La donnée synthétique 3D: Labellisation de haute précision d'images pour ML basée sur les textures
Un modèle de machine learning nécessite un grand nombre de données pour l'entraînement. Parfois, ces données sont difficiles à obtenir dans la réalité, c’est pourquoi nous avons recours à la génération d'images synthétiques 3D (en anglais: Synthetic Data).
Cette technique joue un rôle essentiel dans la création d'images artificielles qui imitent de près la situation souhaitée, mais difficile à capturer, comme des défauts sur une route, des dommages sur un avion ou même la détection d'incendies en forêt. Le tout en incluant toutes les métadonnées intrinsèques nécessaires à l’entraînement des modèles de Machine Learning.
Dans un contexte de vision par ordinateur et pour entraîner efficacement un algorithme d'apprentissage automatique, il est essentiel d’avoir une collection d'images associées à des métadonnées correspondantes . Ces métadonnées fournissent des informations cruciales sur les images, telles que la position des régions significatives, les dimensions, les libellés (dits label ou classes). Ces informations servent d'entrée à l'algorithme d'Apprentissage Automatique et lui permettent de s'améliorer en phase d'entraînement.
Un autre avantage notable de l’approche Synthetic Data est la vitesse avec laquelle il est possible de générer de nombreuses images, chacune avec une multitude de variations aléatoires. Par conséquent, la technique se révèle très efficace en termes de temps, de coûts et de robustesse des modèles ML créés
Introduction à la donnée synthétique avec Unity Perception
Pour comprendre les mécanismes de génération de données synthétiques avec l'outil Unity Perception, nous vous conseillons fortement de lire notre article (La donnée synthétique 3D : Construire un dataset de ML labellisé rapidement). Dans ce dernier, vous trouverez une analyse détaillée du processus de création de jeux de données labellisés et des stratégies visant à améliorer l'efficacité du modèle d'Apprentissage Automatique.
Étant donné que Unity fonctionne comme un moteur de jeu en temps réel et que l'outil Perception fonctionne comme une extension destinée à la création d’images synthétiques labellisées, il est important de connaître son approche et ses caractéristiques sous-jacentes.Perception repose sur le maillage (mesh) d'un objet (sa structure géométrique) pour faciliter la labellisation. Par exemple, l'image ci-dessous (fig 1) peut être désignée comme une brique en raison de sa texture, caractérisée par sa forme cuboïde. De même, l'image suivante (fig 2) peut être identifiée comme un ballon de football en raison de sa texture et de sa forme sphérique.
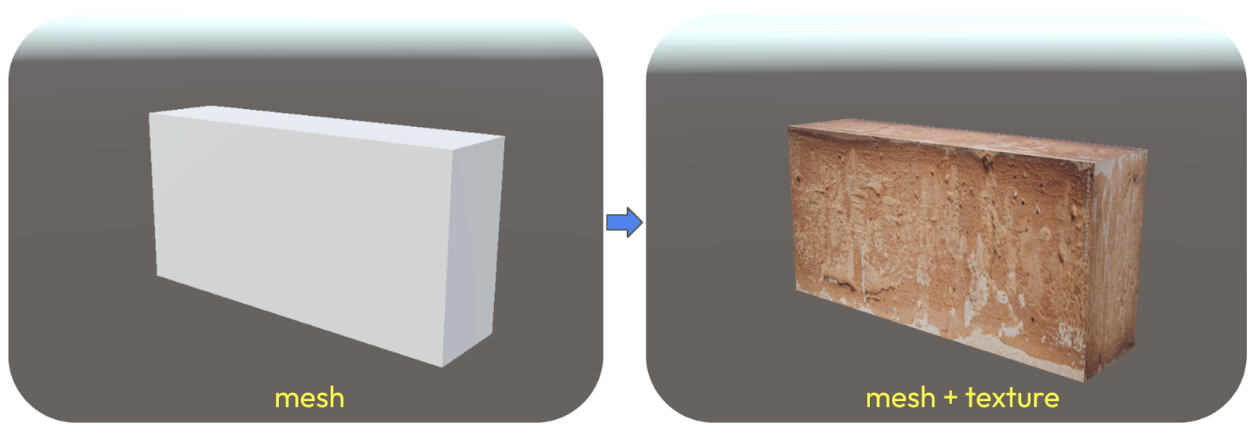
Fig. 1 - parallélépipède sans / avec texture
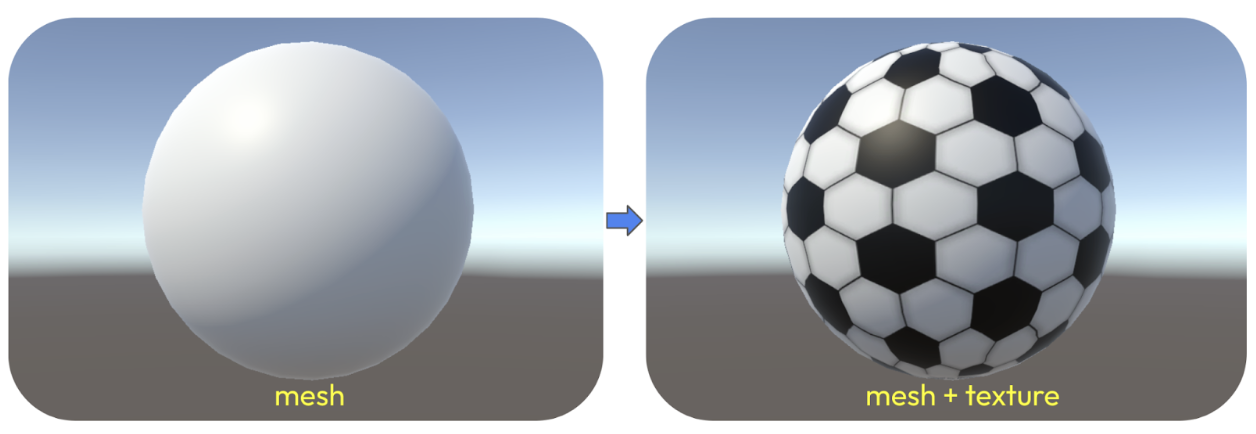
Fig. 2 - sphère sans / avec texture
L'outil Perception permet de générer nativement une variété d’images représentant des objets dans différentes situations en faisant varier leur mesh, les textures, l’éclairage et la position. Les métadonnées telles que le libellé et la position seront directement dépendantes du mesh affiché_._
En reprenant l’exemple précédent, il est ainsi possible d’alimenter rapidement un modèle de machine learning qui pourra identifier/distinguer des ballons et des briques de différentes formes ou tailles dans des contextes environnementaux variés.
Méthode d'étiquetage basée sur la géométrie
Considérons un scénario dans lequel l'objectif est de détecter un défaut comme une fissure sur une route ou des plis/déchirures dans un tissu. L’approche naïve consistant à modifier la surface en 3D pour simuler des défauts est possible mais peu réalisable, car cela demanderait beaucoup de temps et de ressources pour altérer le mesh avec toutes les variantes nécessaires. De plus, l'étiquetage d’un défaut sur une zone partie d’un mesh n’est pas possible facilement.
Pour comprendre ce qui se passe lorsque nous utilisons l'étiquetage basé sur la géométrie avec Perception, imaginons la géométrie de la route comme un simple cuboïde de 1 mètre de long et 3 mètres de large (en ignorant sa hauteur). Maintenant, nous appliquons soit une texture ressemblant à une route fissurée soit nous déformons le maillage (géométrie) de la route pour un aspect réaliste. Selon l'approche conventionnelle discutée dans cet article, même si la fissure ne mesure que 3 centimètres de long et 10 centimètres de large, l'ensemble du maillage (géométrie) sera étiqueté comme une fissure.
Par conséquent, le jeu de données généré par cette méthode présentera des images de route entière, ainsi que les dimensions de la fissure, qui sont essentiellement les mêmes que les dimensions de la route. Naturellement, ce jeu de données s'avère inadapté à l'entraînement d'un modèle d'Apprentissage Automatique qui finira par apprendre la forme de la route au lieu de se concentrer sur la fissure et produira des résultats inexacts (faux-positifs, faux-négatifs).

Fig. 3 - modèle 3D d'une route avec un défaut à détecter
What else ?
Pour sortir des limites de cette méthode, il faut se placer dans une nouvelle perspective vis-à-vis des éléments à détecter: les éléments ne doivent plus être considérés comme faisant partie de la géométrie de base (maillage) de l’objet, mais comme des composants à part entière. Cela nous ouvre la voie à un nouveau type d’étiquetage basé sur des sous-objets ou des textures.
La solution consiste alors à générer de manière procédurale des éléments (représentant précisément les défauts à détecter) et utiliser une randomisation paramétrée pour leur positionnement et leur taille.
Dans les sections suivantes, nous comparerons différentes variantes de cette approche pour évaluer laquelle est la plus pertinente.
Une première approche consiste à placer un maillage invisible (ex: un cube ou plan) uniquement sur les zones de fissure prédéfinies (Fig 4). Ce maillage sert donc d’espace réservé (placeholder). En étant indépendant et de taille réduite, il est ainsi facile de créer une étiquette délimitant précisément la zone à reconnaître. Toutefois, en fonction de l’emplacement il peut être difficile d’aligner correctement le placeholder sur celui-ci.

Fig. 4 - utilisation d'un maillage invisible pour encadrer le défaut à détecter
Une alternative consiste à dissocier la fissure dans un mesh dédié qui pourra être placé n’importe où sur la route et à lui attribuer l’étiquette "fissure" (Fig 5).
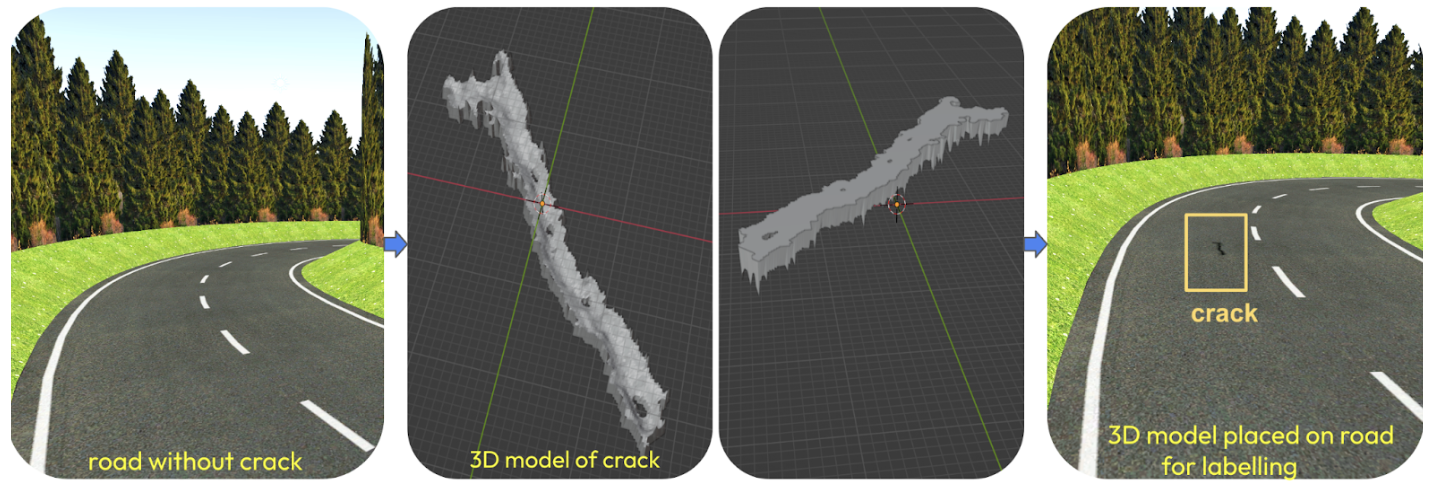
Fig. 5 - utilisation d'un modèle 3D détaillé par défaut à détecter
Bien que ces approches puissent sembler prometteuses, elles entraînent une certaine imprécision dans les résultats. Les principaux défis sont les suivants :
La subdivision des maillages est un processus chronophage.
La randomisation des zones de fissure dans la même zone subdivisée aboutit à un jeu de données présentant une diversité limitée en termes de variations de fissures.
Le confinement des fissures à des zones prédéfinies produit un jeu de données peu représentatif, car les tailles des “zones/boîtes de délimitation” (bounding box) restent trop similaires.
Par conséquent, le modèle d'Apprentissage Automatique finit par se baser sur la taille des zones de délimitation plutôt que les caractéristiques réelles des fissures.
À ce stade, nous rencontrons les limites du package Perception. Il ne peut plus être appliqué efficacement à ce cas d'utilisation spécifique, car notre zone d'intérêt dépend de la texture de la fissure, plutôt que de la géométrie de la route (mesh).
Méthode d’étiquetage basé sur la texture
Rappel: Le terme "texture" fait référence à l'apparence visuelle d'une surface, souvent représentée par une image appliquée à un modèle 2D/3D pour simuler la matérialité et les détails de la surface.
Objectif: Introduire de l'aléatoire à la fois dans la forme et dans l'emplacement des fissures, pour finalement produire un jeu de données composé d'images labellisées précisément (position dimensions).
Solution: Placer aléatoirement des éléments à détecter et générer une image où seuls ceux-ci sont visibles (objets et environnement masqués) puis demander à un algorithme basique de traitement d’images de détecter les positions et faire l'étiquetage.
Processus de génération d'images synthétiques :
L'environnement 3D est capturé, modélisé et texturé à l'aide d'un logiciel de modélisation 3D tel que Blender ou équivalent, puis importé dans le moteur Unity.
Les fissures réalistes sont générées de manière aléatoire à l'aide du plugin Adobe Substance. Ce plugin nous permet de générer de manière procédurale des textures en temps réel.
Pendant la simulation, notre script tourne en boucle afin de générer des variantes d’images labellisées. A chaque itération, il doit effectuer les actions suivantes:
Randomiser la position, l’orientation de la route, l'éclairage de l'environnement, l'angle de la caméra, le ciel, la visibilité (brouillard), ...
Générer une image RGB représentant cette variante de la scène (Fig. 6).
Générer une image en noir et blanc (mask map) sur laquelle seules les fissures sont visibles. Dans cette image, chaque zone de pixel blanc correspond aux "zones de fissures" et les pixels noirs représentent l'environnement (Fig. 7).
Calculer une boîte de délimitation virtuelle autour de chaque zone de fissure. La boîte de délimitation correspond à une segmentation de l'image avec la position précise et les dimensions de chaque zone de fissure. Ces données sont alors enregistrées dans le fichier de métadonnées d'image correspondant (Fig. 8).

Fig. 6 - variante d'image RGB sans / avec défaut

Fig. 7 - image noir et blanc servant de masque de détection
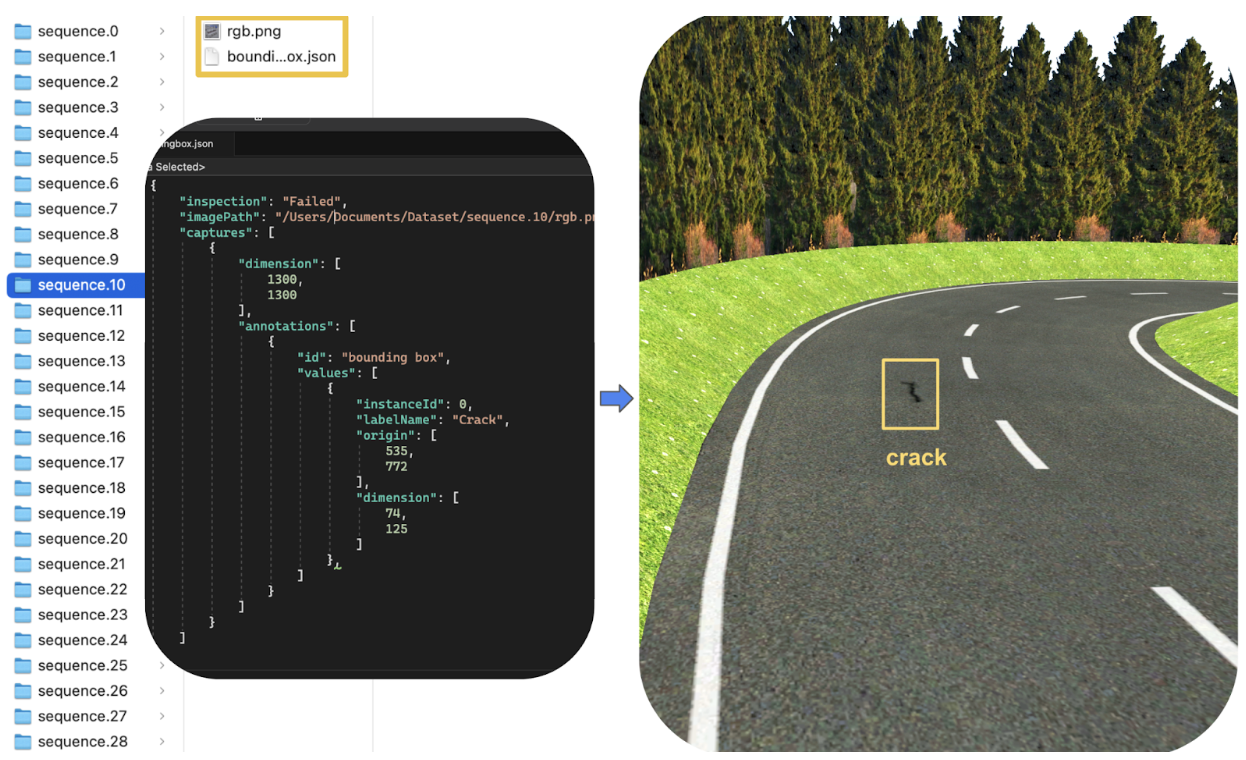
Fig. 8 - fichier de métadonnées
Ce processus est répété pour chaque itération de la simulation, et le nombre d'itérations est égal au nombre d'images générées pour notre jeu de données. Les images RGB générées, l'image en noir et blanc, et son fichier de métadonnées (segmentation) correspondant seront utilisés pour l'entraînement de l'Apprentissage Automatique.
Configuration du projet avant la mise en œuvre de l'algorithme :
Avant de mettre en œuvre cet algorithme, le projet nécessite une configuration spécifique pour obtenir la _mask map_en noir et blanc. Cela implique de préparer la scène d'une manière particulière: la zone de fissure doit être représentée en blanc, tandis que tous les autres éléments doivent être colorés en noir.
Pour suivre au plus près les contours de l’élément à détecter, la mask map doit être générée et mise à jour continuellement tout au long de la simulation.
Pour obtenir une mask map, il faut désactiver toutes les sources lumineuses de la scène (la route et l’environnement deviennent noir) et appliquer l’effet “Unlit” (visible même sans source de lumières) à la texture de la fissure. Dans cette configuration, seules les textures “Unlit” sont visibles, ce qui signifie que seuls les pixels blancs représentant les fissures sont visibles et discernables.
Cependant, il est important de noter que la modification des matériaux pour mettre à jour les textures et l'incorporation de la génération procédurale à l'aide d'outils tels qu'Adobe Substance pendant l'exécution entraînent une consommation notable de ressources. Par conséquent, certaines limites et inconvénients sont associés à l'adoption de cette approche.
Avantages :
Étant donné qu'il s'agit d'un script personnalisé, il offre une grande flexibilité, notamment :
Les valeurs minimales/maximales des zones de délimitation peuvent être prédéfinies pour éviter des zones trop petites ou trop grandes.
La valeur de seuil de distance entre les pixels blancs peut être modifiée pour obtenir une zone de délimitation appropriée autour d'un groupe de pixels blancs.
La minimisation de cette valeur peut entraîner la création de plusieurs petites zones pour un même groupe de pixels blancs (équivalent à plusieurs étiquettes sur une seule fissure).
La maximisation de cette valeur peut entraîner la création d’une seule grande zone de délimitation couvrant plusieurs groupes adjacents de pixels (équivalent à une seule étiquette pour plusieurs fissures proches).
La valeur optimale est propre au contexte du projet: formes des éléments à détecter, densité et proximité.
Indépendant de la position des zones de fissures, il est donc possible d'obtenir un jeu de données plus précis avec une possibilité infinie de variations.
Avec des modifications mineures du code, cette approche peut être appliquée de manière flexible à d'autres scénarios de reconnaissance d’images et de défauts subtils.
La mise en œuvre de cet algorithme peut sembler prête à l'emploi, mais en réalité, le projet Unity doit être conçu de manière à correspondre aux exigences techniques de cet algorithme.
Inconvénients :
En raison des exigences élevées en ressources, les performances de cette approche sont directement liées aux capacités de la machine.
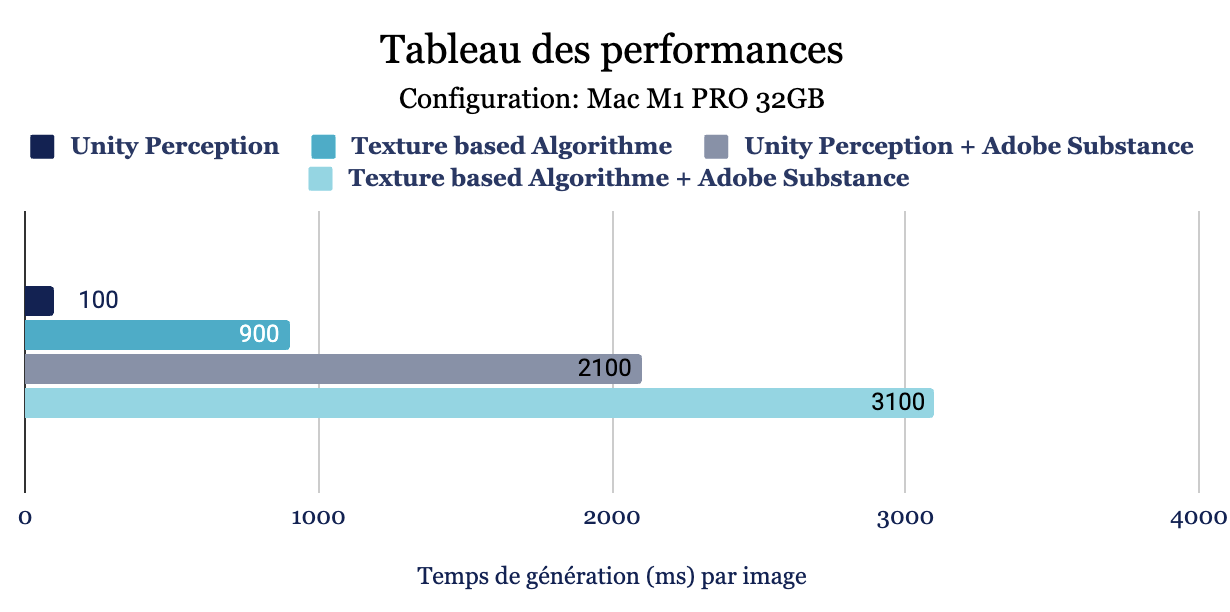
Fig. 9 - comparaison des temps de générations d'images par méthode
Bien que cette méthode puisse présenter des performances plus faibles par rapport à l'approche basée sur la géométrie, elle la surpasse largement en termes de vitesse et d'efficacité.
Conclusion
Bien que l'approche basée sur la géométrie utilisant l'outil Perception soit un atout fiable pour générer des ensembles de données étendus adaptés à l'Apprentissage Automatique, sa portée reste limitée à des cas d'utilisation spécifiques, tels que la détection d'objets. Pour répondre aux besoins des métiers de l’IA avec des applications dans divers domaines tels que l'inspection visuelle, il faut une solution capable de s'adapter aux exigences évolutives.
Dans ce contexte, l'approche basée sur la texture se présente comme une alternative polyvalente. Elle répond à un large éventail de cas d'utilisation (Fig. 10) en matière d'inspection visuelle, où la texture agit comme un facteur déterminant comme la détection de plis sur un tissu, de rides sur un visage, de tâches sur des matériaux (fuites, rouilles)...
Cette solution offre un cadre plus souple et adaptable pour répondre à l'évolution constante du paysage des applications d'IA.
Pour vous aider à choisir entre l’approche basée sur la géométrie et l’approche basée sur la texture, nous avons concocté le tableau ci-dessous qui reprend les différents cas d’usages et l’approche optimale.
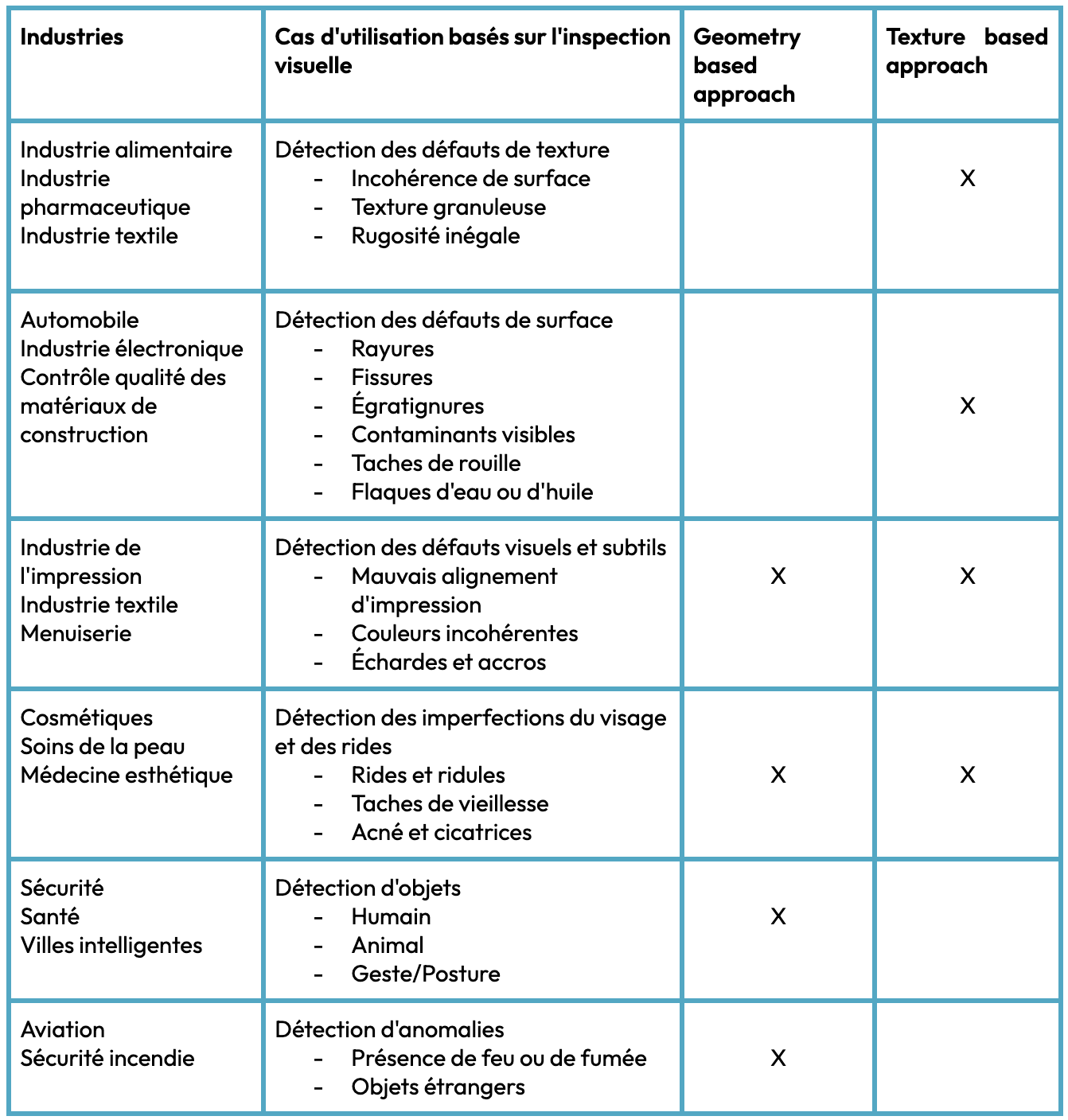
Fig. 10 - Approche par cas d'usage d'inspection visuelle