La genèse du modèle réactif

Dans un précédent article, nous avons introduit un nouveau modèle de développement qui émerge de plus en plus : le modèle réactif. C’est un modèle fondé sur la réaction à des événements déclenchés par les périphériques hardware (disque ou réseau essentiellement). Pourquoi seulement maintenant ?
L’objectif principal de ce modèle est la performance :
- réduire la latence,
- répondre plus vite
- et gérer les pics de charges.
A cela s’ajoute la résilience et la scalabilité.
Pour en arriver là, il a fallu une succession d’étapes dans toutes les couches logicielles. Elles ne sont pas encore toutes terminées, mais c’est pour bientôt. Voici un rappel historique des évolutions des systèmes d’information (SI) permettant désormais de proposer ce nouveau modèle.
Pour bien saisir où se trouve la puissance inexploitée, regardons quelques temps moyens pour des traitements classiques d’un SI. Avec un cycle de processeur d’un milliardième de seconde (1 nanoseconde) nous avons les valeurs suivantes.

Cela semble tellement rapide que les développeurs pensent que c’est sans limite. Maintenant, essayons de rapprocher cela à un temps humain. Considérons qu’un cycle processeur dure une seconde et non une nanoseconde. Voici ce que cela donne.

Cinq ans pour faire un aller-retour Europe / USA n’est pas rien ! Cela indique que la latence n’est pas négligeable.
Imaginez-vous un employé ne faisant rien d’autre qu’attendre cinq ans avant de pouvoir traiter le deuxième colis ? Pourquoi l’acceptez-vous pour vos machines ?
L’évolution des paradigmes vers l’approche réactive
Au début de l’informatique, nous avions des interfaces en ligne de commande. Le modèle de programmation dominant était procédural. Puis sont venues les interfaces graphiques. L’écosystème a évolué vers le modèle objet. Enfin, le Web s’est généralisé. Pour y répondre, les développeurs ont massivement exploité les threads et un modèle requête-réponse. Maintenant, vos clients seront de plus en plus reliés en permanence avec votre SI, via les mobiles ou les objets connectés. Ils ont déjà deux ou trois terminaux chacun, demandant une mise à jour régulière et une synchronisation entre tous.
Chaque évolution a généré de nouveaux langages de développement permettant de porter les nouveaux paradigmes. Le modèle objet permet de mieux modéliser des systèmes complexes. Il est, entre autre, une solution aux interfaces utilisateurs fenêtrées. Le clic droit en est le symbole pour l’utilisateur. Il correspond à la liste des méthodes applicables à l’objet.
Le Web a fait émerger des langages profondément multithreads comme Java, avec une syntaxe spécifique pour gérer la synchronisation entre les flux de traitements (synchronized, volatile).
Parmi les nouveaux langages, Scala/Java (Play) ou Javascript côté serveur (node.js) accompagnent l’essor du modèle réactif. D’autres langages ne sont pas en reste.
La gestion du parallélisme a également évolué. D’un modèle évolué pour optimiser le « context switching » lors du passage d’un thread à un autre.
Voici un tableau récapitulant les grandes étapes de l’informatique. Bien entendu, aucune évolution n’a remplacé la précédente. Elles les ont enrichis. Les développeurs ont alors plus ou moins utilisé les nouveaux concepts.
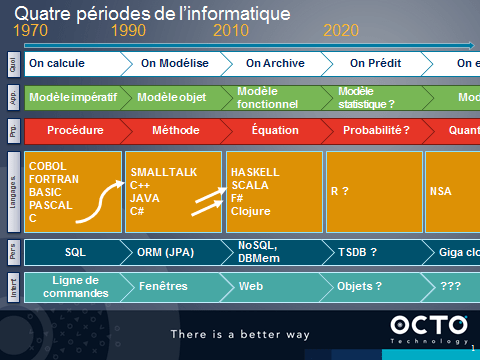
De notre point de vue, nous sommes à l’aube d’une nouvelle approche.
Les étapes
L’objectif principal du modèle réactif est le suivant : réduire la latence. Pour cela, il ne faut plus utiliser des soft-threads mais uniquement des hard-threads. Pour mieux exploiter la puissance CPU, il n’est pas nécessaire de simuler le multitâche (soft-thread). Il est préférable de partager un processeur sur une base événementielle (approche réative) que sur une répartition du temps (approche soft-thread).
Pour atteindre cet objectif, toutes les couches logicielles évoluent.
Pour pouvoir proposer un modèle réactif mature, il a fallu franchir quelques étapes. Elles ne sont pas encore toutes résolues, mais cela ne saurait tarder. Il faut intervenir progressivement sur les couches suivantes :
- Les systèmes d’exploitation
- Les pilotes de périphériques et de bases de données
- Les frameworks
- Les langages de développement
Depuis peu, chaque niveau bénéficie d’évolutions facilitant l’émergence du modèle réactif.
Nous allons voir comment ont évolué les OS et les pilotes aux bases de données.
Evolution des OS
Les OS doivent proposer des API asynchrones.
La première étape importante consiste à recevoir des événements à chaque sollicitation du système par son environnement. Cela peut être la réception d’une trame sur le réseau, l’acquittement de l’émission d’une trame, lorsque le tampon mémoire a été alimenté par les données venant du disque dur, après un calcul d’image sur le GPU, lors d’une saisie clavier, au déplacement d’une souris, etc.
Les OS proposent maintenant des API asynchrones pour permettre cela. C’est le cas sous Windows depuis Windows NT (avec Overlapped I/O) et sous Linux depuis Linux 2.5 (2003). Une des difficultés pour les OS est de communiquer avec les processus pour leur signaler la présence d’un événement. Le modèle choisi par Linux consiste à exploiter la notification par signaux (signal(7)). Ainsi, chaque thread peut être interrompu pour exécuter un signal informant de l’arrivée d’une trame ou la confirmation de sa soumission. Sous Java, le signal débloque un thread dédié en charge des traitements asynchrones.
Comment cela se passe-t-il dans l’OS ? Dans l’exemple d’une communication réseau, deux files de trames sont gérées par l’OS. L’une accumule les trames à envoyer, l’autre les trames reçues devant être traitées par les processus. La carte réseau se charge de vider la file d’émission et d’alimenter la file de réception.
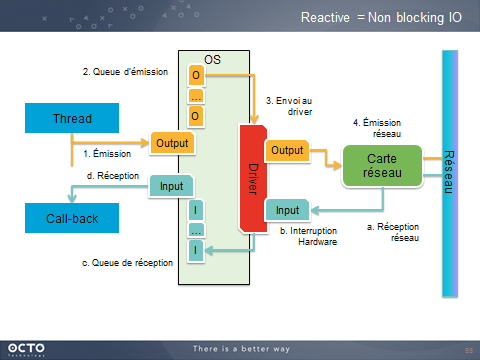
Du point de vue du développement, tant que les files de trames réseaux ne sont pas pleines, il est possible d’en ajouter. Les trames seront réellement envoyées sur le câble ou par les ondes, plus tard.
Ce modèle est appliqué également pour la manipulation des disques ou de tous périphériques (souris, clavier, capteurs, etc.)
Les API des langages ont alors évolué. Java propose depuis Java 1.4 l’API NIO pour « New-IO » et NIO2 pour Java7. L’API est complexe, car les trames réseaux ont des tailles variant d’un à n octets. Comment analyser une requête http avec un seul octet ? Des frameworks proposent alors des surcouches pour agréger les différentes trames, les décoder et informer le programme lorsqu’il y a suffisamment de données pour déclencher un traitement pertinent. Netty est l’un des frameworks les plus connus.
Il est alors facile de réagir à des événements externes. Il y a deux approches possibles. Soit déléguer le traitement à un pool de threads (approche traditionnelle), soit traiter directement le message le plus rapidement possible pour être disponible pour le prochain. La première approche tolère que les traitements dans les threads soient bloquants. Mais cela est au prix d’une multiplication des threads. Difficile de gérer 20 000 clients simultanément (Cf. Notre bench J2EE). La deuxième approche nécessite de n’utiliser que des API non bloquantes. Un mixte des deux solutions est envisageable.
Evolution des pilotes aux bases de données
Pour une architecture réactive, les pilotes de bases de données doivent être non bloquants. On en trouve pour MySQL, MongoDB, etc… Les bases NoSQL ont généralement des API REST, facilement désynchronisables avec un AsyncHTTPClient. Des solutions open-sources sont disponibles.
JDBC est une API bloquante ! Il faudra revoir en profondeur cette norme ou en proposer une nouvelle. C’est une étape importante pour généraliser ce nouveau modèle de développement.
Est-ce que le protocole de la base de données est compatible avec l’approche réactive ?
Evitons de subir les mêmes contraintes qu’avec les threads et la programmation bloquante. Si le protocole d’accès aux données est asynchrone, alors l’artifice qui consiste à augmenter le nombre de connexions pour éviter l’attente de l’acquittement devient inutile.
Est-ce que le protocole de la base de données accepte d’entrelacer des requêtes de plusieurs utilisateurs sur la même connexion ? MySQL le propose. Cette approche permet non seulement d’être réactif, mais de plus, supprime le verrou de la taille du pool de connexions.
De fait, cette démarche applique le modèle réactif adopté pour la gestion des hard-threads.
Et puis...
Les frameworks doivent également évoluer pour proposer des API asynchrones et utiliser en interne uniquement des API non bloquantes. Les librairies des langages évoluent pour proposer des classes permettant de réagir aux événements.
Enfin, les langages eux-mêmes évoluent pour faciliter la rédaction de petits traitements (les closures) ou pour générer un code asynchrone à partir d’un code synchrone.
Nous verrons dans d’autres articles, les différentes stratégies permettant de gérer des traitements parallèles sans utiliser de threads et les évolutions de différents langages permettant de faciliter ce mode de développement.