La Grosse Conf 2025 - L’aube des robots apprenants : vers une nouvelle ère.
Lors de son intervention (Replay disponible), Nicolas a souligné la profonde transformation que traverse actuellement la robotique. Comme l’a déclaré Jensen Huang, CEO de NVIDIA : "The ChatGPT moment for general robotics is just around the corner." Ce parallèle avec l’intelligence artificielle conversationnelle illustre l’évolution des technologies vers une adoption massive et accessible au grand public. 
Un moment charnière pour la robotique
La robotique est aujourd'hui entre deux phases : celle des architectures de type "transformer" (qui ont posé des bases solides) et celle du “moment GPT" (architectures composées d'énormes volumes de données pour l’apprentissage et la naissance de modèles de fondation). L'objectif est d'atteindre un stade similaire au "moment ChatGPT" où la technologie devient véritablement utilisable par tous.
Physical AI : La nouvelle phase de l’IA
Un concept clé évoqué lors du talk est celui de "Physical AI". Il s'agit de l'idée que l'intelligence artificielle rencontre le monde réel. Cette transformation repose sur trois piliers fondamentaux :
1. Percevoir le monde réel grâce à des capteurs et caméras.
2. Comprendre et interpréter ces informations à l’aide de modèles d’intelligence artificielle.
3. Agir en conséquence via des robots et dispositifs autonomes
La robotique est la manifestation la plus concrète de cette nouvelle phase, et nous assistons aujourd'hui à une démocratisation rapide du matériel nécessaire pour développer ces robots intelligents.
La démocratisation de la robotique
La robotique a longtemps été coûteuse et réservée à quelques acteurs spécialisés. Mais cela change rapidement grâce aux avancées en open source et à l'accessibilité croissante des composants.
L’année dernière a marqué une accélération de la robotique, avec l’apparition de bras robotiques domestiques, de robots zoomorphiques (chez Meta) et d’initiatives open source comme ALOHA ROBOT. Hugging Face a récemment lancé la librairie "Le Robot", visant à centraliser et partager des ressources autour de la robotique et de l'IA. L'objectif est d'offrir à tous la possibilité de concevoir des robots à moindre coût en assemblant des pièces facilement disponibles sur le marché. Un exemple est la création de bras robotiques à 100 dollars, dotés de moteurs rotatifs capables d'exécuter des tâches simples comme déplacer des objets.

L'apprentissage des robots : imitation et renforcement
L'une des phases les plus critiques dans le développement des robots intelligents est leur apprentissage. Deux grandes méthodes sont mises en avant :
- Imitation Learning : Basé sur des démonstrations humaines, il permet d'obtenir un taux de réussite élevé avec peu d'exemples
- Reinforcement Learning : Les robots apprennent par essais et erreurs pour déterminer les meilleures actions.
Nicolas a mis l'accent sur l'imitation learning, qui permet à un robot d'acquérir une tâche en seulement quelques dizaines de démonstrations.
Dans cette approche, un humain réalise la tâche via un dispositif télé-opéré, et le robot l’imite en reproduisant fidèlement les mouvements enregistrés. Cela permet un apprentissage efficace sans recourir à de grandes quantités de données synthétiques.
Un des défis majeurs réside dans l'entraînement de ces modèles. Quels datasets utiliser ? Quels environnements et types d'apprentissage adopter ? Ces questions sont centrales pour le développement de robots plus autonomes.
La modélisation
Une modélisation très adaptée à la robotique a émergé en 2023 (https://arxiv.org/abs/2304.13705) : ACT (Action chunking with Transformers). Cette modélisation permet de répondre efficacement aux deux grands problèmes de l’apprentissage robotique, d’un côté le fait que les erreurs se cumulent au fur et à mesure des actions (errors compounds), et de l’autre les problèmes dit de multimodalité lorsque de nombreux chemins mènent à une bonne solution.
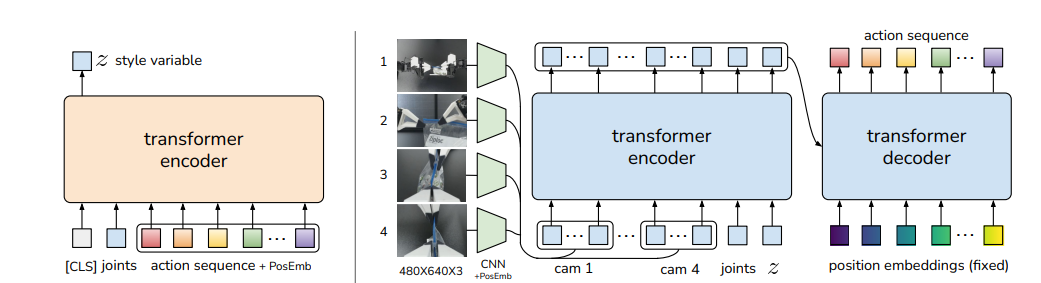
Entraînement du modèle avec CVAE
La modélisation ACT repose sur une architecture CVAE (Conditional Variational AutoEncoders) avec deux parties encodeur et décodeur :
- L'encodeur prend en entrée les séquences de mouvements réalisées par un expert et génère un espace latent , qui capture les caractéristiques sous-jacentes de ces actions. Cette étape permet d'obtenir une représentation compacte et informative des trajectoires du robot.
- Le décodeur prend ensuite cet espace latent, ainsi que les informations conditionnelles (images des caméras et valeurs des rotors du robot), pour générer une séquence d'actions plausible.
L'entraînement du modèle repose sur un ensemble de démonstrations réalisées par un expert humain, qui guide le robot dans l'exécution de tâches spécifiques. À partir d'une petite base d’exemple, le modèle est capable d'apprendre en seulement quelques heures sur un GPU, atteignant rapidement un très bon taux de réussite (90% sur le bras robotique). Cette efficacité montre le potentiel de ces types d’architectures pour construire des robots plus adaptatifs et robustes face aux variations de l'environnement. Cependant, avec ce type de modèle, le robot n'apprend qu'une seule tâche à la fois, et il a fallu partir de zéro pour concevoir le modèle ainsi que la base d'entraînement.
Le futur : construire des modèles de fondation pour la robotique
Pour que les robots puissent apprendre efficacement de multiples tâches, il est crucial de développer des modèles de fondation. Ces modèles évitent de repartir de zéro pour chaque nouvelle tâche en s’appuyant sur des ensembles de données diversifiés.
Un projet récent en ce sens est Physical Intelligence, qui propose un premier modèle généraliste entraîné sur différentes tâches et types de robots. Ces modèles exploitent les capacités des Vision-Language-Action Models (VLA), qui combinent la perception visuelle, la compréhension linguistique et l'exécution d'actions.
Helix, une entreprise innovante, propose par exemple un système hybride combinant :
- Un modèle lent (Vision Language Model VLM), qui prend plus de temps (7-9Hz) pour analyser son environnement ( images, rotors,etc.. ) et fournit un résumé (variables latentes)
- Un modèle d'action rapide qui grâce au résumé du modèle lent, prédit plus rapidement (200hz) les mouvements les plus adaptés pour le robot
Cette combinaison permet aux robots d’avoir une généralisation via un modèle plus conséquent (VLM) et agir rapidement grâce au modèle plus rapide.
Vers une adoption massive des robots
Nous nous dirigeons dans les prochaines années vers une ère où les robots feront partie intégrante de notre quotidien. Certaines initiatives, comme celle de Meta, explorent l’entraînement des robots via des lunettes intelligentes. Celles-ci permettraient aux utilisateurs d’enregistrer leurs actions et de les convertir directement en données d’apprentissage.
Par ailleurs, une réflexion s'amorce sur l'importance des expressions et émotions dans les mouvements des robots. Des études montrent que des mouvements plus naturels et expressifs facilitent l'interaction homme-machine et augmentent l'acceptabilité sociale des robots.
Le futur de la robotique : une transformation en marche
Si nous ne sommes pas encore au "moment ChatGPT" de la robotique, nous nous en approchons à grands pas. L'essor des modèles de fondation, la baisse des coûts des robots et l'amélioration des capacités d'apprentissage accélèrent cette transition.
Les grandes entreprises et les chercheurs se préparent activement à cette révolution. Que ce soit en usine, à domicile ou dans des domaines plus spécialisés, les robots sont en passe de devenir des compagnons du quotidien, capables d’accomplir une large gamme de tâches avec efficacité et intelligence.