La gouvernance augmentée : L'IA générative au service des catalogues de données
À mesure que le numérique s’impose comme la colonne vertébrale des organisations, les entreprises découvrent que leurs données ne sont plus de simples sous-produits de leurs activités, mais bien un patrimoine à part entière. Ce patrimoine informationnel, riche et protéiforme, rassemble l’ensemble des données qu’une organisation produit, acquiert, stocke, traite et exploite. Il est aussi précieux que les actifs financiers, humains ou technologiques, et peut même devenir un levier de différenciation ou, à l’inverse, une source de risques.
Malgré la croissance rapide des données, la plupart des entreprises ignorent la nature exacte de leur patrimoine informationnel. Sans visibilité, il devient difficile de gouverner, sécuriser et valoriser ces actifs.
La donnée, un asset stratégique pour une entreprise efficace
La maîtrise du patrimoine informationnel devient donc un enjeu stratégique. Elle conditionne la qualité des décisions, la conformité réglementaire, la performance opérationnelle, mais aussi la capacité à innover. Des données fiables et accessibles sont essentielles pour éviter les erreurs, les surcoûts et la perte de temps liée à la gestion d’informations dispersées ou contradictoires. 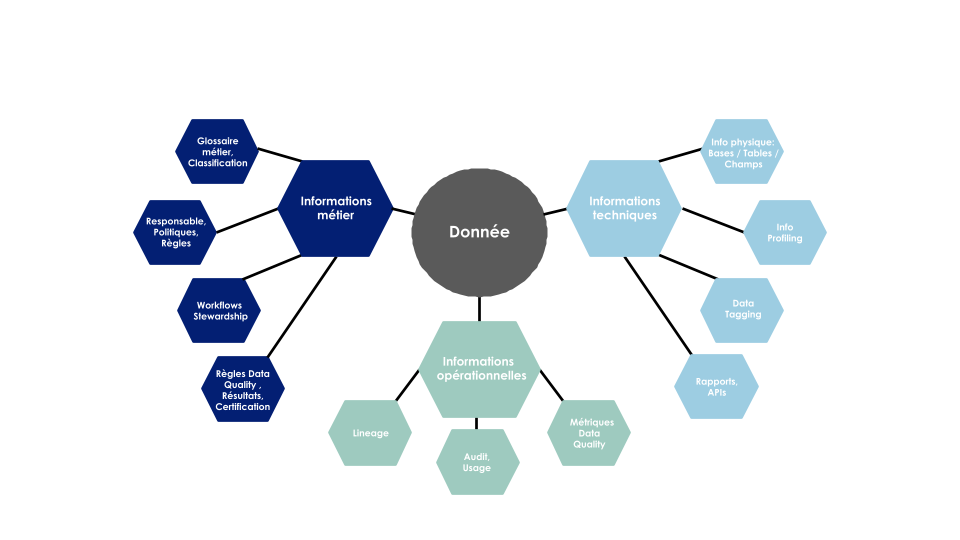
Selon Gartner, environ 30 % des projets d’intelligence artificielle générative (GenAI) seront abandonnés après la phase de proof-of-concept d’ici la fin de 2025, pour des raisons incluant la mauvaise qualité des données, des contrôles de risque insuffisants ou une valeur business peu claire. Gartner
Par ailleurs, 60 % des organisations indiquent ne pas disposer de données “prêtes pour l’IA” (“AI-ready”) ou ne pas savoir si elles le sont, ce qui expose leurs projets à des risques élevés d’abandon. DQ India
De plus, Gartner prévoit que 80 % des initiatives de gouvernance des données et analytics échoueront d’ici 2027 si elles ne sont pas correctement alignées sur les objectifs métiers. Gartner
La gouvernance de données pour créer de la valeur
Pour être efficace, la gouvernance doit rendre la donnée intelligible et accessible à toutes les parties prenantes. C’est précisément la vocation des catalogues de données (ou data catalog en anglais).
Ces plateformes centralisent et organisent la documentation sur les données d’entreprise :
- métier : glossaire, règles, responsables (data owner / data steward…),
- technique : localisations, profiling (analyse automatique du contenu des données pour détecter rapidement doublons, incohérences et autres problèmes de qualité),
- opérationnelles : cycle de vie de la donnée ou lineage (l’arbre généalogique des données, depuis sa source jusqu’aux usages finaux), afin de vérifier la fiabilité d’un chiffre ou l’impact d’un changement).
La promesse de ces catalogues de données : passer de données brutes à des actifs gouvernés, prêts à être exploités sereinement. La gouvernance de données devient ainsi un levier incontournable pour optimiser l’efficacité opérationnelle, assurer la conformité réglementaire et renforcer la fiabilité de la prise de décision — trois conditions immuables pour créer de la valeur et maîtriser les risques.
Une IA présente dans les solutions éditeurs, mais sur un périmètre limité
Les éditeurs de catalogue de données ont intégré depuis plusieurs années les promesses de l’IA pour renforcer leurs fonctionnalités. Voici quelques exemples :
- Recherche intelligente via NLP (propositions des résultats les plus pertinents, avec synonymes, similarités sémantiques, ou orthographes approximatives),
- classification automatique des données sensibles (analyse du contenu pour détecter le type de données, e.g. nom, email, IBAN…),
- détection automatique des relations cachées (analyse des clés étrangères implicites, des doublons, des regroupements),
- scoring de datasets (en fonction de leur popularité, de leur qualité ou de recommandations de jeux de données similaires),
- profiling automatique et détection d’anomalies (via différentes métriques : unicité, complétude, distribution/valeur aberrante, dérive…).
L’intelligence artificielle déploie ses atouts pour rendre ces outils plus ergonomiques, plus puissants, plus intuitifs. Et pourtant, un point de friction majeur subsiste : l’alimentation initiale des informations métiers dans le catalogue de données et son maintien à jour dans la durée.
Car aussi performants soient-ils, ces catalogues doivent bien être nourris d’informations. D’un point de vue technique, les connecteurs et API permettent d’extraire automatiquement les métadonnées depuis les bases de données, data warehouses, outils BI ou de datavisualisation. Mais dès que le versant fonctionnel est abordé, celui qui décrit la donnée avec les mots du métier, les limites apparaissent. La documentation métier, encore largement manuelle, est souvent jugée laborieuse et peu valorisante par les équipes.
La Gen IA comme accélérateur de l’alimentation fonctionnelle des catalogues de données
C’est ici que la Gén IA ouvre des perspectives nouvelles. Nous avons expérimenté son potentiel pour automatiser et fluidifier cette étape souvent trop laborieuse. En partant d’un postulat simple – si l’information existe quelque part, alors l’IA peut la retrouver et la restructurer –, nous avons donc conçu une chaîne de traitement capable d’explorer les gisements documentaires (Confluence, SharePoint, documents Office...), d’en extraire les éléments clés, de les formater selon les standards du catalogue de données (par exemple Collibra ou DataGalaxy), puis de soumettre ce pré-travail à validation humaine.
Chez Octo Technology, nous essayons d’apporter une réponse outillée à cette problématique de préparation documentaire pour alimenter le catalogue de données, en partant d’un postulat très simple : si l’information est présente dans un support, elle est exploitable par un outil de Gen IA.
Nous avons donc réalisé une expérimentation interne dans laquelle, à partir d’informations présentes dans des pages Confluence, un outil de GEN IA qui avait pour objectif d’extraire les informations pour venir ensuite alimenter un template excel formaté selon le meta-model d’un éditeur (Collibra) :
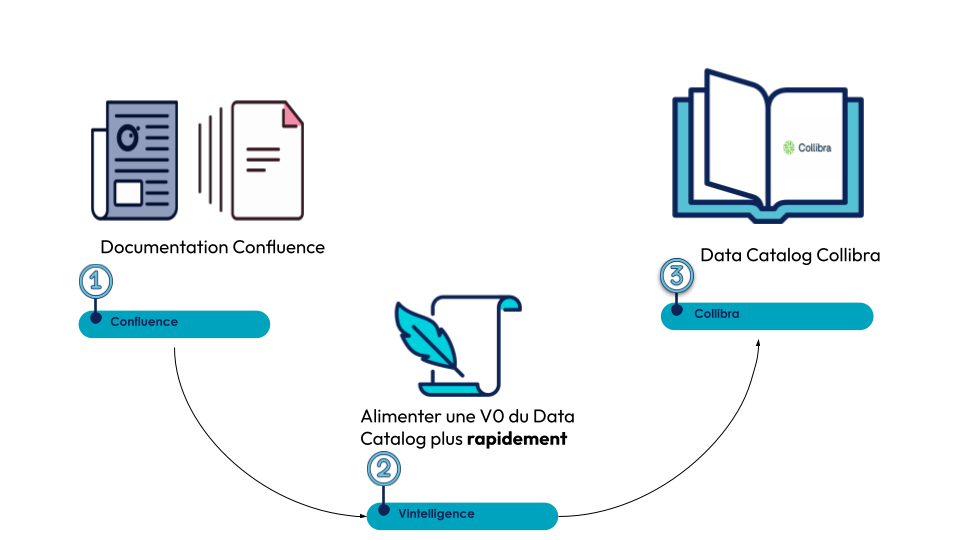
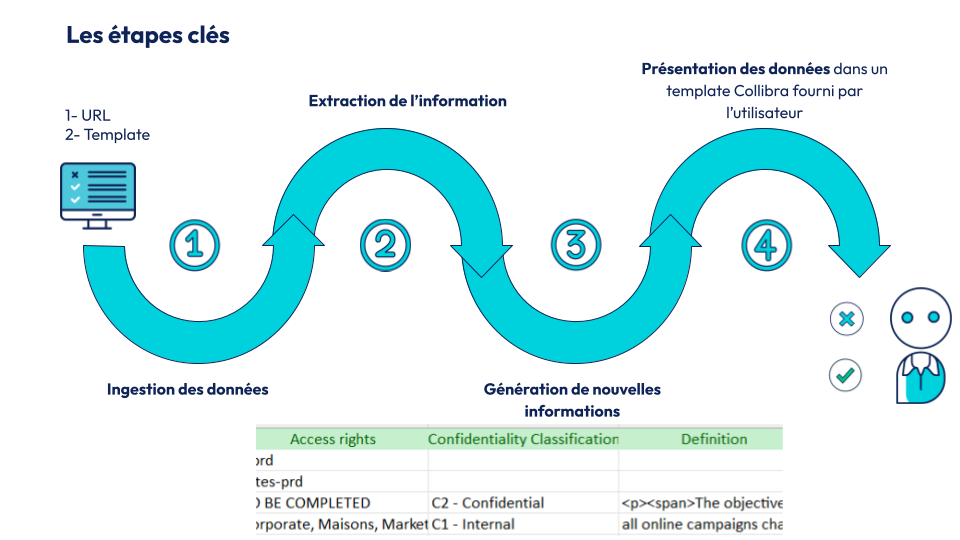
Pour réaliser ce projet, il a fallu imaginer une succession d’étapes dont voici la représentation schématique :
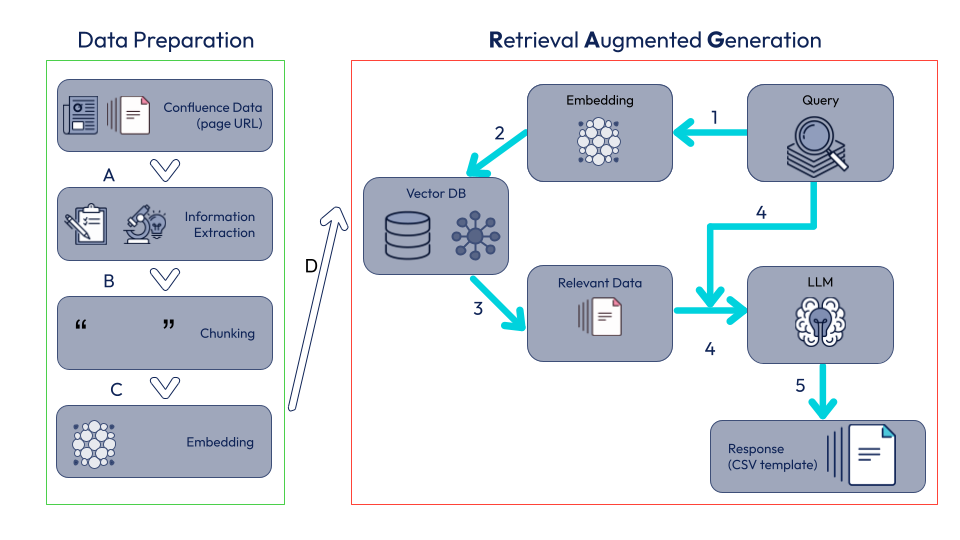
Enfin, la complexité de l’exercice reposait sur la définition de l'architecture RAG à mettre en place et bien sûr sur les choix des technologies à implémenter pour avoir le résultat le plus pertinent, satisfaisant.
La documentation métier, encore largement manuelle, est souvent jugée laborieuse et peu valorisante par les équipes.
Voici les étapes de la méthodologie utilisée pour notre accélérateur :
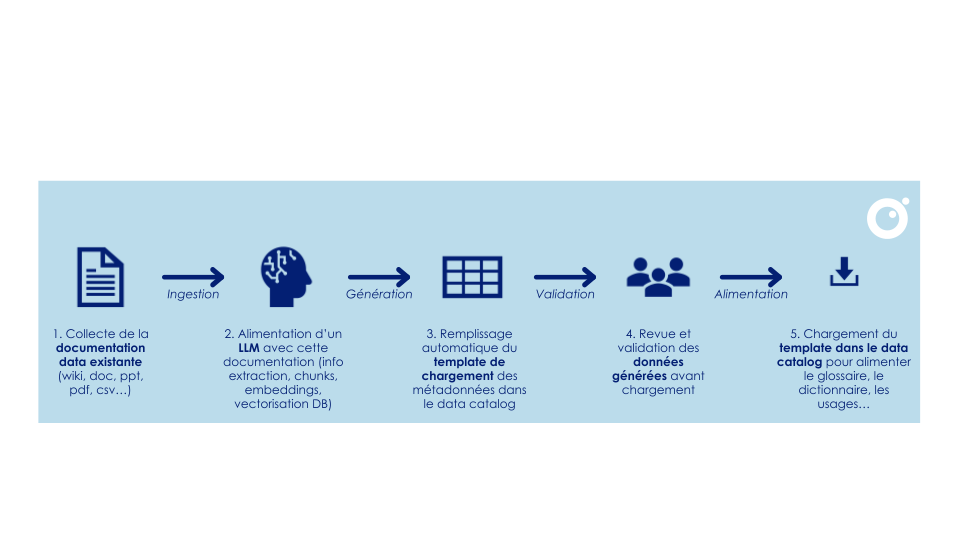
Les premiers résultats sont encourageants : l’IA générative permet de réduire de 30 à 50 % le temps consacré à la collecte, à la reformulation et à la rédaction des définitions, selon les activités. Elle libère ainsi les équipes des tâches répétitives et peu valorisantes. Cette automatisation accélère la valorisation des données documentées, sécurise leur usage et renforce la gouvernance globale, notamment grâce à une meilleure homogénéité des définitions.
Exemple – TJM moyen (Taux Journalier Moyen) :
| Élément | Approche manuelle (data steward seul) | Approche automatisée (LLM + Confluence par exemple) |
|---|---|---|
| Nom | TJM moyen | TJM moyen |
| Définition | Indicateur représentant le revenu moyen facturé par jour et par consultant sur une période donnée. | Mesure le revenu moyen par jour de mission client, calculé comme le chiffre d’affaires facturé ÷ le nombre total de jours facturés. |
| Règles de gestion | - Inclut uniquement les missions client (hors interne) - Calcul = (CA facturé) ÷ (Jours facturés) - Exclut les remises exceptionnelles | - Inclut uniquement les prestations client - Exclut missions internes, absences, gestes commerciaux (jours offerts, remises) |
| Propriétaire métier | Direction commerciale / financière | Finance / Direction commerciale (suggéré) |
| Systèmes sources | ERP facturation, outil de gestion de missions | ERP facturation, PSA (suggérés) |
| Effort estimé | ~30 min (chercher dans Confluence, tableurs partagés, doc reporting) | ~5–10 min (validation + enrichissement) |
Limites et risques de l’IA générative dans la gouvernance des données
Si l’IA générative offre des perspectives prometteuses pour automatiser et accélérer la gouvernance des données, elle n’est pas exempte de limites. La qualité des résultats dépend fortement de la fiabilité et de la fraîcheur des sources documentaires exploitées. Des données incomplètes, obsolètes ou biaisées peuvent entraîner des erreurs ou des interprétations erronées. Par ailleurs, l’IA générative peut reproduire, voire amplifier, certains biais présents dans les données d’entraînement ou dans les corpus analysés.
Il est donc essentiel de maintenir une validation humaine rigoureuse à chaque étape clé du processus, notamment lors de l’intégration des informations dans le catalogue de données. Cette vigilance permet de garantir la pertinence, la conformité et la qualité des contenus produits par l’IA, tout en évitant une dépendance excessive à l’automatisation.
…Vers une gouvernance augmentée
En définitive, la gouvernance des données ne se limite plus à une exigence réglementaire ou à une simple bonne pratique : elle devient un levier stratégique pour accélérer la transformation des organisations. L’IA générative, loin de remplacer l’expertise humaine, agit comme un catalyseur qui libère les équipes des tâches répétitives et leur permet de se concentrer sur la création de valeur. Toutefois, il reste essentiel de garder à l’esprit les limites de ces technologies : la qualité des résultats dépend fortement des sources exploitées, et la validation humaine demeure indispensable pour garantir la pertinence et la fiabilité des contenus produits.
En automatisant l’alimentation fonctionnelle des catalogues de données, la GenAI ouvre la voie à une gouvernance augmentée, plus agile et plus fiable — à condition de conjuguer intelligence humaine et puissance de l’IA, tout en restant vigilant face aux risques de biais ou d’erreurs.
À vous de jouer !
Que vous soyez data steward, décideur ou utilisateur métier, engagez-vous dès aujourd’hui dans une démarche de gouvernance augmentée. Expérimentez, outillez-vous, partagez vos retours et osez repenser vos pratiques. C’est en conjuguant intelligence humaine et puissance de l’IA que vous ferez de vos données un véritable moteur de valeur et d’innovation pour votre organisation.