La gestion des données de tests en Delivery de Machine Learning
« […] successful teams had adequate test data to run their fully automated test suites and could acquire test data for running automated tests on demand.
In addition, test data was not a limit on the automated tests they could run. »
Extrait de: Forsgren PhD. « Accelerate. »
Cet article fait partie de la série “Accélérer le Delivery de projets de Machine Learning” traitant de l’application du modèle Accelerate dans un contexte incluant du Machine Learning.
Introduction
Est-ce que vous avez déjà :
- Eu un encodage one-hot qui bug en production car une catégorie est présente et vous ne l’aviez pas envisagé en phase de construction de votre projet ?
- Essayé de réentraîner un modèle avec “les mêmes données” (à peu près) sans parvenir à obtenir le même résultat ?
- Voulu tester votre code de Machine Learning mais sans savoir comment avoir des données de tests pertinentes ?
- Souffert de tests trop lents ?
Si vous avez répondu oui à une de ces questions, cet article est fait pour vous.
Tester dans un projet de Machine Learning Delivery est nécessaire pour s’assurer de la qualité des artefacts produits (si vous n’en êtes pas encore convaincu, cet article présente en détail les tests automatisés en Machine Learning). Pour tester, il faut des données de test, et beaucoup d’équipes souffrent de la gestion de ces données. Le livre Accelerate cite la gestion des données de tests comme l’une des 24 capacités sur lesquelles il faut s’améliorer pour être plus performant en Delivery.
Accelerate propose trois axes de travail sur les données de tests :
- Leur pertinence,
- La liberté d'en obtenir à la demande,
- Qu’elles ne limitent pas les tests possibles à mettre en place.
Dans cet article, nous vous proposons de travailler, dans le cas particulier du Delivery de Machine Learning, sur ces trois axes ainsi qu’un quatrième : le format et le versionning des données de tests.
Pourquoi la gestion des données de tests est-elle différente dans un projet embarquant du Machine Learning ?
Dans un projet impliquant du Machine Learning, la donnée est un élément central. En effet, elle est au cœur des étapes d’entraînement, d’inférence et de monitoring du modèle.
Les Data Scientists construisent des modèles et développent du code. Ces deux objets doivent être testés. Les tests du code requièrent des données que nous appellerons dans la suite de l’article données de test du code. Les tests ou évaluations des modèles se font eux sur des données historiques connues afin de mesurer la performance. Nous appellerons ces données historiques test set.
Ces deux types de données peuvent être vus comme des objets très différents, mais ont aussi beaucoup de points communs. Nous choisissons volontairement de faire un article qui traite des deux car les pratiques liées à ces objets sont connexes.
Dans un projet embarquant un modèle de Machine Learning, les données de test du code sont très similaires à un projet sans Machine Learning. Les principales différences viennent du test set. Pour être pertinent dans l'évaluation d'un modèle, le test set devrait être statistiquement représentatif des individus sur lesquels le modèle fera des inférences en production. Cela implique que :
- Le test set sera souvent volumineux .
- Il peut y avoir des enjeux de confidentialité et de protection des données personnelles.
- Il faudra mettre à jour le test set, non pas uniquement quand le code change, mais aussi quand les données de production changent. On a donc un changement subit et non pas choisi par les Data Scientists.
- Dans le cas des problèmes faisant appel à la labellisation, il faut labelliser le test set.
Pour tester efficacement, de “bonnes” données de test doivent être représentatives des situations rencontrées en production, permettent d’avoir des tests reproductibles, sont maintenables, respectent les éventuelles contraintes légales. Dans la suite de cet article, nous allons donc voir différentes pratiques d'obtention, de versionning et d’accessibilité des données de tests à la fois pour les test set et pour les données de test du code.
Avoir des données de tests pertinentes
Dans cette partie, nous proposons trois façons d’obtenir des données de tests : les créer manuellement, les simuler, les extraire des données de production. Chaque façon de faire a ses avantages, ses inconvénients et donc ses usages. Nous allons approfondir cela dans cette partie.

Créer manuellement des données de test
Créer manuellement des données de tests est la pratique traditionnelle en développement logiciel. Concernant la brique de Machine Learning, il est intéressant de procéder ainsi pour tester le code, en particulier le code de construction de variables (feature engineering).
Créer les données de tests manuellement permet de lister l’ensemble des cas que l’on souhaite tester. Par exemple, sur la fonction extract_brand présenté en figure n, tester le cas où il y a la marque et le modèle, la marque seule et rien dans la colonne.
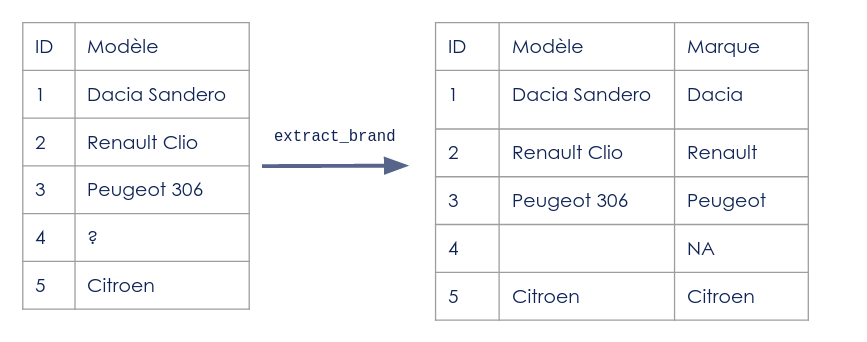
Figure 1 : Exemple de fonction de feature engineering
Pour créer des données pertinentes, il convient d’explorer les données de production pour s’assurer que l’on oublie pas de cas et que l’on teste uniquement des cas qui existent vraiment (éviter la sur-ingénierie).
Nous recommandons cette méthode pour écrire des tests unitaires car elle permet de maîtriser ce que l’on teste. Cette méthode ne sera pas adaptée pour les tests nécessitant de grands volumes de données (tests de performance, certains tests d’intégrations ...) car créer plusieurs centaines ou milliers d’exemples est fastidieux. Également, cette méthode n’est n’est pas pertinente pour évaluer la performance d’un modèle.
Simuler des données de tests
Lorsque l’on a besoin de grands volumes de données, par exemple pour des tests d’intégration, il est possible de simuler les données de test. Cela se fait en écrivant du code qui génère de nombreux exemples.
Ce code peut-être simple, à base de tirage aléatoire, ou plus avancé en utilisant des modèles de génération de données (par exemple : Generative Adversarial Networks). Pour creuser les méthodes de génération de données, vous pouvez vous référer à cet article qui rentre dans le détail de la génération de données, et propose quelques méthodes.
Cette approche permet d’avoir de gros volumes de données anonymes et moins confidentielles. Il restera probablement un peu de sens métier dans vos données, en effet si votre base de données ne contient que des voitures de marque Renault, alors tous les exemples de voitures générés seront des Renault.
En utilisant cette méthode, il est important d’avoir conscience que les données générées reflètent les hypothèses prises. Par exemple, en générant 50% d’images de voiture bleue, et 50% d’images de voiture rouge, nous prenons l'hypothèse que les données de production obéissent strictement à cette répartition. Le choix de l’algorithme de génération de données cache l'hypothèse que cet algorithme est capable de simuler correctement les données de production (le choix de la mesure du “correctement” est également une hypothèse). Ces hypothèses sont parfois fausses, et en tout cas difficiles à maintenir dans le temps. Maintenir ces hypothèses dans le temps requiert de détecter lorsqu’elles deviennent fausses et mettre à jour le code de génération des données.

Figure 2 : Différence de distributions de couleurs de voitures
Ainsi les données générées peuvent être utilisées pour des tests de performance en temps de calcul, ou comme test set. Dans ce deuxième cas, les hypothèses citées plus haut requièrent beaucoup de prudence. Cette prudence peut se concrétiser en implémentant une boucle de feedback rapide sur la validité des hypothèses et sur la performance réelle du modèle en production.
Finalement, et pour faire le lien avec la dernière façon d’obtenir des données de tests, il est possible d’utiliser la génération de données pour faire de la data augmentation, pratique qui consiste à compléter les données de production avec des données générées en appliquant des petites modifications aux données originales (comme illustré en figure n avec des chiens), pour améliorer les performances du modèle. Cela requiert donc d’avoir également des données de production.

Récupérer des données de production
La dernière technique est donc la récupération des données de test en les extrayant de la production. Pour cela, il faut soit faire un export manuel, soit écrire un script qui permet de les récupérer automatiquement.
Il est parfois plus long de mettre cela en place, car il faut avoir les accès, le droit de les utiliser et éventuellement pseudonymiser les données.
Cette pratique est utile pour tester les performances du modèle de Machine Learning. Mais peut ralentir les tests du code du fait du volume des données de test ou du temps nécessaire à les obtenir.
Stocker et versionner les données de tests
Afin de garantir l’indépendance et la reproductibilité des tests, ceux-ci ne doivent pas altérer les données de tests. Il devient alors important d’avoir une gestion minutieuse de ces données notamment en les versionnant. Dans cette partie, nous vous proposerons 3 formats pour les données de tests, chaque format a ses avantages et inconvénients. Avec ces 3 types, vous pourrez gérer l’ensemble des situations pour tester dans un projet embarquant du Machine Learning.
Des objets métier
Les données de tests peuvent être écrites sous forme d’objets métier, implémentés dans le code. Par exemple :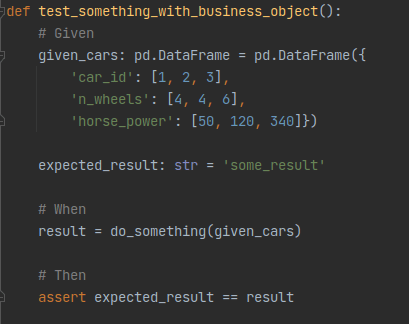
Les objets métier peuvent être utilisés pour plusieurs tests. Dans ce cas, pour éviter la duplication de code et faciliter la maintenabilité, l’objet métier pourra être extrait dans une fonction qui permet de le créer. Cette extraction au format fonction permet également de paramétrer l’objet en fonction d’arguments (exemple : le nombre de lignes dans le data frame).
Avantages :
- Ces objets sont pratiques, car ce sont des lignes de code, elles sont donc versionnables et les différences entre deux versions peuvent être faciles à identifier.
Inconvénients :
- Il peut être parfois pénible de les écrire, et ils peuvent vite devenir volumineux en nombre de lignes de code. Un data frame de plusieurs milliers de lignes risque de rendre un test difficile à maintenir.
Nous recommandons d’utiliser des objets métier qui ont du sens et éviter de mettre des valeurs par défaut (comme nous l’avons fait dans notre exemple). Si votre id est un identifiant d’une voiture, mettez l’identifiant d’une voiture réelle, cela rendra les tests plus facilement compréhensibles.
Des fichiers de données
Une autre façon d’avoir des données de tests est de manipuler des fichiers de données (au format .csv, .parquet, .json, etc.). Ces fichiers seront idéalement au même format que les fichiers que vous manipulez en production pour éviter d’avoir à développer du code de lecture de fichier spécifique pour vos tests.
Ces fichiers sont alors chargés au moment du “# Given” (selon le formalisme Given / When / Then) pour constituer les objets que vous souhaitez manipuler.
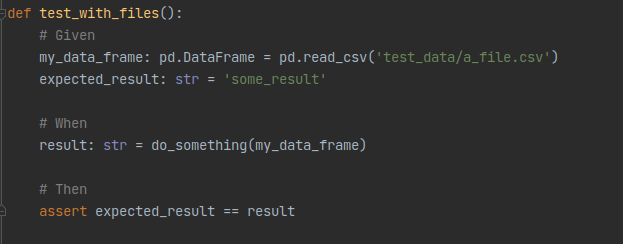
Ils peuvent être versionnés avec le code si leur taille est relativement faible et que les données ne sont pas sensibles, ou avec des outils de versionning de fichiers lourds tels que DVC et GitLFS. Identifier une différence entre les différentes versions d’un même fichier sera plus difficile que comparer des lignes de code.
Nous souhaitons insister sur l’idée de versionner les données avec le code, si elles ne pèsent que quelques Ko, cela sera suffisant et évitera de mettre en place et maintenir des outils supplémentaires.
Une alternative à DVS ou GitLFS, pour versionner le test set est de le stocker à un seul endroit (à condition que l’évaluation du modèle ait toujours accès à ce stockage) et de suffixer les noms de fichiers avec un numéro de version ou un time stamp. Ce numéro de version est lié à la gestion des versions des expérimentations telles que présentées dans la capacité “Gestion des versions” de cet article.
Avantages :
- L’avantage de cette approche est qu'elle permet d’avoir de plus grands volumes de données qu’avec les objets métier précédemment présentés.
- Ces fichiers de données sont versionnables
Inconvénients :
- Manipuler de gros fichiers de test à récupérer sur des systèmes externes pour exécuter des tests risque de les ralentir.
Des “requêtes”
Une dernière idée est de ne pas versionner les données, mais les requêtes qui permettent de les récupérer. Par exemple : pour entraîner mon modèle, je prends toutes les photos datées entre le 26/09/2020 et le 10/10/2020.
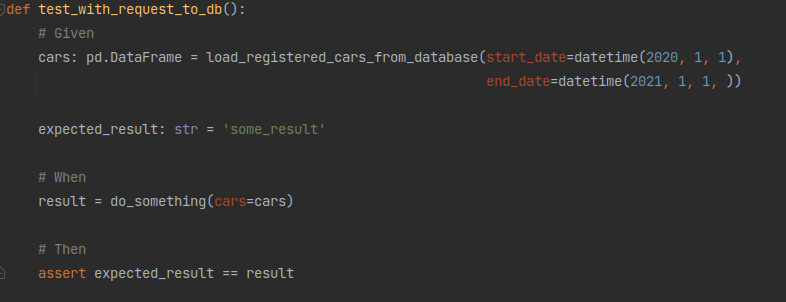
Pour que cela fonctionne, il faut s’assurer que les requêtes sont reproductibles, c'est-à-dire que deux exécutions d’une requête donnent exactement le même résultat.
- Exemple de requête reproductible : Toutes les images prises entre le 26/09/2020 et le 10/10/2020
- Exemple de requête non reproductible : Toutes les images depuis le 26/09/2020
Avantages :
- Ces requêtes sont facilement versionnables dans le code de test et les différences entre deux versions de la même requête sont faciles à comprendre.
- Cela évite de dupliquer des données de production.
- C’est une approche minimaliste qui permettra de réutiliser du code que vous avez déjà développé pour votre application.
Inconvénients :
- Il faut que les machines exécutant ces tests aient accès aux données.
- Les tests peuvent être lents s'il y a un grand volume de données à récupérer.
- Si les données source changent, les tests ne passeront plus et identifier la source de changement sera difficile.
Cette technique n’est plus vraiment du versionning de données, mais du versionning de test. Elle nous semble intéressante pour limiter la duplication de données mais elle a la contrainte forte de nécessiter la stabilité des données : c’est-à-dire qu’elles ne sont ni mises à jour ni supprimées. En fonction du contexte, il peut être intéressant d’implémenter un monitoring qui s’assure de la stabilité des données.
Au vu de ces avantages et inconvénients, cette stratégie nous semble être adaptée à la gestion du test set dans les cas où les données sont volumineuses et que la base de données est stable.
Avoir accès à la demande à des données de tests
Rendre accessibles les données de tests …
Pour faciliter la mise en place de tests de code, mais aussi la mise en place d’évaluations des modèles avec des test set, il faut pouvoir avoir accès facilement, à la demande, à des données de test.
Il existe plusieurs moyens de rendre les données de production accessibles :
- Le stockage à froid, en dupliquant les données de production via des routines régulières dans un espace de stockage (un disque, une base de données, etc.) accessible par les développeurs.
- En produisant régulièrement des test sets à partir des données de production afin que les données de test (train ou validation) restent pertinentes (c’est-à-dire représentatives de la population de production). Ces data sets peuvent être stockés dans un stockage froid également. Nous attirons cependant votre attention sur le fait que dans un projet requérant de l’annotation, il faudra également annoter ces tests sets (Pour aller plus loin sur l’annotation : Deep Learning à l'échelle : mieux annoter pour mieux scaler | OCTO Talks !).
- En produisant et en maintenant du code d’ETL qui permet d'accéder, de transformer et de transporter des données de production.
L’obtention de nouvelles données de test est nécessaire dans deux cas :
- Lorsque le code change, les nouvelles données sont nécessaire pour le tester,
- Lorsque les données de production changent, de nouvelles données de tests sont nécessaires pour évaluer les modèles. Le test set a ainsi une durée de vie limitée.
Si le premier cas n’arrivera que pendant la phase de construction de votre projet, le deuxième arrivera tout au long du cycle de vie de votre projet. Bien outiller l’accès aux données de test est ainsi extrêmement important dans le cadre d’un projet de Machine Learning.
… tout en prenant en compte les contraintes de confidentialité
Le règlement général sur la protection des données (RGPD), les différentes contraintes de confidentialité peuvent amener à apporter des restrictions sur l’utilisation et la prolifération des données de production dans d’autres environnements. Nous avons identifié les contraintes suivantes, et nous proposons quelques solutions à mettre en place pour limiter l’impact sur votre capacité à écrire des tests :
| Contrainte éventuelle | Dans quel contexte cela s'applique-t-il ? | Propositions de solutions à mettre en place |
| Droit à la modification / suppression des données personnelles | En cas de manipulation de données personnelles | Mettre en place un tracking des individus utilisés dans les données de test pour réaliser les mises à jour.<br><br>Réaliser les tests du code avec des données construites ou simulées<br><br>Réaliser les entraînements dans l'environnement de production et relancer un entraînement à chaque fois qu’une modification ou une suppression est réalisée. |
| Non-propagation des données dans d’autres environnements que la production | Lorsque l’implémentation des contraintes de sécurité est différente selon les environnements | Réaliser l’entraînement des modèles en production<br><br>Réaliser les tests du code avec des données construites ou simulées<br><br>Pseudonymisation des données |
| Limites d’accès aux données (requièrent des droits spécifiques) | Lorsque la liste des individus (personnes ou machines) ayant accès aux données est limitée et les accès sont monitorés. | S’assurer que l’entraînement, l’évaluation, l’inférence aient un droit d’accès.<br><br>Générer des données de test du code à partir de métadonnées extraites des données protégées. |
| Principe de minimisation | En cas de manipulation de données personnelles | S’assurer que l’on utilise uniquement les données qui sont utiles aux modèles. Par exemple en mettant en place de la sélection de caractéristiques. |
En plus de ce tableau, nous souhaitons approfondir deux thématiques : le droit à la modification / suppression et le principe de minimisation.
Droit à la modification / suppression
Le droit à la modification / suppression des données personnelles est la contrainte qui nous semble la plus challengeante car elle a un impact pendant la conception et pendant le run du projet.
Cette contrainte vient challenger l’objectif de reproductibilité de nos tests, de nos entraînements. Dans un tel contexte, il convient donc de :
- Commencer par minimiser la place prise par des données pouvant être modifiées / supprimées en les utilisant uniquement pour de l’entraînement et l’évaluation de modèles.
- Ensuite s’assurer que les modifications / suppressions sont bien propagées aux test set.
- Finalement tracer lorsqu’une modification / suppression a lieu pour 1. acter la non-reproductibilité des entraînements / évaluations passés et 2. relancer de nouveaux qui serviront de nouvelles références.
La CNIL indique que “Le responsable du fichier doit procéder à l’effacement dans les meilleurs délais et au plus tard dans un délai d’un mois, qui peut être porté à trois compte tenu de la complexité de la demande.” (source). Il est donc possible d’implémenter la prise en compte des demandes de modifications / suppression en flux ou en batch réguliers.
Rappelons également que l’utilisation des données personnelles dans les tests est conditionnée au consentement de la personne à cet usage (finalité) de ses données.
Principe de minimisation
Appliquer le principe de minimisation, nous amène à limiter les données de tests (en particulier le nombre d'attributs) au strict nécessaire. Cela permet de :
- Simplifier la stratégie de versioning des données et les outils à mettre en place.
- Accélérer la boucle de feedback donnée par les tests en diminuant
- Le temps pris pour récupérer les données de tests (ce temps dépend des contraintes réseau)
- Le temps pour charger les données en mémoire (qui est d’ailleurs limitée)
- Le temps d’exécution des tests
- Minimiser la propagation de données confidentielles ou personnelles
- Améliorer la maintenabilité des tests.
Limiter les données de tests, c’est appliquer le principe YAGNI.
En synthèse
Le respect des contraintes imposées par les régulateurs n'exclut pas d’identifier des solutions qui permettent de faciliter la mise en place des tests. Nous recommandons d’implémenter les contraintes des régulateurs en choisissant la solution qui facilitera le plus la mise en place de tests automatisés.
Les données de tests ne doivent pas être une limite aux tests possibles à mettre en place.
Afin d’avoir confiance dans la qualité du code et des modèles, nous mettons en place des tests automatisés. La donnée est centrale dans ces tests. Les différentes contraintes techniques, légales, business ne doivent pas nous empêcher de mettre en place des tests automatisés.
Dans les parties précédentes, nous avons vu comment faciliter l’accès et l’utilisation de données de test tout en prenant en compte les contraintes légales. Dans cette partie nous souhaitons approfondir le fait que même l’indisponibilité de données ne doit pas être contraignante.
Dans le cadre de tests du code, l’indisponibilité de données peut être contournée en créant les données manuellement.
Dans le cadre de la constitution du test set pour évaluer le modèle, cette indisponibilité peut nous empêcher :
- D’évaluer le modèle, si ce sont les labels qui sont indisponibles,
- D’évaluer correctement le modèle, si une partie de la population qui sera soumise au modèle est absente de la base de données.
- De contrôler d'éventuels biais, si ce sont les caractéristiques sociales qui sont manquantes,
Pour contourner les problèmes d’évaluation des modèles, il est possible de déployer un modèle générique (par exemple une règle métier, ou un modèle qui marche de manière générale) afin de commencer à collecter des données afin de pouvoir par la suite créer un nouveau modèle plus performant que l’on pourra mieux évaluer.
Exemple : avant d’avoir un modèle spécifique aux voitures bleues, commencer par déployer un modèle générique à toutes les voitures, collecter des images de voitures bleues et les faire annoter.
La mise en place de tests automatisés de non-discrimination est elle bien plus difficile, car en Europe il est interdit de collecter des données “qui révèlent la prétendue origine raciale ou ethnique, les opinions politiques, les convictions religieuses ou philosophiques ou l'appartenance syndicale, ainsi que le traitement des données génétiques, des données biométriques aux fins d'identifier une personne physique de manière unique, des données concernant la santé ou des données concernant la vie sexuelle ou l'orientation sexuelle d'une personne physique.” (source CNIL).
Conclusion
En Machine Learning, il y a deux types de données de test, les données de test du code qui sont similaires à celles du logiciel, et le test set qui sert à évaluer les performances des modèles.
Pour tester efficacement, de “bonnes” données de test sont représentatives des situations rencontrées en production, permettent d’avoir des tests reproductibles, sont maintenables, respectent les éventuelles contraintes légales. Elles peuvent être représentées sous forme d’objet métier, de fichiers ou de “requêtes”.
| Méthode d’obtention des données | Format de stockage | Quand les utiliser ? |
| Ecriture manuelle | Objet métier dans du code | Pour les tests unitaires |
| Génération | Code de génération, ou fichiers | Pour des tests de temps de réponse<br><br>Pour tester la performance des modèles (en étant conscient des hypothèses prises) |
| Extraction de la production | Code d’extraction, ou fichiers | Pour tester la performance des modèles, pour tester les pipelines de bout en bout |
Ces données seront versionnées pour assurer la reproductibilité de tests. L’évolution des données en production fait qu’il faudra régulièrement mettre à jour certaines données de tests. Le versionning de ces données de test doit se faire en tenant compte des contraintes de confidentialité et de RGPD, notamment gérer le droit à la modification / suppression des données qui challenge la reproductibilité de nos tests.
Finalement, s’assurer que l’on a le strict minimum en termes de données de tests permettra d’accélérer les tests, de faciliter leur maintenabilité et de limiter la propagation de données confidentielles.