La Grosse Conf 2025 - LangChain : OpenSource, compléxité et adaptation permanente

Lors d'une conférence technique captivante, Philippe, vétéran du développement avec 47 ans d’expérience, a partagé son expertise sur LangChain et les LLMs. Contributeur actif au projet, avec de nombreux pull-requests, il nous a offert un regard unique sur l'évolution du framework et ses bonnes pratiques d’utilisation.
Cet article abordera les points majeurs de son intervention, notamment :
- L’histoire et l’évolution de LangChain
- Les pièges du développement naïf
- Comment structurer efficacement son code avec LangChain
- Pourquoi l’exploration du code source est essentielle.
L’histoire et l’évolution de LangChain
Les origines
En novembre 2022, OpenAI lançait ChatGPT, déclenchant une vague d’intérêt sans précédent pour l’IA générative. L’API d’OpenAI permettait certes d’invoquer un modèle de langage, mais avec des limitations notables. Nous sommes à ce moment-là limités à 4096 tokens, et nous n’avons que des prompts textuels, pas encore d’analyse de fichier à télécharger.
Peu avant, Harrison Chase a créé LangChain, un projet open-source visant à normaliser l’interaction avec ces nouveaux modèles d’IA. L’objectif ? Fournir une API standardisée, capable d’unifier et de faciliter l’utilisation des concepts clés de l’IA générative, comme :
- Les prompts
- Les embeddings
- Les bases vectorielles
- Les retrievers
- Les loaders
- Les modèles
- Les output parsers
- …
Dès ses débuts, LangChain a su attirer l’attention, servant de support à de nombreux tutoriels et démonstrations. Son adoption massive en a fait une référence incontournable dans le domaine.
Une attraction obligatoire pour les acteurs de l’IA Générative
Rapidement, un phénomène s’est imposé : toute technologie liée à l’IA générative devait s’intégrer à LangChain pour être reconnue. Impossible de proposer une nouvelle base vectorielle ou un modèle sans assurer sa compatibilité avec le framework.
Face à cette explosion d’usage, LangChain a dû évoluer et structurer son approche. Les premiers composants, développés de manière empirique, sont devenus difficiles à maintenir. C’est ainsi qu’est né le LangChain Expression Language (LCEL), une nouvelle syntaxe visant à simplifier l’assemblage des différentes briques fonctionnelles du framework.
Avec LCEL, il est désormais possible d’écrire des chaînes de traitement sous une forme intuitive :
chain = prompt | modèle | parser
Cette approche favorise une composition modulaire des flux de traitement :
- Un prompt est envoyé au modèle
- Le modèle génère une sortie
- Un parser l’analyse et l’exploite.
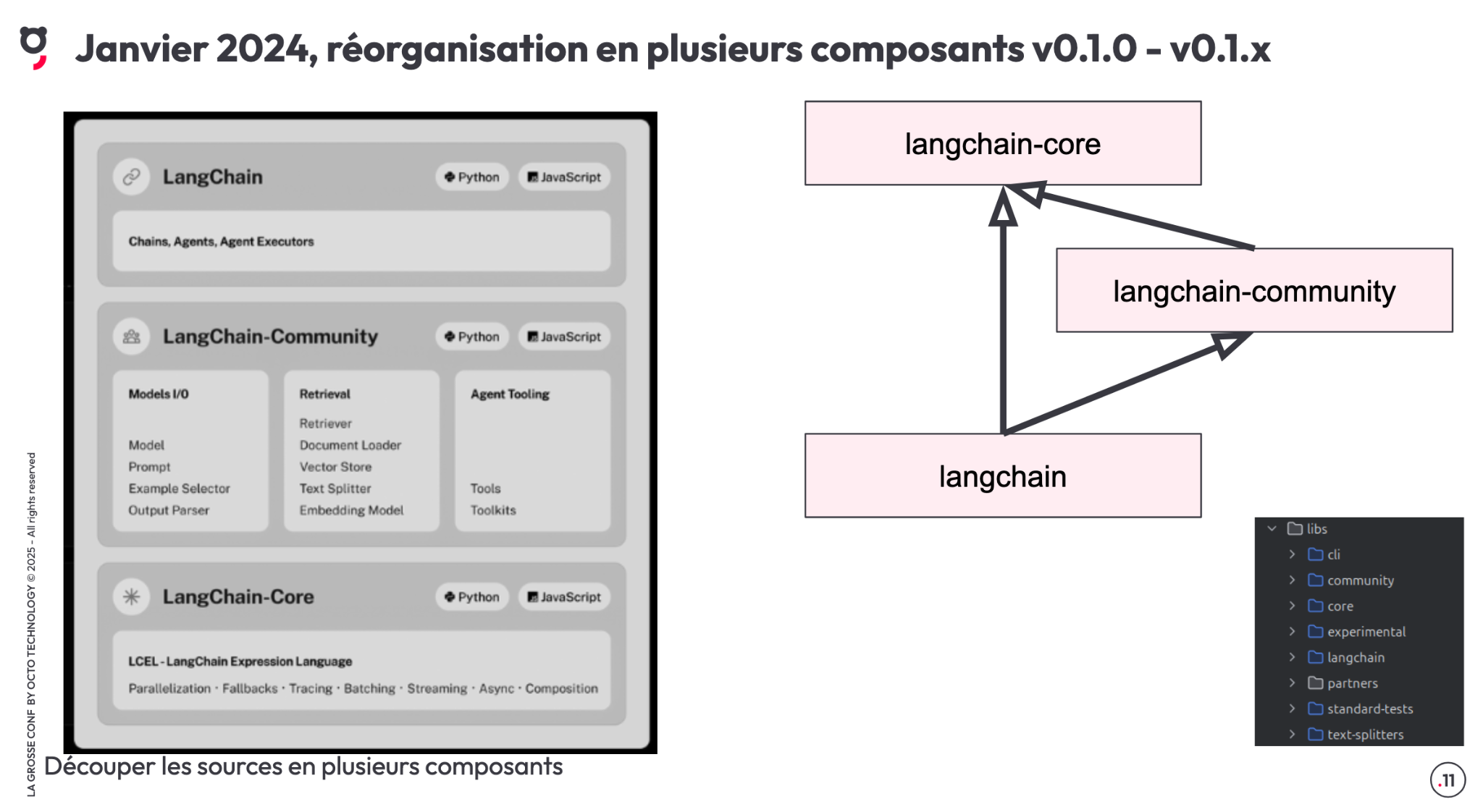
Cette évolution s’est accompagnée d’un refactoring du framework. LangChain a été scindé en plusieurs modules, dont LangChain Core, qui regroupe les interfaces et classes fondamentales (les concepts). Les implémentations spécifiques, comme les bases vectorielles, sont désormais séparées dans LangChain Community.
Vers une meilleure modularité et performance
Autre tournant majeur : la réécriture de PyDantic, le framework Python utilisé par LangChain pour la gestion du typage fort.
- PyDantic 1, bien que fonctionnel, était écrit en Python et souffrait de lenteurs.
- PyDantic 2, entièrement réécrit en Rust, offre une validation des types beaucoup plus rapide et efficace.
Cette transition a entraîné une rupture de compatibilité : LangChain a d’abord tenté de supporter les deux versions simultanément, avant d’abandonner PyDantic 1 avec la sortie de LangChain 0.2.
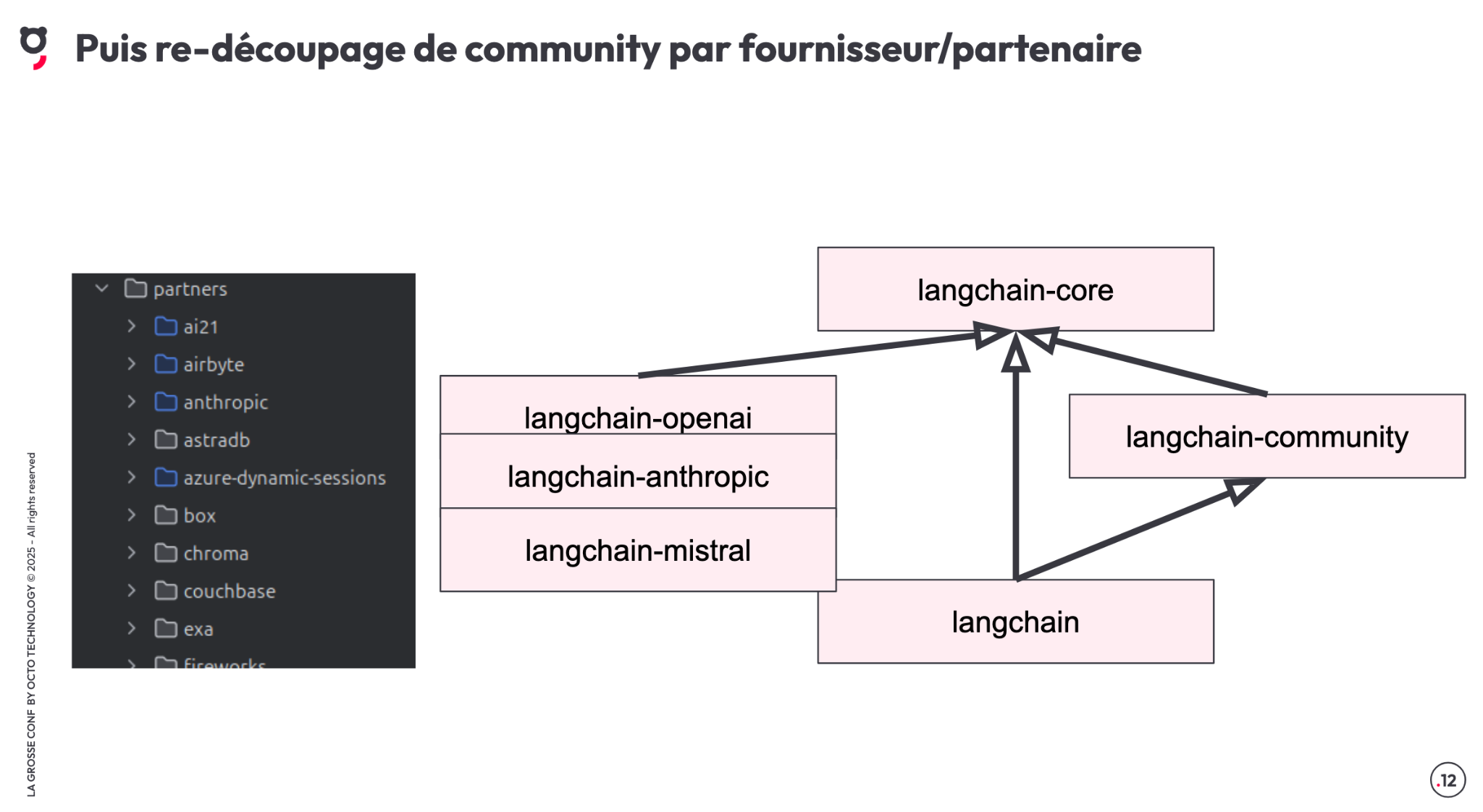
En parallèle, pour éviter la surcharge inutile de dépendances, le framework a été encore plus modulaire :
- langchain-openai
- langchain-anthropic
- langchain-mistral
- …
Chaque module peut être installé indépendamment, évitant ainsi d’alourdir les projets de dépendances inutiles.
Exemples de remise en cause : Document et Loader
L’évolution des LLM ne s’est pas arrêtée au texte : les modèles sont désormais multimodaux, capables de traiter aussi bien du texte que des images ou de l’audio.
LangChain a dû adapter ses structures de données. La classe Document, qui ne contenait initialement que du texte, a évolué vers un modèle plus générique :
- Un BaseMedia, pour gérer tout type de contenu
- Un Blob, qui stocke des fichiers bruts en mémoire avant leur traitement
Cette transition, encore en cours (un loader actuellement donne encore une liste de documents et non de médias par exemple), soulève des défis majeurs en matière de compatibilité et d’adaptation des outils existants.
Ne pas réinventer la roue : mieux comprendre LangChain
Un constat fréquent relevé par Philippe lors de son intervention : beaucoup de développeurs sous-estiment la richesse du framework.
"On pense qu’il suffit d’enchaîner trois objets et que tout fonctionnera parfaitement… alors qu’en réalité, c’est bien plus compliqué."
Trop souvent, par manque de compréhension, certains recréent des fonctionnalités déjà existantes, au lieu de s’appuyer sur l’architecture de LangChain. L’approche recommandée ?
- Plonger dans la documentation
- Explorer les concepts avancés
- Exploiter les fonctionnalités existantes au lieu de les dupliquer
Un Écosystème en Ébullition
En seulement un an et demi, LangChain a connu une évolution fulgurante, passant d’un projet expérimental à un pilier central de l’IA générative. Avec une nouvelle version publiée tous les 2-3 jours, son défi principal reste de suivre le rythme effréné des avancées du domaine, tout en garantissant une certaine stabilité.
Comment aborder un projet LangChain efficacement ?
Philippe illustre son propos avec un cas concret : ingérer des fichiers PDF dans une base vectorielle.
Un problème en apparence simple... mais trompeur
L’objectif semble clair : importer des fichiers PDF dans une base vectorielle. Pourtant, en creusant, plusieurs problèmes complexes émergent :
- Depuis une structure de répertoire
- Pouvoir actualiser les fichiers
- Sans tout réimporter
- Ne pas oublier de supprimer les fichiers qui ne sont plus présents, de la base vectorielle
- Comme le format PDF n’est pas terrible, certains fichiers sont en format Word
- Ce n’est pas 10 documents d’exemples, mais 50.000 de 20 pages qui évoluent quotidiennement
- Les fichiers sont dans un cloud storage
Avec une approche naïve, coder cette solution nécessiterait 500 à 1000 lignes de code. Pourtant, en explorant LangChain intelligemment, Philippe démontre qu’on peut résoudre ce problème en 20 lignes.
Exploiter la puissance des composants LangChain
Analyser le code source pour éviter de réinventer la roue
Plutôt que de coder une solution de zéro, analysons d’abord les ressources existantes.
Les Loaders : choisir le bon outil
LangChain propose plusieurs parsers PDF basés sur la classe BasePDFLoader. Parmi eux, PDFMinerLoader hérite d’un BaseLoader, qui lui-même est une abstraction pour de nombreux autres loaders.
Takeaway : Ne pas coder son propre loader trop vite. Il existe sûrement un loader adapté.
L’optimisation mémoire avec Lazy Loading
LangChain propose quatres méthodes principales pour charger des fichiers :
load(): Charge tous les documents en mémoire (dangereux pour de gros volumes)aload(): Version asynchrone deload()lazy_load(): Retourne un itérateur qui charge un document à la fois, limitant l’usage mémoirealazy_load(): la version asynchrone.
Takeaway : Toujours utiliser (a)lazy_load() en production pour gérer de gros volumes.
BaseBlobParser et GenericLoader : simplifier la gestion des formats
Plutôt que d’écrire du code spécifique pour gérer PDF et Word, LangChain propose un GenericLoader capable de lier les blobs et les parseurs. On obtient finalement pour notre problème un code qui ressemble à ceci :
vector_store=...
record_manager=...
loader=GenericLoader(
blob_loader=FileSystemBlobLoader( # Ou CloudBlobLoader
path="mydata/",
glob="/*",
show_progress=True,
),
blob_parser=MimeTypeBasedParser(
handlers={
"application/pdf": PDFPlumberParser(),
"application/vnd.openxmlformats-officedocument.wordprocessingml.document": MsWordParser(),
},
fallback_parser=TextParser(),
)
)
index(
loader.lazy_load(),
record_manager,
vector_store,
batch_size=100,
)
Takeaway : Utiliser les classes existantes permet de diviser son code par 10.
Que se passe-t-il si un import de documents échoue en plein milieu ?
Sans précaution, un crash réseau peut corrompre les données et nécessiter, une purge et un réimport complet.
Avec PGVector et quelques ajustements, on peut rendre l’import transactionnel et éviter ces erreurs. Philippe a d’ailleurs contribué au projet PgVector en ajoutant cette fonctionnalité via des pull-requests. Vous pouvez d’ailleurs lire cet article du Blog Octo pour avoir tous les détails.
Takeaway : Anticiper les crashs et assurer l’intégrité des données avec des mécanismes de reprise.
Suivre l’évolution constante des IA génératives
Le domaine de l’IA générative évolue trop vite pour être figé dans des règles strictes. Un projet LangChain ne peut pas être livré puis abandonné : il doit être maintenu et adapté en continu.
Takeaway : Accepter l’instabilité et rester flexible.
Conclusion : Réfléchir avant de coder
Le grand enseignement de Philippe
Si vous trouvez LangChain complexe, c’est que vous n’avez probablement pas tout compris aux IA génératives.
Plutôt que d’écrire du code naïf, analysons les ressources existantes et optimisons notre approche. En prenant 3 jours pour étudier LangChain en profondeur, on peut réduire son code de 1000 à 20 lignes et limiter les risques de bugs.
Acceptez de passer trois jours à étudier le framework, sans produire une seule ligne de code !

Bonnes pratiques pour travailler avec LangChain
- Explorer le code source avant de coder
- Pour la gestion des documents :
- Utiliser Lazy Loading pour optimiser la mémoire
- Séparer Loaders et Parsers pour une meilleure modularité
- Anticiper les crashs et rendre l’import transactionnel
- Rester flexible face à l’évolution rapide de l’IA
LangChain ne cherche pas à être stable, et c’est normal. Le framework suit les évolutions de l’IA générative. Attendre qu’il se stabilise est une erreur : mieux vaut l’adopter intelligemment, en intégrant dès le départ une stratégie d’adaptation continue.
En résumé
- Creuser avant de coder permet de gagner du temps et de la robustesse
- LangChain est riche, mais il faut l’explorer pour en tirer toute la valeur
- L’IA évolue vite, donc il faut un projet flexible et maintenable
- Un bon développeur LangChain ne code pas plus, il code mieux.