La gestion des exceptions en java
En auditant des applications pour des clients d'OCTO, je me suis aperçu que la gestion des exceptions est un élément qui fait souvent défaut au même titre que la gestion des transactions. Ce billet était à l'origine des notes personnelles qui avaient pour but de me servir de piqure de rappel et je me suis dit qu'un article de blog serait peut être utile à tous. Ce sujet prête souvent à discussions et il faut parfois adapter au cas par cas, néanmoins avoir un cadre de bonnes pratiques peut s'avérer très utile.
Tout d'abord, voici un schéma présentant la hiérarchie des classes "mères" d'exceptions en java.
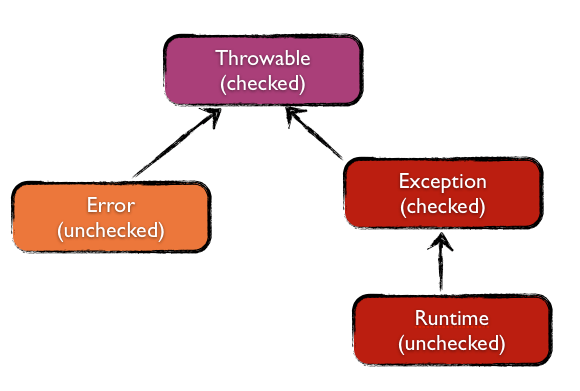
On constate donc 3 degrés de gravité :
- Les erreurs graves qui causent généralement l'arrêt du programme et qui sont représentées par la classe java.lang.Error Ces erreurs empêchent le bon fonctionnement de la JVM (exemple : OutOfMemoryError). 99,9% du temps on ne doit pas les rattraper. On peut les attraper mais c'est un anti pattern car on ne peut globalement rien faire pour les arranger, les attraper risque donc d'empêcher un problème très important de remonter. Vous ne devriez pas avoir à utiliser cette classe à moins de développer un framework extrêmement technique.
- Les erreurs qui doivent être traitées par l'appelant de la méthode qui lève l'exception. Elles héritent de la classe java.lang.Exception ce sont elles qu'on appelle exceptions Checked. Elles doivent être déclarées dans la signature de la méthode après le mot clé throws, ces exceptions sont donc explicites. Il s'agit d'erreur au niveau applicatif qui vont se propager dans le code en ignorant les instructions suivantes.
- Les erreurs qui peuvent ne pas être traitées et qui sont des objets de la classe java.lang.RuntimeException. Ce sont elles qu'on appelle exceptions Unchecked. Ce type d'exceptions peut être levé même sans déclaration préalable dans le throws. Ces exceptions sont donc implicites. Ex : ArrayIndexOutOfBoundsExceptions
Attention cependant, l'API de base ne respecte pas tout à fait ce modèle. Dans Java il y a plusieurs branches de checked et unchecked Exception : les classes nommées XxxException ne sont pas toutes des Exceptions ! Par exemple : com.sun.corba.se.impl.io.TypeMismatchException n'est pas une exception mais une erreur. Certaines erreurs n'ont pas le suffixe Error (java.lang.ThreadDeath ou com.sun.tools.javac.jvm.ClassWriter$StringOverflow), de même sun.tools.java.AmbiguousMember est une exception, il faudra donc être particulièrement attentif à la hiérarchie.
On va alors pouvoir décliner ces exceptions en plusieurs types :
- Les exceptions applicatives (fonctionnelles) : par exemple SoldeInsuffisantException
- Les exceptions techniques ou explicites Java : par exemple SQLException ou IOException
- Enfin, les exceptions technique de la JVM : NullPointerExceptions, ArrayIndexOutOfBoundsException...
Globalement une bonne pratique à appliquer est de n'attraper que les exceptions que l'on sait traiter (dans 95% des cas 'tracer une exception dans un fichier de log' n'est pas 'traiter une exception). Si l'on ne sait pas quoi faire d'une exception, il vaut mieux la laisser remonter. En dernier lieu une couche de framework devra les rattraper et afficher une page d'erreur à l'utilisateur avec un message sympathique et non une stacktrace.
De plus, les exceptions requièrent du design (une hiérarchie d'exceptions) afin de vous permettre de les lancer/attraper finement et d'avoir une remontée informative des erreurs. De plus Java 7 permettra de rattraper plusieurs exceptions en une seule déclaration. L'exemple suivant montre un anti-pattern de gestion des exceptions classique qui va poser plusieurs problèmes. D'une part l'utilisateur ne sait pas qu'il s'est produit un problème, d'une autre les développeurs et l'exploitation ne savent pas quel problème s'est produit précisément car on n'inscrit rien d'exploitable dans les logs.
<br>try {<br> Connection con = connectionManager.getConnection();<br> Statement st = con.createStatement("select * from maTable");<br> ResultSet rs = st.executeQuery();<br> MyFile f = new File("monfichier");<br> f.writeResultSet(rs)<br>} catch (TechnicalException ex) {<br> logger.error("TechnicalException !!! ");<br>} catch (FunctionnalException ex2) {<br> logger.error("FunctionnalException !!!");<br>}<br>
Il vaudrait mieux envisager un traitement de ce type :
<br>try {<br> Connection con = connectionManager.getConnection();<br> Statement st = con.createStatement("select * from maTable");<br> ResultSet rs = st.executeQuery();<br> MyFile f = new File("monfichier");<br> f.writeResultSet(rs);<br>} catch (SQLException sqlex) {<br> throw new WorkflowStepException(ioex);<br>} catch (IOException ioex) {<br> throw new WorkflowStepException(ioex);<br>} catch (WorkflowStepException wkflowex) {<br> rollbackWorkflowForStep(Step.GET_TABLE_AND_WRITE, wkflowex);<br>} catch (FileNotFoundException ex) {<br> processCreateFichierNotExisting();<br>} catch (SQLTimeoutException) {<br> sendMailDatabaseIsDown();<br>}<br>
Bonnes pratiques :
Voici un listing de quelques bonnes pratiques assez communes sur la gestion des exceptions en Java. Bien entendu ce sujet amène toujours à discussion et il ne s'agit pas là d'un modèle universel à appliquer dans tous les contextes mais plutôt de patterns à retenir.
Ne jamais ignorer une exception ...
.. par exemple par un catch vide contenant juste un log ou affichage de la stacktrace.
L'exemple à ne pas faire (et pourtant si fréquent dans nos applications):
<br>try {<br> maMethodeQuiPlante();<br>} catch (Exception ex) {<br> logger.debug("Exception :" + ex.getMessage());<br> ex.printStackTrace();<br>}<br>//Non<br>
Il vaudrait mieux envisager quelque chose comme cela :
<br>try {<br> maMethodeQuiPlante();<br>} catch (MaMethodException ex) {<br> processProblem(ex);<br>}<br>//Oui<br>
Dans le cas ou l'on ne sait pas quoi faire dans le bloc catch : laisser remonter l'exception à un composant technique qui saura en faire quelque chose, ou au pire affichera une page d'erreur à l'utilisateur.
Utiliser throws de manière exhaustive
Si on a Exception A héritée par B et C on met throws A,B,C et pas throws A afin de savoir ce qui s'est vraiment passé.
<br>class AException extends Exception;<br>class BException extends AException;<br>class CException extends AException;<br><br>void maMethod() throws A // Non<br>void maMethod() throws A,B,C // Oui<br>
Les exceptions ne sont pas faites pour le contrôle de flux
Ce mode de fonctionnement n'est pas efficace, difficile à relire et à modifier.
Exemple :
<br>//monattribut est null<br>try {<br> monattribut.maMethod();<br>} catch (NullPointerException npe) {<br> context.reAskAttribute();<br>}<br>
Il vaudrait mieux faire :
<br>if (monattribut != null) {<br> monattribut.maMethod();<br>} else {<br> context.reAskAttribute();<br>}<br>
De plus, une NullPointerException ne devrait pas être attrapée : il s'agit toujours d'un bug à corriger dans son code.
Pattern d'entrées/sorties
Pour les entrées sorties utiliser le pattern suivant. Le code en soit n'a bien sûr pas d'intérêt : il ne fait que présenter la construction du try/catch/finally)
<br>try{<br> //declaration de la ressource<br> File file = new File("monfichier.txt")<br> try{<br> //utilisation de la ressource<br> file.write("un truc");<br> } finally {<br> //fermeture de la ressource<br> file.close();<br> }<br>} catch(IOException ex) {<br> //traitement de l'exception<br> traitementException(ex);<br>}<br>
Pas de return dans un bloc finally
Le return permet de quitter la méthode en cours d'exécution. Mais si un finally existe, ce dernier sera tout de même exécuté. Le bloc finally doit uniquement servir à maintenir l'intégrité et notamment libérer des ressources utilisées par le bloc try (cf. exemple précédent). Exemple :
<br>public String retourDansUnFinally(){<br> try{<br> throw new RuntimeException("Je veux planter");<br> } finally {<br> return "Non !";<br> }<br>}<br><br>@Test<br>public void testRetourDansUnFinally(){<br> assertEquals("Non !", retourDansUnFinally());<br>}<br>
Ce test passera au vert. Dans ce cas l'erreur saute aux yeux, mais si l'exception est levée par une méthode dont la taille dépasse celle de l'écran on ne verra plus rien.
Utiliser les exceptions standards
Evitez de réinventer la roue. Tout le monde les connait, votre code sera donc plus facilement lisible. De plus elles sont documentées (javadoc) et sont adaptées aux cas prévus (FileNotFoundException, SQLException, NullPointerException, TimeoutException ...)
Une exception peut en cacher une autre
En rattrapant une exception on peut décider d'en lancer une autre. Il faut toutefois utiliser le constructeur d'exception qui peut prendre une exception en paramètre afin d'éviter de perdre les informations associées à la première. Il est aussi conseiller de lui adjoindre un message explicite.
<br>throw new CustomException("message explicite", <br> otherException);<br>
Ne pas utiliser de codes de retour dans des exceptions
Il faut faire le deuil des codes retours, les exceptions ont été conçues pour fiabiliser ce modèle. Par exemple SQLException qui oblige à l'attraper pour analyser son contenu...
<br>try {<br>...<br>} catch (SQLException e) {<br> if (e.getErrorCode() == 42) {<br> responseToUniverse();<br> } else {<br> throw e;<br> }<br>}<br>
Ne pas déclarer/attraper des erreurs plus large que celle qui peuvent survenir
- Une méthode lance A ou B qui héritent de C, on mettra throws A, B et pas throws C car si une nouvelle exception hérite de C on sera susceptible de l'attraper sans savoir la traiter. - Un autre cas peut s'illustrer par l'exemple suivant :
Imaginons une interface SimpleInterface déclarant une méthode 'public void work()' Cette interface a de nombreuses implémentations dont certaines inconnues (développées par d'autres équipes par exemple), mais mon code (Boss) peut exécuter toutes ces implémentations. Le code la classe Boss pourrait ressembler à cela :
<br>public void manage(Team team) {<br> for (IEmployee teamMember : team.getMembers()) {<br> try {<br> teamMember.work();<br> reportGoodMember(teamMember);<br> } catch (Exception e) {<br> rememberThisGuyForHisEndOfYearNegociation(teamMember);<br> }<br> }<br>}<br>
Nous avons vu qu'il n'y a aucune raison d'attraper si large - ici : toutes les exceptions. En effet, le compilateur nous garantit qu'on ne peut pas avoir autre chose qu'une RuntimeException ou une Error car l'interface de la méthode work ne déclare aucune exception. Le code suivant est donc équivalent et serait suffisant :
<br>public void manage(Team team) {<br> for (IEmployee teamMember : team.getMembers()) {<br> try {<br> teamMember.work();<br> reportGoodMember(teamMember);<br> } catch (RuntimeException e) {<br> rememberThisGuyForHisEndOfYearNegociation(teamMember);<br> }<br> }<br>}<br>
Cependant, puisque le code fait la même chose, on peut penser que ça ne pose pas de problèmes. C'est vrai, mais cela peut très vite devenir problématique si l'on décide finalement de propager l'erreur.
<br>public void manage(Team team) throws Exception {<br> for (IEmployee teamMember : team.getMembers()) {<br> try {<br> teamMember.work();<br> reportGoodMember(teamMember);<br> } catch (Exception e) {<br> if (e instanceof LeReveilNAPasSonneException) {<br> rememberThisGuyForHisEndOfYearNegociation(teamMember);<br> } else {<br> throw e;<br> }<br> }<br> }<br>}<br>
Dans ce cas, la méthode manage va devoir déclarer des exceptions qu'elle ne lancera jamais (le compilateur le garantit). Et le code appelant la méthode manage va devoir gérer des exceptions qui ne se produiront jamais. C'est un peu subtil mais très important à comprendre. En effet, étant donné que la méthode manage déclare maintenant un throws Exception dans sa signature, elle déclare qu'elle peut lancer tout type d'exception : on doit entourer ses appels d'un try / catch correspondant au scope du throws (ici exception). Donc bien qu'on ai tenté de traiter une exception dont on sait quoi faire (bonne pratique), on force le code appelant à attraper toutes les exceptions qui étendent Exception (mauvaise pratique). Or il n'y a aucune de chance que le code de la méthode manage puisse toutes les lancer ...
La solution à ce problème est donc :
<br>public void manage(Team team) {<br> for (IEmployee teamMember : team.getMembers()) {<br> try {<br> teamMember.work();<br> reportGoodMember(teamMember);<br> } catch (LeReveilNAPasSonneException e) {<br> rememberThisGuyForHisEndOfYearNegociation(teamMember);<br> }<br> }<br>}<br>
Si une autre exception remonte, on ne sait pas la traiter, donc on l'ignore (on la laisse se propager) et une couche technique supérieure devra la gérer.
Bien entendu cet article n'est pas exhaustif, mais nous espérons que ces quelques bonnes pratiques vous aideront à implémenter une gestion des erreurs appropriée et suffisamment informative.