L’atelier matrice d’erreur : démystifier les performances du ML avec ses utilisateurs
Nous pensons que la gestion des erreurs est un aspect important dans les systèmes de prise de décision et qu’il est indispensable d’étudier cela avec les utilisateurs d’un tel produit, a fortiori lorsqu’il embarque du Machine Learning. Dans cet article, nous vous proposons une méthode itérative, pour évaluer le coût d’une erreur et adapter le système de prise de décision, pour que ses utilisateurs aient plus confiance en lui.
La data science proposant de nombreuses définitions que nous utiliserons dans cet article, voici un petit glossaire des termes les plus importants :
- Machine Learning : Ensemble des méthodes d’apprentissage automatique, basées sur la reconnaissance de motifs appris dans un historique de données.
- Métrique : une métrique, dans le contexte de cet article, est un outil qui va nous permettre de quantifier l’erreur d’un modèle.
- Accuracy : ou Exactitude en français est une métrique de classification. L'exactitude est la proportion de prédictions correctes, c’est-à-dire les vrais positifs et vrais négatifs, parmi le nombre total de prédictions. Ce nombre est donc compris entre 0 (parfaite inexactitude) et 1 inclus (parfaite exactitude).
I. Genèse et objectif
La naissance de l’atelier
Aujourd’hui, les algorithmes de machine learning sont de plus en plus présents dans les projets de nos clients et malgré tout, il n’existe que peu d’ateliers pour nous aider à cadrer ce type de projets. Des outils permettent le cadrage mais ils restent principalement techniques. On peut citer le Machine Learning canvas qui nous permet de répondre à des questions telles que “où dois-je collecter les données ?”, “quelle métrique vais-je utiliser ?” ou encore “comment les prédictions vont aider à l’utilisateur final à prendre des décisions ?”. Mais cela ne reste qu’un outil répondant surtout aux problématiques techniques de Machine Learning sans donner au métier plus d’information sur le rôle de l’intelligence artificielle dans le projet (pas de métrique métier par exemple).

ML Canvas
Ainsi, lors de diverses missions chez nos clients ou chez nos partenaires, nous nous sommes aperçus qu’il existe une compréhension hétérogène de la performance en Machine Learning. En effet, on entend souvent que l’objectif est d'atteindre “100% accuracy”. La hype générée ces dernières années autour du machine learning a mis en lumière les capacités prédictives des traitements statistiques, sans toujours mettre en avant le caractère probabiliste et donc faillible de ce type d’algorithmes, par leur nature statistique. De plus, en conditions réelles, de multiples facteurs peuvent avoir une influence sur les performances d’un algorithme d’apprentissage: la qualité des données d’entraînement ou leur différence face aux données du monde réel, l’exhaustivité des processus sous-jacents qu’il sait modéliser intérieurement, et bien d’autres. Tous ces paramètres, qui peuvent parfois être corrigés grâce à des techniques d’ingénierie, sont difficiles à appréhender par un utilisateur néophyte, et peuvent produire un décalage de compréhension.
Notre objectif ici pourrait donc être de créer des liens entre les visions différentes des acteurs qui produisent l’algorithme, d’une part les data scientists qui ont la compréhension du fonctionnement mathématique et des utilisateurs qui en ont une compréhension plus terre à terre / orienté business
Elles vont s’accorder autour de certains points de compréhension partagés, comme la définition de certaines métriques (par exemple, une définition partagée de la précision de l’algorithme), et qui peuvent avoir des significations différentes selon l’interlocuteur. La notion de performance et d’évaluation pouvant être différente selon le contexte, identifier quelle mesure doit être faite et pourquoi elle est primordiale. Par exemple, dans le cas de détection de spam, on préfère être sûr de classifier un mail en tant que spam quitte à laisser passer quelques spam entre les mailles du filet plutôt que de mal catégoriser un mail important.
La performance en ML peut être évaluée à travers différentes métriques. Le choix de la métrique ou des métriques dépend du cas étudié, il n’est alors pas toujours nécessaire de rechercher un score très élevé d’accuracy. On définit ensemble avec le client une compréhension commune du ML, avec des briques logicielles dont certaines peuvent être du Machine Learning dans le contexte du projet.
L’atelier de la matrice d’erreur que nous proposons se veut un outil concret pour construire un système intelligent centré sur l’utilisateur. Sachant qu’il n’est déjà pas simple de centrer un produit sur ses utilisateurs, on y ajoute la complexité d’un système intelligent. Les risques les plus courants sont que:
- le développeur construise le système comme il le perçoit, avec ses biais,
- Le métier gérant l’application, ainsi que ses utilisateurs, ne perçoivent pas que le système devra faire un compromis, toutes les métriques ne peuvent être optimisées.
Les acteurs opérant des systèmes basés sur du ML ont pu capitaliser sur l’appréhension de cette complexité au travers de principes de design et au travers de la communauté Human Computer Interaction qui, depuis une vingtaine d'années, travaille à l’amélioration de leurs interactions.
1. Minimiser la complexité
Jess Holbrook, qui anime cette communauté au sein de Google, propose en premier lieu d’évaluer si le système proposé est le plus simple à comprendre par les utilisateurs, en rapport avec le service qu’il rend.
Pour cela, il présente un outil conceptuel utilisé lors du design de produits embarquant du ML :
- Pour évaluer l’intérêt du caractère intelligent d’un système, soit sa capacité à produire des résultats alignés avec la tâche qu’on lui aura assigné, un questionnaire permet de révéler les attentes et hypothèses des utilisateurs sur le futur système.
- Des questions comme “Décrivez comment un humain expert sur cette tâche pourrait la réaliser”, “Si un humain effectuait cette tâche, quelles attentes auriez vous en tant qu’utilisateur vis à vis du service rendu ?”, permettent de fixer des limites de fonctionnement attendues au système.
- En projetant les réponses sur ce canevas, les UX designers de Google peuvent prioriser les solutions dont la partie intelligente aura le plus d’impact.

Pour les chercheurs de Microsoft, la phase de conception d’un système intelligent est également un moment privilégié pour rendre intelligible aux utilisateurs deux aspects :
- Les capacités du système embarquant du ML, comme par exemple la suggestion automatique du prochain mot dans l’éditeur de texte Word
- Les conditions dans lesquelles le système performe avec les capacités présentées en premier lieu.
2. Diagnostic d’erreur et indécision gracieuse.
De par leur nature statistique, les erreurs font partie de tout de système intégrant du ML. Leur gestion doit naturellement faire partie des principes dirigeant leur design, tel que les équipes People +AI Research (proposent. L’objectif du design d’une expérience de l’erreur est double :
- Améliorer la compréhension du modèle mental de l’utilisateur, soit la représentation mentale qu’il se fera du fonctionnement de l’algorithme et de ses failles, pour lui fournir une information pertinente lorsque le système intelligent est en erreur.
- Améliorer le système en lui-même, en identifiant les sources d’erreur et les options utiles à l’utilisateur à proposer en cas d’erreur manifeste.
Au contraire, si l’erreur n’est pas prise en compte lors du design, des dérives algorithmiques peuvent rapidement apparaître. Typiquement, un algorithme prédisant la demande de location de voitures sur un périmètre donné, s’il se trompe, peut aboutir à une pénurie dans un secteur et une surcharge de véhicules dans un autre, conduisant à un manque à gagner au lieu de l’optimisation souhaitée.
L’atelier de la matrice d’erreur s’inscrit dans ces principes de design en proposant de travailler sur les problématiques concrètes de nos clients.
Objectifs
L’objectif principal de l’atelier est d’obtenir les informations nécessaires pour concevoir un système répondant au mieux aux attentes des utilisateurs. Pour ce faire, nous cherchons à utiliser plusieurs moyens :
Le premier est de sensibiliser aux imperfections des systèmes intelligents. L’idée est d’informer les métiers gérant l’application et ses utilisateurs qu’un système intelligent peut être plus performant que l’humain mais n’est pas infaillible.
Un second moyen est d’identifier les critères d’évaluation de l’algorithme qu’auront ses utilisateurs, par rapport à la problématique qu’il est censé résoudre. Cette étape est une étape indispensable à la réalisation d’un système intelligent performant car il permet de comprendre sur quels éléments l’évaluation du système devra porter. L’idée est de définir de façon plus précise quel est l’objectif du système intelligent que l’on cherche à développer. En effet, si le principal objectif métier est de maximiser les profits faits sur les locations de voiture, une pénurie sur certains secteurs peu demandeurs peut être un compromis acceptable si les secteurs les plus rentables sont correctement approvisionnés.
Comme dit précédemment, un système intelligent ne fournit pas forcément des résultats parfaits. Plusieurs systèmes peuvent être créés pour répondre à une même problématique et chacun aura des avantages et des inconvénients. L’objectif est alors de comprendre les différentes erreurs qui peuvent être commises et de savoir quel est le meilleur compromis en identifiant les erreurs les moins contraignantes.
Aucun modèle n’est parfait : mais lequel choisir ?
L’ensemble des objectifs précédents permettent par la suite de construire des métriques métiers qui reflètent les enjeux métier définis en amont.
Ces métriques seront alors utilisées pour évaluer les performances du système et les améliorer. Elles permettront d’orienter la conception du système en évitant, ou à minima en minimisant, les erreurs ayant été identifiées comme étant les plus « graves ». Elles chercheront donc à minimiser les erreurs ayant été préalablement identifiées comme étant les plus pénibles aux yeux des utilisateurs. En conclusion, cet atelier permet d’accomplir 2 choses :
- Diminuer les écarts de compréhension, par la sensibilisation des utilisateurs aux erreurs qui arrivent dans l’utilisation de l’algorithme.
- Prioriser l’effort à mettre sur la manière de les prendre en charge, en fonction de leur gravité.
Un exemple appliqué à la détection d’animaux
Pour illustrer notre propos tout au long de l’article, prenons l’exemple d’un cas d’usage :
Dans ce cas d’usage, des utilisateurs cherchent à détecter et classer des espèces animales en utilisant un dispositif embarqué en milieu naturel. Initialement, pour analyser la présence ou l’absence d’animaux dans leurs milieux d’observation, des caméras trap sont utilisées : il s’agit de pièges photo-vidéo qui, à l’aide d’un détecteur de mouvement infrarouge, déclenche la prise d’une photo ou d’une vidéo. Ces données sont par la suite enregistrées et analysées manuellement, une à une, afin de notifier la présence ou non d’un animal et d’identifier l’espèce, en cas de présence animalière, grâce à l'expertise de l’utilisateur.

Un animal est il passé devant la caméra ?
Pour améliorer et rendre moins chronophage le processus analyse-identification des données, cette tâche est déléguée à un algorithme de ML s’exécutant sur un dispositif électronique embarqué. Le but est de développer un dispositif autonome capable de détecter et classer les mammifères observés en milieu naturel.
Ici, le ML intervient à deux niveaux : lors de la détection d’une présence animalière puis lors de l'identification de son espèce. L’atelier de matrice d’erreur aura alors pour objectif d’évaluer les différents types d’erreurs commis lors de ces deux étapes.
II. Méthodologie de l’atelier
Quels sont les pré-requis pour faire l'atelier ?
Quel public ?
Le public attendu pour réaliser l’atelier est composé de profils hétérogènes. Nous proposons un public composé d’experts métiers, d’utilisateurs un peu moins experts, ainsi que de data scientists.
Les data scientists ont pour but de modéliser le problème traité. La présence des experts métiers est quant à elle requise afin d’avoir leurs avis sur les différents scénarios de modélisation proposés. Ces derniers doivent donc être capables de juger les résultats des modèles de classification proposés par les data scientists.
L’idée ici est d’avoir un nombre de personnes suffisamment important pour obtenir des réponses diversifiées, et se challengeant, afin de recueillir le maximum d’informations. Toutefois, attention à ne pas surcharger l’atelier en personnes au risque de nuire aux interactions. Un nombre de quatre ou cinq participants paraît idéal, il devra cependant être ajusté au cas par cas.
Quelles sont les informations qu’on souhaite obtenir ?
Avant de commencer l’atelier, il est nécessaire d’avoir une première idée des informations que l’on souhaite obtenir à la fin de l’atelier. Une méthode pour obtenir ces informations est de préparer quelques questions ouvertes en amont.
Reprenons le cas de nos chercheurs, des exemples de questions ouvertes sont :
- Combien de temps prenez-vous pour manuellement identifier les animaux présents dans 100 vidéos ?
- Lorsqu’une espèce est difficile à identifier, que faites-vous ?
- Est ce qu’il arrive que vous fassiez des erreurs sur ces cas complexes ?
Ces questions peuvent être précisées et complétées au fur et à mesure de la discussion, grâce aux réponses obtenues.
Attention toutefois à ne pas poser des questions trop orientées au risque de biaiser le public et leurs réponses. Par exemple :
- Est-ce que l’explicabilité du modèle est importante ?
- Il est plus difficile de faire ceci que cela_, vrai ?_
- Est-ce que vous préférez une application desktop ou un site web ?
Les questions plus généralistes sont préférables. Elles permettent de recueillir plus d’informations, grâce aux réponses des participants qui seront d’avantages variées d’une personne à une autre, comparées aux réponses qui seraient obtenues avec des questions trop orientées.
Le matériel à prévoir
Pour un atelier de matrice d’erreur en présentiel, plusieurs supports de travail peuvent être envisagés. Les différentes modélisations réalisées par les data scientists pourront être projetées (slides) ou imprimées.
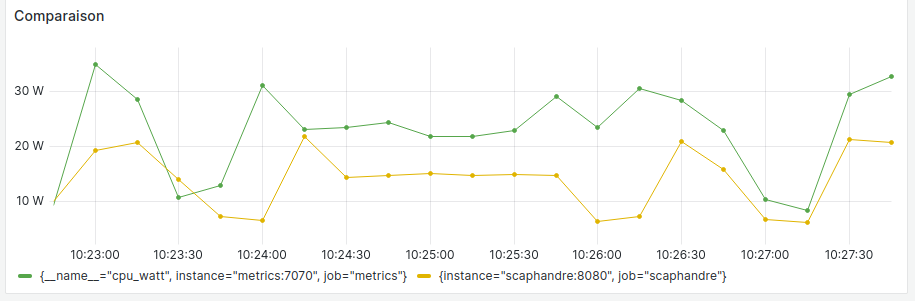
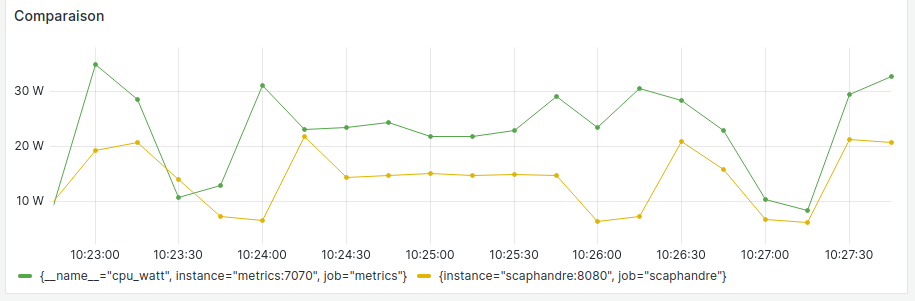
Exemple de slide introduisant le compromis
En présentiel ou en remote, il faudra permettre aux participants de voter entre les différents modèles proposés. Dans les deux cas, le vote peut être effectué sur smartphone (Google form, mentimeter, ...) et les résultats ensuite projetés. En présentiel, le vote pourra également être effectué sur papier, sur lequel figurera, par exemple, chaque modélisation numérotée et accompagnée d’une échelle de notation.
A l'issue du vote, si l’ensemble des voix ne sont pas unanimes, il peut être intéressant de demander aux participants pourquoi ils ont préféré un choix plutôt qu’un autre. C’est l’occasion de saisir des informations qui n’auront pas encore été captées.
Déroulement de l’atelier
La durée estimée de cet atelier est de 2h pour la découpe suivante.
L’atelier débute par un tour de table puis par une présentation de l’atelier (son déroulement et son objectif) pendant environ 10 minutes. Cette étape permet de décrire quels objectifs nous cherchons à atteindre avec cet atelier et de quelle manière nous envisageons de les atteindre.
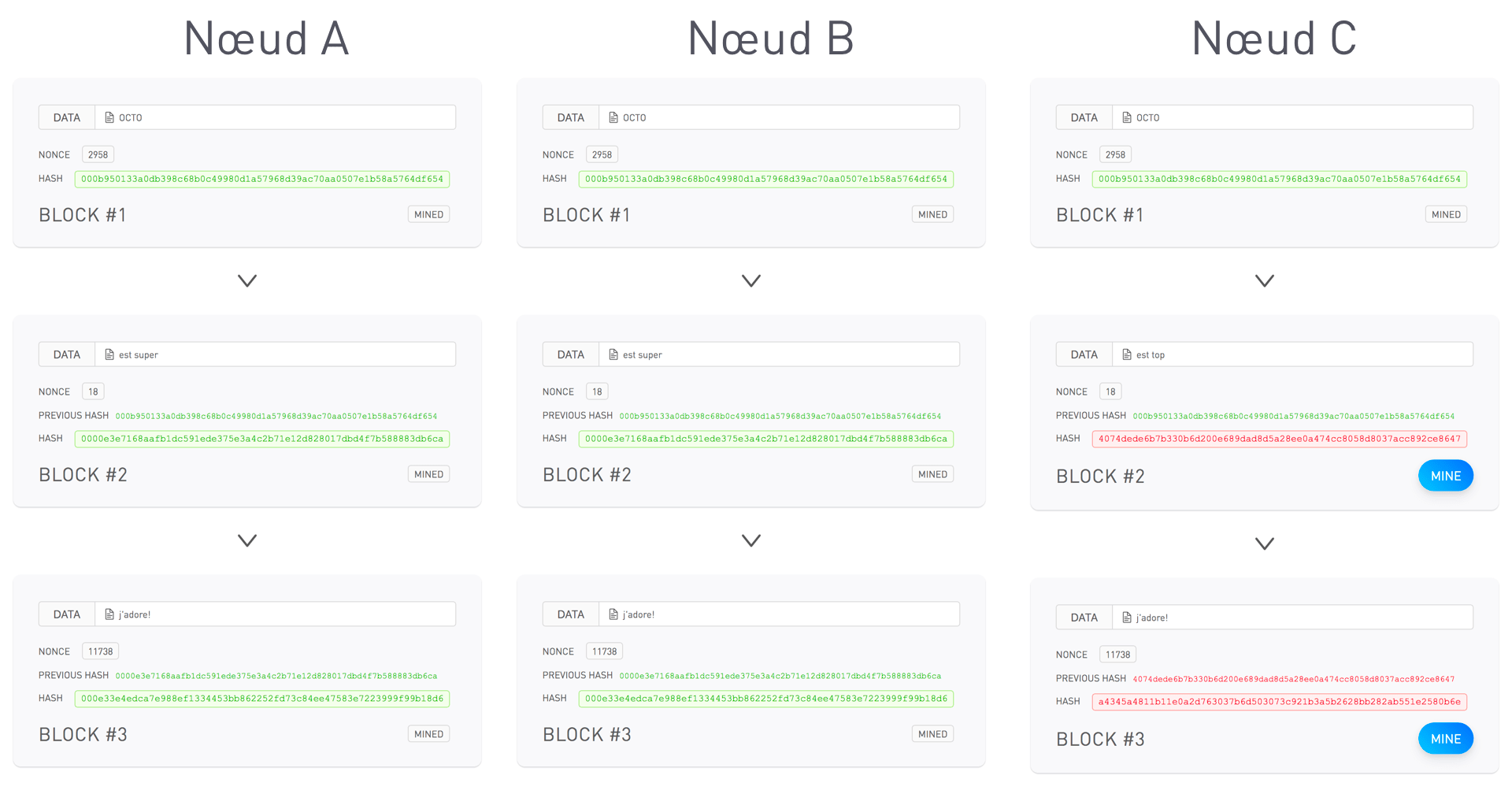
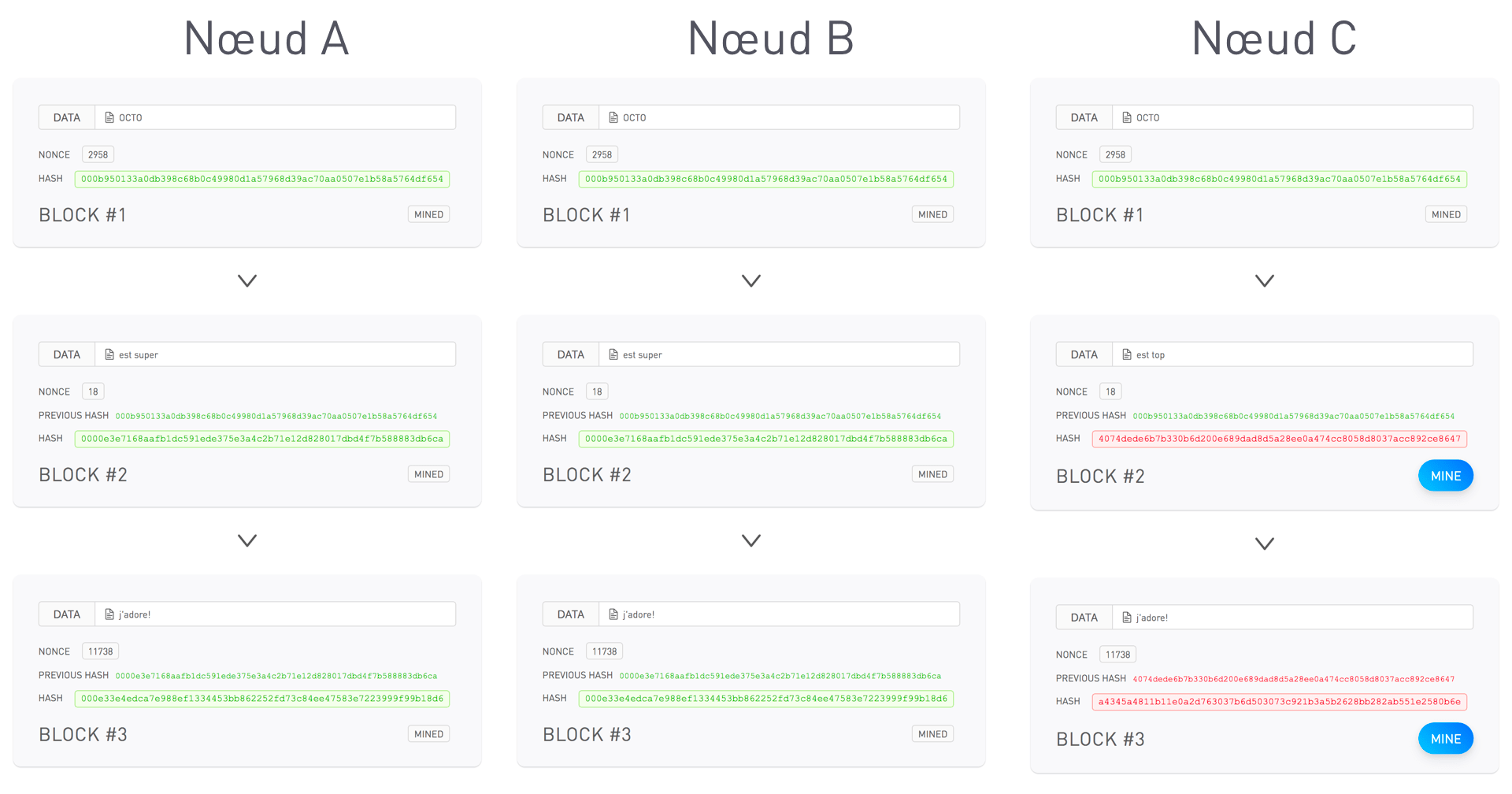
L’atelier se poursuit avec le déroulement des questions ouvertes évoquées précédemment puis par une explication des différents types d’erreurs de machine learning. On évoque et explique également différentes terminologies (faux positif, vrai positif, etc par exemple), en fonction du cadre choisi (classification, régression, etc), qui seront utilisées ultérieurement dans le vrai cas client. Expliquer ces différentes notions permet de s’assurer que tous les participants de l’atelier aient une compréhension globale et uniforme des termes employés et de la finalité du Machine Learning. Par exemple, on définit un faux positif comme étant un faux problème détecté et un faux négatif comme une non détection d’un problème.
Pour rendre les explications parlantes, il est préférable d’illustrer avec, dans le cas d'une classification, par exemple la matrice de confusion d’un modèle :
Introduction aux notions de classification en ML
Lors de la configuration de l’algorithme, nous chercherons à l’optimiser pour qu’il tende soit à détecter le plus d’animaux possibles, et donc maximisant les erreurs catégorisées Faux problème, soit qu’il ne fasse aucune erreur sur les prédictions qu’il émet, erreurs de type Problème non-perçu.
On expliquera alors que dans le cas du Problème non-perçu, le système manque beaucoup de défauts tandis que dans le cas du Faux problème, le système lève beaucoup de fausses alertes.
Cet exemple permet alors d’expliquer qu’un système intelligent commet toujours des erreurs et qu’en règle générale, il y a un compromis à effectuer entre deux types d’erreurs.
Chaque cas d’usage étant différent, le curseur doit être positionné de la meilleure façon. Pour cela, il est important de raisonner en termes de coût engendré par chaque type d’erreur que l’on pourra pondérer par le nombre d'erreurs plutôt qu’uniquement la quantité d'erreurs.
C’est donc à cette étape de l’atelier de matrice d’erreur que l’on sensibilise le public aux imperfections des systèmes de machine learning et que l’on introduit la notion de compromis en vue d’atteindre certains objectifs de cet atelier (cf liste des objectifs listés plus haut).
Une dizaine de minutes peuvent être nécessaires pour donner ces explications.
Cas pratique
Dot-voting
Une fois les notions nécessaires posées, le reste du temps est réservé aux situations sur lesquelles l’algorithme va prendre une décision, dans le contexte du projet. Par exemple, dans le cas d’une :
- Classification binaire :
- 5 exemples de FP, 5 exemples de FN
1. FP : un animal est détecté par l’algorithme, alors que la photo n’en comporte pas\.- FN : un animal est bien présent sur la photo, mais l’algorithme ne le détecte pas.
- ...
- 5 exemples de FP, 5 exemples de FN
- Classification multi-classes (A, B, C) :
- 5 exemples Prédiction=A, Réalité=B
- 5 exemples Prédiction=A, Réalité=C
- ...
- Détection d’objet :
- 5 exemples avec trop de boîtes
- 5 exemples avec trop peu de boîtes
Il est intéressant, dans certains cas, de multiplier les exemples d’erreurs tout en les adaptant, si nécessaire, pour faciliter leur lecture et leur compréhension. Par exemple, dans le cas d’une classification multi-classe, si la combinatoire est trop grande, il est préférable de supprimer certaines classes. Il vaut mieux bien apprendre sur un sous-ensemble du problème qu’être vague sur tout l’ensemble du problème.
A l'issue de chaque cas présenté, les participants doivent émettre une évaluation sur une échelle de 1 (peu grave) à 4 (grave). Un format devra être pensé, par exemple:
- Un format de vote (numérique ou physique)
- Individuel pour éviter les effets de groupe et biais de confirmation
- Avec possibilité de revoir l’ensemble de ses votes avant de confirmer
- Avec un nombre total limité de “points de gravité” par participant
- Qui permet de rapidement consolider les votes pour chaque exemple afin d’éviter un flottement dans l’atelier
Explication des résultats
Avec cette étape, nous cherchons à atteindre les objectifs restants de cet atelier à savoir identifier les critères d’évaluation métier et identifier les erreurs qui sont le moins contraignantes dans la solution à développer mais également les éventuelles divergences.
Pour récupérer une information claire de l’étape de dot voting, il convient de revenir sur les votes des participants et de les inciter à expliquer leurs votes mais également à commenter les votes des autres participants.
Pour ce faire, on parlera d’abord du cas pour lequel le plus de participants étaient en accord. Puis à l’inverse, le cas le plus divergent. Des questions ouvertes peuvent être posées telles que :
- Quels sont les critères communs ?
- Y a-t-il un ou des cas qui vous ont semblé absurdes ?
- Y a-t-il des cas que vous rencontrez habituellement et que nous n’avons pas vus ici ?
- Quel était l’exemple le plus facile à noter ? Le plus difficile ?
On conçoit de cette façon un prototype du meilleur système, selon les participants.
Cas d’usage
Cet atelier de matrice a déjà pu être expérimenté notamment dans le cadre d'un projet de réalisation pour l’éducation routière et le permis conduire.
Pour mieux anticiper les demandes de créneau des candidats au permis de conduire, un modèle de machine learning doit être mis en place afin de prédire 3 éléments : le nombre de créneau à ouvrir, pour chaque semaine, pour les différents centres d’examens.
Questions abordées pendant l’atelier :
Au cours de l'atelier, des questions ouvertes sont formulées par les animateurs de l’atelier sur lesquelles les participants sont invités à réfléchir et répondre. L’objectif de ces questions ouvertes est de comprendre :
- Comment fonctionne le système actuel :
- Comment est effectué le choix d’ouvrir ou non des créneaux ?
- Comment les différents permis sont priorisés ?
- Quels sont les douleurs actuels :
- Quelle est la décision la plus difficile à prendre lorsque vous allez ouvrir une journée d’examen ?
- Comment les performances du système sont évaluées :
- Comment savez-vous que vous avez fait le bon choix ?
- Comment est-il possible d’améliorer l’existant :
- Comment un outil informatique peut-il vous aider ?
Ces différentes questions permettent de comprendre le comportement général de la solution existante et de découvrir le métier.
Également, pour mieux cerner les attentes des experts métiers et des utilisateurs vis-à-vis de la solution, il est demandé aux participants de l’atelier de juger, avec leur connaissance du métier, différentes erreurs commises par des modèles de ML répondant à la problématique et de spécifier celles qui devraient être les plus évitées. Pour ce faire, trois exemples sont présentés.
Dans le premier exemple, les prédictions portent sur le nombre de places à ouvrir pour une date donnée. Le premier modèle présenté prédit de petits intervalles de places, assurant ainsi un nombre restreint de places ouvert en surplus. Cependant, pour certaines semaines, les plages de places prédites sont bien trop petites, manquant ainsi le nombre de places nécessaires à ouvrir pour pouvoir répondre à la demande.
Dans le deuxième cas de figure, le scénario inverse est présenté. Le modèle prédit de plus grands intervalles, ne manquant ainsi jamais le vrai nombre de places nécessaire et répondant donc toujours à la demande. Toutefois, le modèle prédit bien plus de place que nécessaire).

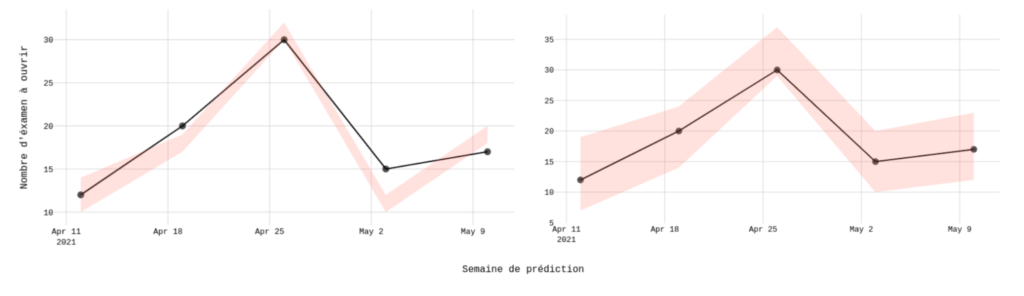
Le deuxième scénario quant à lui interroge les capacités du modèle à prédire correctement les dates d’ouvertures. Pour le premier modèle, les dates sont prédites en retard par rapport à la réalité, tandis qu’elles sont prédites en avance par le deuxième modèle présenté.
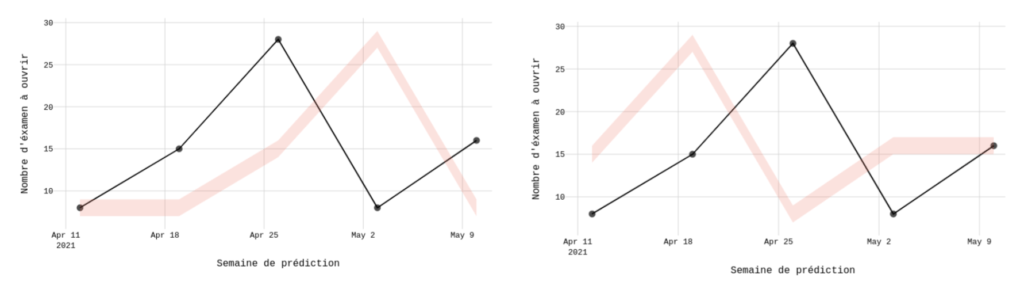
Enfin, le dernier cas questionne la précision des prédictions pour le type de centre d’examen (grand ou petit). Dans un premier cas, le modèle prédit de façon juste le nombre de places à ouvrir lorsque la prédiction porte sur des petits centres d’examens et, à contrario, pour les plus gros centres d’examens, les prédictions sont incorrectes. Inversement dans le second cas.
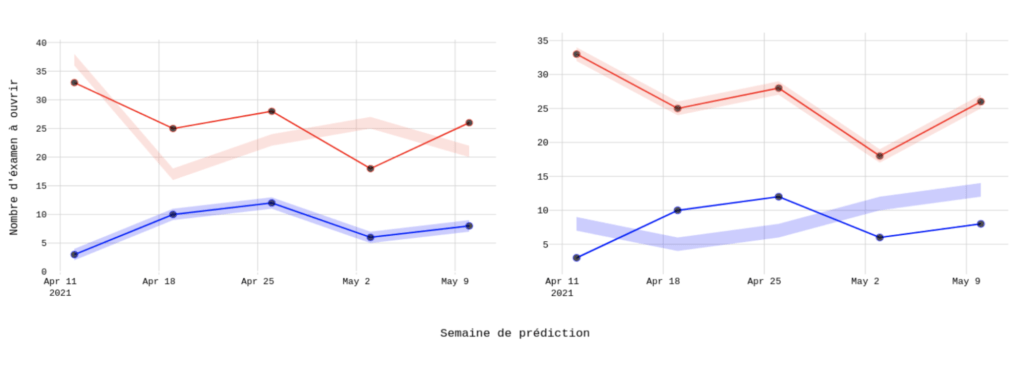
Illustrer les erreurs de la façon la plus interprétable possible permet de capturer des règles métiers et d’obtenir des renseignements sur le comportement général attendu de la solution. Ces informations permettent de formaliser des critères d’appréciations et donc d’adapter la solution aux besoins exprimés.
D’autres résultats, à posteriori de l’atelier, peuvent être obtenus.
Résultats a posteriori
Les retours participants ont été excellents en fin d’atelier. Au début, nous avons perçu que les participants ne savaient pas exactement à quoi s’attendre face à l’atelier mais le fait de présenter les objectifs et le déroulé permet d’enlever ce flou.
Lorsque l’atelier a démarré, les participants y ont spontanément pris part et cela nous a permis de tirer un maximum de valeur à chaque étape et eux une compréhension progressive des enjeux. Avec de nombreux supports visuels et des explications précises, nous avons passé très peu de temps à répondre à des questions et plus de temps à débattre. Tout au long de l’atelier, nous avons remarqué un tel engouement qu’il fallait parfois intervenir pour pas que les débats s’éternisent. Chacun a pu donner son avis et cela nous offre plus de perspectives. Par exemple, nous avons découvert que pour les grands centres d’examen il est important d’avoir une prédiction légèrement supérieure plutôt qu’inférieure à la vraie valeur alors que c’est le constat inverse pour les petits centres. On en ressort que tout le monde n’était pas forcément d’accord sur leurs attendus mais l’atelier a donc permis de discuter de ces différences. Cela nous permet de trouver des attentes communes et de réfléchir à la réponse qu’on peut apporter sur celles qui diffèrent.
Par ailleurs, le public a été très réceptif aux imperfections du ML et ont très vite compris que celui-ci n’est pas une science exacte. La crainte sur l’utilisation de l’outil s’efface au cours de l’atelier pour laisser la place à la compréhension que l’outil est à leur service qu’ils peuvent choisir de suivre ou non. Malgré les niveaux différents, on remarque qu’il y a une compréhension uniforme du ML à la fin de l’atelier.
Ainsi les participants ont vraiment apprécié l’atelier et certains auraient aimé qu’il dure un peu plus longtemps afin de pouvoir continuer à en discuter.
De notre côté, nous avons énormément appris lors de cet atelier. Nous avons pu tirer un maximum d’informations et cela nous simplifie notre phase de développement car cela nous a permis d’appréhender la plupart des interrogations que nous avions en amont de cet atelier.
Conclusion
Nous avons donc vu au cours de cet article que l’atelier de matrice d’erreur se veut complet en mettant l’utilisateur au centre afin que nous définissions ensemble le produit qui lui sera utile. De plus, il permet le partage au métier utilisateur du produit quelques connaissances afin qu’ils puissent saisir l’apport de la data science et en particulier du Machine Learning tout en augmentant confiance en cette science complexe. Le métier va également pouvoir poser des mots sur des intuitions par exemple lorsqu’il classifiait des images contenant des animaux aidant ici le data scientist dans la modélisation du problème.
Enfin, cet atelier permet d’ouvrir le dialogue, et joué régulièrement, de garder cette compréhension partagée indispensable à la gestion d’un modèle de ML en production.