Le chemin vers l'omnicanal
Si votre système d’information n’est pas tombé dedans quand il était petit, faire de l’omnicanal est souvent un parcours semé d’embûches, et de promesses d’éditeurs.
Cet article se propose de parler des sujets de fond liés à ce type de transformations.
Il est aussi l’occasion d’aborder l’histoire des SI pour comprendre comment on est arrivé à la situation actuelle.
C’est quoi l’omnicanal ?
Un canal est un point d’accès spécifique à un système. Un SI peut par exemple avoir un canal web client, un canal application mobile client, un backoffice de gestion, des accès pour les partenaires…
Un SI omnicanal est un SI qui permet aux différentes personnes qui l’utilisent de passer de manière fluide d’un canal de distribution à un autre.
L’exemple type est de commencer à faire une demande de prêt immobilier sur son smartphone, de la continuer sur son ordinateur portable une fois chez soi, puis éventuellement de terminer le dossier en se rendant en agence. Cela ne signifie pas utiliser le même outil dans les trois cas, mais bien d’avoir des outils spécifiques dont l’ergonomie est adaptée à chaque utilisation, et de pouvoir passer de l’un à l’autre "sans couture" (seamless), c’est-à-dire sans avoir à refaire une opération déjà faite comme une saisie de données.
En plus des avantages pour les utilisateur·rice·s, nous allons voir que l’omnicanalité a également des avantages pour l’IT.
À l’inverse, un SI multicanal fournit les mêmes fonctionnalités sur plusieurs canaux mais de manière silotée, et la bascule d’un canal à l’autre est donc visible de la part des personnes ou des systèmes qui l’utilisent.
Dans ce cas une personne qui commence une demande de prêt immobilier chez elle et qui se rend en agence devra reprendre le dossier depuis le début car le backoffice de l’agence n’a pas accès à la demande faite sur le canal web client.
Pourquoi c’est compliqué ?
Le chantier de transformation omnicanal comporte plusieurs axes, liés aux différentes contraintes des systèmes actuels.
Pour comprendre la situation, le mieux est de revenir en arrière et de dérouler l’historique du SI.
Nous allons prendre ici un exemple typique du domaine bancaire tel qu’on le retrouve chez de nombreux acteurs historiques.
Les années 80 : au commencement étaient le mainframe et le backoffice
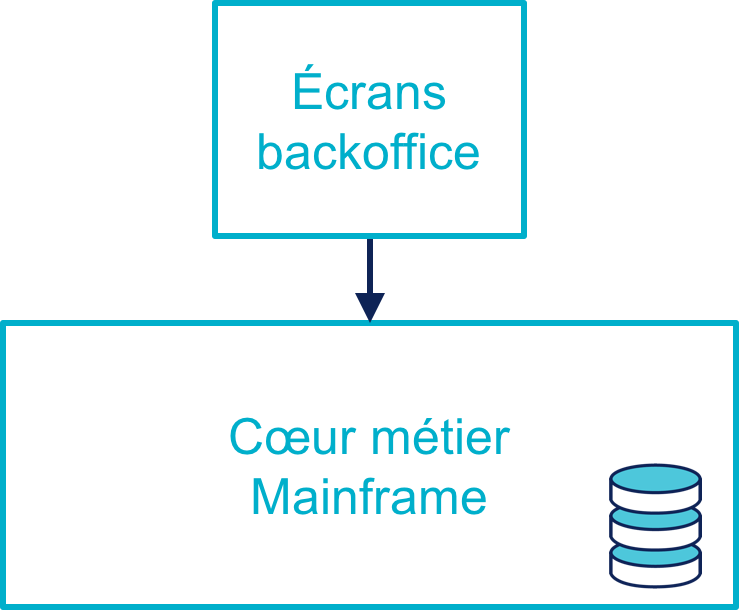
Les premières briques du SI se sont construites dans les années 80 sur mainframe, développées en COBOL ou équivalent. Ces systèmes historiques peuvent être des développements "maison", des progiciels, ou un mélange des deux.
Les écrans de backoffice permettant d’y accéder sont conçus pour les employé·e·s de l’entreprise et leurs sont réservés.
Les workflows de traitement et les fonctionnalités exposées sont directement calqués sur les écrans et chaque étape du process est stockée dans la base de données d’une manière structurée. Il ne s’agit pas d’un modèle MVC : les définitions des écrans sont imbriquées avec les traitements métiers.
Les bureaux étant fermés la nuit et le week-end, les appels interactifs sont désactivés pendant ces périodes, ce qui permet d’exécuter des traitements de masse ou batch. Ces traitements bénéficient ainsi de l’intégralité de la puissance de calcul, et le fait d’être les seuls à s’exécuter leur permet de simplifier leur design car ils peuvent ainsi monopoliser des ressources comme des tables de bases de données sans se soucier du reste du monde.
Cela permet aussi de simplifier les règles métier, par exemple les calculs comptables sont beaucoup plus simples lorsqu’aucune autre opération n’est effectuée pendant qu’ils s’exécutent.
Les années 2000 : l’arrivée du web, le bicanal
Avec l’arrivée du web, il est temps d’ouvrir un site de banque en ligne.
Cela signifie donner accès à des fonctionnalités du mainframe, mais d’une manière différente de celle du backoffice :
- les écrans doivent être adaptés pour être utilisables par des non-employé·e·s, certains workflows comportent donc plus d’étapes ;
- certaines options nécessitant la validation d’un·e employé·e empêcheront d’aller jusqu’au bout du traitement à partir du site, cela nécessitera des opérations de backoffice spécifiques.
Le système mainframe historique est vital pour l’entreprise et la maîtrise qu’ell en a n’est pas toujours satisfaisante : ce patrimoine commence à dater et la connaissance s’est donc perdue, il comporte rarement des test automatisés et avec une documentation souvent lacunaire.
La stratégie choisie est donc souvent de limiter au maximum l’ampleur des modifications sur cette partie du système pour limiter les risques.
L’approche choisie alors consiste à exposer les workflows existant autant que possible - c’est-à-dire ceux du backoffice - principalement sous formes d’API synchrones, et à développer le site web au-dessus de ces API, alors même que les workflows ne sont pas les mêmes.
Les contrats de ces APIs sont donc assez proches des écrans mainframe pour limiter l’effort à fournir. Il ne s’agit bien entendu pas d’API REST, mais généralement de messages MQ ou d’appels CTG.
Lorsque les deux workflows ne correspondent pas, on aboutit à ce type de situation :
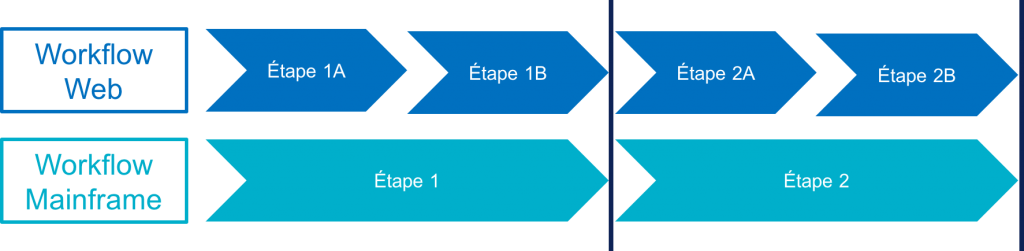
Il est dans ce cas impossible de stocker les résultats des étapes 1A ou 2A dans le mainframe. Ils seront donc stockés dans le backend du site web dans une base de données séparée. Cela signifie aussi qu’il faudra dupliquer les contrôles de saisie de ces étapes dans la partie web, pour éviter d’avoir à revenir en arrière dans les écrans du site web.
Suivant les étapes, les données sont donc stockées soit dans le système cœur, soit de manière intermédiaire dans le sous-système du site web.

En fonction des situations, les points de "rencontre" des workflows sont plus ou moins nombreux. Le cas extrême est celui où il existe un seul point de synchronisation : la dernière étape du workflow. Dans cette situation, le site web doit stocker toutes les données intermédiaires, et recoder tous les contrôles de saisie.

Dans ce cas, les données dans la base du site web qui n’ont pas été déversées dans la base du mainframe ne sont ni visibles depuis le backoffice ni des autres systèmes qui exploitent cette base.
Par exemple, si vous commencez à souscrire un prêt immobilier sur le site web sans terminer la procédure et que vous vous rendez dans votre agence bancaire, il faudra refaire tout ou partie des opérations.
Par ailleurs, les opérations de backoffice spécifiques au site web ainsi que les besoins de support client nécessitent de développer des écrans spécifiques branchés sur le même backend.
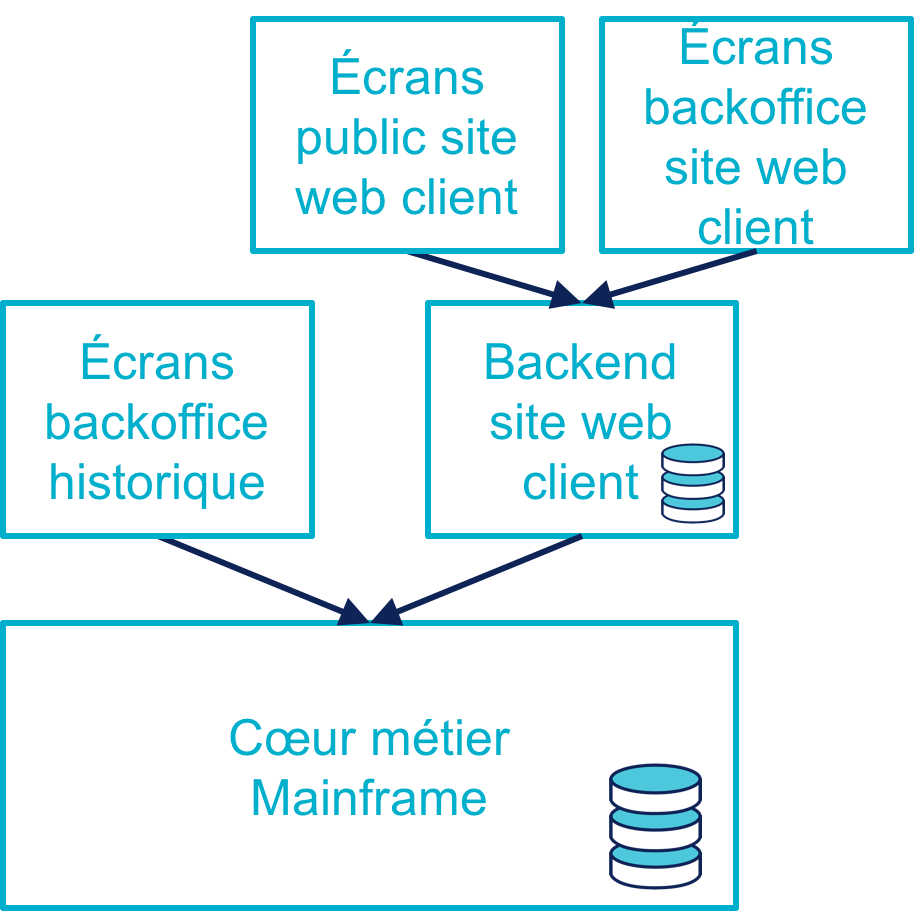
L’inaccessibilité du cœur système historique pendant la nuit pose aussi problème : il est inconcevable de faire de même pour un site web destiné au grand public.
Il existe de nombreuses manières d’améliorer cette situation, l’approche souvent rencontrée consiste à :
- effectuer une copie de certaines données avant de couper le système mainframe, et s’en servir comme d’un cache en lecture seule accessible pendant la nuit, le cache sera désactivé lorsque les traitements de masse sont terminés ;
- ne pas exécuter les opérations qui nécessitent des écritures mais les enregistrer sous forme de demandes d’exécutions dans le backend du site web, et réaliser réellement les traitements le jour suivant à l’ouverture du mainframe.
Cela rend le SI plus difficile à observer car les données sont distribuées entre les deux sous-systèmes.
Bien entendu, même si la réutilisation de fonctionnalités existantes est privilégiée, certains besoins du site web nécessitent de développer des APIs spécifiques dans le cœur métier.
Aujourd’hui : le mobile et les partenaires
L’arrivée du mobile pourrait signifier la mise en place d’une tricanalité. Mais les besoins mobiles sont souvent suffisamment proches des besoins web pour qu’ils s’appuient sur les mêmes systèmes. Dans quelques situations, il peut être nécessaire de stocker des données intermédiaires sur les terminaux, mais il ne s’agit pas d’un vrai troisième canal.
Les écrans de backoffice ont souvent été remplacés par des technologies web. Mais pour limiter les impacts sur le mainframe, on conservera souvent les mêmes workflows, le nouveau backoffice n’aura donc pas à stocker de données.
De même, le site web public a pu être refondu, mais toujours en subissant les contraintes de l’existant.
En revanche, la banque a noué des partenariats. Ces partenaires peuvent par exemple vendre des prêts de la banque en marque blanche quand vous achetez un de leur produits.
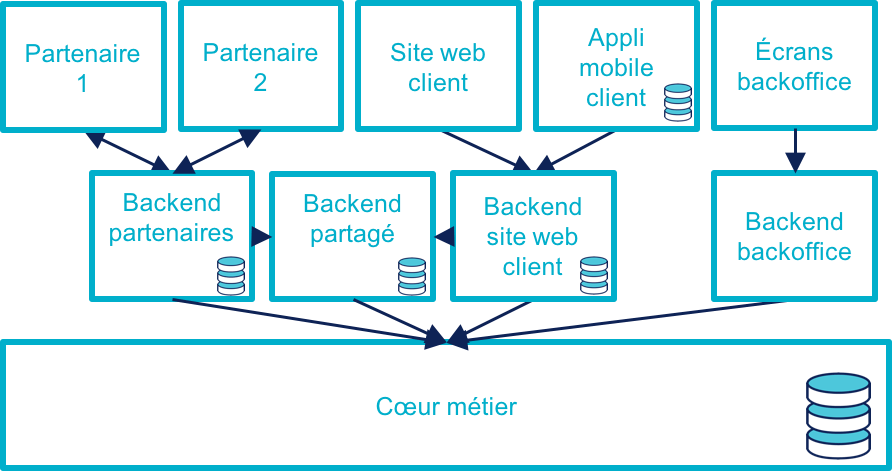
Les process nécessaires aux partenaires sont aussi différents du process historique que du process web, le système devient donc souvent tricanal. Prenons le cas où l’intégration se fait via un backend spécifique.
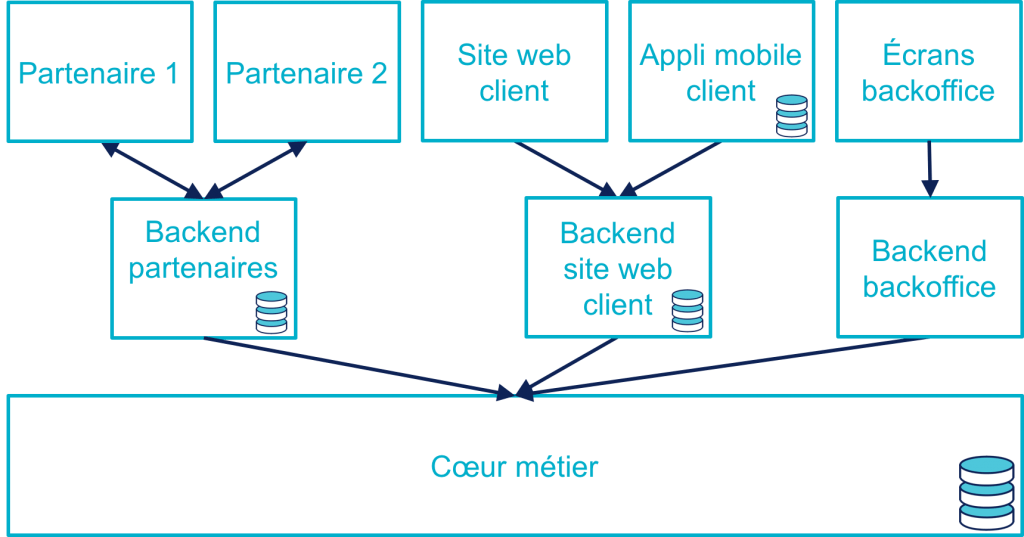
Pour rester lisible, le schéma ne contient pas les backoffice dédiés aux canaux web et partenaires mais ils existent bel et bien, une personne du support peut donc avoir à jongler avec trois backoffices différents.
Le canal partenaire ne pose pas le même problème que le canal web. En effet, un client qui commence à souscrire un prêt en marque blanche en achetant un bien voudra rarement conclure la transaction dans votre agence. En revanche, la multiplication des canaux rend la maintenance du système plus complexe quand on veut modifier un des workflows centraux qui sont exposés aux autres canaux ou changer une des règles de gestion dupliquée à plusieurs endroits.
Certains besoins des partenaires se rapprochent de ceux du site web client, il arrive donc qu’une partie du code soit partagée entre les deux. Cela évite de développer plusieurs fois les mêmes choses mais rend le système encore plus difficile à observer.
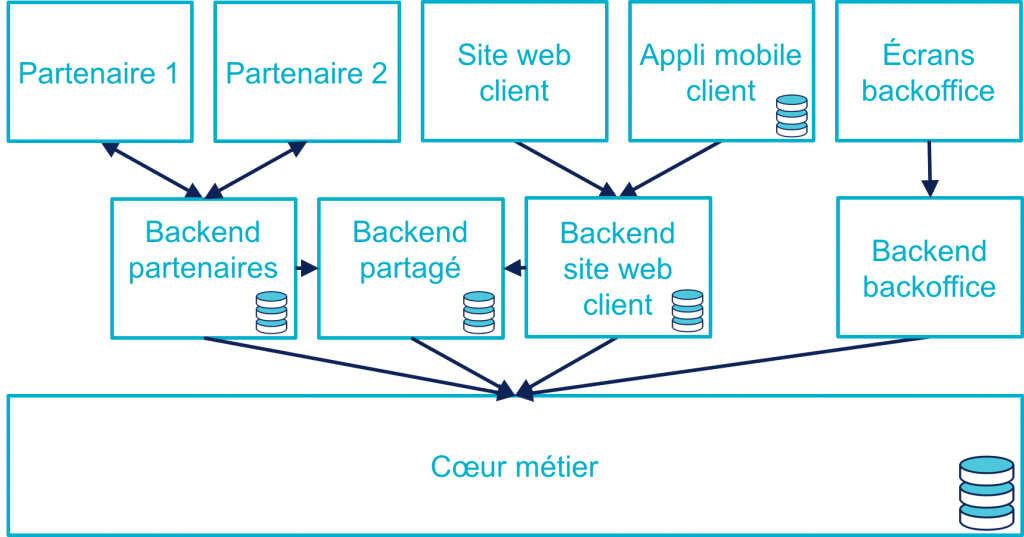
En résumé : les problèmes du multicanal
Le multicanal pose donc les problèmes suivants :
- mauvaise expérience utilisateur·rice·s lors du passage d’un canal à l’autre ;
- duplication de code entre les canaux ;
- données partiellement dupliquées entre les canaux ;
- limites dans la capacité à créer des parcours très différents du parcours historique ;
- difficulté de mettre en œuvre des évolutions cross-canaux du fait de la duplication ;
- système difficile à observer.
Que faut-il pour avoir un SI omnicanal ?
Les problèmes causés par le multicanal et les limites des SI correspondants nous donnent les informations nécessaires pour dresser le plan d’un SI omnicanal.
Avant de rentrer dans le détail, il faut préciser qu’un système omnicanal ne signifie pas un système unique de haut en bas pour tous les canaux mais un système cœur permettant de répondre aux besoins de l’omnicanalité sur lequel viendront se brancher les différents canaux.
La différence avec un système multicanal est la capacité de passer d’un canal à l’autre, pas le fait d’avoir un système unique.
Ainsi vous n’exposerez pas forcément les mêmes services ou les mêmes technologies pour votre application mobiles et pour vos partenaires. Vous aurez un système cœur sur lequel viendront se greffer votre canal backoffice, votre canal public, votre canal partenaire…
Des processus métier indépendants des canaux
Les workflows étant différent d’un canal à l’autre, l’omnicanalité nécessite de concevoir des processus métier qui soient adaptables aux différents canaux.
Cela signifie qu’il ne faut pas penser son processus en termes d’étapes qui ont la granularité d’un écran mais en termes de macro-étapes avec une taille plus importante, ce qui donnera à chaque canal les marges de manœuvres dont il a besoin.
Par exemple, souscrire un crédit peut, en le simplifiant à l’extrême, se décomposer en trois macro-étapes :
- renseigner des informations personnelles et faire des simulations de crédit jusqu’à obtenir une offre satisfaisante ;
- valider une demande de crédit en saisissant des informations supplémentaires ;
- traiter la demande dans le backoffice pour la valider ou la rejeter.
Il s’agit d’un travail de conception métier. C’est souvent la partie la plus difficile du chantier car il s’agit d’un exercice dont on a peu l’habitude, et c’est donc une bonne première étape.
Un système de stockage
Les données doivent être stockées dans un système indépendant des canaux.
Comme les saisies d’informations peuvent se faire dans des ordres différents d’un canal à l’autre, on peut moins souvent s’appuyer sur des contraintes d’intégrité que dans un système monocanal.
Par exemple un·e client·e pourra peut-être créer un compte sans fournir immédiatement son nom ou son adresse.
Des règles métier de validation
Dans un système historique, les services métier étant adossés aux écrans, chacun comportait les règles métiers correspondantes permettant de valider les informations saisies dans le formulaire.
Dans un système omnicanal, ce n’est plus possible car chaque canal peut concevoir son parcours.
Cela signifie que les règles de validation seront sous deux formes :
- dans le système central, des règles de validation seront placées au niveau de chaque macro-étape ;
- les canaux doivent implémenter ces mêmes règles au niveau de chaque écran ou de chaque service exposé avec la granularité la plus fine possible pour être en mesure de remonter des erreurs au plus près de la saisie des données.
Cela nécessite de bien documenter les règles.
Des services facilement utilisables et composables
Ce sont les services synchrones et asynchrones sur lesquels seront construits les canaux.
En effet, composer des services pour de l’omnicanal signifie de bien maîtriser les dépendances entre les différents services pour donner des libertés aux différents canaux.
Ces services doivent aussi, autant que possible, être accessibles 24 heures sur 24. Cela va nécessiter, du point de vue de l’extérieur, que les traitements ensemblistes "de nuit" ne rendent plus le système inaccessible. Cela peut demander de réutiliser le même type de comportements que ceux qui étaient utilisés par les canaux, comme le fait d’enregistrer des demandes d’exécutions à traiter plus tard. La différence est que le comportement sera cohérent entre les différents canaux car réalisé dans la partie commune.
Les canaux
C’est la partie spécifique à chaque canal qui définit le workflow de ce canal et l’expose de la manière appropriée par des écrans ou des services.
L’objectif est que cette partie du SI ne stocke pas d’information. En effet, comme nous l’avons vu plus haut, toute information stockée au niveau d’un canal va créer un silotage. Ils ne font que s’appuyer sur les services de la couche cœur.
L’omnicanalité rend la conception des canaux plus difficiles car ils doivent prendre en compte le fait qu’un processus peut avoir été démarré dans un autre canal ayant un workflow différent.
Par exemple, certains des champs de saisie auront peut-être déjà être remplis et pas d’autres.
Il faut qu’il puisse déterminer comment effectuer la reprise du traitement dans de bonnes conditions.
Cela demande une conception rigoureuse ainsi qu’une bonne couverture de tests.
Faire vivre le système
La dernière pierre de l’omnicanal est la capacité à le faire vivre.
En effet, les canaux sont fortement couplés au système cœur, ils devront donc être modifiés de manière coordonnée.
Ce couplage est un effet direct de l’omnicanalité : c’est elle qui permet de passer d’un canal à l’autre. Le modèle de canaux découplés est celui du multicanal.
Votre organisation doit donc être adaptée à cette contrainte.
Comment y aller ?
Maintenant que nous savons en quoi devrait consister un système omnicanal, reste à étudier les trajectoires pour l’atteindre.
Nous allons commencer par un point sur la situation de départ puis donner quatre exemples de stratégie possibles. Il existe de multiples approches, celles qui sont mentionnées ici ont été choisies car elles mettent en lumières les contraintes qui s’appliquent.
Situation de départ
Le système multicanal comporte deux éléments qui ont de la valeur et sur lesquels il faut s’appuyer en le faisant évoluer vers l’omnicanal, et deux limites qu’il faudra supprimer :
À conserver :
- les règles de traitement métier ;
- les règles de validation de données.
Les deux représentent de la valeur même si elles sont adhérentes au étapes du workflow historique (par exemple les différents écrans du process de souscription originel).
À supprimer :
- le workflow unique formant l’assise du système historique
- les règles d’intégrité des données alignées avec le process historique
Stratégie 1 : commencer par acheter un BPM
C’est la solution que préconisent certains éditeurs.
Les BPM sont des outils permettant de définir des workflow métiers sous forme low-code, c’est-à-dire via de la configuration et/ou des designers graphiques. Ils permettent également de stocker l’état courant des différents workflows.
C’est une solution tentante car elle fournit un socle prêt à l’emploi pour une partie des besoins.
Deux points d’attention pour cette approche :
- comme avec tout progiciel, attention à ne pas oublier les bonnes pratiques de développement comme les tests automatisés : votre BPM embarquera du code, et qui dit code dit tests ;
- ne pensez pas qu’avoir choisi un BPM signifie que vous avez gagné, en effet nous avons vu que la partie la plus difficile du chantier est la conception des services sur lesquels va s’appuyer le BPM.
Il s’agit d’une utilisation très spécifique des outils de BPM, loin de la gestion des processus métiers qui est leur utilisation normale.
Stratégie 2 : repartir sur un nouveau système
C’est la solution la plus risquée, mais qui est parfois la moins mauvaise. Par exemple quand vous avez perdu la maîtrise de votre système historique, ou qu’il s’agit d’un progiciel qui n’est pas compatible avec l’omnicanal.
La solution n’est pas forcément de partir de zéro : il est possible de partir sur un progiciel plus récent, ou de racheter une entreprise disposant d’une solution déjà fonctionnelle.
Stratégie 3 : rendre le cœur métier historique omnicanal
Il s’agit d’attaquer le problème par le bas, c’est-à-dire par le cœur métier.
Cela peut être à l’occasion de l’ajout d’un nouveau canal, en profitant d’avoir des nouveaux besoins factuels, et un budget.
Il va s’agir de transformer le cœur, puis de faire maigrir les canaux existants en redescendant ce qui ne devrait pas s’y trouver, comme le stockage de données.
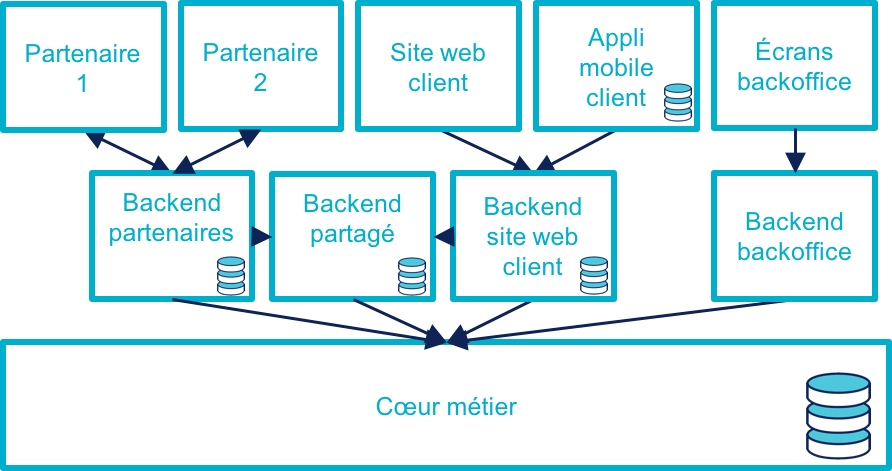
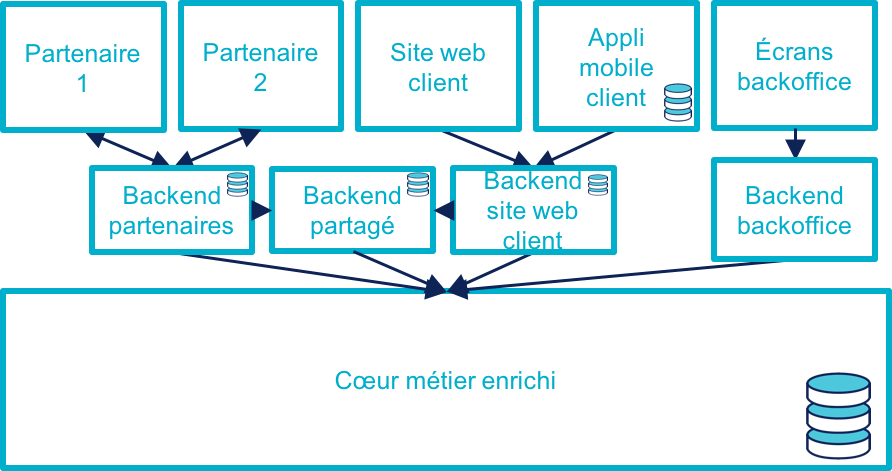
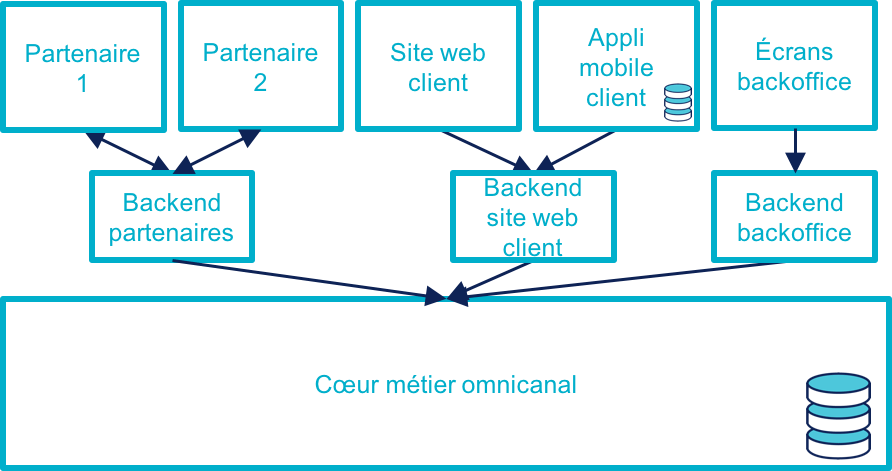
C’est probablement la meilleure solution si vous avez la maîtrise de votre existant et que vous souhaitez capitaliser dessus.
Deux points d’attention :
- faire évoluer de manière significative un outil demande un niveau de maîtrise plus important que le fait de le maintenir, la facilité à corriger des erreurs sur le cœur n’est pas un bon indicateur de votre capacité à le transformer ;
- ne pas introduire de régressions, par exemple en supprimant des comportements non documentés mais sur lesquels le code s’appuie.
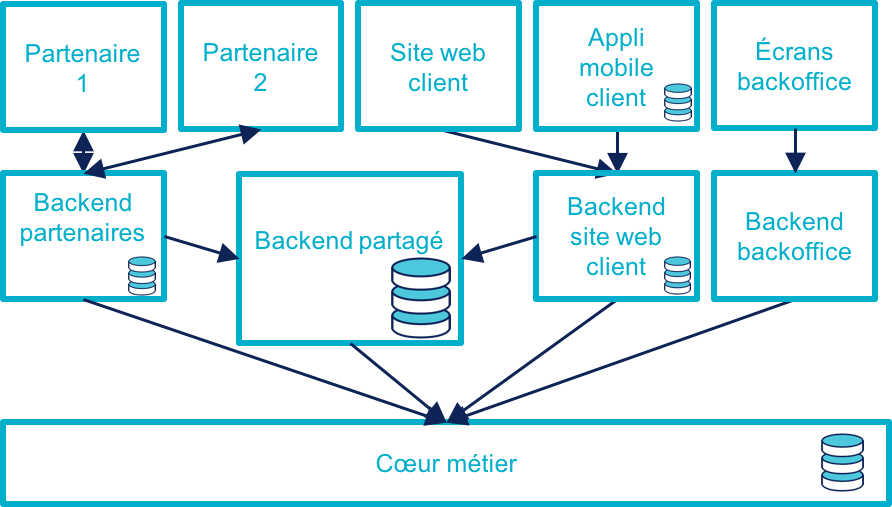
Stratégie 4 : ajouter une couche d’omnicanal au-dessus du cœur
Il s’agit de la voie intermédiaire : on s’appuie sur l’existant le temps de bâtir un remplacement.
Il s’agit de bâtir une surcouche omnicanale au-dessus du cœur. Plutôt que de partir de zéro, il est possible de partir d’un des canaux existants en le séparant entre une partie souche qui servira de base à la partie omnicanal et la partie exposition qui deviendra la nouvelle couche canal.
En enrichissant peu à peu de nouveau types de données en les remontant depuis le cœur historique et des fonctionnalités associées. Cette couche devra exposer les services réutilisables qui serviront de base aux différents canaux.
Pendant la construction, vous continuerez de subir les limitations du cœur existant, mais commencerez à bénéficier de certains avantages de l’omnicanalité, comme la transition plus facile d’un canal à l’autre.
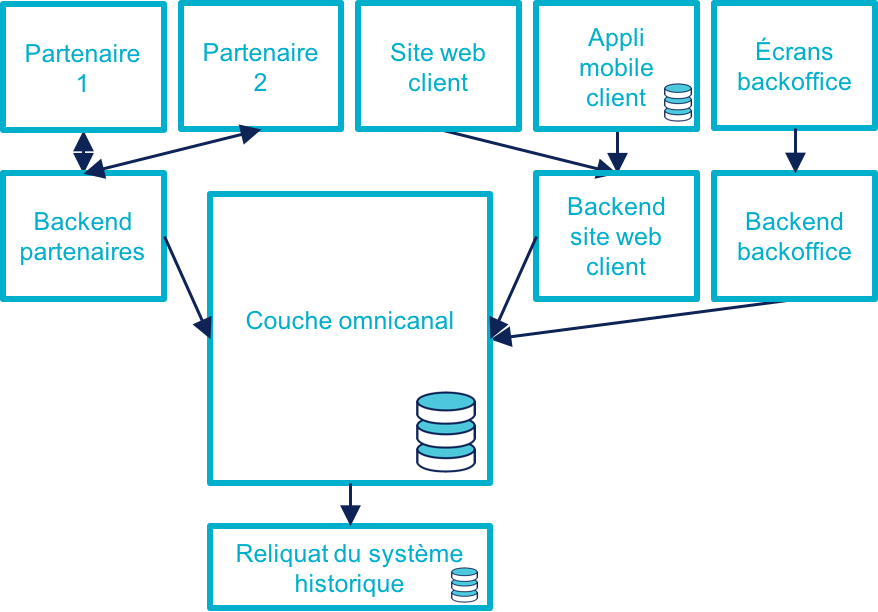
L’étape suivante consistera à dégonfler le système historique pour s’appuyer de plus en plus sur la nouvelle couche.
Cela va probablement demander des évolutions du système cœur. Cependant elles ne demanderont pas de transformations profondes, au contraire de la stratégie précédente.
En cible on pourra décomissionner totalement le système historique, ou conserver certains éléments comme les parties réglementaires pour lesquels la migration ne se justifie pas et qui n’imposent pas de contraintes sur le nouveau système.
Une des difficultés de cette stratégie est de bien choisir l’ordre dans lequel remonter les fonctionnalités pour bénéficier au plus vite des premiers avantages tout en limitant les risques.
Pour terminer
L’omnicanalisation d’un SI est un chantier risqué et de longue haleine. Mal conçu ou mal piloté, il peut être un enfer de plusieurs années qui aboutira à ajouter de nouvelles briques à votre système, sans atteindre aucun des buts fixés.
Il est autant lié à la DSI qu’au métier : il demande du travail à tous les deux, mais apportera aussi des avantages à chacun. Si l’un des deux acteurs veut se lancer sans la pleine coopération de l’autre, c’est l’échec presque assuré.
Même si ce changement peut permettre de réduire la dépendance aux systèmes historiques, y arriver va demander de comprendre comment ces systèmes fonctionnent, et de les modifier. Moins bien vous maîtrisez votre mainframe, plus il sera difficile de vous en passer.
Si un tel projet vous semble long et coûteux aujourd’hui, gardez à l’esprit que plus le temps passe et plus la situation va empirer.
Bonne chance à vous.