La Duck Conf 2023 - Guide de survie du CDC - Compte rendu du talk de Mariane Champalier et Baptiste Courbe

Mariane et Baptiste à la Duck Conf 2023
Du legacy au cloud
Imaginez que vous êtes une entreprise dynamique avec un glorieux historique dans la vente de service. Vous avez une base de données sur votre mainframe que vous gérez méticuleusement depuis 30 ans qui contient toutes les informations dont vous disposez sur vos clients, vos agences, vos produits, etc.
Soudain on vous parle de concepts nouveaux. Vous entendez pêle-mêle les mots: move to cloud, machine learning, infinite scaling. Tout cela attise votre curiosité. Vous vous rendez compte que votre base de données legacy n’est pas capable de gérer vos besoins analytiques croissants.
Après avoir soigneusement évalué la situation, c'est décidé : vous embarquez pour le cloud ! Votre direction vous donne 6 mois.
Mais pas si vite ! Bon nombre de vos services en production utilisent votre base sur mainframe. Les pertes de données et interruptions de services ne sont pas envisageables pour vos métiers, qui ne voient pas bien ce que vous voulez faire avec ce machine learning. Pour eux, il est hors de question de perturber la base. Votre rêve d’infrastructure cloud et de services managés tombe à l’eau.
À moins que…
C’est là qu’interviennent Baptiste et Mariane, respectivement Data Architect et Data Engineer chez Octo Technology ! Pendant leur talk à la Duck Conf 2023, ils vous expliquent comment mettre en place une architecture qui vous permet de tirer parti de tous les avantages du cloud sans perturber vos systèmes legacy.
Ils commencent par vous décrire 3 approches:
Écriture en Y
Vos sources de données écrivent en parallèle sur votre base de production existante sur mainframe et sur votre base analytics sur le cloud. Cela demande d’assurer constamment la synchronisation entre les 2 bases et ajoute de la complexité au système.Architecture événementielleVos sources de données écrivent dans un bus de messages qui envoie les modifications à vos 2 bases. Ce type d’architecture demande souvent une refonte importante de vos SI (création et gestion d’un bus de message) sans forcément répondre à toutes les contraintes exprimées par vos métiers.
Change Data CaptureLes changements sur votre base de production sont répliqués dans votre base analytics cible sur le cloud. Ce type d’architecture est relativement rapide et simple à mettre en place. C’est cette solution que Baptiste et Mariane ont retenue.
Change Data Capture
Mais qu’est-ce que le Change Data Capture exactement ? (CDC pour les intimes)
Il s’agit d’un type d’architecture dans lequel on détecte et enregistre toutes les modifications apportées à une base source pour déclencher des traitements sur une base cible. Chaque modification est envoyée dans une file de messages, puis traitée et appliquée sur la base cible. Le but est de créer un miroir de votre base source.
Dans votre cas, votre base source est une base IBM DB2 et comme vous avez déjà fait des analyses avec BigQuery par le passé, vous choisissez une base PostGreSQL sur CloudSQL dans Google Cloud Platform (GCP) comme base cible.
Pourquoi PostgreSQL et pas BigQuery ?
BigQuery est une base OLAP, adaptée pour les lourdes tâches d’analyses, mais pas optimale pour un haut débit de lecture/écriture (qui représentent une majorité de vos besoins métiers). PostgreSQL est une base OLTP qui est adaptée à ce haut débit. CloudSQL est un service de GCP qui vous permet d’héberger une base PostgreSQL, vous pouvez ensuite manipuler facilement la donnée dans BigQuery.
Pour votre file de message, vous aimeriez un outil que vos équipes connaissent déjà (pour aller plus vite) et hébergé on-premise (pour anonymiser la donnée client avant de l’envoyer sur le cloud). Cela tombe bien, Kafka répond à ces deux besoins !
Précisions sur Kafka : Kafka est un bus de message dans lequel un publisher écrit des messages dans des topics. Des subscribers peuvent s’abonner à des topics pour lire les messages.
Vous avez aussi besoin d’un agent CDC. Il s’agit d’un service installé sur votre base de production qui va écouter les logs de votre base, capter chaque modification, et les envoyer dans votre cluster Kafka.
Enfin, il vous faut des connecteurs pour lire les messages de votre cluster Kafka et les appliquer dans GCP. Kafka Connect fournit un catalogue de connecteurs déjà implémentés. Si vous n’y trouvez pas votre bonheur, vous pouvez construire votre propre connecteur.
Grâce à cette architecture, Baptiste et Mariane ont pu gérer jusqu’à 2 milliards d’événements lors d’une reprise d’historique et plusieurs centaines de tables répliquées en temps réel !
Vous avez mis cette architecture en place et vous voyez maintenant vos données se propager petit à petit de votre mainframe jusque dans votre base sur le cloud. Vous êtes ravis et tout va pour le mieux. Tout à coup, un voyant rouge s’allume, puis un autre, très vite vous êtes submergés d’alertes. Que se passe-t-il ?
Comme tout Data Architect le sait, ce n’est pas tout de mettre en place une architecture. Il faut aussi faire en sorte qu’elle soit résiliente et maintenable.
En bons architectes, Baptiste et Mariane ont anticipé ces problèmes et vous proposent un guide de survie du CDC.
Guide de survie
Le monitoring
Faut-il mettre en place le monitoring après le développement de la solution ou embarquer le monitoring directement dans la solution ?
“L’avantage de faire le monitoring en même temps que les devs c’est qu’au moment où on en a besoin il est déjà en place” - Mariane
C’est exact. Mettre en place le monitoring le plus tôt possible permet de gagner un temps précieux par la suite. Cependant cela demande plus de temps en amont. Or vous êtes pressés car les 6 mois qu’on vous a donné fondent comme neige au soleil. Vous décidez donc de prioriser les fonctionnalités et de remettre le monitoring à plus tard. Cependant, vous êtes d’accord qu’il faut mettre en place du monitoring à terme, avant la mise en production.
Baptiste et Mariane vous proposent de commencer simple et d’utiliser les outils déjà en place dans vos SI. Vous avez déjà une stack ELK (ElasticSearch - LogStash - Kibana) pour remonter et visualiser vos logs. Ils vous proposent aussi d’installer des agents MetricBeat sur vos composants pour remonter des métriques. Avec ces premiers outils déjà présents dans votre SI, vous pouvez construire un dashboard pour monitorer vos ressources.
Votre dashboard en place, vous vous rendez compte que MetricBeat vous envoie beaucoup de métriques. Trop de métriques en fait. Baptiste et Mariane vous conseillent de choisir les métriques que vous souhaitez conserver afin de vous concentrer sur l’essentiel. Par exemple, le nombre de messages par topic est une des métriques principales. Celle-ci vous permet de savoir si l’agent CDC continue à capter les modifications sur les tables que vous souhaitez répliquer... Sur les conseils de Baptiste et Mariane vous sélectionnez aussi des métriques systèmes: espace disque, réseau, cpu,... afin d’évaluer la santé de votre cluster Kafka. Au niveau de vos connecteurs, ils vous incitent à surveiller le lag, qui est le nombre de messages dans Kafka pas encore appliqués sur GCP. Idéalement, celui-ci doit valoir 0, ce qui signifie que vos 2 bases sont parfaitement synchronisées.
Votre dashboard est maintenant prêt et lisible. Votre équipe infra vous demande d’y ajouter des métriques très spécifiques et un peu exotiques. Vous réalisez que la plupart d’entre elles sont difficiles à calculer et apportent finalement peu de valeur. On vous demande notamment le lag temporel : la durée entre la détection d’une modification par l’agent CDC et son application sur la base cible. Cette métrique est difficilement interprétable car il faut l’agréger entre les différents topics et difficilement calculable car il faut récupérer les informations dans plusieurs systèmes. Baptiste et Mariane vous recommandent de challenger les besoins quand le ratio complexité sur valeur ajoutée devient trop important.
Reprise d’historique
Actuellement, vous répliquez tous les nouveaux changements appliqués à votre base source. Mais quid de l’historique de votre base ? Celui-ci est nécessaire à vos besoins analytiques et machine learning. Vous décidez donc de le répliquer aussi.
L’agent CDC est capable de parcourir toutes vos tables et de générer un message par ligne pour répliquer la totalité de votre base. Cela peut représenter un très grand nombre de messages (2 milliards dans le cas qu’ont rencontré Baptiste et Mariane). Cette charge est très lourde pour votre cluster Kafka. Afin d’y être préparé, Baptiste vous propose une checklist.
Premièrement, faites des tirs de performance. Ceux-ci doivent être le plus proche possible des conditions réelles en termes de volumétrie, type de données et dimensions des machines. Ils vous donneront une estimation du temps requis pour la reprise d’historique et des goulots d’étranglement dans votre système.
Le monitoring de votre système vous permet de surveiller étroitement ces goulots d’étranglement pour éviter tout problème.
Deuxièmement, optimisez votre base cible pour la reprise d’historique. Elle sera beaucoup sollicitée mais seulement en écriture, ce qui vous permet de désactiver certaines autres fonctionnalités (comme le logging).
Enfin, préparez plusieurs configurations. Le cloud permet de facilement créer plusieurs configurations adaptées à différents cas d’usage. La reprise d’historique est un cas suffisamment important pour justifier d’une configuration spécifique. Baptiste recommande une configuration pour le cas nominal (réplication de changement au fil de l’eau) et une pour la reprise d’historique.
Ce point est important car il est très probable que vous fassiez la reprise d’historique plusieurs fois.
Cohérence des données
La cohérence est la capacité de refléter les modifications de la base source sur la base cible. La base cible est cohérente si toute lecture à un instant T reflète bien toute modification faites jusqu'à cet instant dans la base source.
On s'intéresse en particulier à 2 types de cohérence : la cohérence à terme et la cohérence immédiate.
La cohérence immédiate garantit que les données sont toujours synchronisées entre les tables. Il n’y a pas de risque que les modifications appliquée sur une table dans la base cible dépendent d’une autre table sur laquelle les modifications n'ont pas encore été appliquées. Obtenir une cohérence immédiate requiert d’avoir une application de synchronisation. Celle-ci enregistre toutes les modifications de tables interdépendantes et les applique au sein d’une même transaction. L’application de synchronisation est un goulot d’étranglement qui demande plus de temps et de traitement pour appliquer les changements.
La cohérence à terme garantit que les tables sont cohérentes entre elles au bout d’un certain temps. Par exemple, il peut y avoir des incohérences à l’instant T mais vos données à T moins une minute sont cohérentes entre elles. Dans ce cas, les données peuvent être répliquées dans chaque table en parallèle et indépendamment. Il faut ensuite compter le temps de propagation des changements entre base source et base cible pour obtenir la cohérence. Cela prend en général de l’ordre de quelques secondes.
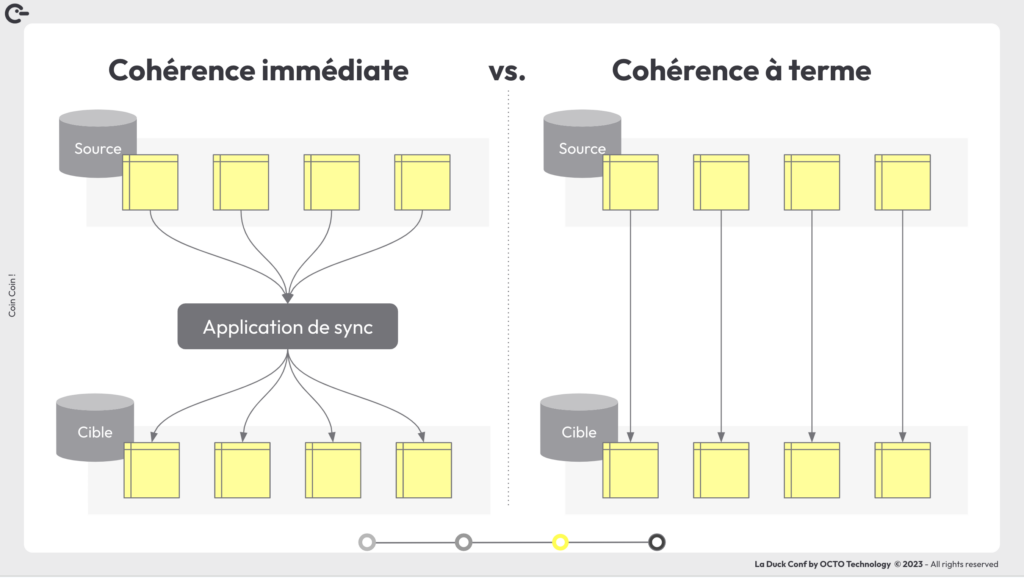
Cohérence immédiate vs Cohérence à terme
Le type de cohérence que vous allez mettre en place dépend de votre usage des données. Si vous avez besoin de requêter vos données en temps réel, il vous faut une cohérence immédiate, sinon, une cohérence à terme. La cohérence à terme est bien plus simple à mettre en place et dans la plupart des cas il n’y a pas de besoin de requêter en temps réel.
Baptiste et Mariane conseillent d’utiliser un topic par table dans votre cluster Kafka dans le cas d’une cohérence à terme. Cependant attention à l’ordre des messages. Celui-ci n’est pas garanti dans un topic, seulement dans une partition. Cela peut créer des problèmes si on envoie un message de modification puis de suppression. S’ils sont traités dans le désordre, on risque une erreur dans la base de données cible.
Pour garantir le traitement dans le bon ordre dans chaque table, Mariane recommande donc d’utiliser une seule partition par topic. Elle précise que ce n’est pas nécessaire si vous souhaitez préserver l’ordre uniquement sur chaque ligne indépendamment des autres.
Typage des colonnes
Kafka utilise le format Avro pour sérialiser vos messages. Celui-ci va assigner le type string à certains types plus complexes venant de la base source. On passera, par exemple, d’un type Timestamp à string. Certaines valeurs de champs seront donc de type string dans les messages d’insertion et de modification. Or vous aimeriez utiliser les types disponibles dans votre base de données cible. Vous avez alors 2 solutions: laisser le système cible caster les valeurs et choisir lui-même les types, ou imposer les types des champs.
La première option est plus simple mais peut causer des problèmes. En effet, vous avez moins de contrôle et les types castés peuvent ne pas correspondre à vos attentes métiers. On privilégiera plutôt la seconde option.
Pour éviter les conversions automatiques qui causent des problèmes de typage, Baptiste et Mariane recommandent d’initialiser les tables manuellement avec le bon schéma, puis d’activer la réplication.
Maintenant, votre réplication fonctionne et vos types correspondent à vos attentes. Cependant, un jour le métier vient vous dire qu’ils vont ajouter un champ dans une table source. Celui-ci n’existe pas dans votre table cible, et les nouveaux messages d’insertion et de modification risquent donc de créer une erreur.
Dans ce cas, Baptiste et Mariane vous proposent l’approche suivante:
Arrêter l’agent CDC pour éviter les modifications problématiques
Modifier le schéma de la table source. Ajouter le nouveau champ avec une valeur par défaut (afin que les messages avec l’ancien format fonctionnent toujours)
Re-lancer l’agent CDC
Ainsi vos données seront traitées sans erreur avec le nouveau schéma !
Take away
Pour finir, Baptiste et Mariane insistent sur les 4 points suivants:
Le lag tu surveilleras : c’est LA métrique la plus importante. Elle permet de s’assurer que vos bases sont synchronisées.
Des tirs de performances tu feras : pour vous assurer que votre système peut supporter la charge, surtout en cas de reprise d’historique.
Ton type de cohérence tu choisiras : le type de cohérence choisi dépend de vos besoins en fraîcheur de la donnée. Allez au plus simple
Tes types tu imposeras : afin de ne pas perdre d’information et d’avoir des données en accord avec vos attentes