RAG avec LangChain : construire un chatbot documentaire (exemple OCTO)
En bref
Un RAG (Retrieval Augmented Generation) permet à un LLM de répondre à des questions en s'appuyant sur vos propres documents. Avec LangChain, il se construit en 3 composants : un loader (pour ingérer vos sources, ici Confluence), un vector store (pour indexer les contenus) et un retriever (pour retrouver les passages pertinents à la question posée).
“Je souhaiterais connaître la démarche pour accéder à mon comité d’entreprise"
Qui n'a jamais imaginé poser cette question à un agent conversationnel permettant de lui indiquer facilement la source d'information, plutôt que de chercher dans 10 documents ou de demander à 10 personnes différentes ? Bienvenue au pays des RAG.
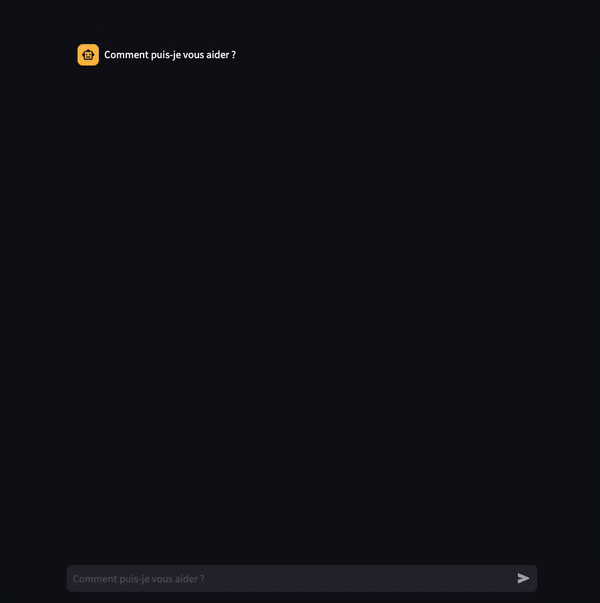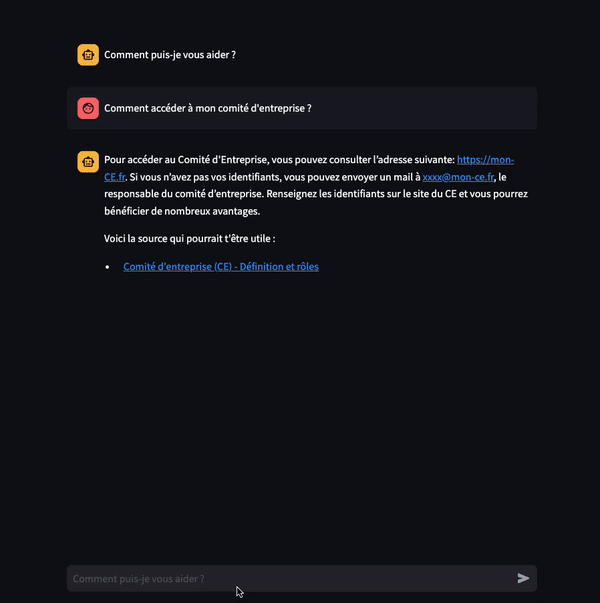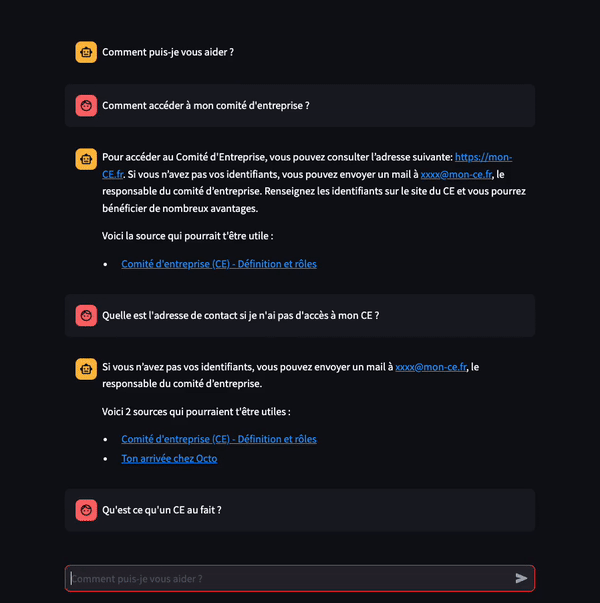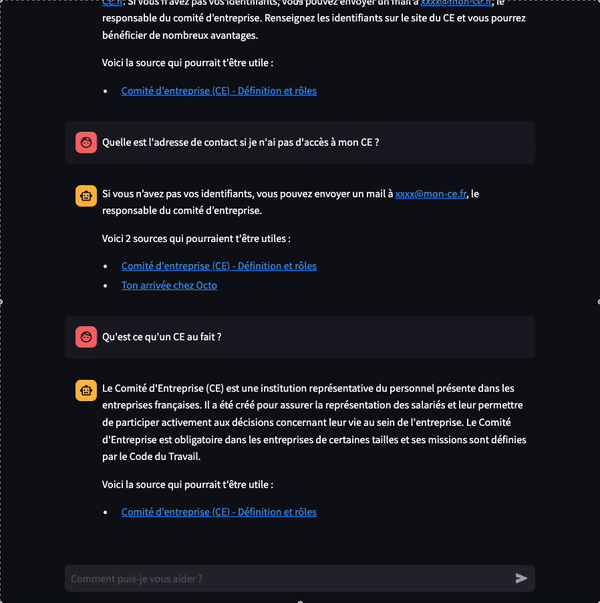
Figure 1: Exemples de questions posées à notre Chatbot
Le RAG, ou Retrieval Augmented Generation, nous permet d’utiliser la puissance d’un agent conversationnel en utilisant nos propres données.
Nous développerons à travers cet article les différentes étapes permettant de créer notre Chatbot interne Octo. Cet agent explore la base de documentation Confluence (utilisée par OCTO pour ses activités internes) afin de simplifier la recherche utilisateur et répondre aux questions courantes des employés. Le code détaillé dans cet article est accessible sur ce repository Git.
Comment exploiter un modèle de langage ?
Le 16 mars dernier, Sam Altman met en lumière un aspect important de l’exploitation des modèles de langues:
"The right way to think of the models that we create is a reasoning engine, not a fact database. They can also act as a fact database, but that's not really what's special about them – what we want them to do is something closer to the ability to reason, not to memorize."
Sam Altman - fondateur OpenAI Interview ABC - 16 Mars
Il propose d’utiliser un agent conversationnel comme un moteur de raisonnement et non pas comme une base de connaissances. Autrement dit, les modèle de langages ne sont pas une immense base de données à la connaissance infinie qui résout nos problèmes en piochant dans son puit de savoir.
Les modèles de langues sont initialement entraînés pour prédire le prochain mot d’une phrase. Grâce à des méthodes d’alignement (ici RLHF), la qualité des réponses de ces agents s’est grandement améliorée.
Cependant, ces modèles ont aussi tendance à halluciner ou apporter des réponses biaisées. Afin de remédier à ces problèmes et pour personnaliser la réponse d’un modèle de langue, plusieurs solutions ont récemment émergé. Parmi ces solutions, il existe le prompting, ou l’art d’adapter notre question afin d’orienter le modèle vers une réponse souhaitée.
Voici un exemple de prompt intéressant pour une problématique de Question Answering :

Dans cet exemple, le modèle de langue a pour objectif de répondre à une question selon le contexte qui lui est transmis.
Il existe aussi d’autres techniques de “prompting” pour résoudre des problèmes plus complexes tels que les Chain-of-Thought dont l’idée est d’introduire un raisonnement par étape. Comme nous allons le voir, ces étapes de “prompting” seront de plus en plus automatisées.
1. Comprendre l’architecture RAG :
Définition
Le RAG est une technique de traitement du langage naturel combinant la recherche d’informations dans une base documentaire et l’exploitation d’un moteur de langage. Il a pour objectif de répondre à des questions issues d’une documentation privée ou inconnue des moteurs de langages open ou closed-source.
Pourquoi utiliser l’approche RAG et ne pas donner toute ma base documentaire au modèle ?
Pour deux raisons :
- La première est la dégradation de la performance des réponses avec l’augmentation de la taille du contexte (pour plus d’informations, consulter ce papier)
- La seconde est simplement la limite de taille de contexte imposée par les modèles de langues.
À titre d’exemple, le modèle ChatGPT autorise une taille de contexte allant jusqu’à 32,768 tokens. Pour comparaison, le roman de Georges Orwell, 1984, a une taille de 89 000 tokens.
Il est donc impossible de fournir toute une documentation d’entreprise en contexte d’un modèle de langue. Pour comprendre ce qu'est un token, voici un exemple de découpage ou tokenisation selon Chat GPT:

Alors, comment choisir les documents à lui transmettre ?
Le RAG est constitué d’une suite d’étapes permettant d’établir cette sélection :
La création de chunks (la division du corpus de textes en sous-parties)
La création d’embeddings (la transformation de ces sous-parties en vecteurs de valeurs numériques)
La création d’une base de données vecteur (le stockage de ces valeurs numériques dans une base de données adaptée)
La recherche d’informations ou information retrieval (la recherche des chunks sémantiquement proches de la question posée)
Ces étapes sont requises pour mener à bien l’indexation de notre base documentaire.
Commençons par étudier comment stocker notre documentation pour la rendre exploitable :
Dans un premier temps, la base de données de l’entreprise est extraite (.pdf, .md, .txt, …) et divisée en sous-parties. Chaque sous-partie peut être de taille fixe ou variable selon le choix de découpage des documents. Des techniques d'overlap sont possible mais peuvent introduire des doublons lors du choix des chunks adéquats pour la réponse à une question posée.
Ensuite, ces sous-parties sont converties en embeddings, décrivant l’information sémantique qu’elles contiennent.
Enfin, ces embeddings sont stockés dans une base de données vecteur.
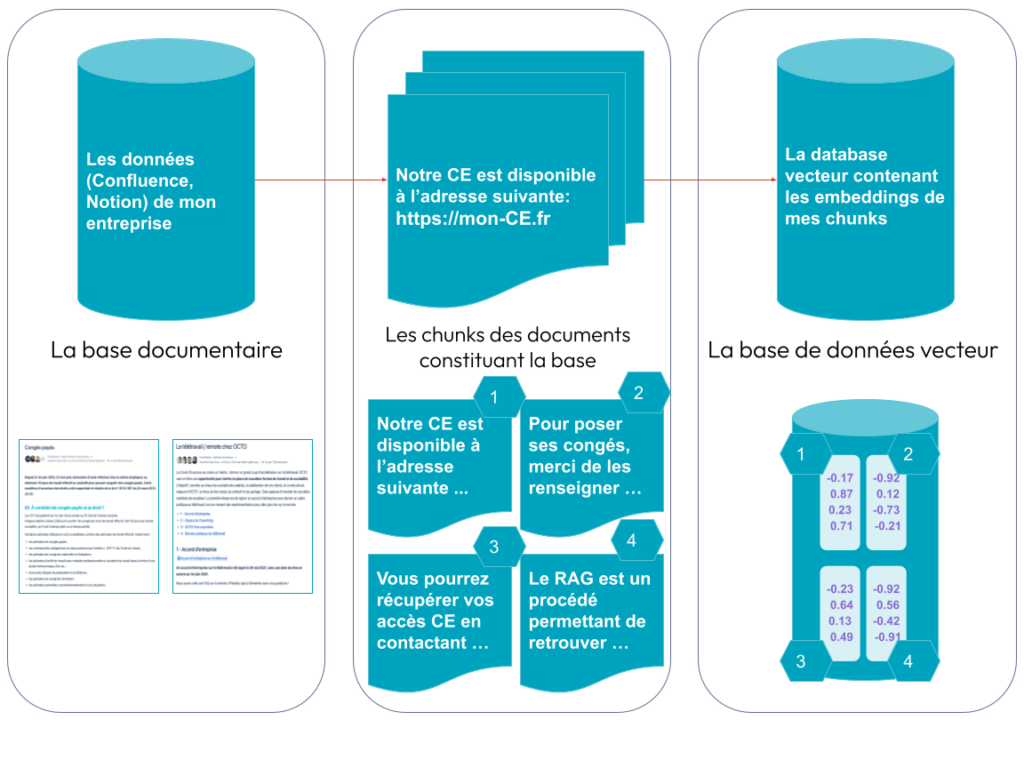
Figure 2: L’ingestion de la base de données de l’entreprise
Ensuite, intéressons-nous à la relation entre la base de données vecteurs et notre modèle de langue.
Une fois la base de données vecteur créée, notre documentation d’entreprise est exploitable. L’utilisateur peut alors poser une question:
Comment accéder à mon comité d’entreprise ?
Cette question est convertie en un vecteur contenant son embedding, représentant l’information sémantique de la question. À partir de l’embedding de la question, une recherche d’embedding similaire est faite dans la base de données vecteur. L’objectif de cette recherche est de retrouver les parties de documents en relation avec la question. De cette recherche, deux contenus ressortent :
- Notre CE est disponible à l’adresse suivante : https://mon-CE.fr
- Vous pourrez récupérer vos accès CE en contactant par mail: xxxx@mon-ce.fr
Ces contenus forment le contexte et seront ajoutés à notre prompt:
Le template de prompt:

Se complète avec le contexte et la question:

Ce prompt final est mis en entrée d’un modèle de langue, voici sa réponse :

Et voilà ! Nous venons d'ajuster la question que nous posons à notre modèle de langue pour que sa réponse soit personnalisée par rapport à nos données.
A titre de comparaison: imaginez que vous souhaitez connaître les destinations de vacances éco-responsables qui vous conviendront. Vous pouvez imaginer poser une question sur l'interface publique de Chat GPT en lui demandant quelles sont les stations balnéaires éco-responsables. Votre lieu de vie étant important pour obtenir une bonne réponse, votre cerveau utilisera probablement implicitement l'approche RAG, en orientant le modèle vers la réponse adéquate grâce à l'indication de votre localisation.
C'est l'objectif du RAG, piocher parmi vos informations personnelles ou d'entreprise pour mieux vous répondre. La question 'Ou puis-je partir en vacances dans un lieu éco-responsable ?' se transformera en 'Sachant que j'habite à Paris, ou puis-je partir en vacances dans un lieu éco-responsable ?
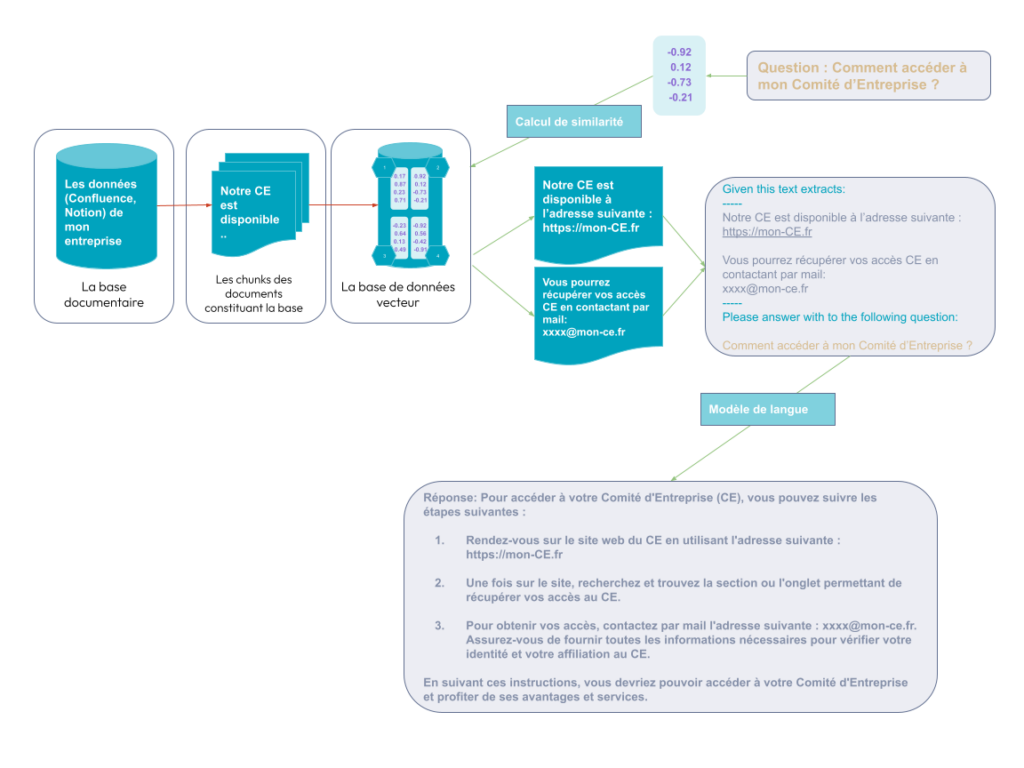
Figure 2: Architecture RAG
Une approche RAG pour la recherche de documentation requiert la construction d’un pipeline, comme présenté ci-dessus. Pour simplifier la création de ces pipelines, communément appelé chaînes, Harrison Chase crée en Octobre 2022 LangChain.
2. LangChain : l’outil du LLM engineer.
LangChain est un framework simplifiant la création de chaînes, ou suite d’étapes, permettant entre autres la mise en place de chatbots basés sur les modèles de langue.
Grâce à sa large communauté Open Source, LangChain offre de nombreuses fonctionnalités et est aujourd’hui le moyen le plus efficace pour créer des architectures autour des modèles de langues. Parmi les fonctionnalités de LangChain, nous citerons les suivantes:
Document Loader : permet de lire des textes d’une source
Vector Store : base de données vectorielle pour les embeddings
Retriever : outils pour retrouver des documents dans une DB ou sur le Web
Chain : pipeline de traitement LLM, en plusieurs étapes
Tools: un moyen de connecter un agent avec des services extérieurs - équivalent des plugins de ChatGPT
Agent: extension des chaînes pour ajouter des outils (lien avec l’extérieur du LLM)
Passons maintenant à l’implémentation d’un Chatbot pour répondre à des questions sur les données de notre entreprise.
3. Construire son Chatbot :
Chez Octo la documentation de l’entreprise est sur Confluence. Elle regroupe entre autres des informations sur les outils internes, les réponses aux questions des employés et des retours d’expériences sur des sujets techniques. Il arrive que l’information soit dispersée à différents endroits, ou que les titres des documentations ne soient pas explicites.
Pour résoudre ces limites et proposer une solution user-friendly, nous avons choisi de créer un Chatbot conversationnel répondant aux questions des employés en indiquant les sources utiles pour approfondir le sujet.
Nous présentons ci-dessous les différentes étapes et le code LangChain pour la création de notre solution : Le Help Desk.
Vous trouverez le repository Github ici.
A. La source de données
La première étape consiste à charger les données depuis Confluence.
LangChain propose différents types de Loader selon le type de fichier (.pdf, .txt, .md, .png). La documentation Octo dans Confluence est en Markdown (le loader Markdown inclut une fonctionnalité d’extraction de textes dans les images).
Nous utilisons le Confluence Loader afin de collecter la documentation directement avec une clé API. Nous avons aussi proposé une MR à LangChain, validée sur la version 0.0.245, pour conserver la structure Markdown et obtenir une meilleure segmentation des chunks.
python<br>import markdownify<br>from langchain.document_loaders import ConfluenceLoader<br><br>loader = ConfluenceLoader(<br> url=CONFLUENCE_SPACE_NAME, # ex: https://prenomnom.atlassian.net/wiki<br> username=CONFLUENCE_USERNAME, # ex: monentreprise@gmail.com<br> api_key=CONFLUENCE_API_KEY # Create a key here<br>)<br><br>docs = loader.load(<br> space_key=CONFLUENCE_SPACE_KEY, # <space_name>/spaces/<space_key>/overview<br> keep_markdown_format=True<br>)<br><br>print(docs[-1].page_content)<br><br>>> <br>“””<br>...<br>## Comment accéder à mon CE ?<br><br>Pour accéder au CE, vous pouvez consultant l’adresse suivante: <https://mon-CE.fr><br><br>Si vous n’avez pas vos identifiants, vous pouvez envoyer un mail à xxxx@mon-ce.fr, le responsable du comité d’entreprise. <br><br>Renseignez les identifiants sur le site du CE et vous pourrez bénéficier de nombreux avantages.<br><br>## Rôle du Comité d'Entreprise :<br><br>Le Comité d'Entreprise joue un rôle essentiel dans le dialogue social au sein de l'entreprise. Ses principales missions sont les suivantes :<br><br>### 1. Défense des droits des salariés :<br><br>Le Comité d'Entreprise est chargé de veiller au respect des droits des salariés en matière de travail, de sécurité, de santé et de conditions de travail.<br>...<br>“””<br>
B. La création des chunks
Comme expliquée dans cet article de Pinecone, l’étape de création des chunks est stratégique. L’objectif est de conserver l’intégralité du contexte dans un chunk afin que sa représentation vectorielle soit la plus représentative possible.
Nos données textuelles ayant été récupérées au format Markdown, il est possible d’en distinguer les parties et sous-parties. On espère maximiser la qualité de nos chunks et des embeddings qui les représenteront dans l’étape suivante.
Le Markdown Header Text Splitter découpe notre page Confluence en identifiant les titres et sous-titres de notre page Markdown. En plus d’un découpage intelligent, les métadonnées des chunks sont complétées avec les titres et sous-titres trouvés.
Prenons un exemple avec le découpage d’un article.
python<br>from langchain.text_splitter import MarkdownHeaderTextSplitter<br><br># Markdown <br>headers_to_split_on = [<br> ("#", "Titre"),<br> ("##", "Sous-titre 1"),<br> ("###", "Sous-titre 2"),<br>]<br><br># Markdown splitter<br>markdown_splitter = MarkdownHeaderTextSplitter(<br> headers_to_split_on=headers_to_split_on<br>)<br><br>chunks = markdown_splitter.split_text(docs[1].page_content) # Sample one doc<br><br>pretty_print(chunks)<br><br>"""<br>...<br>Pour accéder au CE, vous pouvez consultant l’adresse suivante: <https://mon-CE.fr> <br>Si vous n’avez pas vos identifiants, vous pouvez envoyer un mail à xxxx@mon-ce.fr, le responsable du comité d’entreprise. <br>Renseignez les identifiants sur le site du CE et vous pourrez bénéficier de nombreux avantages.<br>--------------------------------------------------<br>{'Sous-titre 1': 'Comment accéder à mon CE ?'}<br>==================================================<br>Le Comité d'Entreprise joue un rôle essentiel dans le dialogue social au sein de l'entreprise. Ses principales missions sont les suivantes :<br>--------------------------------------------------<br>{'Sous-titre 1': "Rôle du Comité d'Entreprise :"}<br>==================================================<br>Le Comité d'Entreprise est chargé de veiller au respect des droits des salariés en matière de travail, de sécurité, de santé et de conditions de travail. Il peut être consulté par la direction de l'entreprise sur différentes questions liées à l'organisation du travail, aux licenciements collectifs, aux restructurations, etc. Il est également informé des projets de l'entreprise et peut émettre des avis.<br>--------------------------------------------------<br>{'Sous-titre 1': "Rôle du Comité d'Entreprise :", 'Sous-titre 2': '1. Défense des droits des salariés :'}<br>...<br>"""<br>
Que se passe-t-il si les chunks créés suivant la structure de notre page Confluence sont trop longs ?
Nous affinons ensuite ce premier découpage en utilisant le Recursive Character Text Splitter. Cette méthode permet de re-diviser de manière récursive les blocs de textes encore trop longs après le premier découpage.
Dans l’exemple ci-dessous, la partie 1. La défense des droits des salariés est divisée en deux chunks.
python<br>from langchain.text_splitter import RecursiveCharacterTextSplitter<br><br>splitter = RecursiveCharacterTextSplitter(<br> chunk_size=400,<br> chunk_overlap=20,<br> separators=['\n\n', '\n', '(?<=. )', ' ', '']<br>)<br><br>splitted_chunks = splitter.split_documents(chunks)<br>pretty_print(splitted_chunks)<br><br>"""<br>...<br>Le Comité d'Entreprise est chargé de veiller au respect des droits des<br>salariés en matière de travail, de sécurité, de santé et de conditions de<br>travail. <br>Il peut être consulté par la direction de l'entreprise sur différentes questions liées <br>à l'organisation du travail, aux licenciements collectifs, aux restructurations, etc.<br>--------------------------------------------------<br>{'Sous-titre 1': "Rôle du Comité d'Entreprise :", 'Sous-titre 2': '1. Défense des droits des salariés :'}<br>==================================================<br>Il est également informé des projets de l'entreprise et peut émettre des avis.<br>--------------------------------------------------<br>{'Sous-titre 1': "Rôle du Comité d'Entreprise :", 'Sous-titre 2': '1. Défense des droits des salariés :'}<br>...<br>"""<br>
Le repository Github inclut des fonctionnalités additionnelles qui ne sont pas présentées ici :
L’ajout des métadonnées de la page Confluence (url, id) avec les métadonnées des blocs de textes (titre, sous-titre)
L’ajout des titres et sous-titres au texte du document
Les fonctions vous permettant de tester le découpage de bout en bout
Une interface Streamlit
C. Les embeddings et la base de données vecteurs
La troisième étape consiste à transformer nos morceaux de textes en représentations vectorielles, appelées embeddings. Ces embeddings nous permettront de faire une étude de similarité pour affiner le contexte transmis au modèle de langue. Il doivent cependant être stockés dans une base de données vecteurs.
LangChain propose de nombreuses intégrations de modèles d’embeddings et de bases de données vecteurs. Nous utilisons par défaut le modèle embedding d’Open AI, text-embedding-ada-002. Nous choisissons la base de données vecteur légère Chroma que LangChain met à disposition
Attention cependant avec le choix des modèles de langage. Utiliser un modèle en utilisant une API tiers tel que celle de Chat GPT rend votre donnée publique. Pour se prémunir de la divulgation de données deux solutions s'offrent à vous:
- La première consiste à héberger le modèle de langage dans une infrastructure privée (on premise ou dans le Cloud)
- La second consiste à utiliser les fournisseurs Cloud qui hébergent le modèle de langage dans une infrastructure dédiée à ce service
Un prochain article détaillera comment remplacer l’API Open AI par des modèles Open Source.
python<br># Embeddings and vector store<br>import shutil<br>from langchain.vectorstores import Chroma<br>from langchain.embeddings import OpenAIEmbeddings<br><br>persist_directory = './db/chroma'<br>chunks = my_custom_splitter(docs) # See notebook for function definition<br>embeddings = OpenAIEmbeddings() # Default to text-embdding-ada-002<br><br># If the directory exists, first delete it<br>try:<br> shutil.rmtree(persist_directory)<br>except FileNotFoundError as e:<br> pass<br><br># Create vector store and save the db<br>db = Chroma.from_documents(<br> chunks, <br> embeddings,<br> persist_directory=persist_directory<br>)<br>db.persist()<br>
D. La chaîne
Dans cette partie, nous allons créer une chaîne nous permettant de mettre en place notre processus de question/réponse.
Nous commençons par créer le retriever qui permet de retrouver les chunks de notre base vecteur. Parmi les paramètres possibles, nous pouvons spécifier une mesure de similarité, indiquer le nombre de chunks souhaités en sortie, ou un score minimum de similarité par rapport à la question posée.
Ces décisions ont un impact sur la qualité des réponses et doivent être optimisées. Le nombre de chunks dépend de différents paramètres tel que le niveau de granularité du découpage ou la richesse de la documentation. Le score de similarité dépend de la proximité des chunks avec la question et donc du niveau de précision de la base documentaire.
python<br>retriever = db.as_retriever(<br> search_type="similarity_score_threshold", <br> search_kwargs={<br> "k": 5, <br> "score_threshold": 0.3<br> }<br>)<br>
Il convient ensuite de créer le prompt adéquat qui aidera le modèle de langue à raisonner.
template = """<br>Use the following pieces of informations to answer, <br>don't try to make up an answer, just say I don't know if you don't know:<br>-----<br>{context}<br>-----<br>Please answer with to the following question:<br>Question: {question}<br>Answer: <br>"""<br>prompt = PromptTemplate(<br> template=template, <br> input_variables=["context", "question"]<br>)<br>```
Nous pouvons maintenant choisir notre modèle et langue et créer une chaîne\_\.\_ Cette chaîne remplace la mise en place des étapes suivantes :
- Créer l’embedding de la question
- Trouver les contenus similaires de la question dans la base vecteur
- Créer le prompt adéquat
- Récupérer la réponse de notre modèle de langue
```python<br># LLM<br>from langchain.llms import OpenAI <br>llm = OpenAI()<br><br># Chain <br>from langchain.chains import RetrievalQA<br><br>chain_type_kwargs = {"prompt": prompt}<br><br>qa = RetrievalQA.from_chain_type(<br> llm=llm,<br> chain_type="refine", # See other types of chains here<br> retriever=retriever,<br> return_source_documents=True,<br> verbose=True<br>)<br>```
Interrogeons notre Chatbot :
```python<br>question = "Comment accéder à mon comité d'entreprise ? "<br><br>query = {"query": question}<br>answer = qa(query)<br><br>print(answer['result']<br>>> """<br>Vous pouvez accéder à votre Comité d'Entreprise en consultant l’adresse https://mon-CE.fr. <br>Si vous n’avez pas vos identifiants, vous pouvez envoyer un mail à xxxx@mon-ce.fr, <br>le responsable du comité d’entreprise. <br>Une fois que vous avez obtenu vos identifiants, vous pouvez les renseigner sur le site du CE <br>et bénéficier de nombreux avantages. <br>"""<br>```
### E\. Tester son modèle
Une particularité d’un projet de ML est **l’évaluation** de la **qualité des prédictions**\. L’utilisation de modèles de langage dont les possibilités de réponse sont infinies complexifie les méthodologies d’évaluation\.
Une approche RAG est faite de deux principaux composants :
- La base de données vecteur
- Le moteur de langage
Afin d’évaluer notre modèle, il convient donc d’étudier la qualité de ces deux composants, individuellement et conjointement\. Le premier composant dépend principalement du choix de l’embedding et de la métrique de similarité\. Le second composant dépend du choix du modèle de langage utilisé et de la qualité du prompt\.
Nous vous présentons dans la suite de cet article les métriques permettant de comparer deux chaînes de caractères, la réponse de notre modèle RAG et celle attendue\. Dans un prochain article, nous détaillerons les différentes méthodes d’évaluations et comparerons les performances de deux modèles RAG\.
Pour comparer deux chaînes de caractères :
1. Il existe des mesures de distance entre la réponse proposée par notre modèle et la réponse souhaitée\. Parmi elles, on peut citer:
- Les distances sémantiques, qui étudient la similarité entre deux embeddings\. Elles nécessitent un modèle de *sentence/paragraph embedding* couplé à une mesure de similarité \(**cosinus**, **euclidienne**, …\)
- Les distances **BLEU** \(utilisé pour la traduction de texte\) et **ROUGE** \(utilisé pour l’évaluation des résumés\), qui étudient la similarité ou l’overlap entre deux chaînes de caractère à partir de n\-grams\. Cependant, ces métriques sont très peu [corrélées au jugement humain](https://arxiv.org/abs/2008.12009?ref=blog.langchain.dev)\.
- Il est aussi possible d’utiliser un autre LLM pour évaluer la performance de notre modèle RAG:
- LangChain propose en effet une chaîne [CriteriaEvalChain](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.criteria.eval_chain.CriteriaEvalChain.html#langchain.evaluation.criteria.eval_chain.CriteriaEvalChain) permettant d’évaluer la qualité des réponses fournies par rapport à un critère, comme la concision ou la véracité de la réponse\.
- La librairie [RAGAS](https://github.com/explodinggradients/ragas) permet d’analyser la qualité de notre modèle sur plusieurs aspects \(grâce à des LLMs\) telles que:
- la **véracité** de la réponse par rapport au contexte
- la **qualité du contexte** choisi par le retriever
- la **capacité** à collecter les éléments de réponses dans la base documentaire
- la **concision** de la réponse apportée\.
Nous vous proposons ci\-dessous le code nécessaire pour l’évaluation de notre modèle RAG avec une approche de calcul de distance sémantique\.
Tout d’abord, construisons un dataset avec les questions et les réponses présentes dans notre base documentaire:
|<br><br>|<br><br>|
|---|---|
|**Questions**<br><br>|**Répon**ses<br><br>|
|Que veut dire O3 ?<br><br>|Un O3 est un One on One ou une réunion régulière \(souvent hebdomadaire\) avec son manager\.<br><br>|
|Quelles sont les étapes de mon intégration ?<br><br>|Rappel des étapes de ton intégration :Avant ton arrivée…<br><br>|
|Quelles sont les bonnes pratiques pour un parrain ou une marraine?<br><br>|Lui faire visiter les locaux\. Lui présenter OCTO …<br><br>|
Ensuite, nous devons:
- Obtenir les réponses de notre moteur de langage pour chaque question
- Calculer les embeddings respectifs de la prédiction et de la réponse attendues
- Calculer la mesure de similarité \(ici **cosinus**\) entre ces deux embeddings
```python<br>from help_desk import HelpDesk<br>from dotenv import load_dotenv, find_dotenv<br>from langchain.evaluation import load_evaluator<br>from langchain.evaluation import EmbeddingDistance<br><br>def get_cosine_distance(reference_text, prediction_text):<br> # Default embeding model is OpenAI <br> evaluator = load_evaluator(<br> "embedding_distance", <br> distance_metric=EmbeddingDistance.COSINE<br> )<br> <br> return evaluator.evaluate_strings(<br> prediction=input_text,<br> reference=reference_text<br> )<br><br><br># Load dataset and RAG model <br>load_dotenv(find_dotenv())<br>dataset = pd.read_csv(DATASET_PATH, delimiter='\t')<br>model = HelpDesk(new_db=True)<br><br># Compute distances between ground truth and prediction<br>cos_distances = []<br>for _, row in dataset.iterrows():<br> prediction_text, _ = model.retrieval_qa_inference(row['Questions'])<br> cos_distance = get_cosine_distance( <br> row['Réponses'], <br> prediction_text<br> )<br><br>cos_distances.append(cos_distance['score'])<br><br>print('Mean cosine distance: ', sum(cos_distances) / len(cos_distances))
<br>```
Voici un exemple de réponse pour une itération :
|<br><br>|<br><br>|
|---|---|
|Questions<br><br>|Qu'apporte la formation sur la prise de parole en public ?<br><br>|
|Réponse du modèle<br><br>|La formation sur la prise de parole en public apporte des réponses concrètes, fonctionnelles et immédiatement applicables pour professionnaliser la communication orale, face à tous types d'auditoires\. Elle fournit aussi des outils de gestion du public pour réagir efficacement aux situations délicates\. Enfin, elle permet d'apprendre à donner et à recevoir des feedbacks efficaces pour améliorer les relations de travail\.<br><br>|
|Réponse attendue<br><br>|Ce stage de deux journées apporte des réponses concrètes, fonctionnelles, immédiatement applicables, à toutes ces questions, afin de professionnaliser sa communication orale, face à des auditoires \(internes, externes, clients, groupes, assemblées, réunions, conférences, cours\.\.\.\)\. Des outils de gestion du public, lors des séquences de questions\-réponses, te permettent aussi d'apprendre à réagir de façon efficace aux situations plus sensibles\.<br><br>|
|Similarité cosinus<br><br>|0\.06<br><br>|
La similarité proche de 0 indique que les deux réponses sont très similaires sémantiquement\.
Le caractère aléatoire des moteurs de langage est responsable d’un phénomène très déplaisant pour un Data Scientist : le code n’est pas idempotent \(en exécutant deux fois de suite ce script, vous aurez deux résultats différents et vous pourrez donc observer deux distances différentes\)\.
Fixer la température à 0 lors de l’instanciation du moteur de langage permet néanmoins de réduire les écarts de distance grâce au caractère *presque déterministe* du modèle\.
Afin d’évaluer la performance de votre modèle RAG malgré le caractère aléatoire de votre moteur de langage, il est également possible d’effectuer N évaluations sur votre dataset pour en obtenir sa performance moyenne\.
### Conclusion
Nous avons parcouru dans cet article les différentes étapes pour la construction d’un **moteur de langage** **connecté** à une **base de connaissance**\.
Langchain offre une grande flexibilité et vous permettra d'optimiser certaines étapes selon votre cas d’usage\.
Nous vous proposerons prochainement deux nouveaux articles :
- Le premier évaluera deux modèles RAG en approfondissant les différentes métriques de performances brièvement citées dans cet article\.
- Le second concerne la mise en place d’un moteur de langage Open Source avec ses implications sur un pipeline RAG\.