La confiance des utilisateurs dans les systèmes impliquant de l’Intelligence Artificielle
Avec le développement de l’IA, de nombreuses questions sociétales ont émergé : éthique, biais, et dilemmes de l’IA sont des notions fréquemment abordées. Et les réponses à ces questions seront des facteurs essentiels, entend-on souvent, de notre confiance dans les algorithmes de machine-learning qui gouverneront bientôt le monde :-)
C’est sans doute vrai, mais la question de la confiance dans les systèmes d'IA ne doit pas être limitée à ces problématiques éthiques. Outre le fait qu’elles dépassent la simple notion de confiance, les réponses à de tels enjeux risquent fort de manquer d’implications activables au quotidien.
D’autre part, on entend beaucoup parler d’interprétabilité et de transparence comme moyens de rassurer les utilisateurs, mais sans comprendre en quoi ces notions influent sur notre capacité à faire confiance.
Or, la confiance est un enjeu clé de l’adoption de l’IA. Celle-ci peut rendre de grands services, mais l’un des challenges à l’adoption de cette nouvelle pratique est la création d’un lien de confiance entre l’utilisateur et le système d’IA.
C’est pourquoi à travers cet article nous vous proposons une approche concrète de la confiance des utilisateurs dans les algorithmes d'IA. À l’aide d’apprentissages issus des neurosciences et de la psychosociologie, nous vous proposons d’explorer les mécanismes qui sous-tendent la confiance chez les êtres humains puis d’en tirer des pratiques réalistes pour les data-scientists.
Préambule
Avant de poursuivre, nous souhaitons préciser l’objet de cet article : il s’agit d’étudier la confiance des utilisateurs dans les algorithmes ou systèmes d’IA. Mais qu’est-ce qu’un utilisateur ? Pour la suite de l’article nous adopterons la définition suivante : un utilisateur est une personne qui porte la responsabilité d’utiliser ou non un système d'IA.
Par exemple, un opérateur sur une chaîne de production à qui on imposerait de suivre les directives d’un système d'IA n’est pas un utilisateur. Il n’a pas de choix à effectuer sur l’utilisation ou non du système… En revanche, l’ingénieur qualité qui a décidé que les opérateurs utiliseraient ce système (sans forcément en être lui-même un des concepteurs) est un utilisateur.
Par ailleurs, nous souhaitons revenir sur l’aspect scientifique des références invoquées dans cet article. Ce sont pour la plupart des études académiques extrêmement rigoureuses. Notre article n’a pas la prétention de se placer au même niveau d’exactitude scientifique ni d’être exhaustif. Nous sommes dans une posture de vulgarisation des concepts, et de leur adaptation à un usage courant (la conception de système d’IA).
Une première notion : la décision confidence
La recherche en Neurosciences sur les mécanismes de prise de décision de ces dernières années a été très prolifique. On a maintenant une bonne compréhension des processus en oeuvre lors d’un choix binaire simple. Nous accumulons de l’information en faveur de l’une ou l’autre des options, plus ou moins rapidement suivant l’intensité ou la qualité (signal sur bruit) des informations traitées, jusqu’à franchir un seuil de décision (accumulation-to-bound) [Ratcliff et al. 2016, Churchland et al. 2008].
La vitesse d’accumulation de l’information, le niveau de départ et la distance à parcourir jusqu’au seuil dépendent du contexte externe (la situation) et interne de l’individus (biais) [Shadlen and Kiani 2013, O’Connell et al. 2012].
Prenons par exemple le cas où nous devons décider si il y a un chien ou un chat sur une image. Il y a des cas très simples où l’image est nette et où l’animal possède toutes les caractéristiques prototypiques d’un chien ou d’un chat, mais il y a des cas plus ambigus ou des images dégradées qui peuvent rendre la décision plus compliquée.
En effet, si la qualité ou la quantité d’information disponible est faible, la vitesse d’accumulation sera faible, le choix est difficile et la décision prendra du temps, voire on pourra commettre une erreur.
Si nous avons un a priori (biais) fort en faveur d’une option plutôt que l’autre, nous allons commencer à accumuler de l’information à un niveau plus proche du seuil de cette option.
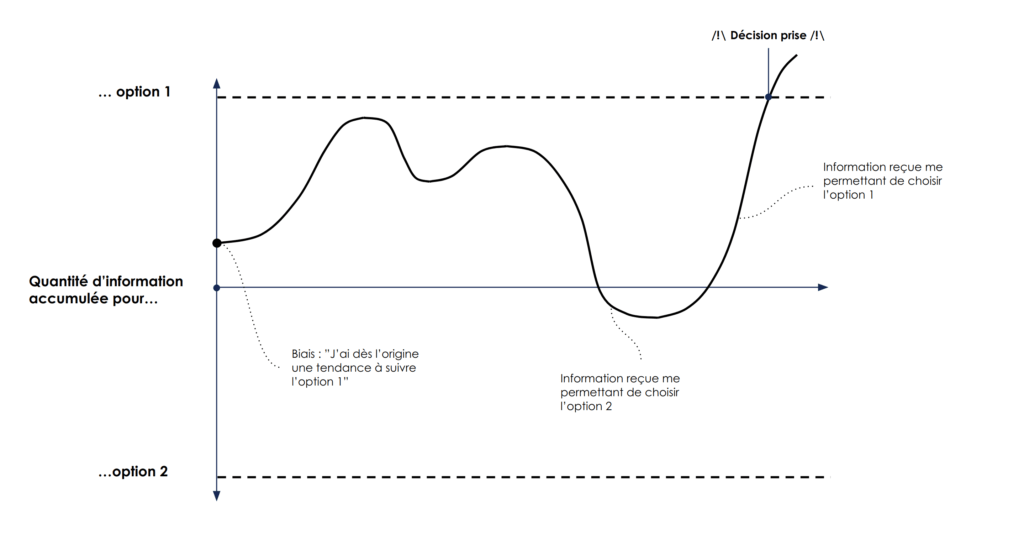
Ce modèle simple est utilisé dans de nombreuses expériences afin d’expliquer le comportement des primates dans ces situations de choix. Il permet également de modéliser le niveau de confiance lié à toute décision. En effet, moins l’information en faveur d’une option est claire, plus nous allons mettre de temps à franchir le seuil, et moins nous serons sûrs de notre décision [Yeung and Summerfield 2012].
Traduction de la modélisation de prise de décision pour expliquer la confiance dans un algorithme
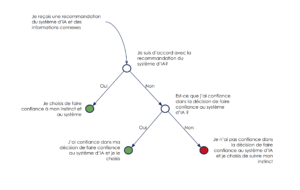
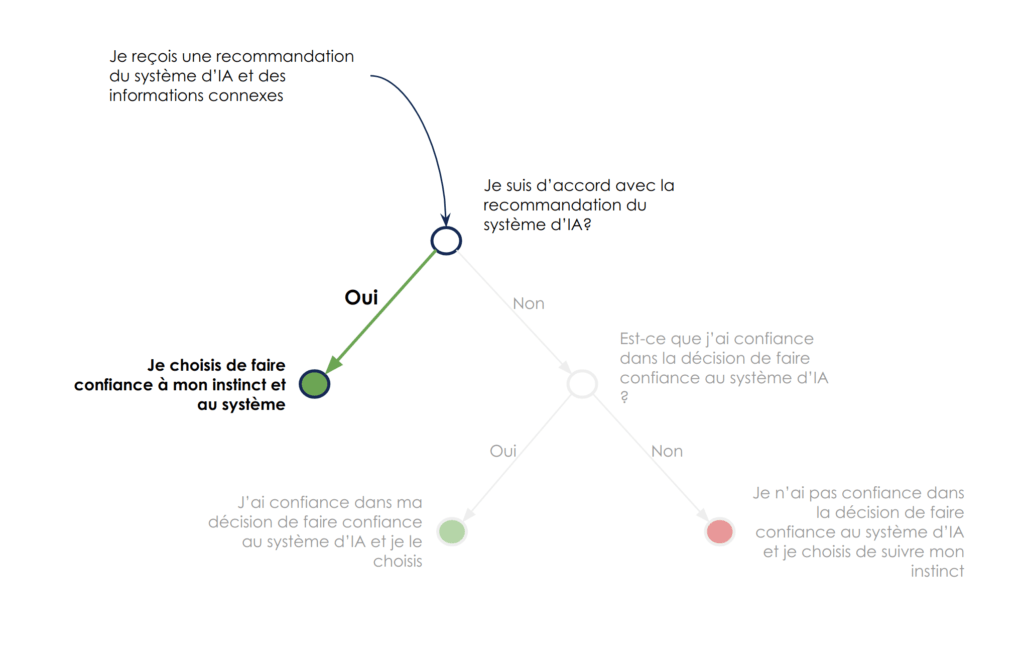
Lorsqu’on applique le modèle de prise de décision à l’utilisation d’un système de IA, on modélise en réalité la décision de faire confiance au système d'IA ou non, c’est à dire de suivre ses indications ou non.
Concrètement, les deux possibilités qui s’offrent à nous dans notre choix binaire sont suivre l’indication du modèle de IA, ou suivre mon instinct.
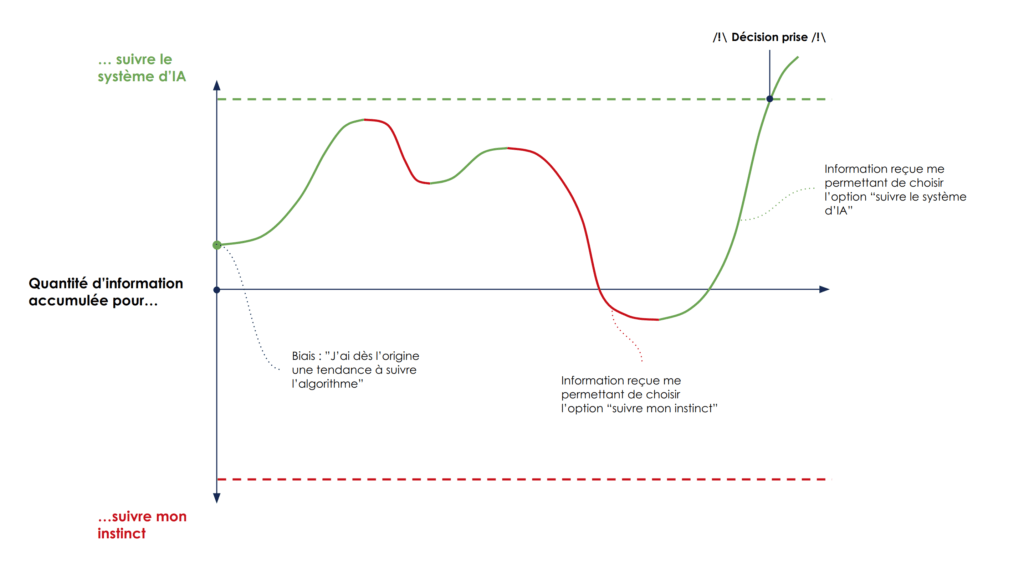
Le système de prise de décision final ressemble à un stacking (empilement) de deux modèles : le modèle de IA puis l’utilisateur. Autrement dit, la sortie du modèle de IA est une entrée du modèle de décision de l’utilisateur humain.
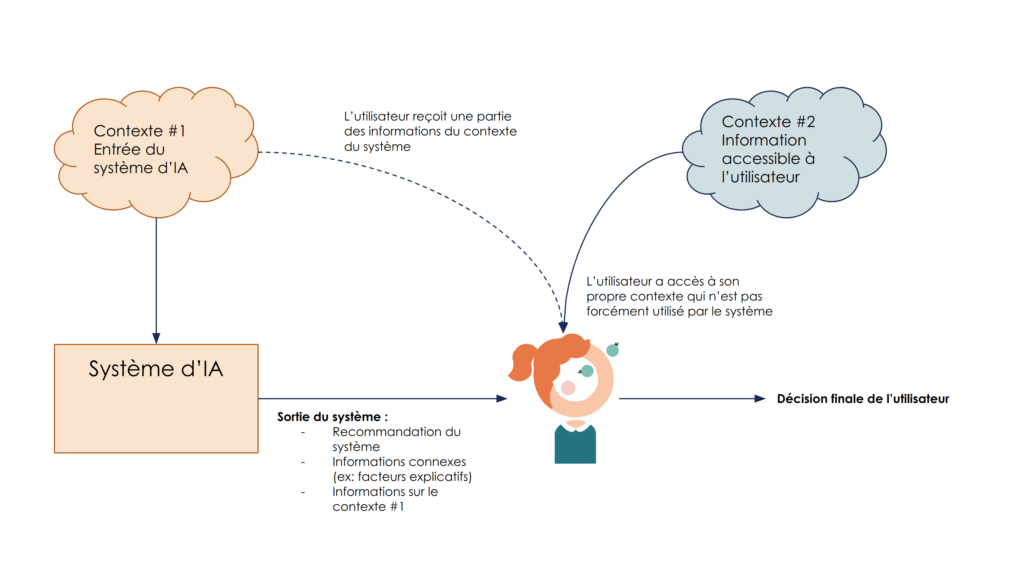
Si l’on revient vers notre objectif de créer de la confiance dans les algorithmes d'IA, la modélisation est en fait le niveau de confiance dans notre décision de faire confiance au système.
Il ne s’agit pas d’une confiance dans le système d'IA lui-même, mais bien de la confiance dans notre décision de lui faire confiance.
La nuance peut paraître légère, mais elle est extrêmement importante. Elle nous indique qu’il ne s’agit pas tant d’augmenter la quantité d’information sur ce qui se passe si je choisis de suivre le système d'IA (ce qui est difficile), que d’augmenter la quantité d’information à disposition pour choisir de suivre (ou non) le système d'IA.
On remarque par ailleurs qu’en considérant la décision finale comme un stacking du modèle d'IA et d’une décision humaine, que cette décision de faire confiance n’intervient qu’en cas de désaccord spontané de l’utilisateur du système d'IA avec l’indication donnée par le système. Nous verrons que cet aspect a des implications sur l’exploitation des feedbacks utilisateurs.
Implications pour nous, datascientists
Maintenant armés de notre modélisation de la confiance, nous pouvons la décliner en concepts plus opérationnels pour augmenter la confiance dans les algorithmes.
Expliquer la recommandation
Une façon efficace d’augmenter l’information disponible pour choisir de faire confiance ou non à l’algorithme est de ne pas fournir uniquement une indication binaire de la part du système, mais au contraire un niveau de détail élevé.
Ceci se comprend particulièrement bien si l’on reprend la modélisation d’un humain prenant en entrée de son système de décision la sortie du système d'IA : on est plus précis (et donc plus confiant) pour prendre une décision avec plusieurs paramètres en entrée qu’avec un seul.
Aujourd’hui, nous disposons de l’outillage suffisant pour fournir cette information à l’utilisateur du système d'IA. On peut par exemple s’attacher à :
- Donner une probabilité de prédiction plutôt qu’une décision binaire
- Donner accès à des paramètres explicatifs de la décision
- Feature importances
- Plus intéressant, des informations liées à la prédiction et non au modèle
- Shap values [Lundberg & Lee 2017]
- Tree interpretor
- Donner une vue (même partielle) du fonctionnement du système : en associant les utilisateurs à la conception du système (choix des données, des métriques, des features, etc.)
- Ajouter un clustering à côté de la prédiction, pour présenter des cas passés “similaires”, donc déjà connus de l’utilisateur
- Prenons l’exemple d’un modèle de recommandation marketing en agence bancaire : le modèle peut indiquer des clients similaires qui ont déjà acheté ou non le produit à vendre par le passé
Fournir ces indications permet d’augmenter la quantité d’information disponible pour l’utilisateur pour choisir de suivre la recommandation du système, et donc augmente la confiance dans sa décision de faire confiance.
Un exemple particulièrement connu de modèle appliquant ce principe est Waze. Avant il s’agissait d’une boîte noire, qui se contentait de vous indiquer le chemin le plus rapide. Aujourd’hui, il vous indique les itinéraires qu’il a considérés, et pourquoi il les a estimés moins rapides. À quelle version faites-vous le plus confiance ?
Prise en compte des feedbacks
Nous avons vu que la décision de faire confiance à un système d’IA peut être perçue comme le stacking de deux décisions : celle du système (sa recommandation), puis celle de l’utilisateur de suivre ou non cette recommandation dans les cas où il est en désaccord intuitif avec le système.
Un mécanisme améliorant mécaniquement la confiance de l’utilisateur est d’augmenter la proportion de cas où le système propose une recommandation en accord avec la décision spontanée qu’aurait prise l’utilisateur. Celui-ci voit alors passer plus de cas où il décide de faire confiance au système…
On pourrait donc être tenté d’isoler le dataset spécifique des feedbacks utilisateurs, et de surveiller la performance de nos systèmes sur ce dataset. Plus spécifiquement, nous pensons qu’une amélioration locale des performances du modèle sur ce dataset de feedback au détriment de sa performance globale serait perçue positivement par les utilisateurs, et entraînerait une augmentation contre-intuitive (la performance globale baisse !) de la confiance des utilisateurs dans le système d'IA.
Ainsi, nous pourrions artificiellement améliorer la confiance des utilisateurs dans notre système. Mais cette tactique est dangereuse…
Non contente de relever de la manipulation — et l’on rejoint par là les questions d’éthique des concepteurs de systèmes d’IA — elle est parfaitement incarnée par le phénomène des “bulles” Facebook. Ce phénomène se manifeste comme suit : chacun a confiance dans le système de recommandation de contenu qui lui propose du contenu en accord avec ses opinions plutôt qu’en conflit avec elles (augmentation locale de la performance), mais le système échoue à donner une vision large des contenus disponibles (diminution globale de la performance).
Ces phénomènes sont également révélateurs d’un effet important : le compromis performance / confiance. Les utilisateurs se trompent, et ont parfois tort quand ils pensent avoir raison. Ainsi, un système parfait présentera paradoxalement plus de cas où ses résultats seront susceptibles d’être remis en cause par l’utilisateur, ce qui peut entraîner une baisse de la confiance accordée à ce système… alors qu’il est plus performant qu’un système imparfait qui reproduirait les erreurs de l’utilisateur.
Ceci doit nous inciter à la prudence, en particulier lors des phases d’acquisitions d’utilisateurs en début de projet : l’augmentation de la performance n’est pas la garantie d’une augmentation de l’adhésion des utilisateurs.
Deuxième notion : la trustworthiness
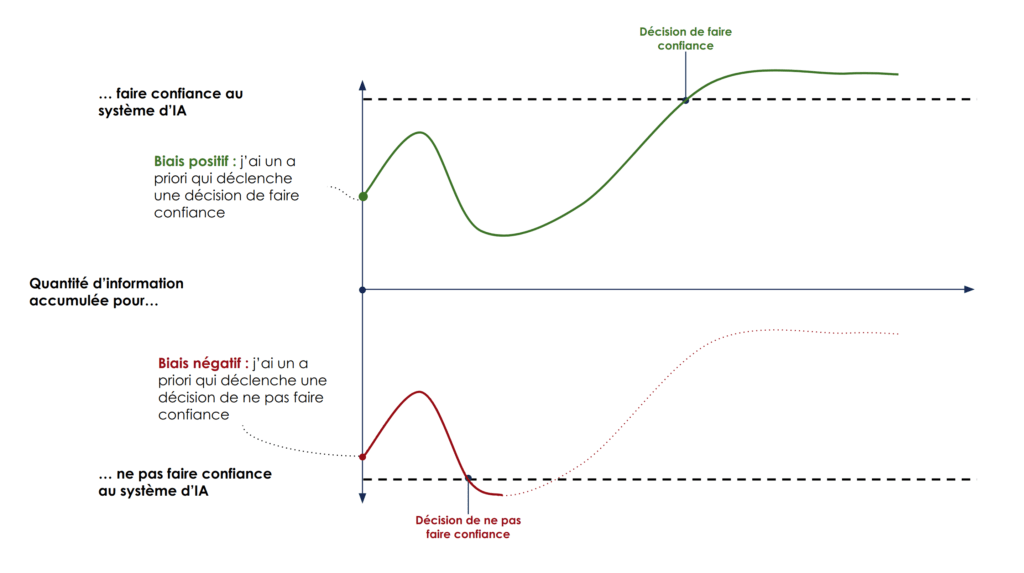
Lorsqu’on étudie les mécanismes sous-tendant la confiance, il y a une notion supplémentaire à prendre en compte : la « trustworthiness ». La traduction française en « digne de confiance » ne caractérise que partiellement cette notion complexe. En effet, ce phénomène ne se réfère pas uniquement à la performance mais dénote un biais a-priori en faveur ou défaveur d’un agent [Van’t Wout & Sanfey 2008, Rilling & Sanfey 2011]
Ce biais, qui est modélisé par le point de départ des courbes d’information, va influencer drastiquement notre décision de suivre ou non les décisions prises par l’agent. Par exemple, si on considère que le gouvernement est trustworthy, on va avoir tendance à suivre ses recommandations, et dans le cas contraire nous nous montrons suspicieux au regard des décisions qu’il prend.
Influence du biais initial sur la décision
Cet aspect est beaucoup moins logique et rationnel que ce qu’on a vu jusqu’à présent car il repose en partie sur des ressentis émotionnels et affectifs.
En effet, les études en neurosciences sur la confiance ont montré de façon répétée l’implication du système émotionnel dans notre évaluation de trustworthiness et nos décisions de faire ou non confiance. On ne peut donc pas ignorer ce facteur, et même s’il y a des explications logiques pour expliquer le choix de faire confiance ou non, une part de cette décision sera inévitablement basée sur des critères émotionnels [Seymour & Dolan 2008, Ruff & Fehr 2014]
Nous allons explorer le facteur principal pouvant influencer nos jugements de trustworthiness : la transitivité sociale.
La transitivité sociale fait référence au fait que si un agent nous est recommandé par une personne de confiance, toute ou partie de cette confiance lui sera transférée. À l’inverse, si l’agent nous est recommandé par une personne qu’on perçoit comme non-fiable, ce doute sera également transféré sur l’agent. Il est donc possible d’influencer la confiance qu’on accorde à un système en modifiant la perception qu’on a de l’entité qui nous la recommande.
Voyons à présent comment tirer partie de ce phénomène afin d’influencer favorablement le biais de trustworthiness.
Implications pour nous, datascientists
Créer une confiance dans les constructeurs du système
La transitivité sociale est un effet plutôt facilement exploitable pour les constructeurs de systèmes d’IA.
Si l’on considère les premiers utilisateurs d’un nouveau système d’IA, ils n’ont aucun pair à qui se référer pour obtenir une opinion sur la confiance à accorder au système étant donné la nouveauté du système. Les seules personnes qui ont confiance dans le système (normalement…) sont les membres de l’équipe de construction de ce système d’IA.
Une façon intéressante de créer la confiance des premiers utilisateurs dans un nouveau système d’IA est donc de créer un lien de confiance entre eux et l’équipe projet en charge du système. Où l’on redécouvre la proximité avec les utilisateurs… Celle-ci n’est donc pas qu’une question d’adéquation du système aux usages, mais bien une pratique essentielle à la création de confiance des utilisateurs envers le système que l’on crée.
La transitivité sociale de la confiance a également un effet démultiplicateur pour les futurs utilisateurs du système. Si les utilisateurs entretiennent un lien de confiance entre eux, la confiance des premiers utilisateurs se propagera vers les suivants, et inversement en cas de défiance [Fareri et al. 2012].
Ceci est une incitation forte à soigner notre interaction avec les premiers utilisateurs, en faisant preuve d’écoute et d’empathie notamment. Avoir une démarche User Experience construite et repartir des besoins plutôt que d’imposer un système d’IA pré-conçu est un premier pas.
D’après l’étude [Merritt & Ilgen 2008], on observe un second effet intéressant concernant l’habitude des personnes à utiliser un système. Plus je l’utilise, et plus je suis capable de juger si le système produit des résultats bons ou médiocres.
Autrement dit, si l’on a un système d’IA qui produit de bons résultats, les utilisateurs s’en rendront mieux compte s’ils l’utilisent depuis longtemps. Ce qui nous pousse à nouveau à associer nos utilisateurs au développement du système d’IA, afin qu’ils en aient la meilleure habitude lors du lancement et qu’ils soient les plus à même d’apprécier ses performances.
Évidemment mieux vaut s’abstenir en cas de déficience des performances — mais mieux vaut, dans ce cas, s’abstenir de mener le projet tout simplement…
Conclusion
La confiance dans les systèmes d’IA est un sujet de société en soi. Cependant, nous avons vu qu’il était également possible de travailler sur la confiance des utilisateurs dans les systèmes que nous construisons de façon plus opérationnelle, ce qui nous permet de mener la quête de la confiance à une échelle locale.
Les neurosciences et leurs modèles nous apportent des éclairages sur la façon dont la confiance se construit, ce qui nous permet ensuite de mettre en place des pratiques favorisant la confiance. Ces pratiques sont pour la plupart connues ou bien outillées : interprétabilité, prise en compte des feedback, proximité des utilisateurs avec des phases d’user experience, etc.
La nouveauté est l’importance à donner à ces pratiques, ce que révèle la notion de confiance. Elles ne sont pas des aspects marginaux de la construction de nos systèmes d’IA, elles vont au contraire conditionner leur adoption par les utilisateurs et in fine être la clé de leur succès.
Références
Yeung, N., & Summerfield, C. (2012). Metacognition in human decision-making: confidence and error monitoring. Philosophical Transactions of the Royal Society B: Biological Sciences, 367(1594), 1310-1321.
Ratcliff, R., Smith, P. L., Brown, S. D., & McKoon, G. (2016). Diffusion decision model: Current issues and history. Trends in cognitive sciences, 20(4), 260-281.
Shadlen, M. N., & Kiani, R. (2013). Decision making as a window on cognition. Neuron, 80(3), 791-806.
Van’t Wout, M., & Sanfey, A. G. (2008). Friend or foe: The effect of implicit trustworthiness judgments in social decision-making. Cognition, 108(3), 796-803.
Rilling, J. K., & Sanfey, A. G. (2011). The neuroscience of social decision-making. Annual review of psychology, 62, 23-48.
Seymour, B., & Dolan, R. (2008). Emotion, decision making, and the amygdala. Neuron, 58(5), 662-671.
Ruff, C. C., & Fehr, E. (2014). The neurobiology of rewards and values in social decision making. Nature Reviews Neuroscience, 15(8), 549.
Tzieropoulos, H. (2013). The Trust Game in neuroscience: a short review. Social neuroscience, 8(5), 407-416.
Fareri, D. S., Chang, L. J., & Delgado, M. R. (2012). Effects of direct social experience on trust decisions and neural reward circuitry. Frontiers in neuroscience, 6, 148.
Merritt, S. M., & Ilgen, D. R. (2008). Not all trust is created equal: Dispositional and history-based trust in human-automation interactions. Human Factors, 50(2), 194-210.
Lundberg, S. M., & Lee, S. I. (2017). A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems (pp. 4765-4774).