Le change approval process d'un logiciel avec du ML
Cet article fait partie de la série Accélérer le Delivery de projets de Machine Learning, traitant de l’application d’Accelerate dans un contexte incluant du Machine Learning. Si vous n’êtes pas familier avec Accelerate, ou si vous souhaitez avoir plus de détails sur le contexte de cet article, nous vous invitons à commencer par lire l’article introduisant cette série. Vous y trouverez également le lien vers le reste des articles pour aller plus loin.
Change Approval Process : de quoi s’agit-il ?
Commençons par une définition de ce que recouvre la notion de Change Approval Process en général avant de s’intéresser aux spécificités du concept dans le cas d’usage du Machine Learning.
Dans l’étude Accelerate, le Change Approval Process est une des capabilities de la famille Lean Management & Monitoring. Cette capability s’intéresse spécifiquement aux processus de revue, de contrôle et de décision qui mènent à la validation ou l’invalidation d’un changement.
Dans cette notion de changement, l’étude est volontairement très large, précisant qu’il peut s’agir de tous les types de changement dans un système de delivery. Le changement le plus emblématique est la livraison d’une nouvelle version de l’application, mais d’autres types de changements peuvent être considérés :
- changement dans l’attendu d’une fonctionnalité ;
- changement dans les modes d’organisation d’une équipe ;
- changement dans l’architecture technique de la solution.
Cette capability s’intéresse donc à la façon dont l’organisation appréhende le changement et le gère : dans quel but ? par quels processus ? dans quelle temporalité ? avec quelles métriques ? via quelles équipes ?
Les objectifs du processus de gestion des changements
L’objectif premier d’un processus de gestion du changement est de limiter les risques. Lorsqu’on effectue un changement, on introduit une nouveauté et donc une dose d’imprévu à une situation connue. Ce dont il faut s’assurer, c’est que ce changement va être positif pour le système en lui ajoutant de nouvelles propriétés désirables plutôt que de le dégrader en lui ajoutant des propriétés indésirables.
Quelques exemples de propriétés désirables en reprenant les catégories ci-dessus :
- mise en production : absence de bug, absence de dégradation des performances, conformité aux exigences de sécurité ou aux impératifs réglementaires
- attendu fonctionnel : meilleure adéquation au besoin, simplification de l’usage
- modes d’organisation : amélioration de l’efficience, réduction du lead time
- architecture technique : meilleure adéquation aux besoins fonctionnels, réduction du coût de maintenance et d’évolution, facilité d’exploitation
Ce que cherche à formaliser un processus de gestion du changement, c’est la preuve que le changement va bien améliorer le système et non le dégrader.
Le deuxième objectif d’un processus de gestion du changement est d'être efficace. Un processus efficace va garantir une amélioration du système avec un impact minimal sur le flux du delivery : pas de ralentissement du flux du travail, pas de temps d’attente, etc.
Les écueils classiques des processus centralisés
Un écueil fréquent des processus de gestion du changement est leur impact négatif sur le flux de travail. Dans de nombreuses organisations, les processus de validation des changements sont confiés à des entités dédiées : équipe de recette, comité d’architecture, comité sécurité, comité de pilotage, etc. Ces instances sont censées disposer de l’autorité et des compétences nécessaires pour instruire et rendre une décision sur une demande de changement relevant de leur périmètre. Elles ont cependant souvent deux attributs problématiques :
- leur fréquence, qui entraîne un délai supplémentaire (attente de la date à laquelle le comité se réunit) ;
- leurs exigences, qui génèrent automatiquement un travail supplémentaire pour obtenir l’approbation (constitution d’un dossier par exemple).
Une perte de vitesse serait-elle donc le prix à payer pour la stabilité de nos systèmes ?
L’étude Accelerate indique que les organisations qui possèdent les meilleurs indicateurs de stabilité dans leur delivery sont aussi celles qui livrent le plus fréquemment. La gestion des changements fait partie des pratiques où l’étude propose des modalités en rupture avec leur conception usuelle. Les organisations les plus performantes ne sont pas celles qui recourent à des validations centralisées. C’est même l’inverse qui est constaté : la délégation systématique à des responsables externes aux équipes engendre un taux d’échec sur changement supérieur, donc moins de stabilité, et une fréquence de déploiement moins bonne, donc moins de vitesse.
Quelles sont donc les caractéristiques d’un bon processus de gestion du changement selon Accelerate ?
Pour garantir l’efficience des processus de validation des changements, Accelerate propose 4 axes sur lesquels travailler :
- la responsabilisation des parties prenantes, en leur déléguant la validation des changements qu’elles introduisent ;
- la détection des problèmes au plus tôt via des processus automatisés, au retour bien plus rapide que celui d’un comité ;
- la différenciation du traitement des changements selon leur nature et leur profil de risque ;
- la mesure de la rapidité et de l'efficience du processus de validation des changements.
Ces éléments généraux posés, regardons maintenant les spécificités de la notion de changement et de validation dans le cas d’un produit logiciel qui embarque des modèles de Machine Learning.
Ce qui diffère en ML sur l’approbation
Le paradoxe du Machine Learning
Un des principaux obstacles à la mise en production de modèles de ML est humain : la peur. Si la peur du déploiement n’est pas propre au ML, elle est exacerbée dans ce contexte.
Lorsqu’une fonctionnalité est développée sans ML, son comportement dépend essentiellement de son code. Il est alors relativement simple de mettre en place une boucle de feedback en amont de son déploiement grâce à des tests automatiques. Lorsque cette même fonctionnalité est développée avec du ML, elle n’est alors plus codée tout à fait explicitement. Une partie de son comportement est inférée à partir de données. Il est donc plus complexe de l’anticiper : produire des tests de façon aussi exhaustive que pour un logiciel sans ML est sinon illusoire, du moins extrêmement coûteux. Cette première boucle de feedback détecte moins bien les problèmes fonctionnels chez un logiciel avec ML. Dès lors, une part relativement plus grande de la validation ne pourra se faire qu’avec le temps, en observant le comportement du modèle face à des données réelles de production.
Cette complexité produit une situation paradoxale : nous ne savons pas si notre modèle fonctionne, donc nous ne le mettons pas en production. Mais, comme nous ne le mettons pas en production, nous ne savons pas s’il fonctionne.
Cette difficulté supplémentaire pousse parfois les organisations à ajouter de nouvelles modalités de contrôle et à renforcer leur processus de validation des changements pour le cas spécifique du ML, alors qu’elles ont par ailleurs allégé leur processus pour les produits logiciels classiques. Afin de se rassurer, elles vont parfois créer de nouveaux processus censés mitiger ces nouveaux risques. En voici quelques exemples :
Exemple 1 : Validation des données d’entraînement
Les données sont annotées par le métier, mais aucun modèle ne peut être entraîné tant que ces données ne sont pas validées par des experts qualité.
Critère d’acceptation : le pourcentage de données correctement labellisées est supérieur à un certain seuil
Problèmes :
- Le lien entre la proportion de données correctement labellisées et l’utilité du produit pour ses utilisateurs n’est pas évident. La définition d’un seuil ayant vraiment une valeur métier est hasardeuse.
- Les experts à mobiliser pour obtenir cette mesure sont souvent occupés et leur priorité n’est pas de vérifier la qualité de ces données. Le temps à attendre pour avoir une validation est donc lent.
Exemple 2 : Validation du modèle avant sa mise en production
Le Data Scientist travaille sur son modèle prédictif, pour déterminer quels articles de journaux pourraient intéresser un abonné au vu de ses lectures passées. Il dispose des données de navigation de tous les abonnés, enregistrées lors des deux dernières années. Aucun système de recommandations n’est en production lors de la période observée. Il ne peut mettre en production son modèle que si ce dernier a une performance jugée “acceptable” sur les données dont il dispose.
Critère d’acceptation : parmi les 10 articles recommandés, l’utilisateur en a vraiment consulté 2.
Problèmes :
- La performance du modèle est mesurée en fonction de données historiques. Elle n’est pas nécessairement transposable à la réalité actuelle du journal et des articles qui y sont publiés en ce moment même ;
- La qualité des recommandations est très probablement mieux mesurée à travers des indicateurs qui ne sont mesurables qu’en conditions réelles (temps supplémentaire passé sur le site du journal pour une personne recevant des recommandations, revenu généré par les recommandations…) ;
- En conditions réelles, l’algorithme de recommandations modifie l’expérience des utilisateurs. Les articles recommandés sont plus facilement découvrables que s’ils n’étaient accessibles qu’à travers la recherche. Ainsi, un score de 2/10 mesuré sans recommandations ne peut pas être généralisé à une configuration où des articles recommandés sont mis en avant.
Ce type de processus de validation s’avère inefficace puisqu’il ne se base pas sur des éléments pertinents à la mitigation du risque. Pire, il retarde le moment où le risque aurait pu être levé et freine ainsi le mécanisme d’amélioration continue du produit.
La question de la preuve et de la justesse
En creux, ce sont ces deux questions qui se jouent dans la validation d’un changement impliquant un modèle de ML :
- La preuve : Au vu de la complexité supplémentaire que m’apporte le ML, comment prouver en amont du déploiement d’un modèle que sa mise en production est souhaitable ?
- La justesse : Ma difficulté à prouver la pertinence d’un modèle avant son déploiement m’emmène à utiliser des proxies (par exemple, un pourcentage de justesse des prédictions). Mais la pertinence de mon modèle au sein de mon produit est-elle vraiment mesurable ainsi ? Ne vaudrait-il pas mieux mesurer son impact sur les parcours des utilisateurs ?
Notre conviction, c’est qu’il faut revoir à la fois nos exigences sur la preuve et sur la justesse.
Définir l’intégralité de ce qui est prévu dans le cas d’un modèle de ML est une tâche illusoire : sa complexité essentielle impliquerait un travail colossal qui n’apporterait pas nécessairement un retour à la hauteur des investissements. L’objectif n’est pas d’avoir un modèle toujours juste mais suffisamment juste.
Pour définir ce qui est suffisamment juste, il faut résister à la tentation de la preuve mathématique : un bon modèle n’est pas celui qui dispose d’un pourcentage de précision exceptionnel sur des données d’entraînement. Un bon modèle n’est pas non plus celui qui dispose d’un pourcentage de précision satisfaisant sur des données de production. La caractéristique d’un bon modèle, c’est plus fondamentalement d’être utile pour le cas d’usage auquel il répond : prouver sa justesse est donc une question d’indicateurs métiers qui évoluent dans le sens attendu, tout en ayant la capacité d’interpréter notre modèle et de le faire évoluer rapidement si c’est nécessaire.
Pour y parvenir, nous proposons ces 3 axes de développement que nous allons détailler ci-après :
- Identifier et mesurer les bons indicateurs de réussite, notamment d’un point de vue usage et métier ;
- Être capable d’aller vite en production pour confronter le modèle à la réalité des usages ;
- Être industrialisé pour pouvoir changer rapidement lorsqu’on en a besoin.
Sans oublier les enjeux classiques d'un projet intégrant du ML, autour des notions d'interprétabilité et d'éthique, qui ne seront pas développés ici.
Dans la dernière partie de l’article, nous allons nous focaliser sur ces 3 axes qui sont intimement dépendants les uns des autres.
Des solutions pour valider des changements efficacement dans un contexte ML
Pour finir cet article, nous vous proposons donc des exemples de solutions pour répondre aux 3 enjeux listés ci-dessus. Fidèles au postulat de base d’Accelerate, nous regroupons les enjeux 2 et 3 dans le même ensemble de pratiques puisque l’industrialisation des mises en production et leur fréquence sont intrinsèquement liées.
Déterminer des indicateurs permettant d’approuver le déploiement d’un nouvel algorithme
Pour approuver un changement via des processus automatisés, il est nécessaire de disposer de critères d’acceptation des changements. Afin que ces critères soient évaluables de façon automatique, nous préconisons la mise en place d’indicateurs permettant de déterminer que le nouvel algorithme répond aux critères évoqués précédemment.
| Critère | Exemple d’indicateur / validation |
| Il répond au besoin utilisateur exprimé dans le ticket | Suivi d’indicateurs métier. Par exemple :<br><br>- Panier moyen<br>- Taux de clic<br>- Taux de rebond<br>- Nombre de pages vues |
| Il s’intègre correctement dans le reste du produit : son intégration technique est réussie | Suivi d’indicateurs techniques comme :<br><br>- Erreurs 500<br>- Erreurs 404<br>- Erreurs 4xx (causées notamment par un contrat d’interface cassé) |
| Il ne dégrade pas l’expérience utilisateur : <br><br>- le reste du logiciel continue à se comporter comme attendu ;<br>- la fonctionnalité qui repose sur l’algorithme n’est pas dégradée au-delà de ce qui est jugé acceptable | Suivi des SLIs. Par exemple :<br><br>- Temps de réponse<br>- Rupture dans le parcours utilisateur<br>- Évolutions d’indicateurs métier (taux d’attrition, taux de clic, panier moyen, ROI…) |
Mesurer ces indicateurs en conditions réelles et avec sérénité
L’endroit le plus pertinent pour mesurer ces indicateurs, est la production. Il nous faut donc sortir de l’impasse que nous évoquions plus haut. Pour cela, nous vous proposons de revoir la chronologie du processus de validation de nos modèles, afin de découpler le déploiement de la mise en service, et donc être en capacité de mettre en production sans impacter notre utilisateur. Voici un exemple nous permettant de le faire.
1. Déployer notre modèle sans impact sur l’utilisateur
Il s’agit de mitiger le risque associé au déploiement du modèle, sans impacter l’expérience utilisateur. Pour cela, nous déployons notre modèle sans le rendre tout de suite accessible aux utilisateurs. Cela est possible grâce au feature flipping, qui nous permet de :
- rendre plusieurs modèles accessibles à partir de nos environnements ;
- paramétrer ces environnements pour qu’ils servent l’un ou l’autre de ces modèles.
Ainsi, nous pouvons déployer notre nouveau modèle mais continuer à servir l’ancien le temps de finir nos validations.
2. Valider l’intégration de notre modèle au sein de notre infrastructure
Au lieu de faire des tirs de charge avec des données générées et des smoke tests sur des scénarios limités, nous préférons opter pour la shadow production, permettant de tester le comportement de notre modèle face à des vraies données. Il s’agit de déployer notre modèle en parallèle de la production et de lui faire parvenir les mêmes données. Cela peut être fait en ajoutant une file de messages pour découpler l’envoi des données pour inférence du modèle. L’application publie alors des messages dans cette file, qui sont ensuite consommés par le modèle en production ainsi que par le nouveau modèle. Nous surveillons notre nouveau modèle en mesurant notamment ses temps de réponse, en repérant et investiguant ses erreurs 500… Cela nous permet d’apporter des changements à notre modèle avant qu’il ne soit accessible pour nos utilisateurs, donc qu’il ne reçoive du trafic en production.
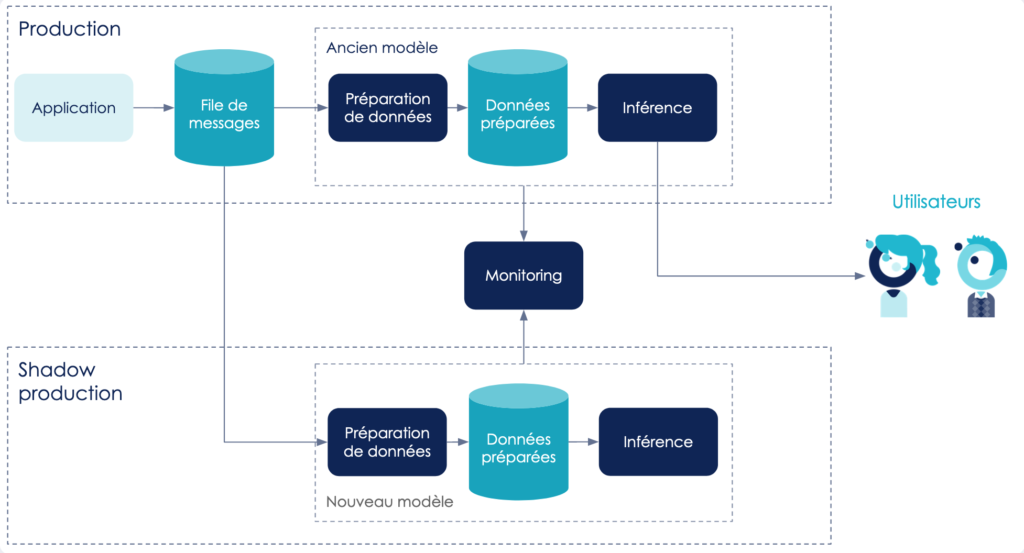
Exemple d'architecture d'une shadow production
3. Valider la valeur utilisateur de notre modèle
Afin de déterminer si notre modèle est prêt pour une mise en service, nous mesurons sa valeur utilisateur en conditions réelles, c’est-à-dire en le rendant accessible à une partie de nos utilisateurs. Nous faisons cela grâce à l’AB testing ou au canary release. Cela nous permettent d’exposer à une petite partie de nos utilisateurs notre nouveau modèle et être en capacité de comparer des métriques métier (taux de conversion, panier moyen…) différenciées selon la version qu’aura vue l’utilisateur.
4. Mettre le nouveau modèle en service
Une fois que toutes nos vérifications sont au vert, nous paramétrons notre environnement de production pour qu’il serve le nouveau modèle. Cette action est décidée et, dans l’idéal, exécutée par le PO ou le métier. Ainsi, la mise en service devient une décision purement fonctionnelle et non technique.
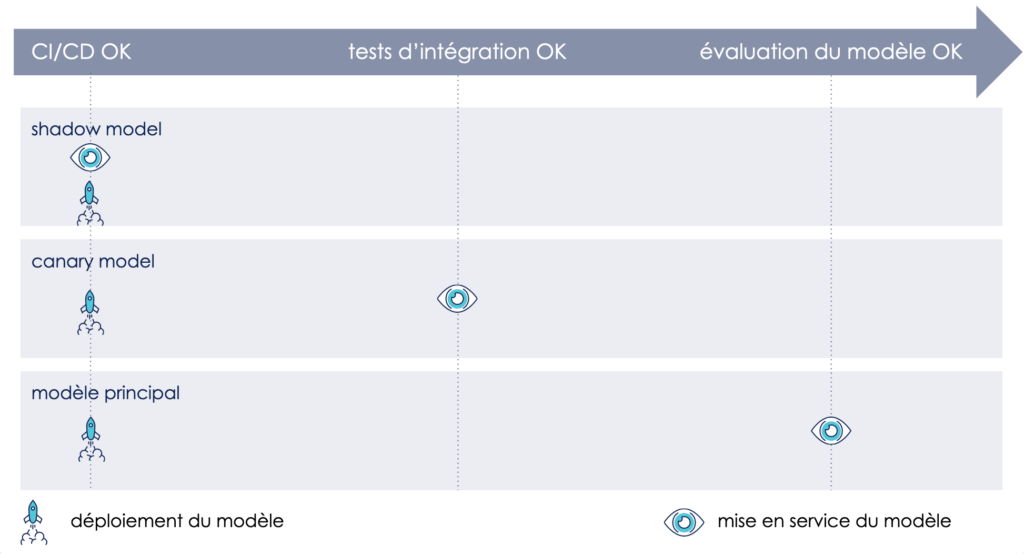
Notre approche : décorréler le déploiement de la mise en service ou validation a posteriori.
CONCLUSION
Approuver un changement, c’est répondre à une exigence de précaution en s’assurant que le changement ne va pas créer de problème, ou pour le dire autrement, ne va pas créer un écart entre la situation réelle et la situation désirée.
Dans le cas de la validation d’un modèle de Machine Learning, ce besoin rencontre un écueil fondamental. Il est en effet est extrêmement coûteux de valider a priori le comportement du modèle et seule sa confrontation avec un environnement réel permettra d’y parvenir en restant pertinent économiquement. Notre besoin de preuve est donc mis à mal et notre réponse instinctive est le plus souvent d’ajouter de nouveaux critères de contrôle a priori fondés sur ce que nous savons contrôler, c’est-à-dire des métriques scientifiques qui permettent de mesurer sa pertinence technique via des preuves statistiques, théoriques et hors ligne.
Comme nous avons essayé de l’illustrer, un changement de paradigme est nécessaire et atteignable pour traiter d’un même mouvement deux problèmes. D’une part, la gestion du risque inhérent à la validation d’un changement impliquant un modèle. D’autre part, les effets de bord liés à l’ajout de contrôles supplémentaires (délai supplémentaire, coût additionnel, etc.). Pour reprendre la terminologie d’Accelerate, c’est combiner une amélioration de la vitesse et de la stabilité du système grâce à des pratiques techniques et méthodologiques, adossées à une vision métier des critères avec lesquels nous approuvons un changement.