La vie après le théorème CAP – Compte-rendu du talk de Borémi Toch & Stéphane Lundy à La Duck Conf 2018
tl;dr (a.k.a “take aways”) :
- Vous ne pouvez pas vous permettre de ne pas vous poser les question autour de la partition, parce que le réseau est fondamentalement non fiable (notamment à cause de la latence). Votre système doit les prévoir, voire les tolérer.
- Le théorème CAP est un beau modèle théorique et mais n'est pas applicable en pratique. Il est intéressant pour les questions qu’il soulève et le compromis qu’il amène à considérer. La solution pratique est complexe, et vous devez envisager votre propre stratégie de réconciliation suite à une partition d’un point de vue métier.
Pourquoi un talk sur un théorème ? Parce que même si un théorème est quelque chose de très formel, très précis et souvent ardu, il y a donc des choses à en tirer.
De nos jours “distributed is becoming the norm” : tout le monde veut de l’élasticité, de la haute disponibilité et de la résilience (à défaut d’avoir besoin). Les systèmes distribués – bien que complexes – sont donc de plus en plus répandus.

La théorie
Le théorème CAP est historiquement parti d’une conjecture par Eric Brewer : un système ne peut être à la fois cohérent (“Consistent”), disponible (“Available”) et tolérant à la partition réseau (“Partition tolerant”). Il est possible de n’avoir que deux de ces propriétés en même temps.
Le théorème a été formellement prouvé par la suite par Gilbert et Lynch.
Cohérence (linéarisabilité) : toute lecture qui suit une écriture doit renvoyer la valeur de cette dernière, ou une valeur plus récente.
Disponibilité : les noeuds disponibles du système doivent répondre à toute requête.
Tolérance à la partition réseau : le système doit tolérer les partitions réseau (lorsque deux sous parties du système ne peuvent plus se coordonner).
L’impossibilité prouvée par le théorème CAP ne s’applique que dans le cadre d’un réseau asynchrone, c’est-à-dire sans limite de temps pour l’acheminement des messages.
CAP dans la vraie vie
En 2012, Brewer revient sur son travail dans un article “CAP twelve years later. How the rules have changed.” (autre article intéressant qui apporte une perspective plus rigoureuse de la perspective sur CAP, en 2015 par Martin Kleppmann “A critique of the cap theorem”).

Le théorème CAP à quelques limites :
- il ignore la latence du réseau : en pratique il est impossible de détecter un noeud indisponible ou un état de partition de manière instantanée,
- en pratique un concepteur de système ne peut se permettre de ne pas tolérer les partitions puisque le réseau n’est pas fiable,
- le théorème dit qu’on ne peut pas avoir C, A et P simultanément et de manière parfaite, mais en fait les cas intermédiaires sont acceptables si on relâche plus ou moins certaines contraintes.
Si vous construisez un système distribué, concrètement, quelles sont les questions que vous devez vous poser :
- “Que devrait faire le système lorsqu’une partition se produit ?”
- “Comment choisissons-nous de résoudre les conflits suscités par une partition qui se termine ?” : deux parties du système ont divergé sur une ou plusieurs valeurs, et il y a plusieurs manières de les réconcilier (le dernier qui parle a gagné, on appelle un être humain et on lui demande de choisir...)
- “Est-ce que la probabilité qu’une partition se produise vaut le coût d’ingénierie ?”
BOTTOM LINE => ce sont des questions business
Des systèmes distribués que nous avons déjà tous rencontrés
Git : dans git il y a partition dès que deux branches sont tirées en parallèle et modifient la même valeur. Git est tout à fait capable de résoudre les conflits, et lorsqu’il n’y parvient pas il fait appel à un être humain pour décider (c’est la résolution de conflits pendant un merge).
Bases de données relationnelles : elles gèrent les partitions d’une manière différente, via des stratégies de concurrence qui peuvent être soit optimistes soit pessimistes.
Autres exemples : un répertoire partagé, édition partagée de documents, blockchain…
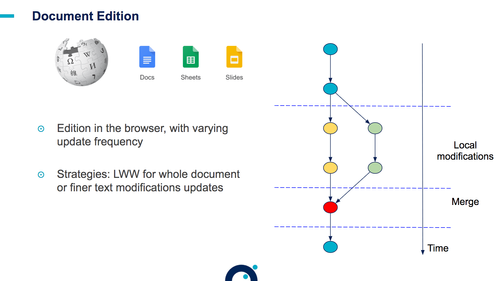
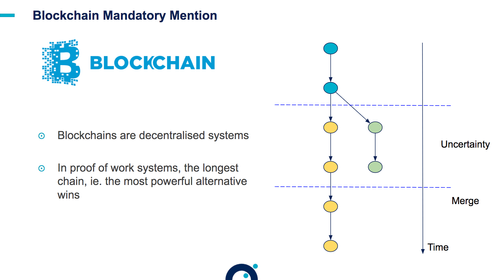
Voir la présentation complète du talk sur slideshare.
Partitions dans la vraie vie
Un site e-commerce
Un article est vendu mais s’avère en réalité indisponible. Que faire ? On pose la question au métier : si on est en période de rush, le métier peut considérer que l’erreur de stock est acceptable, et on peut proposer un bon d’achat au client dont la commande n’a pas été honorée.
Timeline Facebook
Ce que vous voyez sur votre mur est une liste d’évènements, et Facebook veut être absolument certain que les évènements qui s’affichent devant vos yeux sont ceux que vous devez voir (ex. : votre grand mère ne voit pas vos photos de soirées étudiantes). C’est une autre manière de dire qu’ils préfèrent la cohérence (consistency) à la fraicheur et donc la disponibilité (availability) de l’information.
Le feed Twitter
Les choses sont différentes car les tweets ont une forme de durée de vie, et Twitter préfère qu’un tweet soit disponible rapidement pour qu’il puisse être partagé, tant pis si un tweet n’aurait pas dû être publié (offensant etc.). Ils se sont dotés de mesures pour gérer les tweets problématiques après leur publication. C’est une autre manière de dire que Twitter préfère la fraîcheur (une forme de disponibilité) à la cohérence.
Pour aller plus loin
Les CRDTs sont une approche élégante pour éviter les conflits de partitions.
Spanner propose un service proche de contredire le théorème CAP, pas de manière parfaite car c’est impossible, mais de manière si parfaite que vous ne pouvez pas le remarquer (ceci n’est possible que parce que Google possède la maîtrise de son réseau et des horloges de très haute précision à l’échelle du globe)