La technologie GPGPU – 2ème partie : CUDA et Kepler

Dans ce deuxième article dédié à la technologie GPGPU (le premier est ici), je m’intéresse à l'architecture matérielle dont je vais présenter les concepts fondamentaux et l'architecture logicielle CUDA permettant d’exploiter les GPU. Ensuite, j’aborderai quelques notions matérielles des GPU Nvidia de dernière génération.
A l’origine, un GPU est spécialisé dans le rendu graphique, conçu pour supporter un parallélisme de masse et créer autant de threads que possible (centaines de cœurs et milliers de threads).
Alors que les CPUs sont conçus pour exécuter un seul thread, contenant des instructions séquentielles à une cadence élevée, les GPUs sont conçus pour exécuter en masse des instructions en parallèle dans de nombreux threads. Notons qu’un thread sur un GPU n’a pas tout à fait le même sens qu’un thread CPU. C’est un élément de base pour les données à traiter, la plus petite subdivision d’une tâche à effectuer.
Architecture d’un GPU Nvidia
La dernière architecture en date de la firme de Santa Clara se nomme Kepler. Un GPU est composé 15 Streaming Multiprocessors (SMX). Chaque SMX se compose de 192 Streaming Processors (SP) et d’un espace de mémoire partagée servant de cache. Un SP représente un cœur au sens GPU, soit 2880 au total pour l’architecture Kepler. Le GPU peut supporter jusqu’à 6 GB de GDDR5.
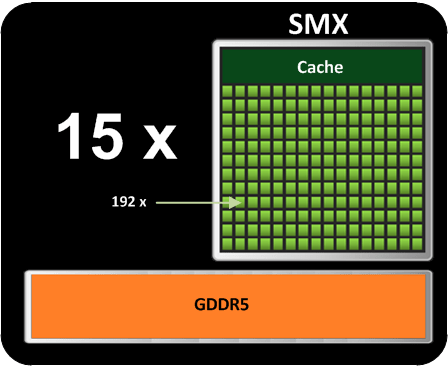
Architecture Kepler
Pour pouvoir faire du traitement sur un GPU, Nivida offre CUDA. Derrière cette technologie, se cache une couche logicielle destinée au stream processing : paradigme de programmation lié au mode SIMD (Single Instruction Multiple Data) permettant à certaines applications d’exploiter la programmation parallèle.
Quelques notions sur CUDA
CUDA est composé d’un Framework, d’un ensemble d’outils et d’une extension du langage C. Grâce à CUDA, le développeur peut utiliser la puissance de calcul d’une carte graphique pour certaines opérations destinées à être traitées par le GPU au lieu du CPU. Ce dernier est d’ailleurs toujours nécessaire pour coordonner le travail CPU et GPU. Le GPU est ainsi vu comme un coprocesseur massivement parallèle très bien adapté au traitement d'algorithmes parallélisables, très mal aux autres. Une opération destinée au GPU est appelée un kernel.
L’exécution d’un programme CUDA s’effectue de la façon suivante :
- Le programme est exécuté par le CPU
- Un kernel est invoqué, son exécution se déplace sur le GPU
- Un grand nombre de threads sont générés et exécutés en parallèle sur le GPU
L’API CUDA permet de répliquer au niveau logiciel les spécificités de l’architecture matérielle GPU et de gérer la communication entre CPU et GPU. Cela permet de voir logiciellement le GPU comme une grille de calcul à une ou deux dimensions, formée de blocs de calcul indépendants.
Chacun de ces blocs est physiquement lié à un SMX et est décomposé en une matrice de threads à une, deux ou trois dimensions. C’est au développeur d’organiser les blocs sur la grille et de déterminer la dimension et la taille des blocs selon les caractéristiques de son application. Par exemple, si je veux multiplier deux matrices, je choisirai des blocs à deux dimensions, à trois dimensions si je fais une opération sur des volumes.
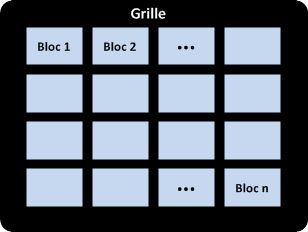
Vue logicielle d’un GPU : Grille
L’exécution des threads d’un même bloc est regroupé en paquets appelés warp (ensemble de 32 threads). Chaque thread dans un bloc exécute une instance d’un kernel et a des coordonnées dans ce bloc. Un bloc possède aussi des coordonnées dans la grille. Cela permet de distinguer chaque thread les uns des autres pour identifier la partie de travail qui lui revient.
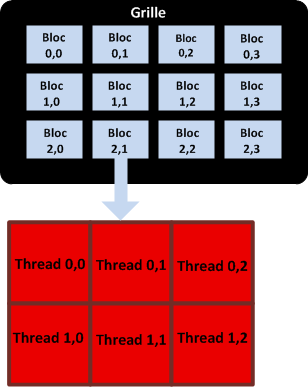
Coordonnées des blocs sur la grille et des threads dans un bloc
La hiérarchie des threads permet de comprendre la cartographie des processeurs sur un GPU :
- Le kernel est invoqué par le CPU et exécuté par le GPU. Les dimensions de la grille doivent être spécifiées au lancement du kernel. La grille, de dimension (x,y) est telle que 1 <= x et y <= 65 536.
- Chaque SMX ordonnance et exécute 4 warp de manière concurrente, soit 32 x 4 x 15 = 1 920 threads max exécutés en parallèle sur un GPU Kepler.
- Le SMX peut traiter 2 instructions indépendantes par warp, soit 2 x 4 = 8 instructions traitées en parallèle par cycle d’horloge, pour chaque SMX, d'où 120 par GPU.
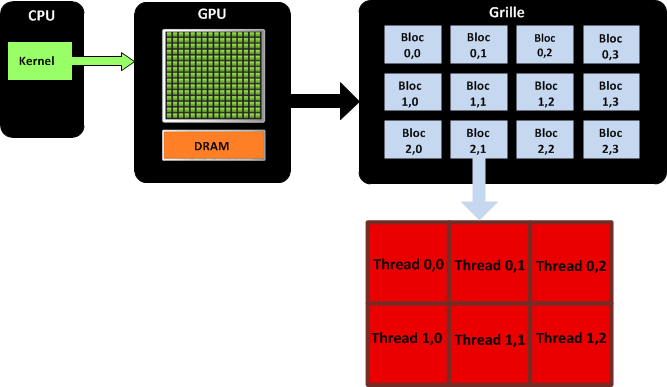
Modèle de threads CUDA
Compilation CUDA
Un programme CUDA est composé de deux parties, une s’exécutant sur le CPU (host) et un autre sur le GPU (device). C’est la partie parallèle (kernel) qui s’exécute sur le device. Le code GPU est composé de fonctions essentiellement en C avec des annotations pour le distinguer du code CPU, d’autres pour distinguer les différents types de mémoire GPU.
Le compilateur CUDA NVCC sépare les fonctions du host et du device. Il en résulte :
- Du code C standard ANSI/ISO
- Du code PTX (Parallel Thread eXecution)
Le langage machine GPU est obtenu en deux étapes. La première étape est la traduction du code « haut-niveau » en langage intermédiaire PTX par le compilateur NVCC (NVIDIA Compiler Collection). Ce code PTX permet d’abstraire le GPU et de le voir comme une grille de threads. L’architecture et les capacités des GPU changeant souvent, il est nécessaire d’avoir une compilation flexible non dépendante des caractéristiques physiques du GPU pour garantir la compatibilité. La deuxième étape est la traduction du code PTX en langage machine. Au premier appel de l’application, le code PTX est compilé en code binaire pour le GPU spécifique à la machine en utilisant le compilateur JIT du runtime CUDA. Le code binaire est ensuite exécuté par le périphérique.
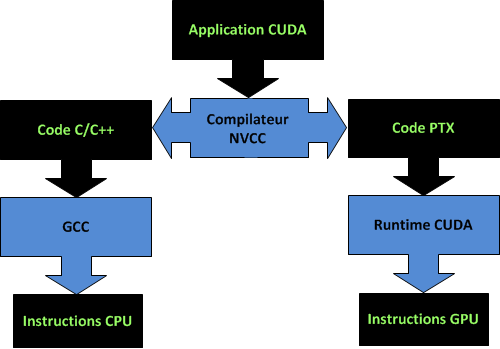
Pipeline de compilation CUDA
Modèle mémoire d’un système hybride
Pour comprendre certaines problématiques liées à la programmation CUDA, il faut expliquer le modèle mémoire dans un système hybride CPU/GPU.
Le host et le device ont des espaces mémoires séparés. Typiquement, le device est une carte matérielle embarquant sa propre mémoire DRAM (les autres types de mémoire seront détaillés dans un prochain article). Pour exécuter un kernel, le développeur doit lui-même allouer de la mémoire sur le device et transférer les données pertinentes du host vers le device. De même, après l’exécution du kernel, il doit transférer le résultat du device vers le host et libérer la mémoire du device dont il n’a plus besoin. Le runtime CUDA fournit une API pour ces opérations.
Cependant elles ont un impact sur les performances, tout le travail exécuté à partir du CPU sur le GPU, retourne le résultat au CPU. Ce résultat peut-être une partie d’une solution plus globale ou éventuellement être analysé par le CPU pour ensuite invoquer d’autres kernels...multipliant les échanges entre CPU et GPU.
Or, le principal goulet d’étranglement dans les traitements GPU est le plus souvent la bande passante du bus de communication entre le CPU et GPU. Un GPU dispose d’une puissance de traitement tellement énorme qu’il est impossible de lui fournir les données suffisamment vite pour exploiter cette puissance. Il est donc nécessaire d’avoir des techniques permettant de réduire le trafic entre mémoire CPU et GPU.
Le parallélisme dynamique introduit avec Kepler permet de réduire ces impacts.
Parallélisme dynamique
Dans la programmation CUDA, il était impossible d’exécuter des kernels de manière récursive, multipliant les va-et-vient avec le CPU.
Le parallélisme dynamique, nouveau dans l’architecture Kepler permet de les limiter. Un kerneI peut dorénavant générer son travail lui-même, le contrôler et synchroniser les résultats sans impliquer le CPU. Il est désormais possible à un kernel parent d’exécuter un kernel enfant jusqu’à une profondeur maximum de 24.
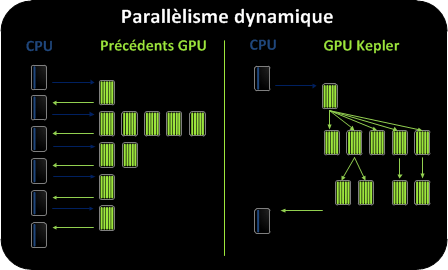
Le parallélisme dynamique permet à une plus grande diversité de programmes d’être implémentée sur le GPU. Des algorithmes nécessitant précédemment d’éliminer la récursivité, les structures de boucles irrégulières ou d’autres structures non adaptées peuvent être implémentés plus facilement. Le déroulement du programme est contrôlé dans un Kernel, réduisant le trafic PCI dans le cas où des données auraient eu besoin d’être copiées et retournées au CPU.
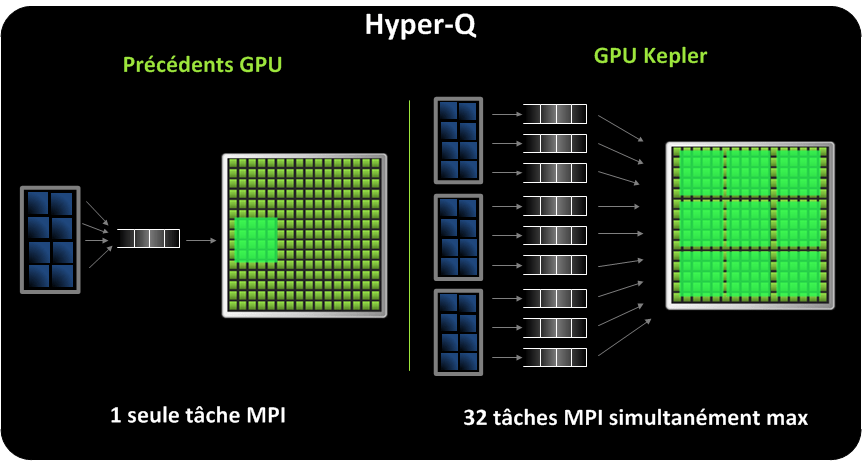
Hyper-Q
Un des challenges dans le passé était de fournir au GPU une charge de travail optimale à partir de multiples flux. Jusqu’à maintenant, une seule connexion hardware était possible entre le host CPU et device GPU. Tous les processus MPI étant dans une seule queue, cela limite la charge de travail pouvant être exécutée simultanément.
Kepler progresse dans ce domaine avec Hyper-Q. Il augmente considérablement le nombre de connexions entre host de device avec 32 connexions hardwares simultanées. Chaque processus MPI peut être assigné à une queue, maximisant l’utilisation du GPU.
L’acteur le plus crédible sur le marché du GPGPU est incontestablement Nvidia. La firme de Santa Clara propose une architecture matérielle en constante évolution. Avec l’architecture Kepler, Nvidia renforce sa position dans l’industrie du HPC. Certaines limitations liées à un modèle où CPU et GPU travaillent ensemble sont résolues. La barre du Téra flop est atteinte avec cette dernière mouture. Est-ce suffisant pour contrer l’attaque d’Intel et son Xeon Phi tout juste sorti des cartons, après deux ans d’attente ? Dans le prochain et dernier article de la série, je rentrerai dans les détails de la programmation CUDA pour présenter les principes fondamentaux.