La pyramide des tests par la pratique (2/5)
Dans le précédent article, nous avons abordé la théorie autour de la pyramide des tests : quelle stratégie adopter pour assurer la qualité et la non-régression de notre application pour un coût raisonnable. Nous avons notamment abordé la notion de feedback et l’importance d’avoir des feedbacks rapides, précis et fiables. Les tests unitaires remplissent typiquement ces critères pour un investissement modéré. Au travers de cet article et d’un exemple concret, nous allons détailler la mise en pratique de tests unitaires automatisés et nous tenterons de répondre aux questions récurrentes de nos clients.
Mise en pratique
"La différence entre la théorie et la pratique, c'est qu'en théorie, il n'y a pas de différence entre la théorie et la pratique, mais qu'en pratique, il y en a une."
Jan Van de Snepscheut
Passons maintenant à la pratique. Pour ce faire et pour compléter notre panorama des tests, nous allons prendre l’exemple de microservices. Ce choix n’est bien sûr pas anodin. Les microservices ont pour vocation d’être le plus autonome possible (équipe, couplage, déploiement, …) et cette autonomie s’acquiert également au travers des tests : les tests d’intégration ou de bout en bout sont assez peu appropriés si l’on souhaite déployer en continu notre (micro-) service indépendamment des autres.
Exemple
Le schéma suivant décrit succinctement l’architecture de notre exemple :
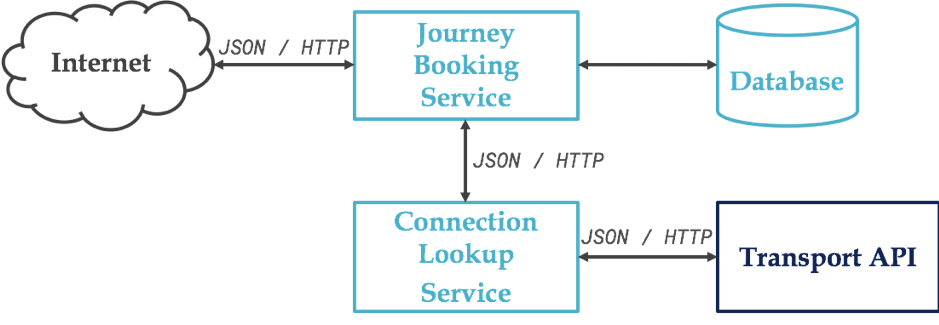
Puisque c’est d’actualité en France au moment ou j’écris ces lignes, j’ai décidé de créer un ensemble de services pour rechercher et réserver des voyages en train, mais plutôt que d’utiliser l’API de la SNCF, je suis parti sur une Open API Suisse : https://transport.opendata.ch/. Cette dernière nous fournira les trajets et horaires.
Le service Connections Lookup est une façade vers cette API et permet de se découpler vis-à-vis de ce service externe. L’intérêt dans cet article est plus pédagogique, mais nous y reviendrons.
Et enfin le cœur du système, le service Journey Booking en charge de rechercher des trajets et d’en enregistrer en base de données. Les endpoints sont les suivants :
GET /journeys/search?from=...&to=...qui est probablement mal nommé puisqu’il permet de rechercher des trajets disponibles et non des trajets déjà réservés (c’est le point d’entrée pour le service de Lookup).
GET /journeysqui donne la liste de tous les trajets réservés
GET /journeys/{id}qui donne le trajet dont l’id est passé dans la requête
POST /journeysqui permet de réserver un trajet
PUT /journeys/{id}qui permet de modifier une réservation
DELETE /journeys/{id}qui permet de supprimer le trajet dont l’id est passé dans la requête
Ces 5 derniers endpoints vont bien entendu interagir avec une base de données (disons Postgres).
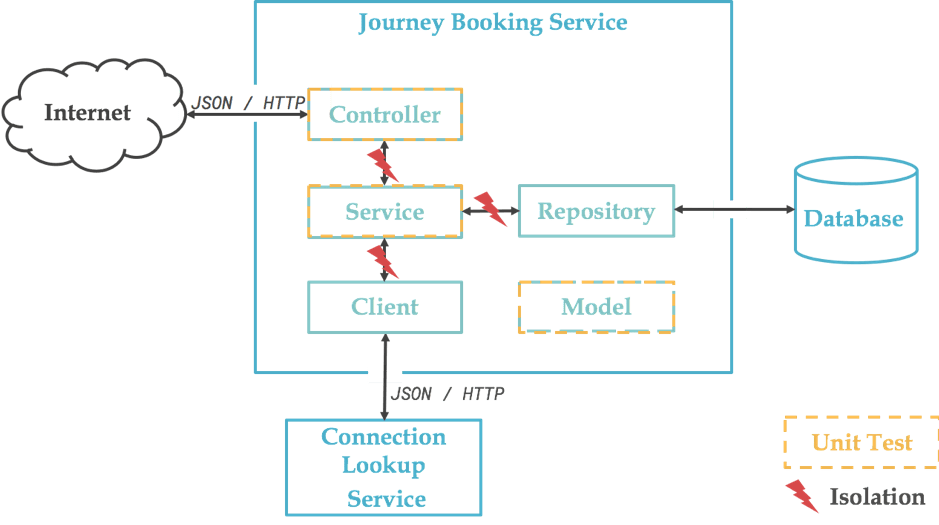
Notre microservice de réservation est structuré comme dans le schéma suivant, rien de plus standard. L’exemple étant simpliste et le code métier réduit au minimum, tout faire depuis le Controller serait justifié, mais gardons notre service pour l’exemple et voyons où cela nous mène...
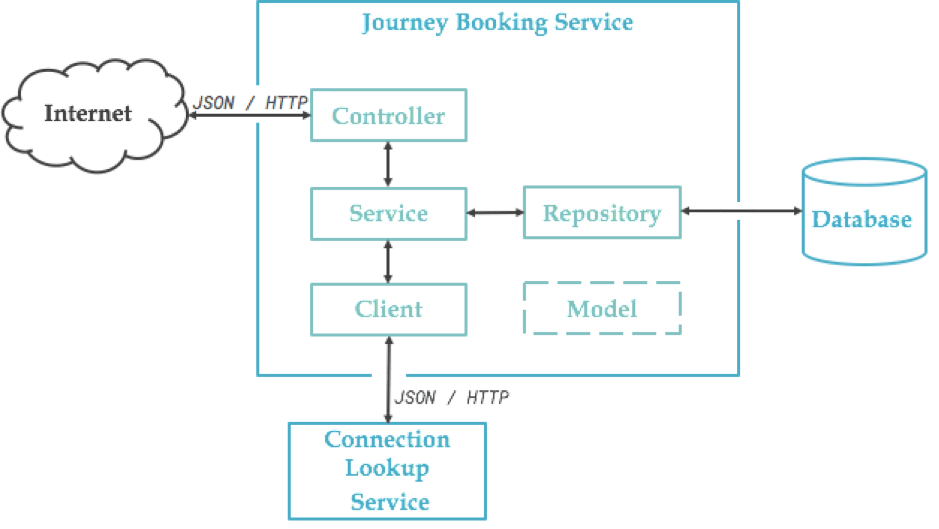
Côté techno, j’utiliserai également un standard : Spring et son ecosystème. Nombreuses sont les possibilités (annotations, utils) pour faire du test avec Spring et il est bon d’être au clair pour savoir quoi utiliser et quand. Le projet complet est disponible sur gitlab.
Tests unitaires
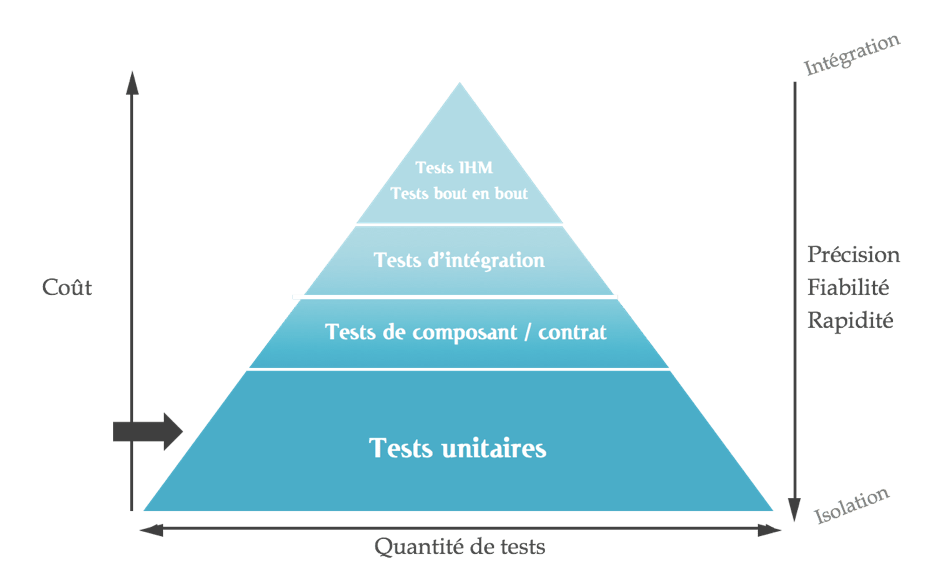
Nous allons commencer par la base de la pyramide, les tests unitaires. Un test unitaire vise à valider un comportement unique (méthode ou sous ensemble d’une méthode) issu d’un cas d’utilisation métier en isolation du reste du monde :
- des autres objets : instanciation, attributs, paramètres, …
- des autres systèmes : une base de données, un web service, l’heure du système, ...
- des autres tests : ordre des tests, données de test
Certains diront qu’il n’est pas nécessaire de tout isoler. Jay Fields, dans Working effectively with Unit Tests, introduit les notions de tests sociables ou tests solitaires. Personnellement je suis plutôt partisan d’isoler au maximum, pour éviter toute interférence. Pour simplifier, un test unitaire est indépendant de toute entrée/sortie : base de données, file system, réseau, …
Pour ce faire, on utilisera ce que certains appellent des bouchons, d’autres des stubs, ou encore des mocks, des fakes, … bref ce que la littérature appelle des Test Double (Doublure pour les Tests, en français). Il s’agit d’un objet sur lequel nous avons le contrôle et qui va se substituer à une dépendance de notre objet testé et nous permettre de valider différents comportements attendus en fonction des retours de la doublure (cas nominal, aux limites ou d’erreurs).
S’il est possible de les développer à la main, de nombreuses librairies sont également disponibles : Mockito, EasyMock ou JMockit pour les plus connus dans le monde Java.
Que tester ?
Si on reprend notre schéma précédent, ou voudrait logiquement tester unitairement chacun des objets qui constituent notre composant :
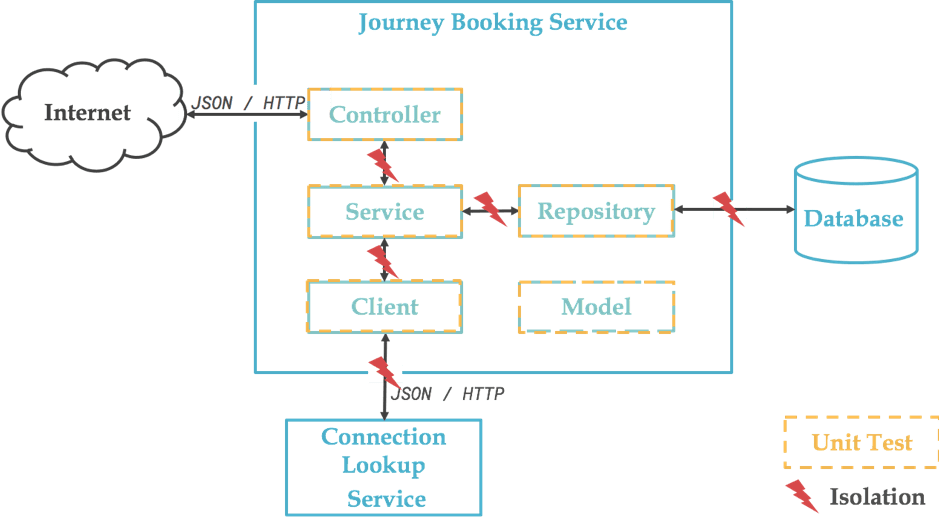
En vérité, le Client étant implémenté avec la librairie Feign, autant dire qu’il n’y a pas vraiment de code à tester unitairement :
De même pour la partie Repository, basée sur Spring Data et qui ne comporte donc aucun code :
Nous reviendrons donc sur ces deux éléments pour les tests d’intégration, notre objectif n’étant pas de tester les frameworks sous-jacents (déjà bien testés par ailleurs).
Nous avons donc le schéma suivant :
Voici un extrait du Service (lien Gitlab) :
Et un extrait du Controller (lien Gitlab) :
Comme je le disais auparavant, le Controller semble presque être un simple passe-plat, presque…
Passe-plats
La question que beaucoup de clients nous posent est “est-ce que ça vaut le coup de tester un passe-plat ?”, ce à quoi je répond par une autre question “est-ce que ça vaut le coup d’avoir ce passe-plat ?”. Souvent là pour respecter un pattern de découpage en couche, il n’a d’autre objectif que d’être là “au cas où”...
La pratique de TDD (Test Driven Development) permet généralement d’éviter cela. Sans rentrer dans les détails de la pratique qui nous vaudrait un article complet, TDD vise à spécifier le comportement attendu via un test avant de l’implémenter effectivement. On écrit donc en premier lieu le test et ensuite l__e code le plus simple possible qui permette au test de passer__ et donc de satisfaire le comportement spécifié. Ainsi, on évite le sur-design, les couches “au cas où” et on se concentre sur le code le plus simple qui fournit rapidement le plus de valeur.
Dans notre exemple, si le controller semble n’avoir que peu de code, il a tout de même deux responsabilités : exposer des DTO en lieu et place des entités (conversion d’objets) et exposer l’API via l’utilisation d’annotations. Le code (même minime) sera donc testé unitairement et nous testerons l’exposition (mappings des urls, gestion des codes d’erreur, …) dans les tests de composants.
Méthodes privées
Parmi les questions récurrentes de nos clients également, “faut-il / comment tester les méthodes privées ?”.
- La réponse extrême est “non” : Si vous faites du TDD, les méthodes privées n’apparaissent qu’après l’étape de refactoring (red / green / refactor) et sont donc indirectement testées au travers des méthodes publiques.
- La réponse pragmatique est “non mais” : sur du code legacy, tester des méthodes privées peut être un moyen à court terme de poser un harnais de tests sur une classe avant de la refactorer (pour réduire sa complexité : trop de responsabilités, trop de dépendances…). Spring fournit une classe utilitaire (ReflectionUtils) pour simplifier l’écriture de ce genre de tests. À terme, après refactoring, ces tests devraient être supprimés, remplacés par des tests de méthodes publiques.
100% de couverture sinon rien
Grâce à des outils tels que Jacoco, Cobertura ou Clover, il est possible de déterminer quelle quantité de notre code est atteinte/couverte lors de l’exécution des tests. Au-delà du simple indicateur, cela nous permet de voir où le test est passé et surtout là où il n’est pas passé. On peut ainsi vérifier si des pans critiques de l’application ne sont pas testés.
Attention à cet indicateur qui peut s’avérer faux : il est en effet possible de couvrir 100% du code sans avoir rien testé (aucune assertion). Ne visez pas les 100%, concentrez-vous sur les parties critiques de l’application dans un premier temps et utilisez l’indicateur pour avoir une tendance (augmentation, diminution). Et si vous souhaitez aller plus loin et vous outiller, il est possible de faire du mutation testing, à savoir modifier plus ou moins aléatoirement le code métier et vérifier que les tests échouent. Si les tests continuent de passer, c’est probablement qu’ils ne valident pas suffisamment le code. Le framework Pitest permet d’automatiser cela en Java.
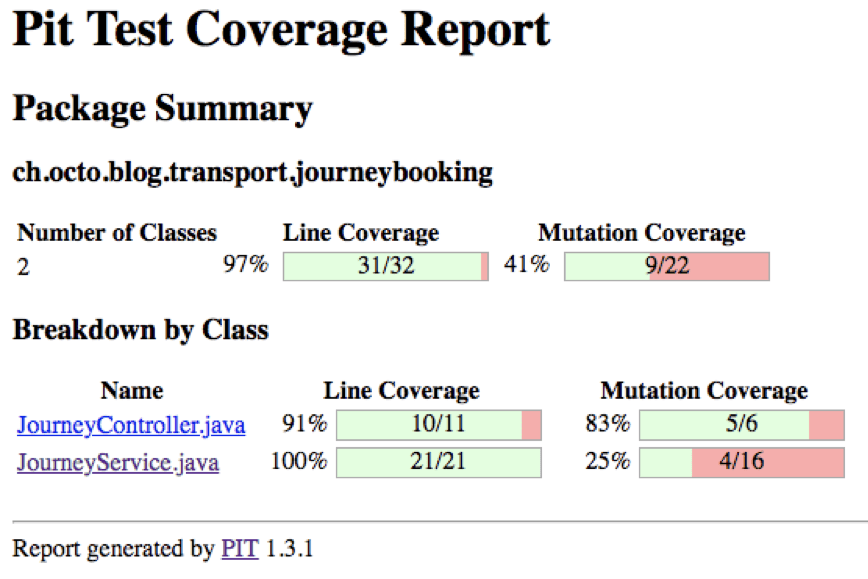
Par exemple, le rapport suivant indique que JourneyService (après avoir enlevé tous les assert) est couvert à 100% par les tests, mais qu’en termes de mutation, le score est plutôt mauvais.
Exemple de test “incomplet” :
Et le rapport associé :
Implémentation des tests unitaires
Nous utilisons JUnit, AssertJ et Mockito pour l’implémentation des tests et vous remarquerez qu’il n’y a pas de Spring à ce niveau de la pyramide. Voici donc un extrait des tests du Service (lien Gitlab) :
Plusieurs choses à noter dans ce code :
Le nommage des méthodes de test doit être explicite. Si un test échoue, on sait ainsi très vite quelle est la source du problème. Il n’y a pas de convention mais je conseille d’adopter la nomenclature suivante, verbeuse mais non ambiguë :unitUnderTest_ShouldExpectedBehavior_WhenInitialStateCertes nous ne respectons pas les conventions de nommage, mais le code de test doit être aussi maintenable sinon plus que le code métier. Le code de test documente ce que fait effectivement votre application (mieux que n’importe quelle documentation), alors autant qu’il soit compréhensible.
Afin d’être lisible également, vous pouvez adopter la structure standard suivante :
- Préparation de l’environnement de test, initialisation des données d’entrée.
- Exécution du comportement que l’on souhaite tester (généralement une méthode).
- Vérification des résultats obtenus.Personnellement, j’utilise quelques commentaires issus de la syntaxe Behavior Driven Development (BDD) : given, when, then pour structurer le test. Certains utilisent la règle des 3A: arrange, action, assertion. L’essentiel encore une fois étant d’avoir un code correctement structuré et lisible.
- Dans la même veine, j’utilise la classe org.mockito.BDDMockito qui adopte également la structure BDD. Ainsi Mockito.when est remplacé par BDDMockito.given et verify par then.
Autre point important dans cet exemple, Mockito est utilisé à la fois pour fournir un Stub (dans les deux premiers tests) et un Mock (dans le troisième). Sans rentrer dans les détails, le Stub n’est là que pour se substituer à une dépendance et permettre de valider que le système testé fonctionne. Le Mock, lui, permet de vérifier le comportement du système sous test : les interactions qu’il a avec ses dépendances. On vérifie que la dépendance a bien été appelée avec les paramètres attendus. Attention à l’utilisation des Mocks, les tests deviennent très étroitement liés à l’implémentation, ce qui peut vite virer au cauchemar.
Il va sans dire que ces tests doivent absolument être exécutés en continu au sein de votre pipeline de build, à chaque commit pour détecter au plus tôt les régressions.
Les tests unitaires permettent de valider les aspects métier de votre application (logique métier, algorithmes). Ils sont le harnais de sécurité pour toute modification du code (ajout de fonctionnalités, refactoring, corrections d’anomalies) et je n’insisterai jamais assez sur le fait qu’ils sont indispensables.
Nécessaires mais non suffisants, nous aborderons dans le prochain article les tests de composant, qui complètent parfaitement la panoplie de tests qu’il est bon d’avoir en sa possession.