Le Serverless : prochaine pierre angulaire des applications pour IoT et Assistants virtuels
Depuis plusieurs années déjà, le concept d'IoT est sur le devant de la scène. Depuis 3 ans, le marché a émergé et des premiers exemples concrets sont là. Paris Aéroport modélise le comportement des passagers dans les terminaux grâce aux caméras de surveillance dans le projet Vasco. CMA-CGM a équipé ses conteneurs de capteurs. De plus en plus d'objets du quotidien deviennent connectés (ampoules, thermostats, ...). Les assistants vocaux virtuels ont déferlé dans les foyers à l'occasion des fêtes de fin d'année. D’un point de vue du système d'information ce sont tous des objets connectés. Ils vont permettre toujours plus d'interactions avec les utilisateurs ce qui est une bonne chose. Mais ils demanderont au SI encore plus de disponibilité, de scalabilité et de richesse que les applications mobiles et les portails web. Nous sommes convaincus qu’il faut être préparé à ces nouveaux enjeux. Notre meilleure chance réside dans les opportunités liées aux nouvelles technologies qui les accompagnent. Les plateformes cloud, et les plateformes serverless dans une forme plus avancée, sont ainsi à nos yeux indissociables des objets connectés et des assistants virtuels. Elles sont, en effet, un remarquable atout pour répondre aux nouveaux enjeux qui leur sont associés.
Ce premier article de notre série consacrée au serverless analysera les principaux enjeux des objets connectés. Puis il abordera les promesses liées aux plateformes Serverless. Enfin il finira par s’interroger sur les écueils à éviter. Les solutions à ces questions seront l’objet des prochains articles de cette série.
Les quatre besoins des objets connectés et des assistants virtuels
Commençons par les objets connectés. À travers 3 articles nous avons mis en lumière, il y a quelque temps déjà, l'architecture particulière liée à ces objets.
Le premier besoin est l'interconnexion des objets connectés aux applications.
Dans le cas d'objets très nombreux (par exemple les conteneurs), un réseau spécialisé permettra un device (matériel) moins coûteux et moins gourmand en énergie. Des sociétés comme SigFox se sont spécialisées dans l’installation de ce type de réseau. Construire des antennes, tirer des câbles, est le coeur de métier d’une entreprise de télécoms. Aucune autre entreprise n’a d’intérêt à entreprendre de tels investissements. Il faut donc connecter les objets connectés et les applications associées à ce nouveau type de réseau.
De plus d’autres contraintes sont propres aux objets connectés. Lorsque la connexion est interrompue (imaginez un conteneur traversant une tempête en mer de Chine) les applications doivent pouvoir accéder aux données de ce conteneur hors-ligne.
Contrainte de sécurité ensuite (imaginez qu’un pirate ait physiquement ouvert le boitier du conteneur et envoie des informations erronées à sa place) les objets corrompus doivent pouvoir être exclus du réseau à tout moment.
Dans le cas des assistants vocaux, une forte barrière d'entrée est liée aux technologies de reconnaissance vocale et conversationnelle. Watson d'IBM a remporté le jeu Jeopoardy en 2011, il y a 7 ans déjà. Depuis, les géants de l'informatique comme Google, Amazon ainsi que Microsoft et IBM ont assurément investi pour aboutir aux assistants vocaux que nous connaissons : Google Home, Alexa, Cortana et Watson. Quelle entreprise se risquerait à ré-écrire un algorithme de reconnaissance du langage naturel en espérant faire mieux et plus vite que Google et Amazon ? Là encore, le besoin d’interconnexion des applications d’assistants virtuels aux plateformes proposant cette reconnaissance du langage naturel sous forme de service est important.
Les nouvelles applications IoT ou applications pour assistants virtuels ont donc besoin d'être connectées à des plateformes qui prendront en charge une complexité que le SI existant n'est pas capable de gérer. Cette connectivité ne pourra plus se limiter à un simple réseau. Il est nécessaire d'interagir avec des services complexes comme le provisionning/déprovisionning - ajout de nouveaux objets dans la flotte, ou suppression de la flotte d’objets détruits ou corrompus. Les API entre les objets et les applications sont complexes, à l’image des interactions entre un être humain et un assistant virtuel.
Les applications IoT et les assistants virtuels sont-ils les seuls concernés ? Non, car des plateformes hébergées existent dans d’autres domaines banalisés (aujourd’hui l’encodage et la publication de vidéos). Et là-encore, l’interconnexion joue un rôle majeur.
Le second besoin concerne les données. Dans cet article mes collègues introduisent le besoin de 3 types de stockage pour les données :
- froid : pour l'analyse big data des immenses volumes de données collectées
- tiède : pour les informations susceptibles d'être modifiées. Par exemple, dans le cas d'un conteneur connecté, il s’agit de l’état de l’objet durant sa période de transport. Son état changeant de « embarqué », « en voyage », « débarqué », « livré »…
- chaud : pour traiter les évènements dans un horizon de temps rapproché comme des évènements techniques, par exemple les valeurs successives d’une sonde de température avant d’identifier un dépassement de seuil

Le stockage chaud est quasi systématiquement embarqué dans la plateforme, voire directement dans l’objet du fait du grand volume de données qu'il faudrait faire transiter et des besoins en faible latence. Celui-ci est le plus souvent masqué derrière une API. Dans le cas des objets connectés les plateformes présentent une API vers un shadow d’appareil et non pas vers l’appareil lui-même pour masquer la complexité d’interconnexion par exemple.
Le stockage froid commence à être bien maîtrisé ces dernières années avec les outils Big Data. Mais là encore, la mise en place d'un cluster Hadoop ou l'industrialisation d'un code TensorFlow nécessite un investissement non négligeable. L'utilisation d'une plateforme mutualisée, disponible sous forme de service, peut être un atout considérable.
Enfin, le stockage tiède est le plus couplé au besoin métier. Les bases de données relationnelles qui ont été maîtresses de ce domaine pendant des années ont désormais besoin d’échanges plus nombreux et plus fréquents avec les stockages chauds et froids. L'utilisation d'un serveur de bases de données existant au sein de son SI n'est probablement pas la meilleure solution pour répondre à ce besoin. Un Backend as a-Service de stockage offre plus d’opportunités d’intégration avec les API du stockage chaud et les plateformes de type BigData d’une même plateforme.
Le troisième besoin concerne les solutions applicatives elles-mêmes qui devront être connectées aux objets, et traiter ces données.
Celles-ci devront à la fois être scalables et prendre des décisions en temps réel de façon automatique et autonome.
Elles devront être transactionnelles au sens d'un engagement pris lors du dialogue entre l’utilisateur et l’objet opérateur. Par exemple lorsque le cadenas d'un vélo connecté est ouvert par l’application sous-jacente, c'est une partie du capital social de l'entreprise qui est confié à l’utilisateur de l’application. La notion de transaction prend ici un sens quasi aussi aigu que dans un distributeur automatique de billets - souvent nommé par son trigramme anglophone ATM - Automatic Teller Machine - en informatique.
Ces solutions sont interconnectées comme nous l'avons vu avec la plateforme mais également avec le Système d'Information de l'entreprise et l'existant. Il s'agit de leur quatrième besoin : faire le pont entre deux mondes : celui de l'informatique pervasive (omniprésente en français) et l'informatique traditionnelle. Je nommerais cette-dernière informatique interactive ou transactionnelle (au sens de l’ancien terme Transactional Processing).
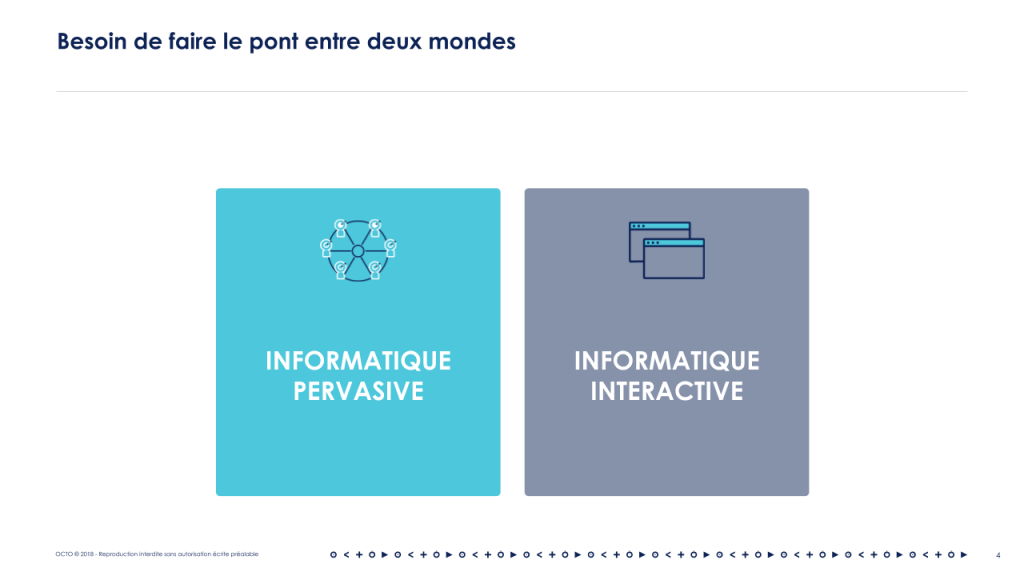
L'utilisation d'une application comme Mobike diffère fondamentalement de l'usage d'un site web ou d'une application mobile. Les interactions sont très fréquentes et très brèves dans l’informatique pervasive. L'émergence du Bluetooth Low Energy et de son intégration aux smartphones peuvent laisser entrevoir une interaction avec l'objet sans même ouvrir d'application. Cela renforcera cet aspect pervasif.
Ces applications présentent également des interfaces d'administration, par exemple pour gérer les objets ou affiner les réponses fournies par un chatbot. Dans ce cas les interactions homme-machine sont beaucoup plus traditionnelles : c’est ce que j’appelle l’informatique interactive.
D'un côté ces applications pourront recevoir plusieurs dizaines de milliers d'évènements par jour mais chacun interaction étant très brève. Mais chacun d'eux ne durera que quelques millisecondes. Et de l’autre, leurs autres écrans d'administration nécessiteront une interaction très classique d'un utilisateur. Celui-ci enchaînera pendant plusieurs minutes des requêtes HTTP de 100 millisecondes à quelques secondes.
Nous pensons que le phénomène va s'accentuer dans les années à venir. Que vous déployiez vous-même des objets connectés, ou que vous soyez alimentés par rebond - par exemple en étant présent sur une plateforme d'assistant vocal - votre Système d'Information va être confronté à ces quatre nouveaux types de besoins : interconnexion, stockage, architecture applicative et tolérance à plusieurs types d’informatiques.
Les architectures Cloud et Serverless : un atout dont il faut tirer parti
En synthétisant ces enjeux : ces nouvelles applications devront être fortement interconnectées à des plateformes qui leur fourniront leurs services de base. Elles auront besoin de services de stockage à la fois traditionnels et big data. Elles devront être autonomes, transactionnelles et scalables. Elles devront enfin faire cohabiter informatique pervasive et informatique interactive en lien avec l'existant.
En informatique pervasive, si 50 évènements sont traités chaque minute mais que chacun ne dure que quelques secondes, cela représente 72 000 évènements par jour mais moins de 10 % d'utilisation d’un serveur à 32 cores. A contrario, si les 72 000 évènements arrivent sur un pic de 5 minutes cela représente 240 transactions par seconde qui peuvent saturer un serveur. Avec ce type de besoin, le dimensionnement de la capacité informatique par le pic d'utilisation devient rapidement intenable.
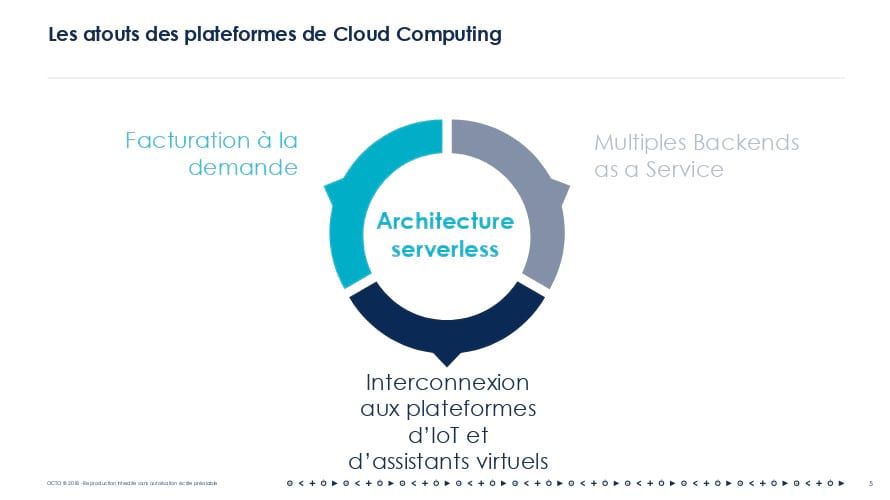
Les architectures serverless répondent exactement au besoin de l'informatique pervasive. Cette architecture peut se passer d'un serveur toujours en fonctionnement, en se reposant sur des Backend as a Service ou "BaaS" et des plateformes de type Functions As a Service ou "FaaS". Il est possible de fournir simplement du code à la plateforme. Le provisioning des instances, la scalabilité, la haute disponibilité sont gérés de façon transparente par la plateforme. La facturation ne se fait plus au temps d'utilisation des instances mais au nombre d'évènements.
Le stockage des données suit également cette évolution : AWS Aurora est ainsi désormais disponible dans une facturation serverless (après S3 et DynamoDB)
Ces Backend as a Service sont également une très bonne réponse au besoin de gestion efficace des données. 3 systèmes technologiques différents sont possibles pour répondre à l'ensemble de ces besoins :
- un stockage comme Hadoop pour les données froides afin de tirer profit d'un profond historique de données
- un stockage hautement dynamique pour les données tièdes comme un stockage SQL ou NoSQL
- un stockage intégré à la plateforme ou aux objets eux-même pour stocker les évènements récents et masquer par la même occasion les interruptions de transmission.
Chacune de ces technologies peut être complexe à installer et à opérer. Fournir ces technologies sous forme de Backend As A Service est un atout primordial pour une bonne gestion des données.
Le premier besoin d'interconnexion forte entre les plateformes IoT et les applications font enfin des plateformes de cloud computing des localisations privilégiées pour ces nouvelles applications.
Les fournisseurs de cloud computing, et en particulier AWS que nous allons utiliser comme exemple dans les articles suivants, ne s'y sont pas trompés. Ils proposent ainsi :
- une plateforme IoT (8 services dans AWS IoT)
- une plateforme pour les assistants vocaux (AWS Alexa)
- une plateforme pour le traitement vidéo (6 services dans AWS Media Services, ainsi que AWS Media Tailor, et Video Rekognition)
- un plateforme d'intelligence artificielle (un service d’assistant virtuel, 2 services visuels et 4 services linguistiques).
À côté de ces plateformes, on trouvera des Backends de données as a Service en mode facturation à l'évènement (AWS S3 pour le stockage non structuré, DynamoDB pour le stockage NoSQL, Aurora Serverless pour le stockage relationnel), d'autres Backend de données as a Service en facturation plus traditionnelle pour le Big Data (Elastic MapReduce comme Hadoop-As-A-Service et Redshift comme service décisionnel) ainsi qu'un service de computing Serverless (Lambda comme Fonction as a Service).
Ces plateformes serverless sont donc les plateformes privilégiées pour les applications d’objets connectés et d’assistants virtuels de demain. Elles présentent de nombreuses opportunités qui vont vous permettre de répondre à ces enjeux mais également de créer de nouveaux challenges pour les développeurs.
La conception Cloud Native : un must have pour bien débuter
Pour tirer les pleins bénéfices du cloud, la conception des applications doit être adaptée comme nous le montrions dans cet article sur les applications Cloud Ready/Cloud Native.
Nous savons également que les promesses d'une plateforme - aussi vaste soit-elle - nous amènent très vite vers ce que Thoughworks appelle dans son dernier ouvrage Evolutionary Architecture le "Last 10 % trap" - “[traduction] D’un point de vue métier, l’outil ne peut tout simplement pas supporter le processus optimal ; c’est un effet de bord du Last 10% Trap.” (Neal Ford, Rebecca Parsons, Patrick Kua, Building Evolutionary Architectures: Support Constant Change, O’Reilly Media, Septembre 2017). Si nous nous reposons les yeux fermés sur une plateforme, nous nous retrouverons enfermés et nous n'arriverons jamais à gérer la complexité induite par ces nouveaux types d'application.
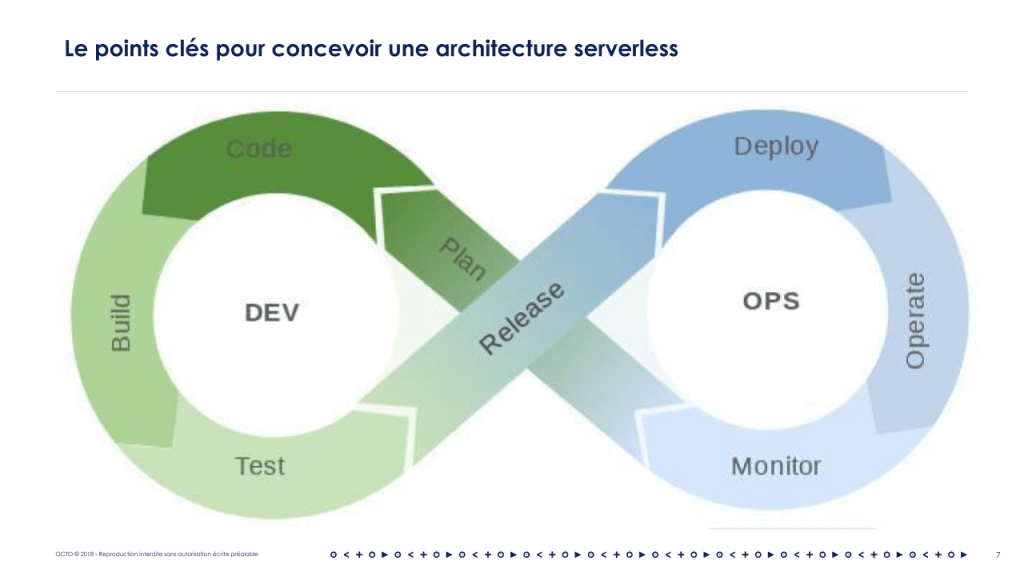
Afin de bien concevoir une application Serverless, nous devons réfléchir aux éléments centraux à prendre en compte pour garder la main sur leur architecture : - la conception - le mode de programmation - le debuggage - l'intégration - le déploiement - l'observabilité
Au niveau de la conception tout d'abord, l'approche microservice semble naturelle aujourd'hui. Les Fonctions as a Service incitent à partitionner l'application en une multitude de fonctions qui se coordonnent entre elles. Ce découpage favorise la modularité et le choix des technologies les plus appropriées. Mais le mieux est souvent l'ennemi du bien. Prenons l'exemple d'une modularité à l'extrême avec une fonction par ressource et par verbe HTTP. Une petite application avec 6 ressources et n'utilisant que 2 verbes par ressource nécessitera pas moins de 12 fonctions. Cela va nécessiter 12 processus de builds indépendants, 12 configurations d'Infra as Code donc beaucoup de complexité et de temps de déploiement. N'y a-t-il pas une meilleure façon de faire ?
La programmation fonctionnelle et la programmation évènementielle mises en avant par les plateformes de Functions As a Service répondent très bien à l'enjeu de l'informatique pervasive. À l'inverse, elles présentent un challenge très important pour réaliser des applications plus classiques. En effet, le temps de démarrage d'une Fonction as a Service peut atteindre quelques secondes lors du premier appel.
Certaines propositions émergent comme l'architecture en service block. Cette architecture ré-introduit une instance de type microservice pour gérer l’interaction avec l’utilisateur (ce que nous avons nommé informatique interactive). Là encore, n'y a-t-il pas une meilleure façon de faire ?
Le debuggage ensuite. Lorsqu'on développe du code destiné à être déployé sur des Plateformes as a Service, son exécution est dépendante de cette plateforme.
Celle-ci devra à la fois faire office d'environnement de développement, de qualification et de production. Gérer de multiples environnements dans un même service est complexe si le service n’offre pas de support aux environnements multiples.
La boucle de feedback est longue du fait du temps de déploiement de l'application.
La plateforme fournit des logs à l’exécution, mais ceux-ci peuvent s'avérer trop limités dans un besoin de développement. L'usage d'un outil de debuggage devient indispensable. Certaines plateformes permettent d'exécuter leur runtime dans un conteneur docker sur le poste développeur mais au prix de certaines limitations quant aux services managés testés.
A l'inverse des frameworks applicatifs permettent de se rendre indépendant de la plateforme. Quelle solution doit-on privilégier ?
L'intégration des différents services joue un rôle crucial en miroir des choix de conception. Faut-il privilégier des fonctions extrêmement simples en confiant beaucoup de responsabilités à des plateformes d'intégration : une API Gateway ou une plateforme de type Kubernetes (si on utilise un FaaS comme RIFF) ? En d'autres termes, faut-il privilégier une approche très orientée Service Mesh ou redonner un peu de responsabilité à l'application ?
Dans une plateforme de Function et de Backend as a Service, l'infrastructure est prise en charge par la plateforme. Est-ce que l’Infrastructure As Code ne devient pas superflue ? Nos premières expériences montrent qu'avec l'augmentation du nombre de fonctions, l'organisation du déploiement devient au contraire un enjeu majeur pour gérer la complexité liée aux grands nombres de services.
L'observabilité enfin est un enjeu majeur, car les infrastructures sont on ne peut plus volatiles. Le meilleur moyen pour diagnostiquer un problème sur une application Serverless repose sur l'observabilité. Or, il n'y a plus aucun serveur sur lequel stocker ses logs ni même se connecter. Tout est à réinventer.
Chacune de ces questions pourrait nécessiter un article à part entière. Celui-ci étant déjà assez conséquent nous avons préféré vous proposer une série d'articles pour illustrer ces différents points à travers des retours d'expérience, et des mises en oeuvre de ce type d'application.