Le Système d’Information Héréditaire : l’évolution par la transmission du patrimoine identitaire
Beaucoup d’entreprises partagent maintenant l’idée que pour rester compétitives, la donnée est un élément clef. Il y a quelques années, le Big Data était le nouvel Eldorado : les données ont d’abord été rangées dans des Data Warehouses, construits principalement pour alimenter les activités de Business Intelligence. Puis lorsque de nouveaux cas d’usages ont commencé à émerger, les solutions de stockage ont évolué vers des architectures de type Data Lake qui pouvaient accueillir de la données sous plus de formes. De nouvelles technologies sont apparues pour soutenir des usages de plus en plus diversifiés (exploration, self service …) et toutes ces initiatives ont fini par former des Data Platforms.
Pour autant, les systèmes mis en place ne sont pas toujours en mesure de fournir des solutions à la hauteur des attentes. L’entrepôt de données est devenu un monstre monolithique difficile à maintenir, et l’accès à la donnée est parfois compliqué. L’équipe data est sollicitée dans tous les sens et n’est pas tout le temps en mesure de répondre aux multiples attentes de leurs clients.
Lorsqu’un système n’arrive plus à faire face aux nouveaux défis qu’il rencontre, cela annonce souvent les prémices d’un changement. Dans son article “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh”1, Zhamak Dehghani présente le paradigme data-mesh dont nous parlerons dans cet article et qui permet d’adresser une partie de ces défis. Nous proposerons une approche complémentaire basée sur la transmission de l’identité qui permet de soutenir sainement la croissance du système d’information.
L’idée et les valeurs
À l’origine de chaque entreprise, il y a une idée, une réponse à des problèmes de la société. Cette réponse constitue la raison d’être de l’entreprise et si elle est communiquée efficacement, elle obtient l’adhésion des personnes qui partagent la même idée. Elles en deviennent même de fervents ambassadeurs2. Apple vs Microsoft, Bose vs Sonos, Amazon vs Google… Autant de face à face qui suscitent de grands débats passionnés. En se connectant à nos convictions profondes, ces entreprises parviennent à engager notre système limbique, siège de nos émotions. Cher lecteur, soit averti : ce parallèle avec la biologie est le premier d’une longue série dans ce qui va suivre.
Toutefois, la raison d’être à elle seule ne suffit pas à créer une entreprise. Après tout, pour un problème donné il existe souvent plusieurs solutions. L’idée, portée par un ou plusieurs individus, est accompagnée de valeurs qui conditionnent la manière de répondre à ce besoin : “nous vendons ces grains de café en favorisant le commerce équitable”, ou “nos conseillers répondent à vos besoins en toute bienveillance”. On se souvient tous des discours réservés aux nouveaux arrivants mettant en avant “les valeurs” ou “les piliers” de son entreprise. On parle même souvent d’ADN.
L’idée et les valeurs définissent donc ensemble l’identité de l’entreprise et conditionnent le développement de l’organisme qui va se construire pour répondre aux besoins exprimés.
La course à la croissance
Très vite, la taille de l’entreprise augmente. Les raisons sont multiples et souvent concurrentes : pour faire face aux marchés concurrentiels, ou pour mieux répondre aux besoins des clients, ou encore pour s’adapter à la charge des utilisateurs de plus en plus nombreux, ...
À mesure que l’entreprise grandit, l’organisme se développe et les rôles se spécialisent. Les tâches qui étaient autrefois portées par une ou quelques personnes sont reprises par des équipes, par des pôles ou des domaines. On pourrait ici aussi faire le rapprochement en biologie avec le développement des cellules embryonnaires : d’abord souches, les cellules se différencient ensuite pour remplir un rôle dédié dans l’organisme.
Mais à la différence d’un organisme biologique abordant son arrivée dans la vie par une phase d’apprentissage pour se déplacer, chercher sa nourriture et échapper aux dangers, il n’en est pas toujours de même pour un organisme économique.
Forcé à se lancer dans une course aux capitaux effrénée, l’organisme économique doit se développer au plus vite s’il veut “rester dans la course”. Or dans un domaine où tout le monde court, il doit courir deux fois plus vite que les autres pour avancer. Ce paradoxe est expliqué dans les travaux du biologiste Leigh Van Valen3 qui lui a donné le nom d'hypothèse de la reine rouge :
“l'évolution permanente d'une espèce est nécessaire pour maintenir son aptitude face aux évolutions des espèces avec lesquelles elle co-évolue”

‘Now, HERE, you see, it takes all the running YOU can do, to keep in the same place.
If you want to get somewhere else, you must run at least twice as fast as that!’
En parallèle de cette croissance, l’identité de l’entreprise doit se préserver en dépit du nombre de Dunbar4. Cette limite imposée par la taille de notre néocortex représente le nombre de personnes avec lesquelles un individu peut avoir des relations stables.
Pour franchir cette limite biologique, les entreprises ont recours à plusieurs solutions s’articulant autour de la même idée : puisque le groupe devient trop grand, il est donc nécessaire de le fractionner. Pour garder l’idée et les valeurs, chaque sous-groupe hérite des concepts du collectif. Ainsi émergent des groupuscules au noms diverses : pôles, tribus, ligues, communautés, … tous liés par une même identité.
Pour soutenir la croissance et permettre à ces groupes de communiquer, un Système d’Information se développe en miroir de l’organisation.
Dans la plupart des entreprises, le SI s’organise aussi en périmètres distincts : pôle data, environnement de développement, de production, usine logiciel, CRM, système de paie, plateforme d'achat ... Ce schéma de développement contraint par l’organisation est très bien décrit par la loi de Conway :
“Les organisations qui conçoivent les systèmes … sont contraintes de produire des modèles qui sont des copies de leur propre structure de communication”
Cette loi est connue pour être souvent citée avec ironie, mais elle est pourtant une dure réalité du monde de l’entreprise5.
En plus de ces silos métiers, on observe bien souvent aussi des séparations en pôles d’expertises. Les domaines manipulant de la donnée en sont un bon exemple. En effet, comme les possibilités d’exploitation de la donnée sont très nombreuses, il n’est pas rare de voir apparaître des équipes aux rôles spécifiques : Business Intelligence, Data Visualization, Data Science, Data Governance, Data Warehouse…
Avec le temps, la taille de tous ces périmètres augmente. De la croissance émerge de nouveaux challenges : adaptabilité, agilité des pratiques, raccourcissement du time to market, maintien en conditions opérationnelles et prévention des défaillances… Et les organisations en silo ont du mal à faire face. Les interactions sont ralenties, et les processus de plus en plus complexes... autant de raisons qui perturbent la croissance de l’organisme.
Pour autant, il existe maintenant beaucoup de solutions à chacun de ces problèmes : agilité, pratiques DevOps, intégration continue, livraison continue… Les entreprises sont en pleine transformation pour adopter ces nouvelles pratiques.
Une question reste cependant en suspens dans beaucoup d’entreprises :
“Qu’allons-nous faire de toutes ces données qui s’accumulent dans différents endroits du SI ?”
Vers un nouveau paradigme
Force est de constater après plusieurs années que le Big Data et les architectures de type Data Lake n’étaient pas les “silver bullet”6 qui ont été promises7. Beaucoup d’entreprises se retrouvent avec un monstre monolithique, contenant de la donnée sous presque toutes ses formes : structurées, non structurées, modélisées ou brutes… Les challenges d’accès à la donnée sont nombreux et difficiles à adresser.
Même si les approches de type flux de données sont venues apporter un nouvel élan aux initiatives portées par la donnée, bien souvent les pipelines se sont multipliés. La donnée est transformée à différents endroits du SI et transite par plusieurs équipes, si bien qu’une équipe n’a souvent aucune idée des raisons pour lesquelles la donnée qu’elle manipule existe en premier lieu.
Le système donne pourtant l’impression d’évoluer. En faisant évoluer les outils technologiques pour toujours rester à l’état de l’art, le système se construit avec un ensemble de pratiques reconnues qui fournissent indépendamment des solutions aux problèmes rencontrés. Cet ensemble de pratiques et de règles forment un paradigme. Comme le décrit le philosophe des sciences Thomas Khun8, un paradigme est un modèle qui s’impose pendant une période donnée. C’est l’ensemble des théories, des méthodes, et des conceptions ontologiques qui fournissent à la fois une description des problèmes types rencontrés et des solutions qui les adressent.
Or le paradigme atteint ses limites lorsque de nouveaux problèmes surviennent et qu’il ne fournit pas de solution. Si tel est le cas, il faut alors envisager d’en changer.
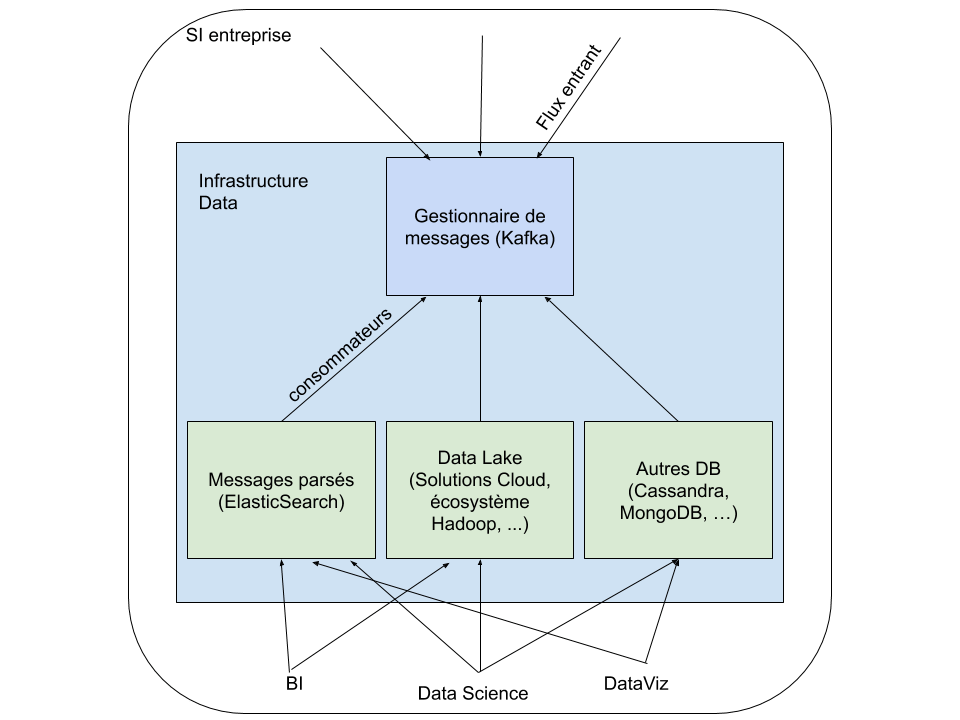
Exemple d’un monolithe : les applications consommant de la donnée doivent se connecter aux systèmes qui gèrent la donnée
C’est ce que suggère Zhamak Dehghani en proposant une organisation différente basée sur une architecture Data Mesh1. Ce changement de paradigme repose sur l’adoption simultanée de plusieurs concepts qui ont déjà fait leurs preuves : Distributed Domain Driven Architecture9, Self-serve Platform Design10, et Product Thinking11 (les liens fournis ici permettent d’entrer un peu plus dans le détail de ces concepts).
Si a priori cela ressemble à une accumulation de buzzwords techniques, leur utilisation fait sens. En regroupant les processus utilisant la donnée en Domaine, chacun serait défini par son usage de la donnée. Les domaines sont différenciés en plusieurs rôles : les domaines sources qui stockent la donnée d’entrée et les domaines orientés vers la consommation de la donnée, qui structurent et enrichissent les données des domaines sources. Les pipelines deviennent alors des objets internes aux domaines, et chaque domaine en est responsable. Ce paradigme n’est donc pas une solution de remplacement de l'architecture existante, mais plutôt une manière plus pragmatique d’exploiter la plateforme de données.
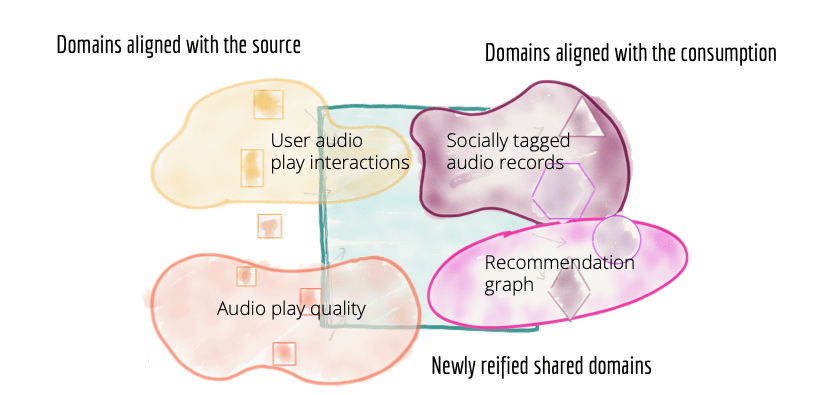
Décomposition de l’architecture data en domaines différenciés (source)
Pour réutiliser le parallèle avec la biologie, cette transformation vers un Data Mesh distribué permet de remplacer les groupes par des cellules organisées qui sont alimentées par la donnée et responsables de leur propre traitement de la donnée. Si cette nouvelle structure peut jouer un rôle essentiel dans une transformation réussie, elle n’est pourtant pas suffisante.
Pour en revenir à la croissance observée dans beaucoup d’entreprises : dans le cas des systèmes opérant la donnée, on constate souvent qu’une nouvelle entité (le data lake, le data warehouse, la plateforme data, ...) croît de manière disproportionnée au sein de l’organisme. Elle se développe non pas pour répondre à ses besoins, mais pour accommoder un flux de données toujours grandissant, pour simplement continuer à exister, ou encore pour rentabiliser le capital investi dans sa construction.
C’est ici que le parallèle avec la biologie prend tout son sens. Les cellules d’un organisme biologique peuvent se multiplier des milliards de fois, elles peuvent prendre plusieurs rôles et plusieurs formes et pourtant elles ne perdent jamais l’information essentielle : elles œuvrent toutes ensembles pour un organisme unique. Cette information, c’est le code génétique de l’organisme. Transmise de cellule en cellule, l’identité est toujours préservée.
En se développant trop rapidement, certaines cellules du système d’information peuvent perdre leur identité et ne plus partager le même ADN que le reste de l’organisme.
Un Système d’Information Héréditaire apparaît
Pour subsister tout en gardant l’identité de l’entreprise, les domaines - ou cellules - doivent hériter de trois éléments fondamentaux :
- L’identité (aka l’ADN) : l’ensemble des règles d’utilisation de la donnée définie par l’entreprise
- Le traducteur : en interprétant les règles spécifiques du domaine, il en définit son rôle
- La source d’énergie : caractérisé par la source de donnée entrante, c’est aussi la source de vérité du domaine
L’ADN
C’est le patrimoine distribué de référence. Les règles qu’ils renferment sont immuables et universelles. Elles définissent en détail toutes les façons de manipuler la donnée. C’est aussi le garant du niveau de sécurité fondamental de l’information.
En fonction des implémentations techniques disponibles, l’ADN peut prendre plusieurs formes : description de requêtes SQL, mode d’emploi pour l’alimentation ou consommation de topic Kafka, comment stocker des objets dans un bucket S3, comment exploiter la donnée via des jobs Spark, …
La manière de transmettre cet ADN doit être exhaustive, simple et claire, et surtout répliquée à l’identique pour chaque nouveau domaine.
Ainsi, les membres d’un nouveau domaine disposent des informations essentielles pour accéder aux données de manière fiable et sécurisée.
Le traducteur
Le traducteur conditionne l’accès à la donnée en utilisant les règles de l’ADN. Il gère les permissions et les utilisations.
Dans la pratique, c’est la liste de contrôle d’accès via un ensemble de stratégies qui autorise ou non la récupération des données d’un domaine source, mais aussi l’utilisation des services d’un autre domaine. C’est aussi lui le garant des règles métiers du domaine.
Cela permet de rendre disponible la donnée sans créer de zone cachée : tout est disponible mais seulement certains domaines peuvent y accéder.
La source d’énergie
La donnée est l'énergie nécessaire au bon fonctionnement du domaine, elle doit donc être accessible n’importe où dans l’organisme. Si les mécanismes de traduction présentés ci-dessus permettent l’omni-disponibilité de la donnée, encore faut-il connaître l’emplacement des sources dans le réseau.
Les adresses des domaines sources doivent donc être référencées et connues publiquement pour que tous nouveaux domaines puissent s’y connecter.
En veillant à la distribution de ces trois éléments, le système garde son intégrité et son individualité. Les domaines, aussi différents soient-ils, produisent ensemble la valeur qui fait avancer l’organisme entier, en partageant un patrimoine identitaire commun.
Mieux se connaître pour évoluer plus vite
En résumé, les techniques organisationnelles contrant la loi de Dunbar nous ont appris à nous organiser en groupe partageant la même identité.
Pour qu’un système d'information se développe sainement, il est nécessaire d’appliquer ces mêmes principes en distribuant l’ADN de l’organisme dans tous les domaines.
La mise en place de ces éléments n’est pas si coûteuse car beaucoup d'entreprises ont déjà des solutions dans ce sens : gestion d’ACL, exposition des services via des API publiques, …
Les avantages en revanche sont considérables :
- la gestion des domaines n’est plus centralisée
- les valeurs intrinsèques de l’organisme sont toujours conservées
- la mise à l’échelle n’est plus un effort mais devient naturelle
- la donnée est omniprésente et accessible à tous
- la répartition en domaines bien identifiés facilite l’exploration de la donnée, ce qui ouvre la voie à de nouveaux domaines apportant de la valeur
- la donnée ne s’accumule plus sans raison d’être et est identifiée comme étant l’énergie fournissant l’accélération
En définitive, l’évolution vers un système toujours plus concurrentiel implique bien souvent une croissance rapide et importante, mais la croissance de l’organisme doit se faire de manière raisonnée, en gardant en permanence les idées et les valeurs qui l'ont fait naître.
Pour aller plus loin, dans un prochain article nous discuterons des implications d’un changement de paradigme vers des concepts Data Mesh pour un cas d’usage concret, et nous discuterons de la valeur ajoutée de l’approche identitaire.
Références
<sup id="ref1">1^https://martinfowler.com/articles/data-monolith-to-mesh.html
<sup id="ref2">2^Sinek, Simon. Start with Why. Penguin Books, 2011
<sup id="ref3">3^Leigh van Valen, A new evolutionary law Evolutionary Theory, Vol. 1 (1973), pp. 1-30.
<sup id="ref4">4^Dunbar, R. I. M. (1992). "Neocortex size as a constraint on group size in primates". Journal of Human Evolution. 22 (6): 469–493. doi:10.1016/0047-2484(92)90081-J.
<sup id="ref5">5^http://www.hbs.edu/research/pdf/08-039.pdf
<sup id="ref6">6^https://en.wikipedia.org/wiki/No_Silver_Bullet
<sup id="ref7">7^https://www.thoughtworks.com/insights/blog/curse-data-lake-monster
<sup id="ref8">8^Khun, T. (1962). “La structure des révolutions scientifiques”
<sup id="ref9">9^https://blog.octo.com/domain-driven-design-des-armes-pour-affronter-la-complexite/
<sup id="ref10">10^https://martinfowler.com/articles/data-monolith-to-mesh.html#DataAndSelf-servePlatformDesignConvergence
<sup id="ref11">11^https://martinfowler.com/articles/products-over-projects.html