Lean for Machine Learning (ML)
La mise en production d’algorithmes d’apprentissage est un chantier dont il faut savoir anticiper l’ampleur. Notre expérience nous a montré que la brique algorithmique n’est qu’une petite partie d’un système complexe : c’est pour cela que nous travaillons à son intégration dans le SI au plus vite afin de lever les inconnues dues à ses spécificités. Dans cet article, nous vous proposons une démarche conduite conjointement avec le métier, dans le but premier d’apporter de la valeur à l’utilisateur final.
Pour illustrer notre démarche de mise en production d’algorithmes de Machine Learning (ML), nous allons partir de l’exemple fictif de mise en production d’un algorithme de recommandation d’articles sur le blog d’OCTO. Il s’agirait de proposer des articles de façon personnalisée aux visiteurs du site.
Pour un retour d’expérience dans la mise en production d’algorithmes de machine learning, vous pouvez également vous référer à cet article.
PRÉSENTATION DU CONTEXTE
Imaginons que notre blog fonctionne avec l’architecture initiale ci-dessous :
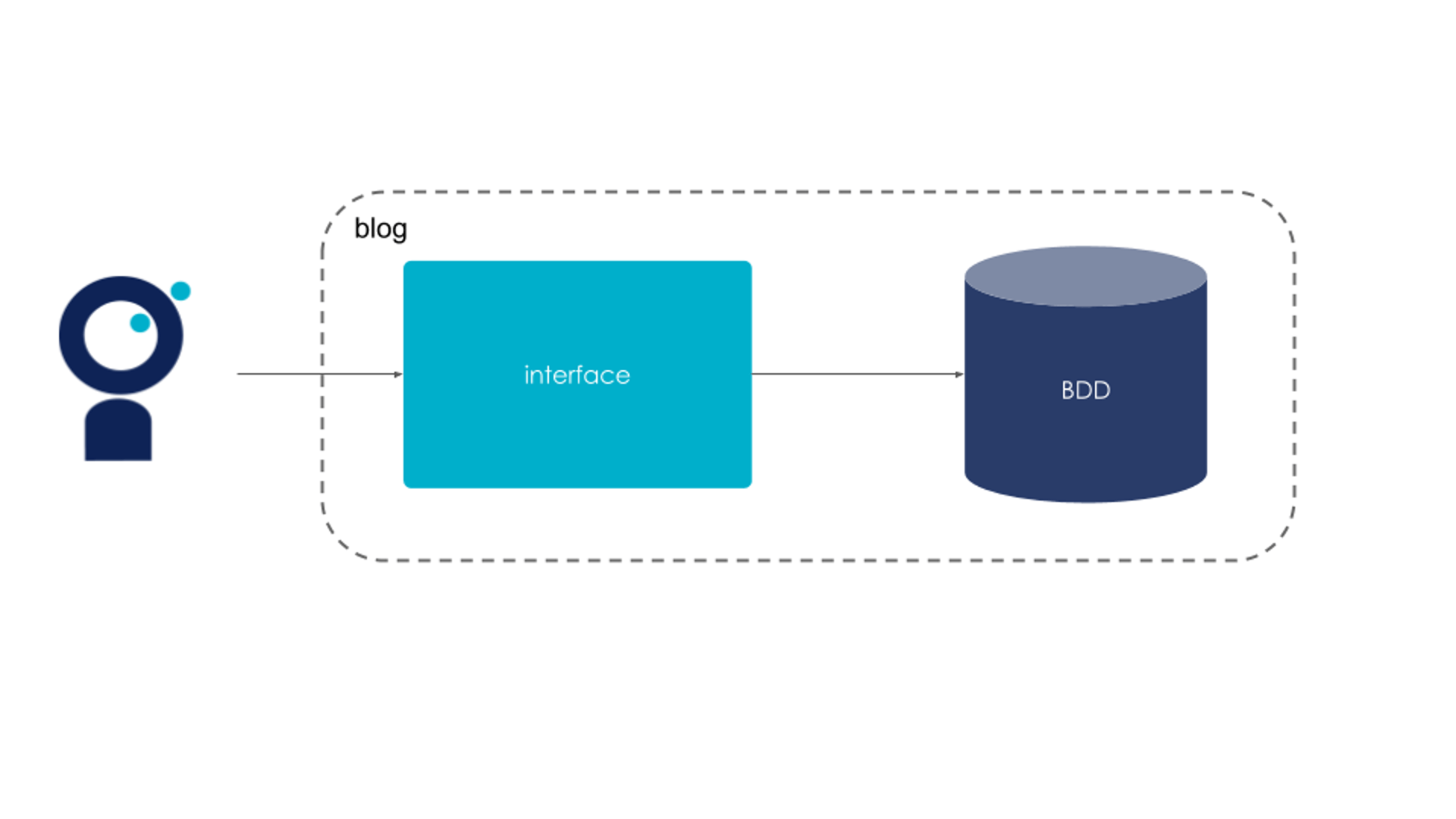
Figure 1 : L’architecture initiale du blog
Pour ajouter notre fonctionnalité de recommandation, nous souhaitons intégrer notre algorithme de recommandation à notre application. Ceci soulève un certain nombre de questions sur plusieurs axes :
Axe métier et utilisateur : Quelles valeurs pour quels key performance indicators (KPIs) souhaitons-nous atteindre ? Précisions que dans la suite de cet article, nous utiliserons le sigle KPI pour parler exclusivement des indicateurs métier.
Axe scientifique : Quelle(s) métrique(s) de machine learning souhaitons nous optimiser ? Quel impact l’optimisation de cette ou ces métrique(s) a sur les KPIs ? Rappelons que le lien entre métrique machine learning et KPIs ne va pas toujours de soi (pour quelques exemples de comment les faire converger, voir cet article).
Axe technique : Comment notre architecture va t-elle évoluer pour intégrer ces évolutions ?
Ces questions amènent plusieurs chantiers qui sont souvent difficiles à appréhender quand on travaille sur des produits de delivery classique. Le but de notre article est de proposer une méthodologie qui va nous aider à continuer à apporter de la valeur à notre produit pour nos utilisateurs en assurant un service fonctionnel tout en priorisant nos chantiers de la meilleure façon.
1. Start with why : une démarche co-construite avec le métier, centrée sur l’utilisateur
Au coeur de notre démarche : l’utilisateur et le métier. La mise en place de systèmes intelligents basés sur des algorithmes n’est utile que si l’objectif est d’aider le métier à atteindre sa mission et/ou d’améliorer l’expérience des utilisateurs. Ainsi, avant toute chose, la première étape de notre démarche consiste à s’aligner avec le métier sur des KPIs mesurables qui caractérisent au mieux son écosystème et sur la façon de mesurer ces KPIs.
Dans notre exemple fictif (tous les chiffres communiqués ici sont issus de notre imagination), on suppose qu’OCTO souhaite augmenter sa notoriété et positionner les Octos comme des experts sur les sujets tech. Il s’agit ici de l’objectif métier. La Com’, qui gère le blog OCTO, considère en effet qu’en améliorant la pertinence des articles proposés, les lecteurs liront plus d’articles, passeront plus de temps sur le blog et auront ainsi plus de chances de se souvenir d’OCTO à la fin de leur navigation. La valeur pour l’utilisateur, c’est à dire le lecteur du blog, réside dans le fait d’avoir du contenu pertinent et cela passe par la personnalisation des articles recommandés.
La Com’ se rapproche alors d’une équipe de consultants OCTO, qui lui propose de co-construire des KPIs afin de déterminer une façon de mesurer l’impact de l’algorithme de recommandations vis-à-vis de l’objectif recherché. Dans cette optique, les consultants organisent des ateliers afin de comprendre le besoin du métier et pour le traduire par des indicateurs. Les KPIs que l’on décide alors de suivre sont :
Le nombre de visiteurs uniques par mois : plus il y en a, plus le blog est visible. A ce jour, il est de 1000 utilisateurs par mois.
Le nombre d’articles lus par visiteur : plus le visiteur lit d’articles, plus il aura des chances de se souvenir d’OCTO et de reconnaître son expertise technique. Aujourd’hui, il est d’1,5 pour OCTO.
Le temps passé sur le blog : mesuré grâce au temps moyen d’une session utilisateur. Il est aujourd’hui de 12 minutes.
Notons qu’on cherche à faire un état des lieux actuel en mesurant les KPIs avant la mise en production de l’algorithme (à la main et de façon ponctuelle) et on a ainsi déterminé une baseline.
La Com’ aimerait augmenter le nombre de visiteurs uniques à 2000 utilisateurs par mois, que le nombre d’articles lus par visite passe à 2 et que le temps moyen d’une session soit d’au moins 15 min. Pour cela, les consultants proposent à la Com’ d’ajouter des articles recommandés à côté de chaque article lu par un utilisateur.
Figure 2 : Le blog aujourd’hui
Figure 3 : Le blog avec la fonctionnalité de recommandations personnalisées selon le lecteur
2. What : modéliser notre problématique métier d’un point de vue Machine Learning
L’équipe de Data Scientists cherche alors à traduire la problématique de la Com’ en un problème de Machine Learning. Pour cela, on part de notre volonté d’améliorer la pertinence. Il est donc nécessaire de déterminer quels articles intéressent nos lecteurs. Dans un monde idéal, on aimerait faire lire tous nos articles à tous nos lecteurs et leur demander lesquels les intéressent. Dans la réalité, l’objectif métier n’est pas directement mesurable, il faudra se contenter d’une variable corrélée qui, elle, l’est (un proxy). Il s’agit de déterminer ces proxys avec le métier.
Suite à une discussion avec la Com’ et à l’observation des statistiques de navigation, on décide de considérer qu’un lecteur du blog est intéressé par un article s’il clique dessus et n’est pas intéressé par l’article si on le lui propose mais qu'il ne clique pas dessus. Si l’article ne lui est jamais proposé, on suppose que le label est manquant : on cherchera à le prédire. La métrique de machine learning retenue par l’équipe pour évaluer notre modèle est la ROC AUC. Les considérations liées au choix du critère et à celui de la métrique sont hors du périmètre de cet article. Pour creuser ce dernier point, voir cet article.
3. How : une approche itérative
Sur la base de ces KPIs, la suite de notre approche sera d’améliorer itérativement notre algorithme en déroulant une méthodologie qui se résume en trois principes tirés des réflexions de Henrik Kniberg sur l’Agile Product Ownership :
DO IT FAST : Prioriser la mise en production
DO THE THING RIGHT : Intégrer la qualité par design
DO THE RIGHT THING : Être à l’écoute des utilisateurs pour améliorer le produit
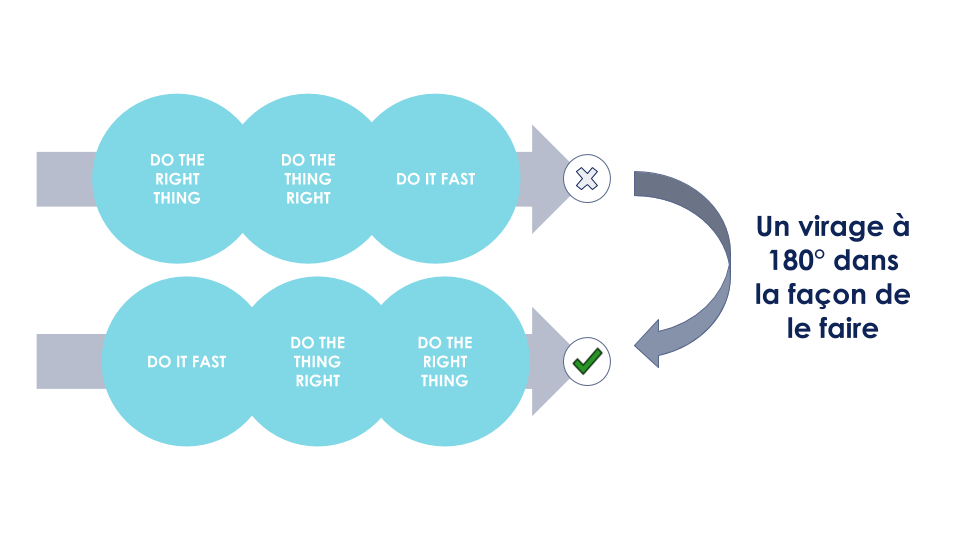
Figure 4 : Repenser la façon de mettre en production du machine learning
Le but est de renverser l’approche traditionnelle qui consiste à commencer par s’interroger sur l’approche à mettre en place, en posant des hypothèses non vérifiées empiriquement, pour ensuite se poser la question de l’implémentation technique et finir par mettre tout cela en production. On cherchera plutôt à se donner les moyens de mettre en production une solution au plus vite pour se confronter rapidement à la réalité. Afin d’arriver à cet objectif, nous intégrons la qualité dès le début du développement. Il sera alors plus facile d’adapter l’algorithme de recommandations selon nos observations en production : notre code sera facilement adaptable.
DO IT FAST : prioriser la mise en production
Dans cette étape, l’ambition est de tirer les flux jusqu’à la production le plus rapidement possible en adoptant une approche lean et incrémentale.
Lorsqu’on aborde un problème de machine learning, on a tendance à se focaliser sur la conception de l’algorithme. Cependant, les problématiques de mise en production de machine learning entraînent d’autres chantiers tels que : la collecte de données pour nos algorithmes, le monitoring des métriques, la mise en ligne du service de prédiction etc. L’algorithme n’est qu’une petite brique dans notre système intelligent qui est beaucoup plus vaste. Dans son papier “Hidden Technical Debt in Machine Learning Systems”, Google illustre ces propos à travers le schéma ci-dessous :
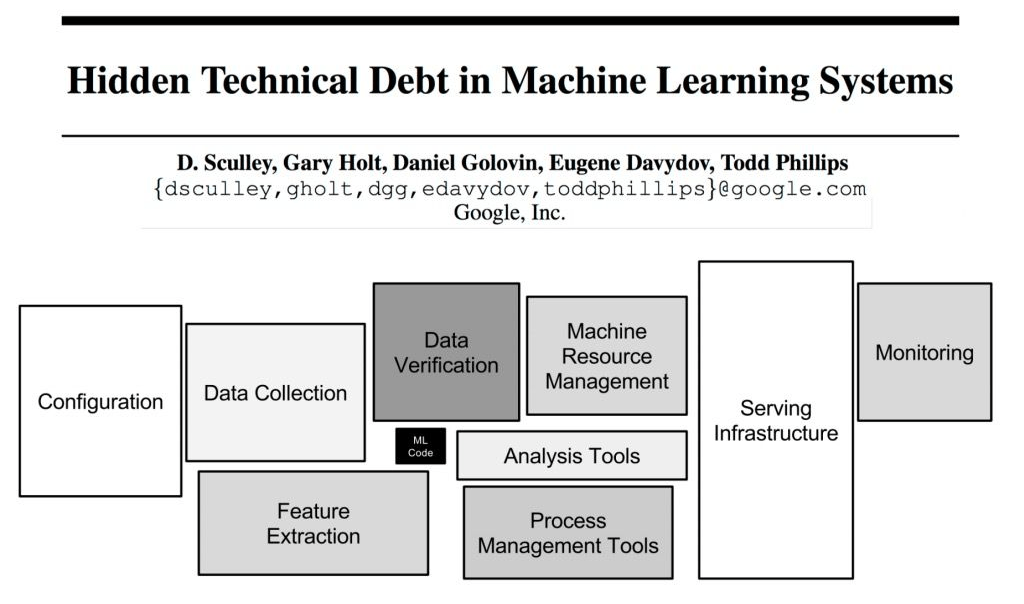
Figure 5 : Un système complet de ML selon Google
Vu qu’un système de ML n’est composé que d’une petite partie de code de ML, il nous semble donc contre-productif de dépenser une énergie démesurée dans l’amélioration marginale de la performance de notre algorithme hors production. Nous priorisons donc la mise en place d’une architecture évolutive de notre système plutôt que l’optimisation de notre modèle d’un point de vue ML.
Cela se traduit dans notre exemple par l’intégration d’un algorithme de recommandation simple en production. D’ailleurs, on n'utilisera pas tout de suite un modèle de ML, mais un algorithme rule-based, c’est-à-dire déterministe. Cela nous permettra d’intégrer la brique de recommandations à notre blog dans une logique de travail en petits incréments. On traitera alors quelques questions :
Comment allons-nous intégrer les recommandations à notre interface graphique ? Quel sera l’impact sur le reste du blog ?
Comment allons-nous servir nos prédictions ? Allons-nous développer une API ? Quelles sont les informations dont notre frontend aura besoin pour afficher les recommandations ?
Quelles sont les données qu’on souhaiterait exploiter afin de fournir des recommandations pertinentes (même déterministes) ? Où sont-elles ? Comment les récupérer ? Où les stocker ?
D’un point de vue technique, nous aurons dérisqué les incertitudes sur le flux de production, réfléchi à notre architecture et mis en service une brique de recommandations, tout en continuant d’assurer un service qui tourne.
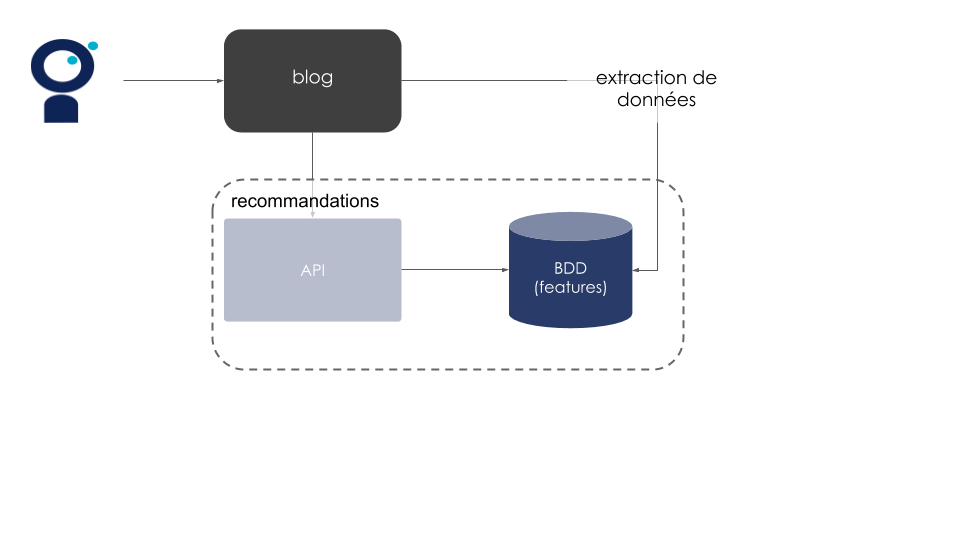
Figure 6 : Exemple d’architecture après intégration de la brique de recommandations
Une fois cette phase sécurisée, on peut aller plus loin et traiter la complexité d’intégrer un modèle apprenant. On ne priorise cependant pas encore la qualité scientifique de notre modèle. De façon caricaturale, supposons que nous développons un algorithme qui a une ROC AUC de 0.5 (ce qui correspond à la performance la plus faible possible de notre algorithme). Au lieu de nous concentrer sur l’amélioration de cette métrique, nous chercherons plutôt à déployer cet algorithme imparfait en production. Cela nous permettra de réfléchir à la façon de stocker notre modèle, affiner la liste des données que nous voudrions exploiter et commencer notre réflexion sur la façon d'entraîner notre modèle.
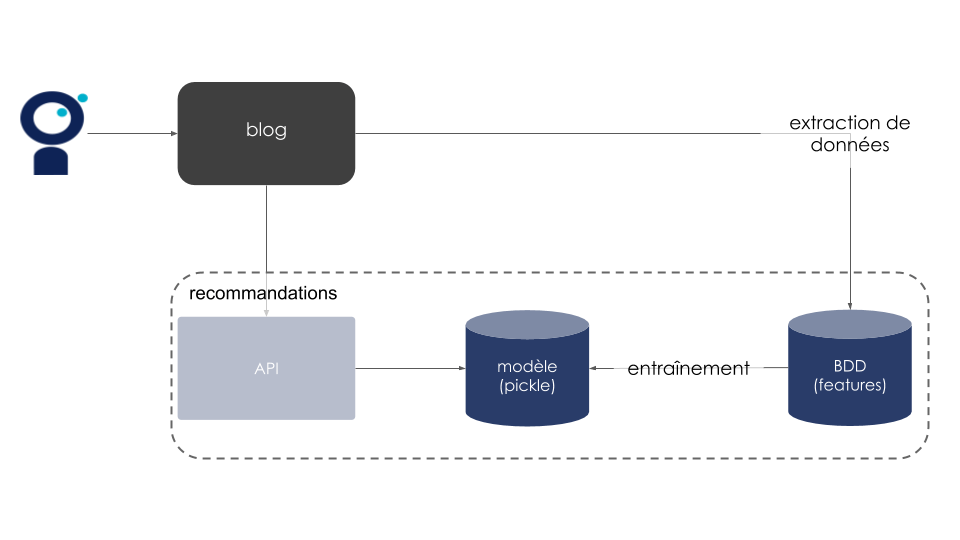
Figure 7 : Exemple d’architecture après intégration d’un modèle de ML simple
La mise en production de ces premiers modèles, pourtant basiques, soulève déjà beaucoup de questions. Les traiter au plus vite nous permet d’avancer par petits pas et d’être en mesure de montrer rapidement des résultats à la Com’, qui n’a pas à attendre qu’on trouve notre algorithme optimal pour commencer à avoir des recommandations sur le blog. Cette approche nous semble d’autant plus pertinente qu’elle nous permet d’avoir un feedback rapide de nos utilisateurs, en mesurant l’évolution de nos KPIs en conditions réelles (manuellement et de façon ad hoc). Même si nos indicateurs ne bougent pas, on pourra effectuer nos premières mesures et commencer à évaluer cette feature en fonction de ces métriques.
DO THE THING RIGHT : se soucier de la qualité
Afin de rendre notre brique de recommandations facilement adaptable, nous nous soucions de la qualité du code et des artefacts associés à nos systèmes de machine learning. Pour cela, il s’agit de traiter la brique technique associée à l’algorithme comme nous le faisons pour un logiciel standard, et ce dès le tout début du développement. L’équipe travaillant sur la mise en production du système de recommandations suivra les bonnes pratiques DevOps, Agile, et de Software Craftmanship, tout comme le reste de l’équipe.
Un système de Machine Learning comporte ses propres particularités, comme souligné dans l’article Continuous Delivery for Machine Learning. On cherchera donc à adapter certaines bonnes pratiques de développement à notre contexte. Nous sommes toutefois convaincus que développer un système de ML reste une tâche de développement. À ce titre, on s’appuie sur les différentes capabilites d’Accelerate. Détaillons par la suite les principales pratiques de développement qui nous ont paru le moins évidentes en tant que Data Scientists et comment nous proposons de les généraliser à la mise en production de systèmes de ML :
Versionner
Il s’agit de garder la trace de l’état de notre système de recommandations dans le temps afin de pouvoir l’auditer mais aussi pour pouvoir revenir facilement à un état antérieur si besoin. Dans un logiciel classique, on versionnera surtout le code. Dans un projet de Machine Learning, il faudra aussi garder un historique des données utilisées pour l’entraînement de notre modèle, des modèles déployés dans le temps ainsi que de leur performance.
Tester
Nous sommes convaincus que le code de machine learning, comme tout code applicatif, a besoin d’être testé.
Il s’agit ici de tester chacune des briques le composant ainsi que leur intégration. Il est également nécessaire de tester le système entier de bout en bout, pour valider que tous les pipelines sont correctement orchestrées et permettent la mise à disposition des recommandations à l’utilisateur final.
Enfin, il est pour nous important de discuter avec le métier de tests d’acceptance d’un nouveau modèle, qui permettront de rendre accessibles en production uniquement les modèles ayant une performance supérieure à un certain seuil d’une métrique choisie.
En disposant d’un harnais de tests fiable, il sera alors bien plus facile de changer de modèle ou d’adapter notre pipeline d’entraînement tout en s’assurant de l’intégrité de notre système.
S’intégrer aux processus d’intégration continue et de déploiement continu (CI/CD)
On intégrera donc naturellement les tests liés à l’algorithme de recommandations à un outil d’intégration continue. On cherchera également à automatiser le déploiement de notre brique de recommandations et on n’hésitera pas à utiliser des méthodes telles le blue / green deployment pour sécuriser nos mises en production.
On optera également pour le feature flipping (expliqué en BD ici), qui nous permettra d’activer et désactiver notre algorithme en cas de besoin. Ainsi, imaginons que nous développons un algorithme qui fait passer notre ROC AUC à 0.8 lors de nos tests en local (un score honorable sur le papier, et supérieur aux 0.5 précédents). Nous le déployons en production, mais pour des raisons que nous n’avons pas anticipées, il fait plonger le temps moyen d’une session utilisateur à 5 minutes, le nombre de visiteurs uniques par mois et nombre d’articles lus par visiteur restent constants. On sera alors heureux de pouvoir aisément basculer vers la version précédente de notre algorithme.
Cela facilite également la mise en place d’A/B testing sur une petite partie de nos utilisateurs. Ainsi, lorsque nous testons notre modèle de ML simple, nous ne le faisons que sur une toute petite proportion de nos utilisateurs. On vérifie alors que ce nouvel algorithme fonctionne bien en production tout en comparant son impact sur l’expérience de nos utilisateurs par rapport à l’autre modèle. S'il s’intègre comme prévu dans l’environnement applicatif et qu’il améliore nos KPIs, il sera déployé plus largement. Sinon, on utilisera notre feature flipping pour désactiver ce modèle.
DO THE RIGHT THING : répondre aux besoins des utilisateurs
Une fois la mise en production sécurisée, nous serons en mesure d’améliorer de façon incrémentale notre algorithme grâce à une brique de monitoring afin de nous adapter au mieux aux retours de nos utilisateurs.
Une fois en production, nous pouvons confronter les résultats de notre algorithme aux retours de nos utilisateurs. Ce feedback est d’autant plus riche qu’il est mesurable : il est donc important d’être en capacité de mesurer les KPIs métiers ainsi que des métriques techniques.
Nous nous attelons alors à définir des métriques techniques qui vont nous aider à suivre notre système de machine learning tout au long de la chaîne en mettant en place un monitoring avisé.
Nous allons donc :
automatiser le suivi de nos KPIs, les métriques métier identifiées au tout début avec la Com’. Nous les suivions déjà de façon manuelle, il s’agit maintenant de les intégrer à un outil de monitoring sous forme de dashboard et/ou d’alertes ;
suivre automatiquement les distributions de nos données d’entrée jugées intéressantes ainsi que nos prédictions (par exemple la proportions d’articles cliqués), pour déterminer des besoins de réentraînement ou des pistes d’amélioration pour nos modèles en cas de dérive.
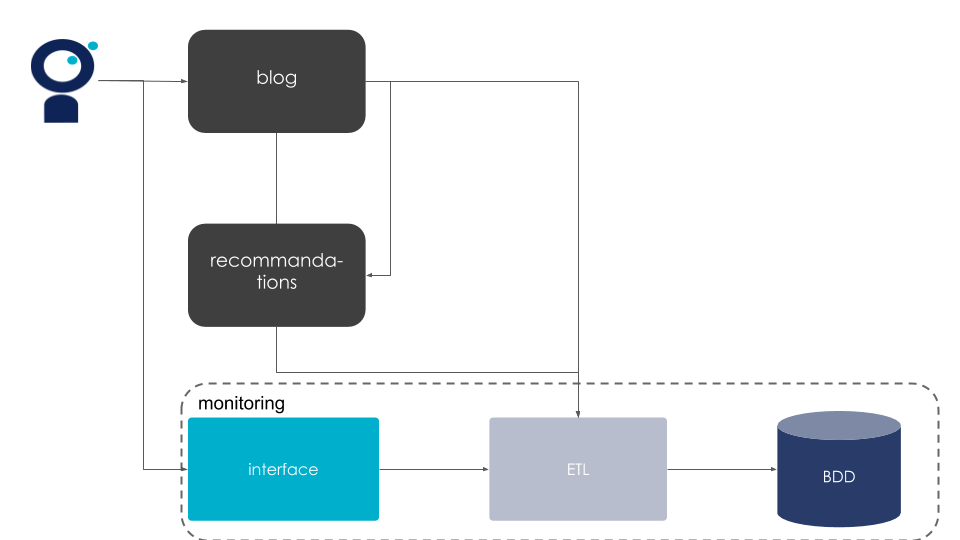
Figure 8 : Exemple d’architecture en intégrant du monitoring
Le but du monitoring est d’avoir une boucle de feedback rapide et utile, ainsi que d’offrir une solution préventive pour détecter les défauts sur notre système de machine learning en général et de nos modèles en particulier (Cet article expose une méthodologie à suivre pour le monitoring de système de ML). Ceci nous permet d’être plus réactifs et d’intervenir rapidement en cas de besoins urgents, mais aussi d’améliorer de façon éclairée et incrémentale notre algorithme. Nous pourrons ainsi être guidés dans nos futurs choix de POCs et de fonctionnalités à prioriser.
Supposons que notre système de monitoring nous montre que nos KPIs se dégradent. On remarque de plus que la distribution de nos données dérive : le réentraînement du modèle devient alors une tâche prioritaire. Au contraire, si on observe que la distribution de nos données est stable, que notre nombre d’articles lus par visiteur est passé à 3, le temps moyen d’une session utilisateur est à 20 mais le nombre de visiteurs uniques par mois est passé à 500, on s’interrogera sur les effets de bord de notre algorithme. Est-ce qu’il fait de l’over-spécialisation, ce qui intéresse beaucoup un plus faible nombre de lecteurs ? Se passe-t-il autre chose ? L’équipe pourra alors investiguer ce problème et guider les prochaines optimisations de notre algorithme de Machine Learning de manière éclairée par la donnée
CONCLUSION
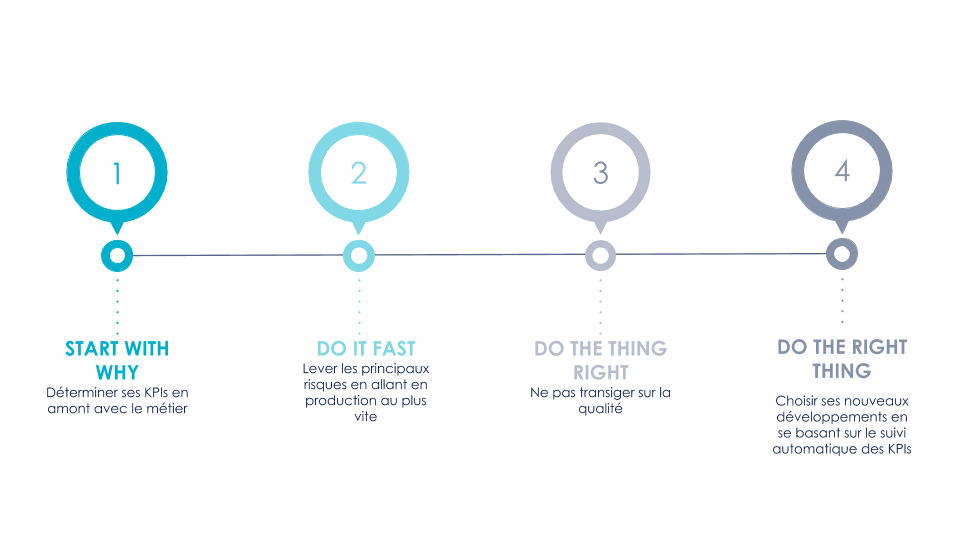
Figure 9 : Schéma récapitulatif de la démarche lean for ML
Lorsqu’il s’agit de faire un produit intégrant du machine learning, la plupart des data scientists se concentrent sur l’aspect modélisation et optimisation de métrique scientifique. Et pourtant, la mise en production d’un algorithme de machine learning engendre un certain nombre de chantiers que nous choisissons de prendre en compte dès le début de la conception du produit. Dans cet article, nous avons présenté une méthodologie pragmatique lean for ML qui peut se résumer en quelques points :
Être centré utilisateur et métier, en définissant des KPIs mesurables ;
Prendre du recul sur les métriques scientifiques en les mettant en perspective avec les KPIs métier ;
Privilégier les chantiers ayant des impacts dans l’architecture, comme l’intégration d’un modèle simple dans notre système, au lieu de se lancer directement sur le machine learning et sur l’optimisation des métriques ML ;
Privilégier, encore et toujours, la qualité : on va vite mais on fait bien. Avoir un code et une architecture propres nous permet de nous adapter facilement aux retours des utilisateurs ;
Observer l’évolution de notre système à travers des KPIs et des métriques provenant de notre système en production afin de guider nos actions futures.
Toutes ces bonnes pratiques nous donnent des bases solides pour améliorer incrémentalement notre algorithme... et surtout avoir des utilisateurs satisfaits !