La Duck Conf 2023 – Compte rendu du talk de Benjamin Joyen-Conseil – « Archi Data : déjà-vu ? »

En ce 29 mars 2023, après 2 mois de longue attente, Benjamin Joyen-Conseil, architecte data de chez OCTO Technology, se lance pour parler de Data Architecture. Il propose de nous faire voyager à travers le temps pour découvrir l’évolution de cette architecture depuis ces 20 dernières années.
Voici le paysage DATA en 2023 :
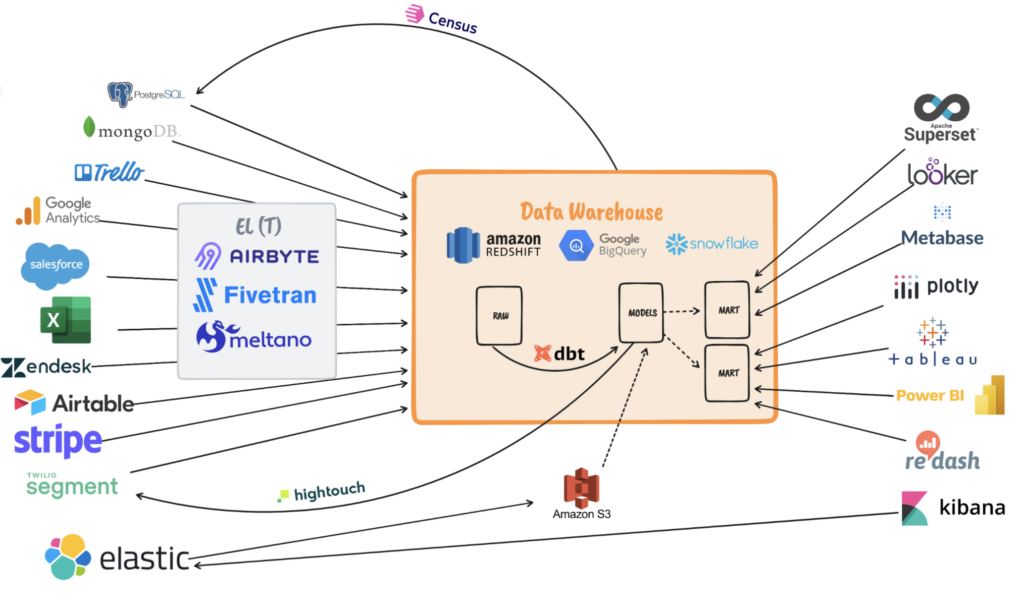
C’est ce que nous appelons la modern data stack. Elle se découpe en 3 parties :
Les ELT qui vont tirer les sources d’informations et les déposer sous format brut dans notre brique centrale qui est le Data Warehouse.
Ensuite, nous transformons les données avec des outils tels que dbt pour en constituer des modèles.
Enfin, ces données vont servir aux différents cas d’usages comme la BI traditionnelle, le décisionnel, le self-service, le ML, etc.
Mais nous avons un peu cette impression de déjà vu… Finalement, dans les années 2000, ce que nous voyons est très similaire.
Nos sources d’information à gauche, des ETL qui poussaient ces informations au centre dans le Data Warehouse, et à droite les cas d’usages qui se servaient dans ce dernier.
Mais alors que s’est-il passé depuis 20 ans ? Nous avons pourtant beaucoup parlé de data, mais nous arrivons quand même avec une architecture très semblable.
Alors est-ce que nous avons une évolution de notre architecture data ou alors c’est juste un délire de techos?
Le mieux est de revenir en arrière et de voir ce qu’il s’est passé pendant ces dernières années pour comprendre et répondre à cette question.
2000 à 2010 : découpage du monolithe Data Warehouse pour le faire passer à l'échelle
Dans les années 2000, le Data Warehouse devait stocker plus, plus longtemps et différemment. Avec les nouveaux formats de données déstructurées comme les données web, le Data Warehouse conçu avec un modèle relationnel, était devenu assez peu flexible pour stocker ce genre de données. Il devait aussi être accessible à travers le monde.
Pour pouvoir passer cette brique monolithique à l'échelle, nous avons dû la découper :
Le stockage distribué avec les DFS (Distributed File System) pour adresser le passage à l’échelle en termes de volumétrie. Cela nous a permis de répliquer l'information.
Les moteurs d'exécution distribués eux aussi, qui se chargeaient de la résilience, de la distributivité, en partitionnant le dataset. On retiendra le moteur Spark qui utilise la structure de données RDD (Resilient Distributed Dataset).
Les structures de données avec le schema on read qui nous a permis de charger nos données sans avoir à se soucier de leur structure. Cela a fait émerger de nouvelles modélisations telles que le data frame, les arbres, les graphes etc.
Les dialectes ont aussi subi des changements. Historiquement, il y avait SQL, un langage de requête, mais les frameworks comme Spark ou Pandas, nous ont amené à travailler la donnée avec des langages de programmation comme Scala ou Python.
Finalement, quels ont été les game changers?
Le stockage et les moteurs d'exécution ont été proposés directement sur étagère sur le cloud. À partir de 2010, les fournisseurs cloud commençaient à être déployés dans les entreprises, nous n'avions plus besoin de dizaines d'ingénieurs pour aller travailler des volumétries de données conséquentes, pour avoir accès à de la technologie.
Le schema on read a permis de se passer du formalisme relationnel et de se dire que l’on stocke d’abord la donnée sans savoir quels vont être nos cas d’usage pour avoir une flexibilité de lecture.
Enfin, tout était conçu comme du code source. Notre modélisation était aussi as code avec des outils comme dbt. La contractualisation, la sémantique layer, tout était as code.
Le Data Warehouse a été découpé et est revenu dans une nouvelle version plus puissante.
2010 à 2015 : découpage du monolithe ETL en ELT pour le faire passer à l'échelle
Durant cette période le challenge concernait les ETL. Ils restaient toujours monolithiques, le passage à l'échelle était compliqué. Les software as a service tels que Miro, Notion, Trello se multipliaient et nous voulions les intégrer à notre Data Warehouse comme de nouvelles sources d’informations.
Finalement, comme le Data Warehouse, l’ETL a été découpé pour lui aussi passer à l’échelle. Nous avons donc changé de paradigme et sommes passés de Extract /Transform/Load à Extract/Load/Transform. Ainsi, nous bénéficions alors des avantages que nous offrait le cloud. L’extraction était faite par de multiples connecteurs reliés à nos services SaaS qui poussaient les données sur le cloud dans un format plat et les déposaient dans des stockage objet comme AWS S3 ou les buckets GCS, le tout sans jamais se préoccuper de modélisation. De là, les données étaient finalement insérées dans le Data Warehouse où elles pouvaient être transformées, manipulées, exploitées.
2015 à 2020 : comment opérer cette Modern Data Stack complètement découpée
Nous arrivons en 2015 avec ce paysage DATA :
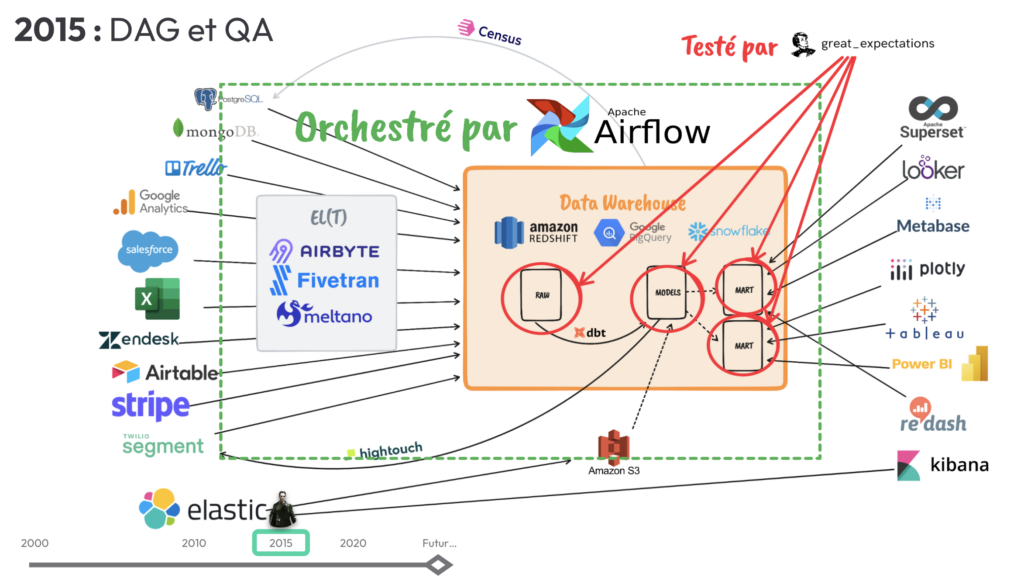
Des besoins de gouvernance, de vision transverse du pipeline de la donnée ont émergé avec la multiplication des technologies de ces dernières années. Des outils comme Airflow ont proposé une abstraction que l’on appelle le DAG (directed acyclic graph) as code. Il a permis à toute la population data de visualiser et orchestrer leur pipeline de traitement des données, peu importe la technologie utilisée.
Nous cherchions aussi à garantir la qualité des données à chaque étape de notre pipeline. Pour cela, il existait des frameworks comme great_expectations. Contrairement à ce qui existait déjà en termes de quality assessment des données, il pensait aux usages de la donnée pour en exprimer des data contrats.
2020 : fin du cycle IT, retour à l'architecture de base, mais avec tout ce qui la rend moderne
En 2020, on a observé la fin d’un cycle IT. Notre architecture d’origine a évolué, mais était revenue dans un état stable, elle avait une nouvelle version avec des nouveaux standards :
Le Data Warehouse cloud a ouvert la data à toutes entreprises, n’importe qui pouvait faire de l’analytics.
Tout était as code, le data pipeline, la data modélisation et le data contrat étaient as code.
Le DAG avait rendu accessible et visible tout le data pipeline.
Les datasets respectaient des contrats orientés vers les usages, vers les utilisateurs.
Finalement, qu’en est-il du futur ?
2023 : les nouveaux standards, data-pipeline as Code, data-model as Code, data-contract as Code
Benjamin nous confie ces prédictions pour le futur de l’architecture DATA.
- Prédiction 1 : shift right, la dataviz va aussi devenir "As Code"
Le reporting lui aussi sera as code avec des outils de dataviz as code comme Lightdash open source et compatible avec Gitlab ou encore Evidence qui propose de builder les reports.
- Prédiction 2 : le SQL est remis en question
Son principal problème est qu’il est difficilement lisible et maintenable c’est pour cela que PRQL un nouveau langage compatible à SQL a vu le jour l’année dernière**.**

- Prédiction 3 : Data Warehouse everywhere, sans infrastructure
Le résultat de la combinaison de ces prédictions est la modern data stack en boîte:
Apache Arrow un framework qui offre une performance accessible avec la vectorization, l’IO-Stream ou la compression.
DuckDB une base de données embarquée, native, sans serveur qui va permettre de lire de façon performante des fichiers volumineux sans avoir l’infrastructure.
dbt un outil qui permet de matérialiser, de structurer le Data Warehouse sous forme de layers et de manière idempotente.
PRQL le langage SQL plus moderne.
Tout assemblés, nous avons un Data Warehouse sans infrastructure cloud, qu’on peut exécuter n’importe où, un Data Warehouse serverless.
Finalement cela nous fait penser à Docker. Il exprime une infrastructure découpée sous forme de layers qui sont mutualisables, dérivables, plus faciles à maintenir.
Takeaway : on va repartir sur un nouveau cycle, qui va découper à nouveau notre Data Warehouse pour le faire passer à une nouvelle échelle
Grâce à l’émergence de Data Warehouse serverless, un nouveau cycle va démarrer qui permettra l’accessibilité à l’exploitation des données à tous les acteurs du numérique. De plus, nous avons pu observer plusieurs populations différentes qui ont chacune apporté leurs pratiques et une nouvelle population apparaît : les data citizens. Nous commençons tous à être familiarisé à utiliser de la donnée par exemple avec Bankin ou avec des applications de sport pour suivre son activité sportive. Finalement, avec les nouveaux usages de ces utilisateurs et leurs demandes de statistiques personnalisées, cela va solliciter de plus en plus notre architecture. Nous allons devoir faire évoluer à nouveau notre Data WareHouse pour un nouveau passage à l’échelle.