La gestion visuelle dans un projet de Machine Learning Delivery
Introduction
En développement logiciel et en Machine Learning, le travail en cours n’est pas aussi visible que dans une usine où l'on voit les pièces s'assembler et progresser d'une étape à l'autre. Ne pas voir le travail en cours peut nous empêcher de voir certains des points bloquants, de se projeter sur la quantité de travail bientôt terminé, d’améliorer le process, … Pour remédier à cela, il est donc important d’outiller l’équipe pour rendre le travail visible tant au niveau des membres de l'équipe elle-même qu'au niveau du management. Le livre Accelerate propose d’ailleurs une capacité sur ce sujet : Visualising Work.
En Machine Learning Delivery, cette pratique s'avère plus délicate encore de par la nature des tâches effectuées qui sont souvent plus longues et très expérimentales. Plus encore, on a moins d'expérience et moins de maturité sur ces projets.
Dans cet article, nous cherchons à explorer des solutions pour mettre en place du management visuel dans les projets de Machine Learning Delivery. Nous verrons d'abord en quoi c'est utile et pourquoi cela permet d'accélérer le delivery puis nous présenterons des pratiques que nous avons testées et vérifiées pour permettre la visualisation du flux de travail. Finalement, nous parlerons d'outils et de moyens pour suivre la qualité de ce qui est produit.
Pourquoi visualiser ?
L'étude statistique menée par les auteurs d'Accelerate a prouvé un lien de causalité entre le Lean Product Management, dont le management visuel est une composante, et la performance de Delivery. En effet, les affichages visuels tels que des dashboards, sites web ou même boards physiques utilisés pour suivre la qualité et la progression permettent d'identifier rapidement les éléments de blocage et les défaillances du système pour mieux les traiter.
Outre la performance de delivery, le management visuel influe sur la culture de l'organisation et contribue à diminuer le risque de burnout puisque c'est un élément-clé de la communication. Il traduit une volonté de transparence et de confiance au sein des équipes. Peut-on accéder facilement à l'information ? Est-on capable d'identifier rapidement les bugs et les défaillances du produit ? À quels niveaux ou plutôt pour qui ces informations sont-elles accessibles ? Autant de questions qui permettent de savoir comment circule l'information au sein de l'organisation, ceci étant un indicateur central de la culture (Pour approfondir le sujet de la culture, vous pouvez vous référer à l’article Westrum Organizational Culture et Machine Learning et pour approfondir le sujet du burnout, vous pouvez vous référez au chapitre 9 du livre Accelerate).
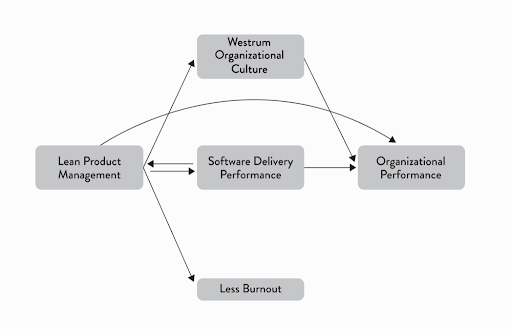
Figure 1 : Les impacts du Lean Management - source : Accelerate. Figure 8.2
Pour qui ?
Avant de commencer à visualiser, la première question que l’on se pose est : qui devrait avoir accès à ces informations ?
Les visualisations doivent être facilement accessibles à tous : l’équipe de développement bien sûr pour qu’elle puisse suivre sa progression, identifier les problèmes puis les résoudre; les stakeholders et le management doivent aussi pouvoir y accéder, cette transparence permettant de mieux se comprendre et d'instaurer la confiance au sein de l'organisation. Le management fera toutefois attention à ne pas sombrer dans le micro-management.
Maintenant que le télétravail est grandement répandu, ces visualisations doivent être digitalisées mais quand l'équipe est colocalisée, il est également possible de les rendre physiques en ajoutant un écran sur le plateau qui affiche l’ensemble de ces informations ou en créant un board physique qui permet aux équipes de mieux s'approprier leurs affichages.
Nous vous suggérons également de centraliser l’information dans le moins d’outils possible afin de faciliter l’accès à celle-ci. Une visualisation dans un outil inconnu de tous et difficilement accessible n'apportera pas les bénéfices promis.
Visualiser le travail en cours
D'abord, nous tenons à préciser que nous avons la conviction forte que les équipes doivent choisir et adapter leur outillage tout au long du développement. Nos expériences nous ont amenés à avoir tout de même un outillage standard pour commencer, qui sera adapté par les équipes en cours de cycle, notamment via les rétrospectives. Nous présenterons donc des pratiques que nous avons mises en place lors de nos différents projets et que nous recommandons.
Quelles sont les tâches que nous souhaitons visualiser en Machine Learning ?
Une équipe développant un projet de Machine Learning effectue certaines voire toutes les tâches "classiques" qu'on retrouve dans un projet de delivery logiciel, en l'occurrence développement de fonctionnalités, testing, debugging, monitoring, etc. Par contre, quelques tâches demeurent spécifiques au Machine Learning:
Une équipe développant un projet de Machine Learning effectue probablement et régulièrement certaines de ces tâches :

Figure 2 : Les principales tâches spécifiques dans un projet de Machine Learning (ML)
- Expérimentations
On aurait tendance à penser que ce type de travail n'a lieu qu'au début du projet quand on essaie de détecter du signal dans les données. Or, pour pouvoir inscrire le projet dans un contexte d'amélioration continue, l'expérimentation doit avoir lieu de manière récurrente : essayer d'entraîner un nouveau type de modèles, rajouter de nouvelles données, faire un feature engineering différent, etc. Chacune de ces tâches représente un petit ticket, un petit lot. Le livrable de ce type de tâches est la validation ou l'invalidation d'une hypothèse de départ en s'appuyant sur les résultats de l'expérimentation.
- Annotations
Dans le cadre de l'apprentissage supervisé, il faut prendre en compte cette étape essentielle pour l'élaboration et l'entraînement des modèles. Le livrable est une donnée annotée.
- Entraînements ou ré-entraînements de modèles
A l'instar de l'annotation, l'entraînement de modèles fait partie intégrante des projets de Machine Learning et c'est une tâche récurrente. Le livrable est un modèle entraîné.
Une méthode de visualisation : le Kanban
L'un des outils de visualisation de travail les plus populaires dans les projets Agile est le Kanban. Celui-ci permet de visualiser la progression des tâches à travers les différents états possibles du workflow. Un kanban très simple serait composé par exemple de quatre états : tâches à faire (to do), en cours d'exécution (doing), en cours de revue (review) et terminées (done). Concrètement, il s'agit d'un tableau de colonnes verticales représentant chacune un état et dans lesquelles se trouvent les tâches correspondantes.
L’objectif de cette méthode de visualisation du travail - et des autres méthodes d'ailleurs - n’est pas tant de faire du reporting mais bien d’identifier des problèmes, des difficultés. En effet, le kanban est idéal pour mesurer le flux du travail et savoir ainsi les points de blocage ou bottlenecks : les tâches restent très longtemps dans la colonne "DOING", sont-elles trop complexes, mal découpées ? Les tâches prennent trop de temps pour passer à l'état "terminées", les processus de validation sont-ils trop lourds ?
Un autre avantage de la configuration en colonnes du Kanban est la facilité d'instaurer une WIP (Work In Progress) limit. Cette limit aura les deux impacts suivant :
- Minimiser la concurrence entre les tâches en cours qui est rarement bénéfique et conduit plutôt à un débit plus faible comme l'énonce la loi de Little.
- Favoriser une démarche de flux tiré plutôt que poussé. C'est-à-dire chercher à finir des tâches avant d’en commencer de nouvelles. Par exemple : inciter les développeurs à faire les codes reviews en priorité.
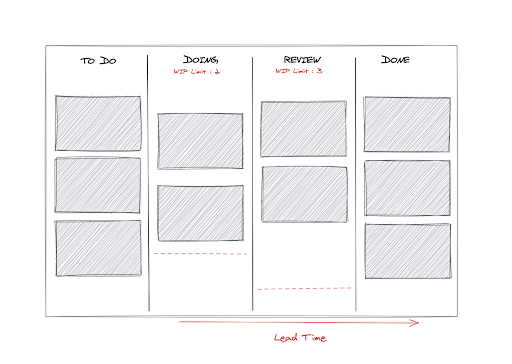
Comment adapter le Kanban à un projet de delivery de Machine Learning ?
Le backlog d'un projet de Machine Learning comporte à la fois les spécificités d'un projet de développement logiciel classique et les spécificités liées au Machine Learning dont nous avons parlé plus haut (entraînement, annotation, évaluation du modèle, etc..). Comment peut-on le rendre le plus compréhensible et le plus visible possible ?
Rendre visible les contraintes métier
Souvent en Machine Learning, il est nécessaire d’avoir accès aux données avant de pouvoir commencer une tâche. Il convient alors d’intégrer l’accès aux données dans la definition of ready (ce qui qualifie qu’une tâche peut être commencée). Si l’accès aux données est un problème récurrent dans votre organisation, il peut être intéressant de marquer les tickets en attente de données dans une colonne dédiée ou avec un tag dédié.
A l'instar de l'accès aux données, la validation des modèles à mettre en production est souvent un processus métier incontournable surtout dans certains cas critiques où il est nécessaire de vérifier le comportement du modèle en amont sur différents jeux de données : par exemple, quand on veut être sûr que notre chatbot ne présente pas de biais discriminatoire. A par le fait qu'il serait l'idéal d'automatiser autant que possible cette validation, on peut représenter cette contrainte dans une colonne de validation et en ajoutant une définition de “terminé" (Definition Of Done).
L'intérêt de rendre visible ces contraintes est d'identifier rapidement les processus qui ralentissent le flux de travail pour anticiper ces goulots d'étranglement et les alléger si possible.
Suivre et maîtriser les tâches d'expérimentation
Les expérimentations se prêtent également bien au Kanban, à condition de les avoir découpées. On appelle communément Spike (qui est un terme utilisé aussi dans le développement logiciel) les tâches exploratoires dont on n'est pas sûr du résultat. Il peut être intéressant de distinguer dans le kanban les tâches d'expérimentation des tâches de développement (build) afin de voir au premier coup d'œil la proportion de build versus expérimentation. En effet, il est intéressant de conserver un bon compromis entre expérimentation et valeur délivrée à l’utilisateur (via le build). Ce trade-off peut être représenté par le schéma suivant :
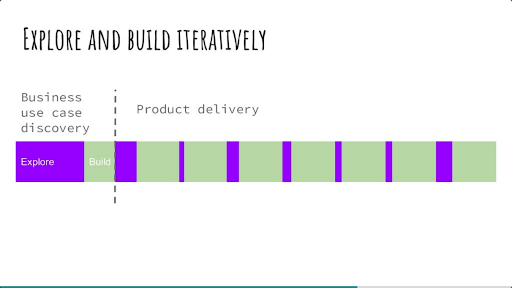
Figure 4 : Build et exploration dans un projet de delivery - source : (Agile France) Danse avec les unicorns : la Machine Learning en agile, de l'exploration à l'adoption
Afficher les spécificités d'un delivery en Machine Learning
Les tâches d'entraînement peuvent se prêter au Kanban si les calculs ne sont pas trop longs (supérieurs à plusieurs heures). Dans le cas d’entraînement long en temps, la tâche va rester longtemps sans bouger dans le Kanban, cela risque de diminuer la lisibilité de celui-ci. Pour y remédier, il est possible de transformer un peu le Kanban en ajoutant une colonne "Entraînement en cours” afin de bien visualiser ces tâches et de les séparer des tâches où le développeur est actif. Une autre solution serait de créer des Story spécifiques à l'entraînement dont la To-Do list serait connue à l'avance et contiendrait toutes les étapes depuis la récupération des données jusqu'à l'évaluation des modèles en prévision de l'automatisation de ces tâches. Une telle Story permettrait l'alignement des membres de l'équipe sur le processus de réentraînement : les données à récupérer, quelles proportions de données pour l'entraînement, la validation et le test, quelles métriques utiliser pour l'évaluation, etc.
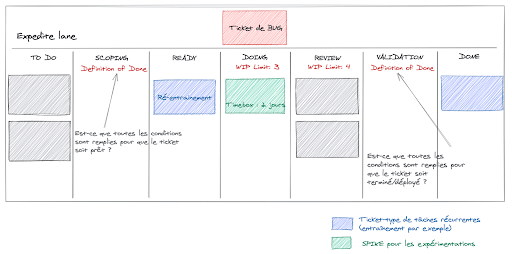
Figure 5 : Un exemple de Kanban utilisé dans un projet de ML Delivery
Finalement, une troisième solution serait d'utiliser la notion de Class of Services : il s'agit à la base d'un "découpage" horizontal du Kanban selon le Cost of Delay de la tâche ou, en d'autres termes, l'impact qu'aurait un délai trop long avant la livraison de la tâche. Chacune des classes ont des modalités différentes pour le traitement des tâches. Une classe "Réentraînement" pourrait être créée et l'équipe pourrait se mettre d'accord sur la façon de traiter ce type de tâches.
Nous tenons toutefois à nuancer l’intérêt de visualiser ces tâches en fonction de votre contexte et de l’objectif de l’équipe. Une équipe chargée de produire des modèles a tout intérêt à visualiser les tâches d’entraînement car c’est sa raison d’être, c’est le cœur de son travail. Une équipe de delivery logiciel, qui voit l’entraînement de modèle comme la construction d’une nouvelle version n’a pas particulièrement d’intérêt à visualiser cette tâche au même titre qu'une tâche de build / deploy d’une nouvelle version de l’application qu'on ne visualise généralement pas.
Les tâches d’annotation quant à elles ne se prêtent pas bien au Kanban, car plus de temps sera consacré à bouger les tickets dans celui-ci qu'à faire la tâche, notamment à cause de la forte volumétrie de données et du faible temps (souvent quelques secondes) pour les annotées. Il convient alors de faire un monitoring automatisé de l’avancée de l’annotation. Pour faire cela on peut se tourner vers une stack classique du monitoring : une base de données couplée à un dashboard Grafana ou peut-être un outil d'annotations tel que Amazon SageMaker Ground Truth.
Dans cette section, nous avons vu que le Kanban, outil classique du suivi du travail en développement logiciel, peut très bien s’adapter à un projet de delivery de Machine Learning. En voici un résumé :
| Quoi visualiser ? | __Commen__t ? |
| Développement | Kanban |
| Expérimentation | Kanban |
| Entraînement / Ré-entraînement | Kanban avec quelques adaptations éventuelles |
| Annotations | Dashboard (ex. Grafana) de suivi couplé à une base de donnée |
Visualiser la qualité et les défaillances du système
De même que pour le suivi du travail en cours, la visualisation de la qualité ne doit pas se faire à des fins de reporting mais bien d’amélioration continue.
Dans la précédente section, en plus de lister les tâches qui sont réalisées sur un projet de delivery de Machine Learning, nous avons également identifié leurs livrables / leurs artefacts. Ce sont les suivants : du code, des expérimentations, des annotations, des modèles. S’assurer de la qualité du projet au global requiert de s’assurer de la qualité de chacun de ces artefacts. Rendre la qualité visible renforcera la transparence et le collective ownership (tout le monde aura la même vision de la qualité du projet et donc la responsabilité sur celle-ci est partagée)..
Visualiser la qualité du code
Le code étant un composant classique des projets de développement logiciel, il n’est pas nécessaire de réinventer la roue et les outils de suivi de qualité restent les mêmes : une pipeline d'intégration continue ou CI est un excellent moyen de rendre accessible à toute l'équipe un bon nombre d'informations sur la qualité et les problèmes du code produit (résultats des tests automatisés ou d'un linter, packaging et déploiement du code, etc.).
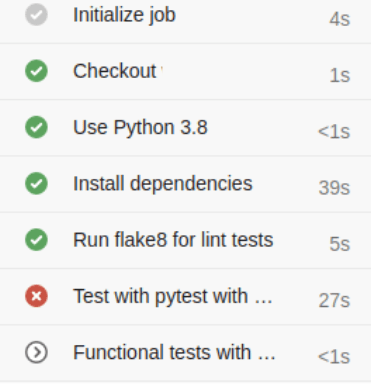
FIgure 6 : Exemple de pipeline de CI qui permet de voir que une non qualité a été détectée grâce aux tests “pytest”
Pour le suivi de la qualité en production, Accelerate propose quatre métriques qui permettent de mesurer la performance de Delivery (voir article d'introduction). Parmi ces métriques-là, il existe deux indicateurs de stabilité qui mesurent la qualité du code déployé. Ces deux métriques sont :
- Le nombre de bug en production,
- Le temps nécessaire pour réparer.
En cas de défaut de qualité, il est possible de corriger le code produit, revoir les standards de développement, former le développeur ou l’équipe à certaines pratiques, etc.
Visualiser la qualité des annotations
Comme indiqué plus tôt, un dashboard de visualisation de l'avancement des annotations est un moyen assez efficace de partager aux différentes personnes concernées la quantité de données disponibles pour faire évoluer le modèle dans le cas d'un apprentissage supervisé si besoin. Plus encore, ce dashboard peut permettre de visualiser la qualité des annotations produites puisque l’on est capable de retrouver et de voir facilement les données utilisées pour entraîner les modèles. Les annotations peuvent ainsi être confrontées aux critères de qualité du métier. Un autre exemple de mesure de qualité serait de comparer les annotations de deux annotateurs sur les mêmes données (par exemple avec le score du Kappa de Cohen) ou même de comparer les annotations manuelles à des annotations générées automatiquement.
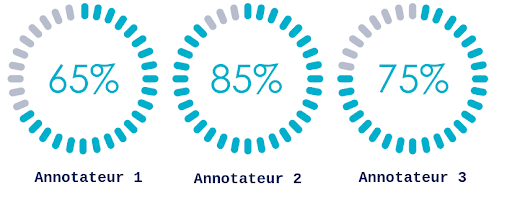
Figure 7 : Exemple de dashboard de suivi de la cohérence des annotations
En cas de défaut de qualité il est possible d’identifier un annotateur qui produit souvent des annotations de faible qualité et lui ré-expliquer le processus d’annotations; il est possible de mettre en place des revues d’annotations (un peu comme les revues de code) pour aligner les annotateurs; finalement il est possible de modifier le processus d’annotation pour le simplifier.
Visualiser la qualité des expérimentations :
La qualité des expérimentations ne peut pas réellement se mesurer à partir d'une expérimentation, elle doit se mesurer à partir de plusieurs expérimentations. Une expérimentation peut ne pas être concluante et ce n’est pas gênant. Ce qui est problématique, c'est la succession d’expérimentations non concluantes.
Dans le cas d'un projet de Machine Learning visant à optimiser une métrique, par exemple, pour suivre la qualité au global des expérimentations, il est possible de tracer une courbe "performance du système / date de l’expérimentations". Cette courbe doit avoir une tendance ascendante marquée, c’est à dire qu'au global les expérimentations récentes doivent donner un système plus performant que les expérimentations passées. Si cette courbe stagne ou décroît c’est que les dernières idées d’expérimentations n’ont pas été concluantes.
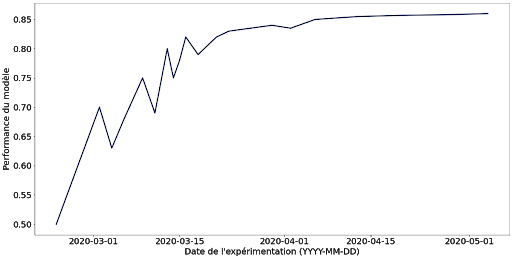
Figure 8 : Exemple de courbe performance du modèle au fil des expérimentations
Pour corriger un défaut de qualité des expérimentations, il est possible de prendre du recul sur les dernières expérimentations, imaginer des expérimentations plus variées, arrêter les expérimentations car on a obtenu tout le signal possible à tirer des données disponibles.
Visualiser la qualité des modèles :
Il est possible de visualiser la performance des modèles dans deux situations : en phase de construction ou d’entraînement et en phase de production.
Dans le cas de l’entraînement de modèle, en plus du logging, il existe des outils tels que MLFlow, Tensorboard, etc. qui permettent de visualiser les performances du modèle en cours d’entraînement. Suivre cela permet de voir s'il a atteint un plafond de performance et si les prochaines itérations d’entraînement ne sont pas nécessairement utiles.
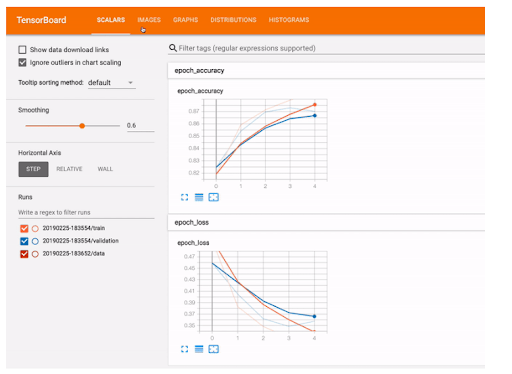
Figure 9 : Exemple de tensorboard qui affiche l’accuracy au fil de l’entraînement (source)
La mesure de la qualité des modèles en production peut se faire à deux niveaux. Le premier est à la fin de l’entraînement via des contrôles type allow list / block list (des tests qui vérifient que pour une situation en particulier la prédiction est bien celle souhaitée), des vérifications sur les biais et de la shadow production. Le deuxième niveau est en cours de run, lorsque le modèle est en production il convient de monitorer ses performances dans le temps, vous pouvez approfondir ce sujet avec cet article.
En cas de défaut de qualité, il est possible de ne pas déployer en production le modèle, de faire un ré-entraînement, de corriger des biais dans la base de donnée, etc.
Dans cette section nous avons vu comment visualiser la qualité des différents artefacts afin de s’assurer de la qualité global du projet. En voici un résumé :
| Quoi visualiser ? | __Commen__t ? |
| Code | Intégration continue |
| Expérimentation | Traçage des expérimentations via des outils de viz (ex. MLFLow) |
| Modèle | Shadow production, monitoring avec un dashboard (ex. Grafana), |
| Annotation | Mise en place d’une métrique adaptée et monitoring de celle-ci. |
Conclusion
Dans cet article nous avons détaillé, dans un contexte de Machine Learning, une pratique notamment poussée par le livre Accelerate : la visualisation du travail en cours et de la qualité ainsi que les défaillances du système.
Nous avons identifié quels types d'informations seraient intéressants et utiles à diffuser :
- Le travail en cours : développement, expérimentation, entraînement, annotation,
- La qualité : du code, des expérimentations, des modèles, des annotations.
Nous avons également vu que les méthodes de visualisation de la qualité et du travail sont de natures variées et sans effort particulier elles seront dispersées dans différents outils.
Cette visualisation permet de voir le travail en cours, d’identifier des goulots d’étranglement, des problèmes dans les processus etc. La nature des informations diffusées, de par le fait qu'elles concernent à la fois la productivité de l'équipe et les problèmes en production, permet d'établir un climat de confiance et de transparence entre les différentes parties prenantes et contribue à la création d'une culture générative au sein de l'organisation. Par contre, cette capacité seule n'est pas suffisante pour l'amélioration des performances de delivery en Machine Learning et nous verrons dans d'autres articles comment les autres capacités Accelerate peuvent la compléter.