharger Kapacitor :
$ curl https://dl.influxdata.com/kapacitor/releases/kapacitor_1.4.0_amd64.deb -o kapacitor.1.4.0.deb
Installer Kapacitor :
$ dpkg -i kapacitor.1.4.0.deb
Alerting
On va reprendre une partie des composants que l'on avait sur l'article précédent :
- Une application en go à monitorer
- Une base InfluxDb
- Un agent Telegraf qui collecte les métriques et les stocke dans une base InfluxDb
- Kapacitor qui récupère les données de la base InfluxDb pour réaliser l'alerting
Configuration de la connexion à la base InfluxDB
Il faut configurer Kapacitor pour pouvoir récupérer les données depuis InfluxDB.
Dans le fichier /etc/kapacitor/kapacitor.conf :
[[influxdb]] enabled = true default = true urls = ["http://localhost:8086"] name = "database_name" username = "database_user" password = "database_password"
Cas d’usage : alerting sur une métrique applicative
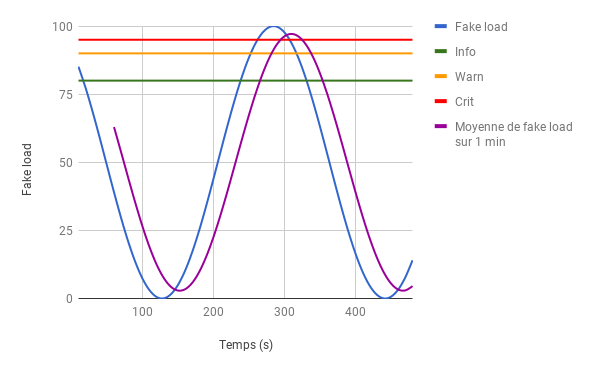
Pour notre exemple, nous allons mesurer la moyenne de la métrique fake_load (sinusoïde) sur une fenêtre glissante de 1 minute.
Nous avons défini trois niveaux d’alerte :
Si la moyenne sur la dernière minute est supérieure à :
- 80 → on lève une alerte de niveau INFO
- 90 → on lève une alerte de niveau WARN
- 95 → on lève une alerte de niveau CRIT
Pour configurer cette alerte, il faut la définir dans un fichier app.tick. Nous allons expliquer le contenu du fichier étape par étape.
Configuration de la source de données
var fake_load = stream |from() .database('database_name') .retentionPolicy('autogen') .measurement('fake_load')
On retrouve ici le nom de la base de données (‘database_name’), le nom de la retention policy par défaut (‘autogen’) et le nom de la mesure à analyser (‘fake_load’).
Déclaration de la fenêtre de travail
var fake_load_window = fake_load |window() .period(1m) .every(5s)
On retrouve ici la durée de la fenêtre (1 minute) et la fréquence d’analyse (toutes les 5 secondes).
Calcul de la moyenne
var mean_gauge = fake_load_window |mean('gauge') .as('my_mean')
On retrouve ici le calcul de la moyenne de la valeur gauge de la métrique fake_load.
Les alertes
var notification = mean_gauge |alert() .message('ALERT') .info(lambda: "my_mean" > 80) .warn(lambda: "my_mean" > 90) .crit(lambda: "my_mean" > 95) .stateChangesOnly() .log('/tmp/alert.log')
Ces lignes permettent de créer des alertes quand la moyenne passe certains paliers. L’option stateChangesOnly permet de déclencher l’alerte une seule fois quand le seuil d’un niveau est dépassé. Sinon, l’alerte serait déclenchée toutes les 5 secondes. Pour cet exemple nous écrivons l’alerte dans un fichier de log. Il est néanmoins possible de déclencher différents types d’action.
Par exemple, nous pouvons déclencher un script bash :
var action = mean_gauge |alert() .crit(lambda: "my_mean" > 80) .stateChangesOnly() .exec('/home/ansible/action.sh')
Cas d’usage sur une métrique système
Nous allons voir désormais comment placer une alerte sur la métrique système “espace disque utilisé”. Dans l’exemple ci dessous, nous levons une alerte si le disque est rempli à plus de 13 % (valeur arbitrairement faible pour déclencher l’alerte) :
La métrique qui nous intéresse est le champ used_percent de la métrique disk :

Il y a une subtilité à connaître concernant les métriques enregistrées dans Influxdb : il y a des tags et des fields.
Les fields correspondent aux valeurs des métriques (par exemple : l'espace disque utilisé) alors que les tags sont des constantes associées à l’enregistrement (par exemple : le host d’où vient la métrique).
Voici les tags de la métrique disk :
> SHOW TAG keys from disk name: disk tagKey
device fstype host mode path
Voici les fields de la métrique disk :
> SHOW FIELD keys from disk name: disk fieldKey fieldType -------- --------- free integer inodes_free integer inodes_total integer inodes_used integer total integer used integer used_percent float
Pour déclarer l’alerte système :
var disk = stream |from() .database('database_name') .retentionPolicy('autogen') .measurement('disk') |alert() .crit(lambda: "used_percent" >= 13.0) .stateChangesOnly() .id('disk \'{{ index .Tags "device" }}\'') .message('{{ .ID }} is {{ if eq .Level "OK" }}fine{{ else }}almost full{{ end }}: {{ index .Fields "used_percent" | printf "%0.3f" }} percent.') .log('/tmp/disk_alert.log')
Ce qui génère ce type de logs :
{ "id": "disk 'sda1'", "message": "disk 'sda1' is almost full: 14.186 percent.", "details": "...", "time": "2018-04-06T15:17:40Z", "duration": 0, "level": "CRITICAL", "data": { "series": [ { "name": "disk", "tags": { "device": "sda1", "fstype": "ext4", "host": "ubuntu-xenial", "mode": "rw", "path": "/" }, "columns": [ "time", "free", "inodes_free", "inodes_total", "inodes_used", "total", "used", "used_percent" ], "values": [ [ "2018-04-06T15:17:40Z", 8859475968, 1214183, 1280000, 65817, 10340831232, 1464578048, 14.186075021791131 ] ] } ] } }
Activer l’alerte
Une fois l’alerte écrite dans un fichier (/home/ansible/app.tick), il faut utiliser le client kapacitor pour activer l’alerte :
kapacitor define app -type stream -tick /home/ansible/app.tick -dbrp influx_db.autogen
app: id de la task dans kapacitor/home/ansible/app.tick: chemin du fichier contenant la définition de l’alerteinflux_db.autogen: nom de la base de données et de la politique de rétention.
$ kapacitor list tasks ID Type Status Executing Databases and Retention Policies app stream disabled false ["influx_db"."autogen"]
La tâche est bien créée mais n’est pas encore activée.
$ kapacitor enable app $ kapacitor list tasks ID Type Status Executing Databases and Retention Policies app stream enabled true ["influx_db"."autogen"]
Avantages
Comme les autres outils de InfluxData, Kapacitor est simple à installer et à configurer. Il permet de faire des calculs en mode batch et en mode streaming. Le mode batch permet de monitorer des comportements sur de plus longues durées comme une journée ou une semaine. Le langage de script tick permet de faire un alerting fin. Il propose de nombreuses opérations de calcul sur les données et un nombre important de vecteurs de notifications (email, slack, PagerDuty, OPSgenie…).
Inconvénients
La documentation n’est pas très riche. On peine à trouver des exemples et des explications. Il existe des outils pour déboguer, pour faciliter le test d’alerte… cependant, ces outils ne sont pas mis en valeur par des tutoriaux / Getting started, ce qui fait que le coût d’entrée pour écrire ses premières alertes est assez élevé. La communauté est moins importante que celle d’autres outils tels que Prometheus. Il est donc plus difficile de trouver des informations hors de la documentation officielle.
Clustering
Pour activer le clustering, il faut passer sur la version Kapacitor Enterprise. Actuellement sur la version 1.4, le mode cluster n’est pas encore complètement terminé : certaines opérations doivent être exécutées sur tous les noeuds. Mais le dédoublonnage des alertes est bien fonctionnel d’après la documentation. Nous n’avons pas testé cette solution.
Conclusion
Le produit s’intègre simplement dans la stack d’InfluxData mais sa prise en main reste complexe. La syntaxe des scripts tick n’est pas intuitive et certaines ambiguïtés auraient pu être évitées grâce à une documentation plus fournie. Nous sommes curieux de voir son utilisation en production sur des cas concrets. En effet, nous avons vu que Kapacitor dans sa dernière version (1.4) intègre des fonctionnalités de pilotage d’infrastructure (autoscaling sur docker swarm et EC2).
Vous pouvez retrouver le code ansible de cet article ici : https://gitlab.octo.com/tpatte/monitoring_kapacitor