L'Event-Driven Architecture chez Octo : épisode 1, le pourquoi
Commençons par une petite histoire qui date d'il y a un peu plus d'un an.
Du côté de la DSI d'Octo, on gère une vingtaine d'applications internes, beaucoup de front, des sites vitrines, et surtout on a dans nos valises un vieux legacy de 13 ans. Oui je sais, c'est pas si vieux, mais pour nous c'est déjà beaucoup. C'est notre backoffice principal, sans lui la boîte ne tourne plus, c'est fini… On en prend soin, on le bichonne, mais on commence à atteindre certaines limites.
À côté de ça, on nous demande de plus en plus de faire communiquer nos applications internes entre elles, mais aussi avec des systèmes SaaS externes et voir même les SaaS entre eux. Et on voulait une solution qui nous permette de faire ça de manière simple, rapide et scalable.
Et comme vous vous en doutez au vu du titre de l'article, nous avons donc choisi l'Event-Driven Architecture (EDA).
Qu'est-ce que l'EDA ?
L'Event-Driven Architecture (EDA), ou Architecture Orientée Événements en français, est une architecture logicielle où les composants communiquent entre eux via des événements. Mais ça veut dire quoi concrètement ?
Ici les applications ou systèmes ne font pas de requêtes directes les uns aux autres, mais émettent des événements lorsqu'une action se produit. Ces événements sont ensuite consommés par d'autres applications qui réagissent en conséquence.
Qu'est-ce qu'un événement ?
Tout changement d'état — l'achat d'un article, le clic sur un bouton j'aime, l'ouverture d'une porte — constitue un événement au sens de l'EDA.
Concrètement, un événement c'est un petit message qui dit "hé, il s'est passé un truc !". Il contient en général un type (OrderCreated, serieLiked, doorOpened, …), un timestamp et des données utiles pour comprendre ce qui s'est passé.
Avec ça on a un historique complet de ce qui se passe dans notre écosystème et chaque application peut réagir ou pas en fonction de ce qu’il se passe.
Pourquoi pas juste des APIs comme avant ?
Bonne question, vous avez raison de la poser (oui, je vous fais parler maintenant).
Avec une API classique, quand mon app A veut prévenir l'app B qu'il s'est passé un truc, elle appelle directement B. Ça marche très bien… tant qu'il n'y a que B. Le jour où il faut aussi prévenir C et le SaaS externe D, l'app A doit connaître tout le monde, gérer les erreurs de chacun, et si B est down, c'est tout qui se plante.
Avec l'EDA, A émet juste son événement et passe à autre chose. C'est l'event broker qui se charge de le distribuer à qui veut bien l'écouter. A n'a aucune idée de qui consomme, ni combien ils sont. Demain on rajoute un consommateur ? On le branche, point. Pas besoin de toucher au code de A.
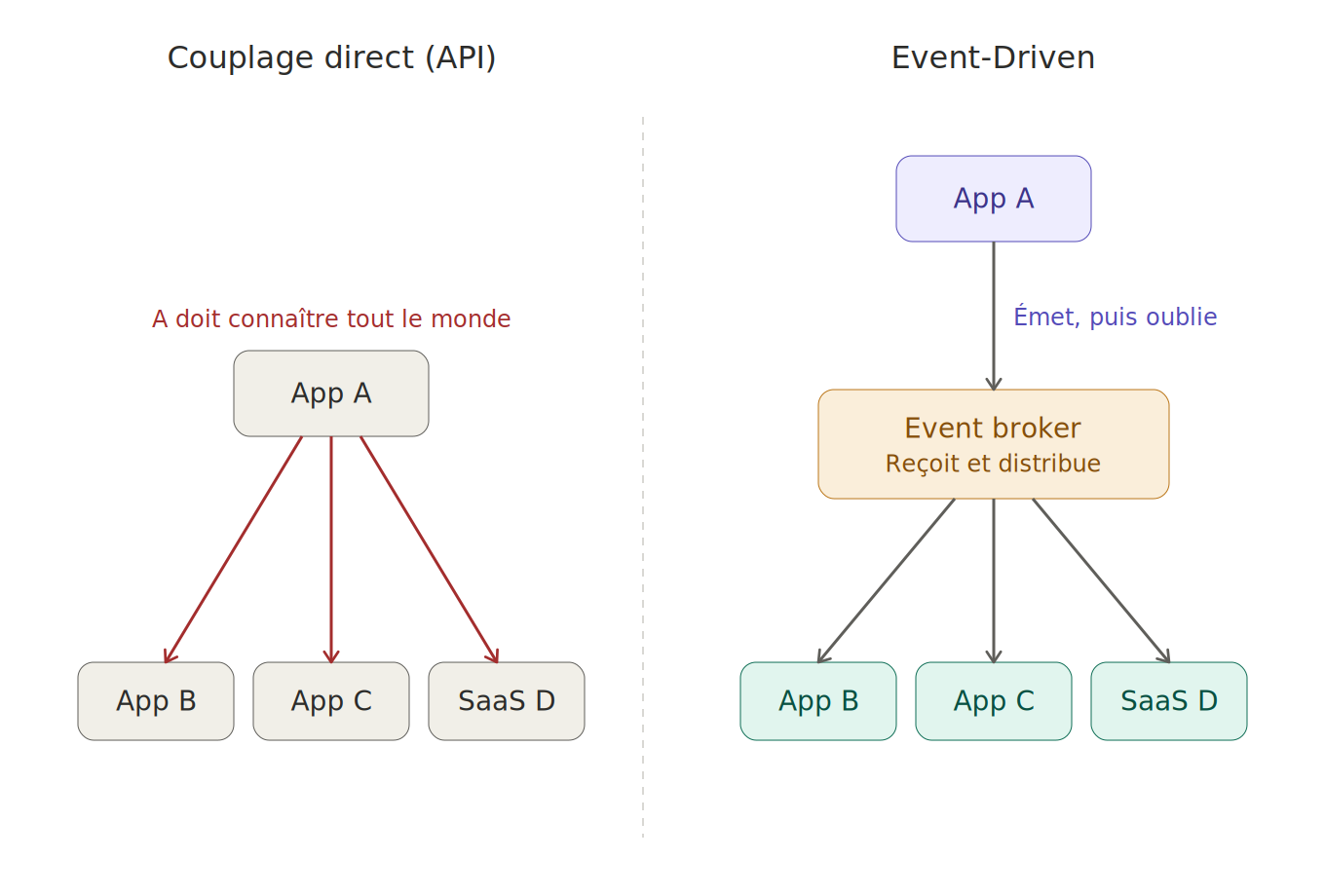
C'est ce qu'on appelle du découplage, et c'est ce qui nous intéressait le plus dans notre contexte, où on doit faire dialoguer un legacy et un nombre croissant de systèmes externes.
Les briques de base
Comme toute bonne recette, il faut plusieurs ingrédients :
- Le producer : celui qui émet les événements. Dans notre cas, ça peut être notre legacy quand un client fait une action, ou un SaaS externe via un webhook.
- L'event broker : le chef d'orchestre. C'est lui qui reçoit les événements et les distribue. Chez nous c'est EventBridge (mais on en reparlera dans un autre article).
- Le consumer : celui qui écoute et réagit. Ça peut être une autre app interne, une lambda, un webhook vers un SaaS, … En fait la même chose que pour le producer.
Pour reprendre ce que l’on vient de se dire juste avant : un événement c'est du passé. C'est un fait qui s'est produit, pas une demande. La nuance est subtile mais elle change tout. Le producer ne dit pas "fais ça", il dit "ça s'est passé, démerdez-vous". Et c'est ce qui rend le système si flexible : le producer n'a pas à savoir qui doit faire quoi. Il balance et il oublie.
Et un producer peut être un consumer dans un autre contexte, hein. Rien n'empêche que l'app qui consomme un événement en émette un autre derrière. C'est même très courant.
Notre cas concret : le recrutement
L'exemple le plus parlant chez nous, c'est notre process de recrutement.
On utilise SmartRecruiters (d’ailleurs allez faire un tour sur nos offres d’emploi on a des trucs cool) et à chaque modification de statut d'une candidature, un événement “ApplicationUpdated” est émis. Et à partir de là, en fonction du statut, plein de choses peuvent se déclencher :
- Une notification dans Mattermost (notre chat interne, en gros un Slack-like)
- La création d'un ticket dans Jira Service Management
- La mise à jour d'un fichier Excel… ou deux… ou trois
Et oui, parce que comme dans toute bonne entreprise, on a plein d'infos qui vivent dans des fichiers à droite à gauche. C'est d'ailleurs une des raisons qui nous ont poussés à mieux orchestrer ce qui se passe entre nos outils : avant, une info pouvait être modifiée dans le système A et nulle part ailleurs, ce qui créait à terme des incohérences pas mal pénibles à débugger.
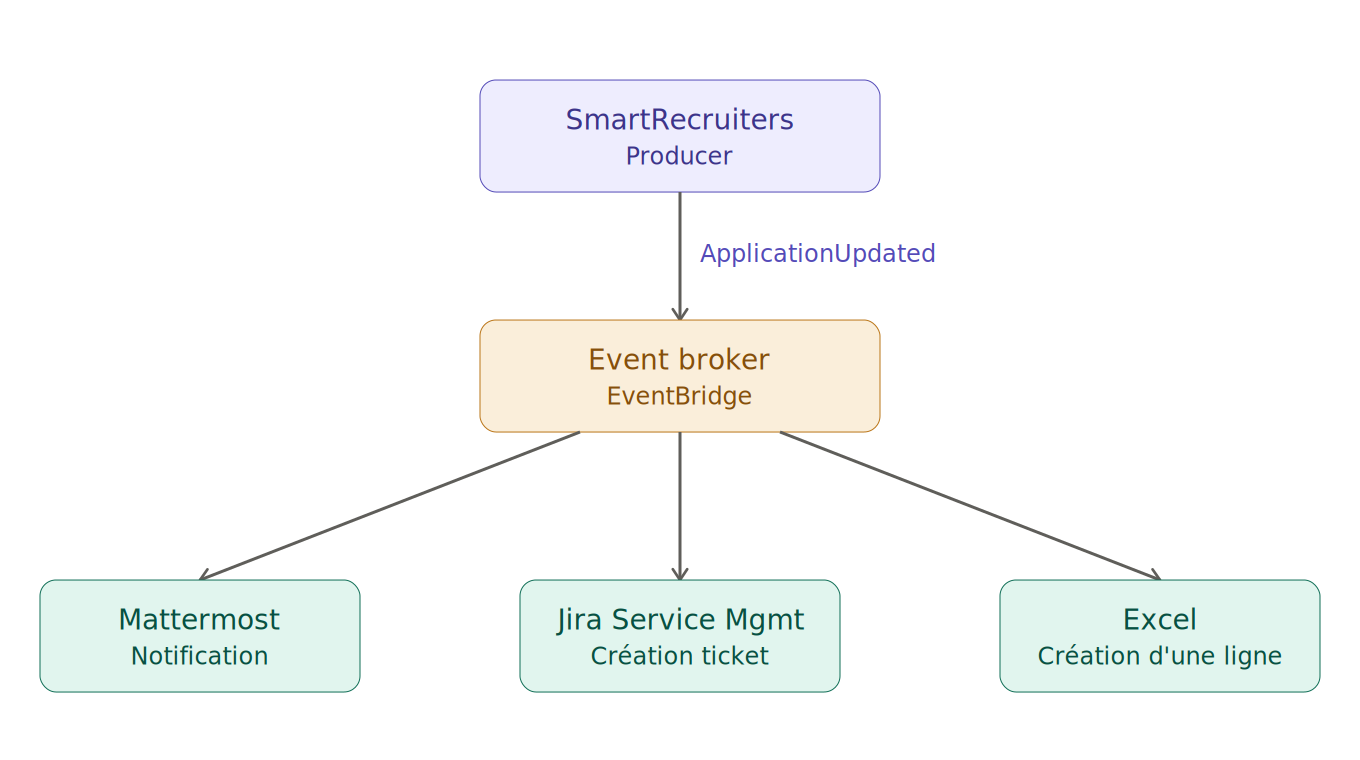
Avec l'EDA, le producer (SmartRecruiters) émet son événement, et tous les consommateurs intéressés font leur petite affaire de leur côté. Si demain on veut ajouter une étape — genre prévenir un autre outil, ou envoyer un mail automatique — on branche un nouveau consumer, et basta. Aucune modification côté SmartRecruiters, aucun risque de péter ce qui marche déjà.
Ce qu'on en retire
Globalement, on est plutôt contents. Le découplage tient ses promesses, on rajoute des consumers sans trembler, et on commence à avoir une vraie cohérence entre nos outils.
Mais (parce qu'il y a toujours un mais), tout n'est pas rose. Et le plus gros caillou dans notre chaussure, c'est la gestion des logs et du monitoring.
Quand vos événements traversent 3, 4, 5 systèmes différents, savoir où ça a coincé devient un sport en soi. Et il n'y a pas de solution toute prête qui sort de la boîte (ou alors j'ai mal cherché, et c'est clairement une possibilité à ne pas négliger 😄). On a démarré sans rien de centralisé, et autant vous dire que c'était… disons, folklorique. On a dû passer pas mal de temps à construire quelque chose de robuste, scalable, et surtout utilisable aussi bien par les devs que par notre PO.
Mais je vous en reparlerai plus en détail dans un autre article, parce que sinon on va y être jusqu'à la semaine prochaine.
Et la suite ?
Pas de panique, on ne va pas s'arrêter là. Cet article c'était la mise en bouche, le pourquoi du comment.
Dans le prochain, on rentrera dans la théorie pure : les patterns (pub/sub, event sourcing, CQRS et tous les acronymes qui font peur en réunion), les types d'événements, les bonnes et mauvaises pratiques.
Je vous montrerais l’envers du décor avec notre stack à nous : full AWS, EventBridge, Lambda, SQS et tout ce qui s'ensuit. Avec du code, des schémas et bien évidement quelques galères à raconter.
Il faudra aussi que je vous parle plus en détail de notre infra de monitoring et d’alerting car je suis plutôt fier de ce qu’on a réussi à faire de nos petites mains.
À très vite !