L'Edge computing, challenger ou partenaire du Cloud en milieu industriel ? - Compte rendu du Comptoir x Duck Conf 2022 de Baptiste O’Jeanson et Louison Roger
Cette année, La Duck Conf s'invitent aux Comptoirs OCTO.
De nos jours, les usines sont de plus en plus équipées, intelligentes, technologiques… mais elles fonctionnent bien trop souvent de manière isolée.
Aujourd’hui, la priorité est de mettre en commun la connaissance industrielle par la donnée dans le but d’optimiser la performance industrielle globale. Cependant, collecter les données en milieu industriel n’est pas une mince affaire et apporte de nombreux challenges.
Dans ce comptoir, Baptiste et Louison nous montrent comment le mariage Edge - Cloud permet de répondre à ces challenges en déployant et en monitorant des solutions intelligentes, et évoquent un certain nombre de bonnes pratiques DevOps.
La vidéo du comptoir est disponible ici.
Ce comptoir s’inscrit dans la continuité du comptoir MLOps : les bonnes pratiques de la Data Science en production ?
Le Cloud, l’Edge
Définitions et caractéristiques
Pour commencer, deux définitions :
Le National Institute of Standards and Technology nous dit que :
“Le Cloud computing est l'accès via un réseau de télécommunications, à la demande et en libre-service, à des ressources informatiques partagées configurables.”
Une contrainte se dégage : l’accès à une connexion internet.
L’Edge computing est l’ensemble des solutions hardware et software qui permettent de rapprocher la collecte et la restitution des données de l'utilisateur final, dans le but de répondre aux contraintes imposées par l'environnement de production.
Deux notions émergent :
- la proximité entre la collecte et la restitution des données de l’utilisateur final
- l’environnement de production qui dicte les contraintes
Continuons avec les principales caractéristiques du Cloud et de l’Edge computing :
Le Hardware
Concrètement, on retrouve quoi comme matériel dans le Cloud ?
On va retrouver des racks de serveurs reliés par de la fibre optique.
Et côté Edge ?
On peut retrouver deux catégories de matériel :
- des Edges serveurs : ça s’apparente à un datacenter (ce qu’on retrouve dans le Cloud, mais en plus petit) proche de là où on en a besoin, c'est-à-dire l’usine.
- des Edges devices : tout système de traitement programmable disposant d’une capacité de calcul (CPU, GPU, TPU). Ça peut être un ordinateur portable, une tour, une tablette, un smartphone ou du matériel plus “bas niveau” comme un Raspberry, ou une carte Coral.
Enfin, on retrouvera des Edges sensors (ou IoT) auquel notre Edge device (ou Edge serveur) sera connecté qui sont des capteurs : capteur de proximité, caméra, douchette pour code barre, capteur de pression, de température, etc.
Qu’est-ce qui sépare le Cloud de l’usine et des Edges ?
Une connexion internet !
Les Uses-cases
À présent qu’on a une meilleure idée de ce que sont le Cloud et l’Edge computing, parlons use-cases.
Imaginons un industriel qui produit des bonbons. Il fabrique des bonbons de forme “ronde” et des bonbons de forme “carrée”. Chaque type de bonbons est produit sur une ligne de production dédiée. Ici, partons du principe qu’on s’intéresse à la production de bonbons “carrés”. Sur la ligne de production, on a :
- un convoyeur qui achemine les bonbons
- un Edge device (une tour) qui est connecté à
- des capteurs : une caméra pour prendre en photo les bonbons et un capteur de proximité (ou détecteur de présence) pour savoir quand les bonbons sont devant cette caméra
- un convoyeur pour savoir le numéro du lot de bonbons en cours de production qui passent devant l’Edge device
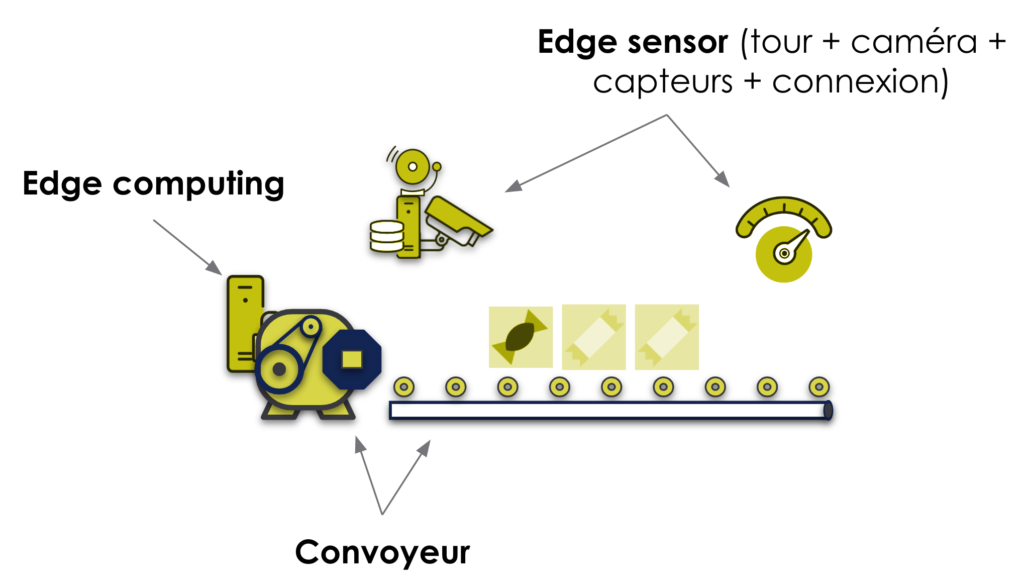
Inspection visuelle
Sur cette ligne, on ne souhaite pas que des bonbons “ronds” s'immiscent dans la production de bonbons “carrés”.
Un premier use-case serait de distinguer les bonbons “ronds” des bonbons “carrés” pour éviter ce problème de mélange. Pour ce faire, on pourra s’appuyer sur des photos des bonbons prises par la caméra pour les classer et envoyer ces informations au convoyeur pour agir en conséquence. C’est ce qu’on appelle de l’inspection visuelle.
La capacité à capter des informations contextuelles en étant proche du terrain est fondamentale. De plus, la possibilité d’agir en temps réel l’est tout autant, car on ne souhaite pas arrêter la ligne de production en attendant la décision.
Maintenance prédictive
Un deuxième use-case pourrait être de prédire quand le convoyeur ou la presse fabriquant les bonbons tomberait en panne. Pour ce faire, on pourra s’appuyer sur les données provenant des capteurs de pression ou de température, placés sur la machine, pour anticiper une anomalie. Si un écart est à prévoir, l’information sera communiquée à l'usine de manière à planifier la maintenance nécessaire en amont de la panne. C’est ce qu’on appelle de la maintenance prédictive.
Pour un tel use-case, la notion de proximité terrain ne sera nécessaire que pour la collecte des données. En effet, les machines industrielles sont conçues pour être robustes et fiables : on ne s’attend pas à des maintenances tous les jours. De ce fait, le traitement des données pourra être fait dans le Cloud.
Dataviz pour l’analytics
Un troisième use-case pourrait être de construire un dashboard de suivi de la production croisé avec les données des ventes pour répondre à des questions d’analytics comme : combien a-t-on produit de bonbons l’année dernière ? Lequel se vend le mieux ?
C’est ce qu’on appelle de la dataviz pour l’analytics.
Ici aussi, la notion de proximité terrain ne sera nécessaire que pour la collecte des données. La structuration et le stockage des données pourront se faire dans le Cloud. De même pour la construction et la publication (exposition) du dashboard.
À travers ces différents use-cases, on voit bien que dans certains cas, il sera obligatoire d’être proche du contexte, “dans le feu de l’action”, là où ont lieu les événements, car la cadence de production doit être respectée. On aura besoin de puissance de calcul à l’Edge. C’est le cas de l’inspection visuelle.
Dans d’autres cas, la proximité avec la ligne de production n’est nécessaire que pour collecter les données. Pour le reste, il n’est pas bloquant d’avoir une latence dans le Cloud.
Pour aller plus loin : la question du (ré)entraînement de modèles
Chacun de ces use-cases pourra impliquer l’entraînement ou le réentrainement de modèles. Par exemple, pour distinguer les bonbons “carrés” des bonbons “ronds”.
La collecte de données nécessite d’être proche de la ligne de production. En revanche, l'entraînement peut être fait dans le Cloud pour bénéficier de sa puissance de calcul quasi infini à la demande.
La complémentarité Edge/Cloud dans l’industrie
Notre constat
Les industriels sont focalisés sur la maximisation de la productivité. En effet, la cadence dans l’usine et la qualité de la production sont les deux principaux facteurs qui impactent les revenus. De plus, nous avons remarqué que les usines étaient toujours plus intelligentes et autonomes, mais qu’elles avaient toujours besoin d’ajustement et de réglages pour répondre à des contraintes liées aux produits, fournisseurs, conditions extérieures, etc. Enfin, l’autonomie des usines peut parfois induire une certaine isolation, par la distance entre les usines d’un grand groupe international ou même par la langue, par la culture, l'histoire, etc.
Notre vision
Mettre en commun la connaissance industrielle permettrait :
- une amélioration de la qualité
- une meilleure gestion des flux
- une innovation plus ciblée
- d'éviter les arrêts de production liés aux pannes grâce à la maintenance prédictive
- le partage du savoir
Pour cela, nous proposons aux usines, et plus largement aux groupes industriels de :
Collecter la donnée : récupérer les données des instruments, des machines dans les usines
Structurer la donnée : stocker les données de manière ordonnée et pérenne
Enrichir la donnée : construire des dashboards, faire de l’IA, construire des modèles prédictifs
Restituer la donnée : aider à la décision en usine
Une partie de ces activités nécessite d’être à proximité de l’usine, voire d’intégrer aux moyens de production :
- la collecte des données (connexion au convoyeur, aux capteurs de proximité, à la caméra, etc)
- une partie de l’enrichissement des données (résultat de l’inférence d’un modèle sur une image par exemple)
- la restitution sous forme d’information à l’usine (indiquer au convoyeur d’envoyer le bonbon au client ou le mettre à la poubelle)
L’Edge est propice à l’exécution de ces tâches.
D’autres activités peuvent être faites là où on le souhaite :
- la structuration des données (stockage dans une base de données ou dans du stockage objet)
- une partie de l’enrichissement des données (entraînement d’un modèle de classification, croisement de données)
Le Cloud, par son élasticité, sa capacité quasi infinie, son coût à l’usage et son offre de service composable, semble être le candidat commis d’office.
Notre classifier de bonbons à l’échelle : manager une flotte d’Edges
Déployer un use-case sur une ligne de production est une chose, mais qu’en est-il de le déployer sur plusieurs lignes dans plusieurs usines ?
Voici les principales étapes pour manager une flotte d’Edges :
- Installer le hardware nécessaire sur la ligne de production
- Installation de l’Edge serveur/device à côté de la ligne de production
- Installation des Edge sensors nécessaires à la collecte de données
- Raccordement du matériel et démarrage de l’Edge
- Onboarding d’un nouvel Edge serveur/device dans la flotte
- Installation de drivers et de librairies
- Configuration des utilisateurs et des accès
- Création de dossiers
- Mise à jour de la solution déployée à l’Edge
- Déploiement de nouvelles versions du logiciel
- Déploiement de nouveaux modèles de ML
- Monitoring de la flotte d’Edges
- Remontée de métriques des Edges vers le Cloud en temps réel (télémétrie)
- Remontée de données (images, métadonnées) des Edges vers le Cloud en temps réel (stockage objets ou dans une base de données)
- Heartbeat et health check pour s’assurer que les Edges sont opérationnels
Toutes ces étapes peuvent être implémentées en s’appuyant sur des solutions libres comme :
- Ansible, pour la configuration et l'installation des Edges, mais aussi pour la gestion d’infrastructure dans le cloud
- Grafana, pour construire des tableaux de bord de monitoring
Ainsi que des solutions PaaS comme Azure IoT Edge, AWS Greengrass, GCP IoT Core : pour exécuter des logiciels à l’Edge, gérer leurs mises à jour et leur fonctionnement.
Azure IoT Edge, une solution managée
Baptiste et Louison nous détaillent la solution d’Azure, puisque c’est celle qui était la plus mature il y a 8 mois et qu’on retrouve en général chez les clients (ce qui est dû au fait que la suite Microsoft est déjà bien présente chez les industriels).
Azure IoT Edge comprend trois composants principaux :
- Les modules IoT Edge : ce sont des conteneurs (Docker) déployés à l’Edge qui exécutent des services Azure, des services tiers ou son propre code.
- Le runtime IoT Edge composé de deux modules principaux :
- L’Agent : s’occupe de l’instanciation des modules, vérifie qu’ils continuent à s’exécuter et signale l’état des modules à IoT Hub
- Le Hub : joue le rôle de proxy local pour IoT Hub en exposant les mêmes points de terminaison de protocole qu’IoT Hub
Pour plus de détails, voici le lien vers la documentation Azure.
Azure IoT Edge, l’orchestration
Pour utiliser la solution Azure IoT Edge afin d’orchestrer une flotte d’Edges, il faut :
- Créer un hub IoT
- Enregistrer un appareil IoT Edge
- Configurer votre IoT Edge (Installer le runtime IoT Edge)
- Déployer un module
Toutes ces étapes sont automatisées dans un playbook Ansible versionné pour assurer la répétabilité et l’idempotence.
Azure IoT Edge, une première implémentation
À droite, notre environnement Edge dans l’usine, deux lignes de production sur lesquelles est déployée notre solution de classification de bonbon (classification : OK / KO).
À gauche, l’environnement Cloud, dans lequel on retrouve :
- L'IoT Hub, qui va orchestrer nos déploiements et va communiquer avec l’ensemble des Edges via leurs agents.
- Un storage account, qui va nous permettre de sauvegarder les images prises sur la ligne pour de potentielles futures analyses ou pour le réentraînement de notre classifier
- Une instance de base de données PostgreSQL pour le stockage des métadonnées liées aux bonbons (timestamp de passage sur la ligne, code barre, goût, décision)
- Un dashboard Grafana pour monitorer nos Edges et leurs prédictions
Nos takeaways
Takeaway #1
Mettre en commun la connaissance industrielle pour :
- Améliorer la qualité industrielle
- Avoir une meilleure gestion des flux
- Faire de la maintenance prédictive
- Partager du savoir
Takeaway #2
La complémentarité Edge x Cloud :
- Privilégier l’Edge lorsqu’une réponse en temps réel sans latence est nécessaire
- Privilégier le Cloud pour des usages à froid
Takeaway #3
Automatiser le déploiement et le management de vos flottes d’Edges : utiliser les services managés comme Azure IoT Edge / Hub pour ne pas réinventer la roue et ne pas à avoir à maintenir l’outillage.