L'économie cachée des LLM
Depuis quelques mois, plusieurs collègues et moi-même utilisons Claude ou GPT quotidiennement via un abonnement. Je me suis rendu compte que pour certains usages intensifs, Claude Code ou Codex qui tourne toute la journée, des sessions d'analyse de code longues, le coût équivalent en API dépasserait largement les 20€ mensuels de l'abonnement.
Ma réaction fut de penser qu'Anthropic et OpenAI perdaient de l'argent sur ces utilisateurs. Et pourtant Anthropic revendique désormais plusieurs milliards de dollars de chiffre d'affaires annualisés tout en gardant ces mêmes abonnements qui les feraient possiblement “saigner”.
Les fournisseurs d’intelligence artificielle, OpenAI, Anthropic, Google, Mistral, et compagnies, offrent deux modèles tarifaires pour accéder à leurs produits. Le premier, l'API, qui facture aux nombres d’input tokens et d’output tokens, et qui s’arrête quand le portefeuille est vide. Le second, l'abonnement, paiement mensuel qui s'arrête lorsque les quotas horaires et hebdomadaires sont atteints. Même produit, même infrastructure, même consommation et pourtant deux factures différentes. En effet, si vous prenez par exemple l'abonnement à 20€/mois la quantité de tokens à laquelle vous aurez accès sera sans comparaison avec ce que vous pourriez obtenir avec la même somme via API. Pourquoi ?
On ne sait pas combien OpenAI, Anthropic, Google paient réellement pour produire un token. En revanche, avec des architectures publiques, du matériel public, et des mesures publiques, on peut estimer combien de tokens un budget donné permettrait de produire sur une infrastructure optimisée.
Pour obtenir des éléments de réponse, nous allons donc approximer le coût de production d'un million de tokens pour un modèle public aux performances comparables à celles des modèles propriétaires. Cela nous donnera un ordre d’idée et nous permettra de déterminer s’il se rapproche des prix proposés via l’API ou via l’abonnement.
Pour la suite, pas besoin de maîtriser l'architecture d'un transformer ou les détails du mécanisme d'attention pour faire les calculs. Quelques intuitions sur ce qui se passe quand un modèle traite un prompt et produit des tokens suffisent, et nous allons les construire ensemble dans les prochaines sections.
Quand on envoie un prompt, que se passe-t-il vraiment ?
Comme vous avez pu le remarquer, j'ai utilisé le terme « fournisseurs de tokens » pour parler des entreprises spécialisées dans les LLM (Large Language Model). Ce choix n’est pas anodin car l'essence de leur travail consiste, à partir d’un prompt, à produire les tokens suivants le plus rapidement, le plus efficacement et le plus pertinemment possible. Un prompt est lui-même une suite de tokens que le modèle traite pour estimer quel token peut venir ensuite, puis le suivant, et ainsi de suite.
Un token, c’est un bout de mot, une ponctuation, un emoji, un espace... Certains tokens sont visibles, d’autres non. In fine, le texte est converti en nombres entiers, appelés tokens, que le modèle transforme ensuite en vecteurs pour apprendre à les interpréter. Mis bout à bout, les tokens forment les réponses des LLM. Notre prompt est transformé en tokens afin que notre texte soit interprétable par le modèle. Le tokenizer est entraîné avant même la phase de pré-entraînement du modèle, puis reste généralement fixé. Comme chaque famille de modèles peut avoir son propre tokenizer, un même texte peut être découpé différemment selon que l’on utilise GPT, Claude, Llama ou Mistral. Pour visualiser ceux d'OpenAI, on peut utiliser Tokenizer. Et pour une histoire qui illustre leur profondeur et les risques inhérents à ces derniers, découvrez si Peter Todd est l'antéchrist.
Une fois que nous avons transformé notre prompt en tokens, vient la phase de prefill.
Le prefill, c'est le traitement de tout le prompt en un bloc, préalable à la production du premier token. Le prefill construit aussi le KV cache, une “mémoire” des tokens déjà traités que le modèle réutilise pour éviter de recalculer tous les tokens précédents à chaque nouveau token. Le délai pour réaliser cette tâche est aussi connu sous le nom de Time to First Token (TTFT). Plus le prompt est long, plus cette phase est coûteuse.
Une fois cette phase terminée avec le premier output token produit, on peut commencer la deuxième phase : le decode, soit la production des output tokens qui forment la réponse, un par un.
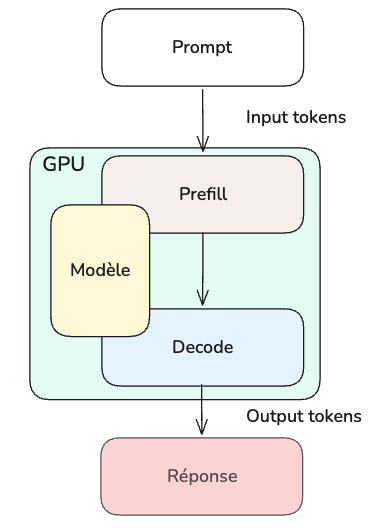
Cheminement lors de la production d’une réponse à un prompt.
Mais avant d'entrer dans le détail du decode, j'aimerais introduire un autre concept : celui de Mixture-of-Experts (MoE). L'architecture MoE permet à un modèle d'avoir une large capacité d'apprentissage, disons 1T, soit mille milliards de paramètres, mais de n'en activer qu'une partie, qui fera par exemple 32B (Milliards de paramètres) et qui formera un expert, lors des phases de prefill et de decode. Ainsi un "router" va sélectionner l'expert de son choix et n'activer que 32B de paramètre plutôt que les 1T possibles.
C'est comme si, à la place d'avoir accès à un amas de connaissances écrit dans un grand livre, nous avions organisé ce savoir par grands thèmes, un peu comme dans une encyclopédie. Le routeur est celui qui sait (plus ou moins bien) dans quelle encyclopédie se trouve l’information (la thématique) nécessaire à la création de notre réponse.
Pour illustrer, prenons le cas de Kimi K2.6, dernier modèle open weight de MoonshotAI, qui rivalise avec les derniers modèles d'Anthropic et OpenAI sur plusieurs benchmarks publics. Ce modèle est un MoE de 1T de paramètres, avec 32B activés, décomposés en 384 experts dont seulement 8 activés par token.
Ce qui signifie que, pour les MoE, le coût pour servir un token de façon unitaire n'est pas lié au nombre de paramètres totaux (1T) mais au nombre de paramètres activés (32B). Cela permet un faible coût tout en conservant une grande capacité.
Maintenant que nous avons la vue d'ensemble : un MoE suit aussi deux phases, le prefill (input tokens) suivi du decode (output tokens). Et dans ces deux cas, comme indiqué par leurs différences de prix, il existe une réelle différence de coûts.
Pour éviter de changer d’hypothèses à chaque section, nous allons garder le même exemple tout au long du calcul : un prompt de 2048 tokens, servi par un modèle MoE de 1T paramètres dont 32B sont activés par token, hébergé sur un noeud de 8 H100. Par moments, je ramènerai certains calculs à une seule H100 pour fixer un ordre de grandeur local, mais l’exemple de référence reste bien le nœud complet. Les détails arriveront au moment où ils deviendront utiles. Pour l’instant, retenez seulement que ces chiffres servent de repères.
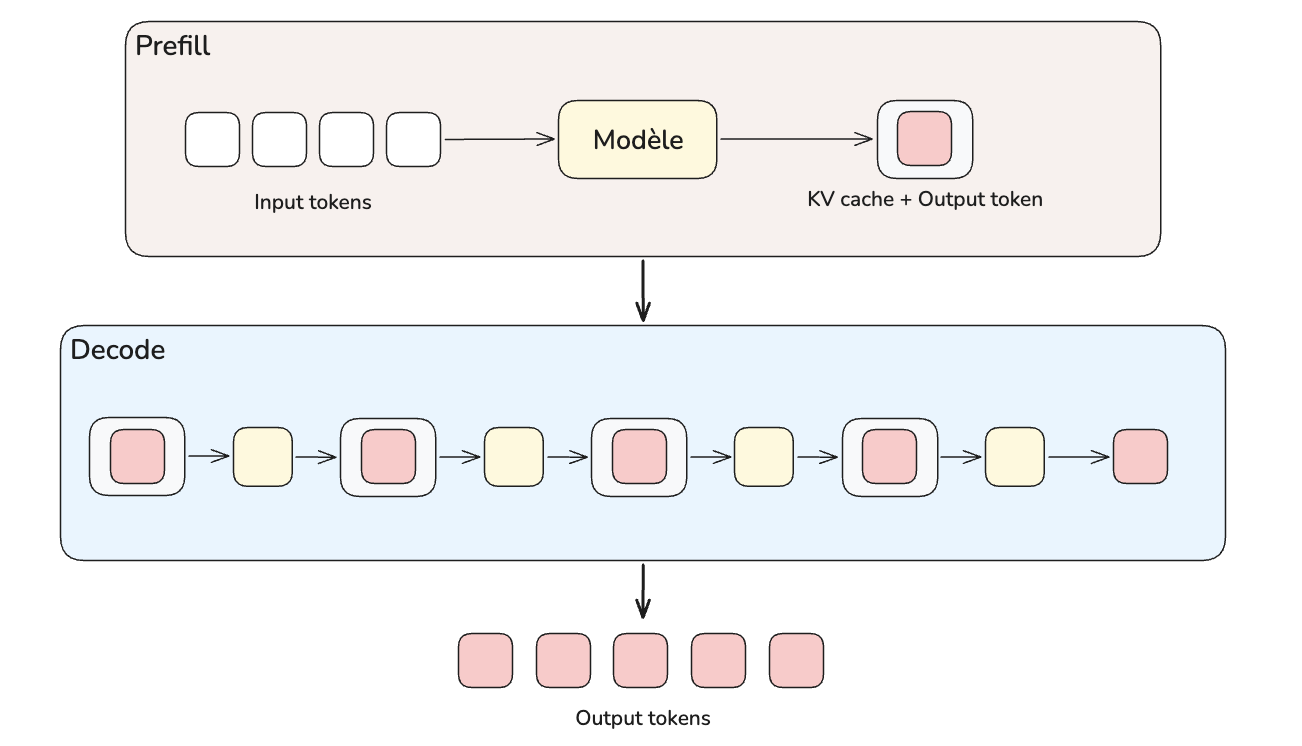
Ce que coûte le prefill
Le prefill, c'est la phase où le modèle traite tout le prompt d'un seul trait, jusqu'à la génération du premier token, avant de passer le relais à la phase de decode.
Pour comprendre son coût, illustrons par un calcul. Prenons un prompt de 2048 tokens. Pour chaque token, le modèle doit effectuer 2 opérations arithmétiques, une multiplication et une addition (multiply-add), et ce avec chacun des paramètres activés, soit 32B. En multipliant tout ça, on obtient un résultat en FLOPs.
Un FLOP, pour floating-point operation, est une opération arithmétique à virgule flottante. Quand on parle de FLOPs, avec un s minuscule, on parle du nombre total d'opérations nécessaires pour exécuter une tâche donnée, par exemple un prefill. À l'inverse, un débit de calcul se note plus clairement en FLOP/s : c’est le nombre d’opérations qu’un GPU peut exécuter par seconde. Dans les fiches techniques, ce débit est souvent écrit FLOPS, TeraFLOPS ou PetaFLOPS, même si cette notation peut prêter à confusion.
Pour notre prefill, on obtient donc : 2048 × 2 × 32B = 131 TFLOPs.
Un GPU comme le H100 peut exécuter ces opérations dans plusieurs formats numériques. Deux formats reviennent souvent en IA : le bf16, un format 16 bits, et le FP8, un format 8 bits. Plus on baisse la précision, plus le débit théorique peut monter. C’est pourquoi un H100 n’a pas un seul chiffre de performance : il dépend du format choisi, de la variante du GPU, et parfois même du fait qu’on compte ou non la sparsity. Pour garder le raisonnement simple, je prends donc ici 2 000 TFLOPS comme ordre de grandeur commode, pas comme la fiche technique exacte d’un H100 précis.
En rapportant nos 131 TFLOPs à cette capacité théorique, on obtient un plancher d’environ 66 ms pour un H100. Ce chiffre sert surtout à fixer l’ordre de grandeur. En pratique, le temps réel sera plus élevé, car on n’atteint pas en continu le pic théorique annoncé par le constructeur une fois qu’on ajoute les surcoûts réels d’exécution.
Avant d'exécuter ce calcul, il faut que les paramètres soient chargés quelque part. Pour donner un ordre de grandeur, les paramètres d'un modèle en bf16 représentent approximativement 2 octets chacun, soit une multiplication par deux pour sa place mémoire (32B (Milliards) x 2 octets = 64GB).
Une carte H100 ne calcule pas directement une multiplication matricielle complète en INT4 comme elle le fait en bf16 ou en FP8 sur ses tensor cores. Dans un schéma INT4 weight-only, les poids sont stockés en INT4 pour économiser la mémoire et la bande passante, puis déquantifiés à la volée dans un format de calcul plus large, typiquement FP8, FP16 ou bf16 selon le moteur d’inférence et les kernels utilisés.
Les paramètres du modèle K2.6 sont distribué en INT4 (4 bits par paramètre, soit 0,5 octet), ce qui donne 500 Go pour 1T paramètres, qui ne rentre pas sur une seule carte GPU H100 (80 Go de High Bandwidth Memory (HBM)), il en faut 8 pour héberger le modèle complet.
Une carte graphique H100 ne calcule pas nativement en INT4. Les poids sont stockés en INT4 (pour économiser la mémoire et la bande passante), mais sont convertis en FP8 à la volée lors du calcul. On garde donc l'économie mémoire sans perdre la puissance de calcul des tensor cores. Ce sont des unités de calcul spécialisées du GPU, conçues pour exécuter très rapidement les multiplications et additions de matrices, au cœur des calculs des modèles.
Les poids restent en permanence dans la HBM des 8 GPU (la mémoire embarquée sur les cartes). Mais les unités de calcul ne lisent pas directement depuis la HBM : à chaque forward pass, les poids doivent transiter par la SRAM (la mémoire ultra-rapide proche des tensor cores, ~50 Mo). Comme les matrices sont trop grosses pour y tenir, on les découpe en tuiles, des blocs rectangulaires dimensionnés pour la SRAM, que le GPU charge et traite un par un. Pendant qu'il calcule sur la tuile courante, la suivante est déjà en transit depuis la HBM : on recouvre la latence mémoire par le calcul. Le gain du MoE, c'est que pour chaque token, seuls les experts choisis par le routeur ont leurs tuiles streamées.
Lors du prefill, on a 2048 tokens, et chacun pioche 8 experts parmi 384. On fait 2048 x 8 = 16 384 sélections distribuées sur 384 experts, soit en moyenne 43 tokens par expert. Ce qui signifie que pratiquement tous les experts finissent par être sollicités. Sur un prefill, on ne relie donc pas juste une fraction du modèle, on charge quasiment tout, environ 500 Go.
Avec 8 H100 en parallèle, la bande passante mémoire agrégée est d’environ 27 To/s. Lire 500 Go de poids représente donc un plancher d’environ 19 ms. Ce n’est pas le temps réel du prefill, mais une borne basse imposée par la mémoire. À cela s’ajoutent ensuite le calcul lui-même, l’attention, le routage MoE, les échanges inter-GPU, la déquantification et les inefficacités d’exécution. Le temps observé peut donc être nettement supérieur à ce simple plancher mémoire.
Pour estimer le coût, on peut raisonner au niveau du cluster. Le prix d’une H100 chez les fournisseurs cloud varie énormément. Pour fixer un ordre de grandeur, nous prendrons 4 $/h par carte, soit environ 32 $/h pour 8 cartes, donc autour de 0,009 $ par seconde. Si un prefill prend de l’ordre de 80 ms en pratique, cela représente un coût d’environ 0,00072 $ pour 2048 tokens d’entrée, soit environ 0,35 $ par million de tokens d’input.
Ce calcul suppose qu’on sert un seul utilisateur, ou du moins qu’un total de 2048 tokens, à la fois. En pratique, les fournisseurs regroupent plusieurs requêtes dans les mêmes phases d’exécution, ce qui améliore l’amortissement du matériel. Nous verrons plus loin que ce chiffre baisse fortement dès qu’on regroupe plusieurs prompts en batch, car le prefill contient déjà beaucoup de tokens à traiter en parallèle. Mais avant d’en parler, il nous faut un outil de lecture plus général : distinguer ce qui limite une exécution, le calcul ou la bande passante mémoire.
Pourquoi le decode est memory-bound
Un GPU dispose de deux grandes ressources : sa puissance de calcul, mesurée en FLOPS, et sa bande passante mémoire, mesurée en octets par seconde. Une exécution peut être limitée par l’une ou par l’autre. On parle alors d'être compute-bound (limité par le calcul) ou memory-bound (limité par la bande passante).
Le prefill est déjà plutôt limité par la mémoire dans ce calcul simplifié, mais il reste beaucoup mieux rempli que le decode. Le decode, lui, est le cas extrême : très peu de calcul par octet chargé. Pour comprendre pourquoi, on a besoin d'un outil : l'intensité arithmétique.
L'intensité arithmétique, c'est le nombre d'opérations qu’un (cluster de) GPU fait par octet lu depuis la mémoire (HBM).
Si on reprend le prefill, lors de cette étape on charge 500 Go de paramètres (quasiment tout le modèle, vu que le routage disperse les 2048 tokens sur tous les experts). Et on effectue 131 TFLOPs de calcul sur ces paramètres, soit 131 × 10¹² / 500 × 10⁹ ≈ 260 opérations par octet.
Pour savoir dans quel régime on se trouve, on compare cette intensité au ratio entre le pic de calcul et la bande passante mémoire. Cette frontière entre memory-bound et compute-bound s’appelle le ridge point. Pour un H100 en FP8, c'est 1979 TFLOPS / 3,35 To/s ≈ 591 opérations par octet. Notre prefill qui se situe à 260 op/byte est en dessous, nous sommes donc memory-bound.
Memory-bound signifie que les tensor cores attendent surtout les données venant de la HBM. Compute-bound signifie qu’au contraire, la HBM fournit les données assez vite, et que la limite vient surtout des tensor cores eux-mêmes.
Maintenant, posons la question dans l’autre sens. Que se passerait-il si on ne produisait qu'un seul token au lieu d'en traiter 2048 d'un coup ?
Si on chargeait encore les 500 Go complets, l'intensité s'effondrerait à 0,13 op/byte. En réalité le MoE nous sauve, pour un token, seuls 8 experts sur 384 sont sollicités, soit ~16 Go. Mais même ainsi, l'intensité ne remonte qu'à 4 op/byte.
Comme pour chaque octet chargé, les tensor cores ne font qu'une fraction d'opération. Ils sont donc la plupart du temps à attendre la prochaine tuile, la mémoire est saturée. On est memory-bound. Le GPU est extrêmement sous-utilisé.
C'est la situation du decode. Là où le prefill charge les paramètres une seule fois pour traiter tous les tokens du prompt, le decode paie une partie de ce chargement à chaque token qu’il produit. C'est cette distinction qui est la source de la différence de prix entre input et output tokens. Par ailleurs, le decode paie aussi la lecture du KV cache, les communications inter-GPU, et d'autres choses liées à des inefficacités et à des latences induites. Mettons des chiffres là-dessus.
Comme pour le prefill, faisons les deux calculs "memory-bound" et "compute-bound" côte à côte. Cette fois, un seul token sera produit.
Pour le calcul : 1 × 2 × 32B = 64 GFLOPs. Sur une H100 à 2 000 TFLOP/s, cela donne 64 × 10⁹ / 2 × 10¹⁵ ≈ 0,03 ms..
Regardons maintenant la lecture des poids depuis la HBM, la mémoire embarquée des GPU. Contrairement au prefill, le decode ne charge pas la quasi-totalité du modèle. Pour un seul token, le routeur sélectionne seulement 8 experts sur 384, auxquels s’ajoutent les parties communes utilisées par tous les tokens, comme l’attention, les projections, les normalisations et le routeur. Dans notre approximation, cela représente environ 16 Go de poids à lire depuis la HBM. Sur 8 H100, avec environ 27 To/s de bande passante HBM agrégée, cela donne une borne basse de 16 / 27 000 ≈ 0,6 ms.
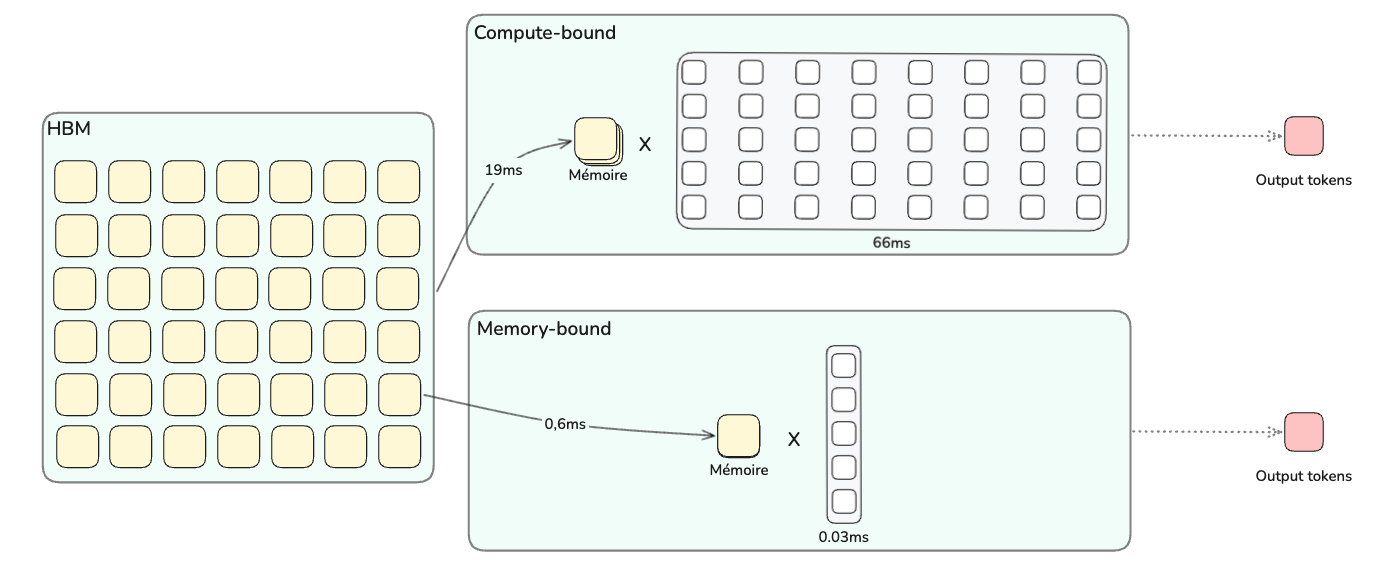
Compute-bound vs Memory-bound
Pour passer à un prix, on applique la même recette que précédemment. Le cluster coûte $0,009 par seconde. Si on produit un token en 0,6 ms, le débit maximum théorique est de 1 / 0,0006 ≈ 1 666 tokens par seconde. Ça donne un coût de $0,009 / 1 666 ≈ $5 par million d’output tokens.
Ce calcul donne une borne basse théorique : si le forward pass ne prenait que 0,6 ms, le cluster pourrait produire environ 1 666 tokens par seconde dans ce scénario simplifié. Cela donnerait environ 5 dollars par million d’output tokens. Mais ce chiffre ne doit pas être lu comme un débit réel de production : il ignore le KV cache, les communications inter-GPU, le routage, les latences de kernels, les déséquilibres entre experts et les inefficacités d’exécution.
Le point important est ailleurs : pour un utilisateur isolé, le cluster est surdimensionné.. En revanche, le coût baisse lorsqu’on regroupe plusieurs requêtes dans un batch. C’est précisément ce que font les fournisseurs, ils remplissent un cluster avec plusieurs requêtes en parallèle. Nous allons voir comment cela fonctionne.
Qu'est-ce qui change avec le batching ?
Revenons sur notre décompte du decode pour un utilisateur. Un forward pass charge 16 Go de poids et produit un token. Sur 8 H100, ça prend 0,6 ms.
Pendant ces 0,6 ms, le cluster entier (640 Go de HBM, 27 To/s de bande passante, 8 H100) tourne pour produire un seul token. Mais est-il possible de produire plusieurs tokens dans le même forward pass ?
C'est ce que fait un batch. On regroupe les requêtes de N utilisateurs et on fait fonctionner le modèle une seule fois pour toutes les requêtes. Chacun reçoit son token, mais on a payé le chargement des poids une seule fois. Pourquoi ça marche, malgré des requêtes aux besoins différents ? Une tuile arrive en SRAM, les tensor cores calculent dessus, puis attendent la suivante. Ce temps d'attente, on peut le remplir. Au lieu de faire passer un seul token dans la tuile avant qu'elle ne reparte, on y fait défiler les 100 tokens qui attendent. Le voyage de la tuile est amorti sur 100 tokens au lieu d'un.
La formule devient :
coût_par_token ≈ (coût_cluster_par_seconde × t_forward) / N
Comme vu précédemment, pour un utilisateur isolé, t_forward ≈ 0,6 ms et N = 1. Cela donne environ $5/M dans notre borne basse théorique.
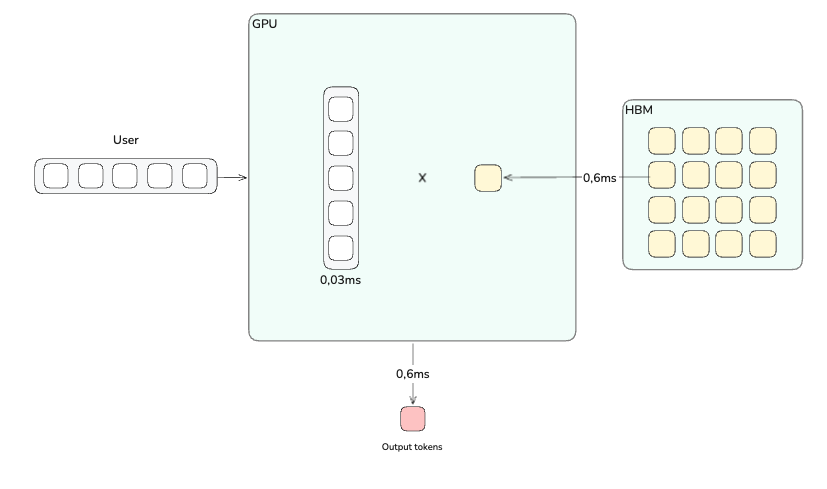
La production d’un token pour un seul utilisateur prend 0,6ms
Pour N utilisateurs, il y a une subtilité. Avec plus de tokens à traiter dans le même forward pass, le routeur va choisir plus d'experts. Avec un seul token, on choisit 8 experts sur 384. À 64 tokens, on a 64 × 8 = 512 sélections réparties sur 384 experts, soit en moyenne 1,3 tokens par expert. À partir de quelques dizaines de tokens, on se retrouve à streamer quasiment tous les experts, comme pour le prefill. Le modèle complet, 500 Go, passe à nouveau dans les unités de calcul.
500 Go sur 8 H100 à 27 To/s, ça prend 19 ms. C'est 30 fois plus long que les 0,6 ms d'un seul utilisateur. Mais pendant ce temps, on produit N tokens au lieu d'un seul.
Refaisons le calcul avec N = 64 et t_forward ≈ 19 ms :
coût ≈ ($0,009 × 0,019) / 64 ≈ $2,7 × 10⁻⁶ par token soit environ $2,70 par million de tokens
On est passé de $90/M (un utilisateur seul) à $2,70/M (64 utilisateurs dans un batch).
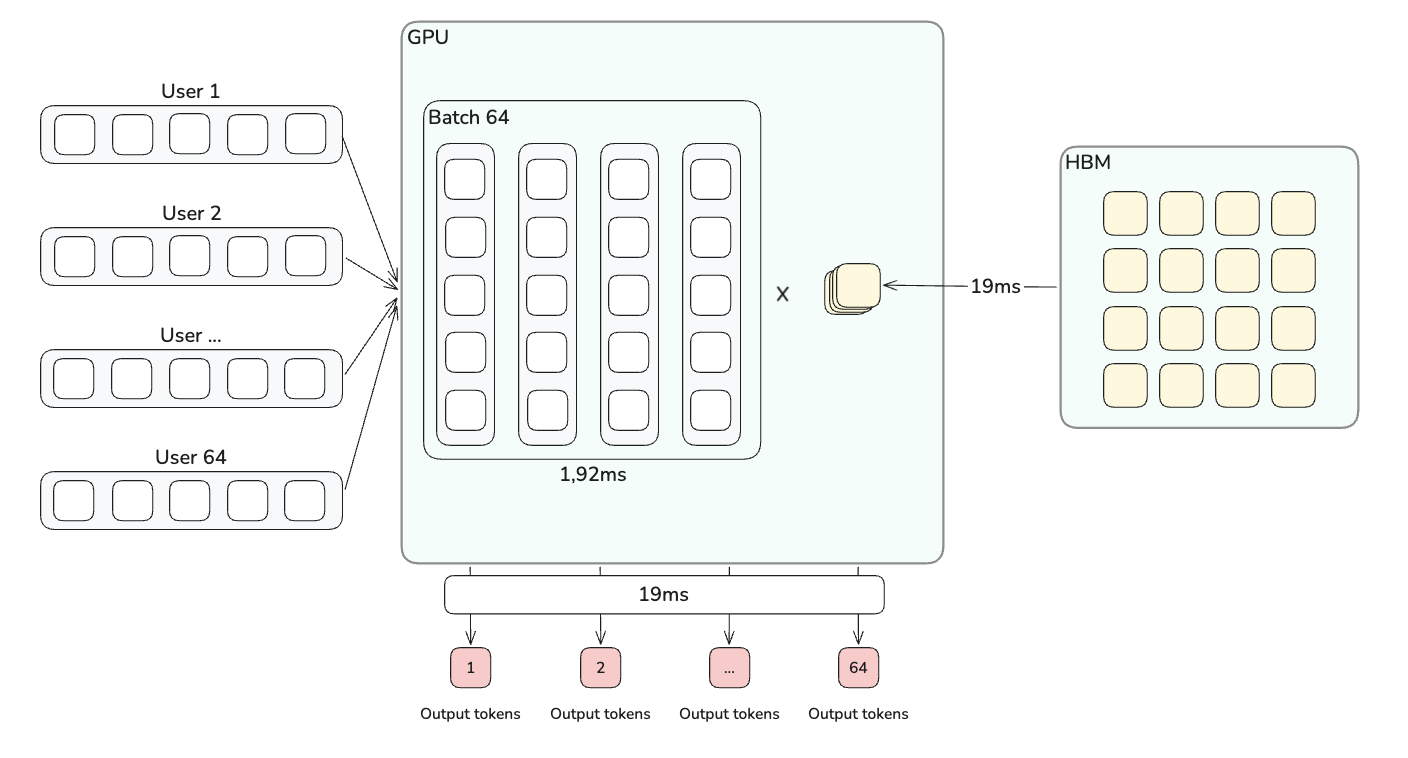
La production de 64 tokens pour 64 utilisateur prend 19ms
Jusqu'où peut-on pousser ? Théoriquement le plafond, c'est le ridge point : tant qu'on est memory-bound, ajouter des utilisateurs au batch ne change pas t_forward (la mémoire reste saturée à 19 ms), donc le coût par token continue de chuter linéairement avec N. On atteint ce ridge quand l'intensité arithmétique rejoint les 591 op/byte du H100 en FP8 :
64N × 10⁹ / 500 × 10⁹ = 591 → N ≈ 4600
Il faut théoriquement produire un token pour 4600 utilisateurs en même temps pour que le cluster soit pleinement exploité. Bien qu’impossible, car ça ne laisserait aucune place pour le KV cache et autres erreurs potentielles.
En pratique, les fournisseurs combinent le batching avec d’autres techniques : le chunked prefill, qui découpe les longs prompts en tranches pour les intercaler avec le decode ; le continuous batching, pour ne jamais laisser un slot vide ; et le speculative decoding, pour produire plusieurs tokens par étape. Mais le batching reste le levier économique principal.
Pour aller plus loin, il faut aller plus large. Les vrais fournisseurs ne tournent pas sur 8 H100, ils tournent sur 72 ou 144 H100 en expert-parallel (chaque carte héberge quelques experts, les tokens sont routés vers la bonne carte). Ça leur permet de tenir des batch beaucoup plus gros, de mieux paralléliser les experts, et amortir un chargement plus important.
Il faut toutefois distinguer le batching du decode et le batching du prefill. Dans le decode, chaque utilisateur ne produit qu’un seul token par forward pass. Il faut donc beaucoup d’utilisateurs simultanés pour augmenter l’intensité arithmétique. Dans le prefill, c’est différent : un seul utilisateur peut déjà apporter 2048, 10 000 ou 100 000 tokens d’un coup. Le batch n’a donc pas besoin de contenir des milliers d’utilisateurs pour mieux remplir les GPU.
Reprenons notre prefill de 2048 tokens. Si on batche 64 prompts de cette taille, on traite : 64 × 2048 = 131 072 input tokens
Le calcul total devient : 64 × 131 TFLOPs ≈ 8,4 PetaFLOPs
Sur 8 H100, avec environ 16 PFLOP/s (2000 TFLOP/s x 8) théoriques, cela donne un plancher de calcul autour de 8,4 PFLOPs / 16 PFLOP/s ≈ 0,52 s. À $0,009 par seconde pour le cluster, le coût devient : ($0,009 × 0,52) / 131 072 ≈ $0,000000036 par token, soit $0,036 par million d'input tokens.
Ce chiffre n’est pas un coût réaliste, c’est un plancher. Il suppose que le cluster est parfaitement rempli et qu’on se rapproche fortement du pic théorique. Pour un ordre de grandeur plus robuste, on peut regarder les mesures publiques de SGLang sur DeepSeek : leur déploiement sur des noeuds de 8 H100 atteint environ 52 300 input tokens/s par noeud pour des prompts de 2000 tokens, avec prefill-decode disaggregation et expert parallelism. À $2/h par H100, cela donne environ $0,085 par million d’input tokens. À $4/h, hypothèse plus conservatrice côté cloud, on obtient environ $0,17 par million d’input tokens.
Je retiendrais donc trois niveaux : environ $0,04/M comme plancher théorique, $0,08 à $0,20/M comme ordre de grandeur réaliste pour un prefill optimisé, et $0,35/M pour notre prefill isolé de départ.
Pour le decode à grande échelle, on peut regarder les mesures de Tensor Economics,qui modélise et confronte les performances de DeepSeek V3.1 et Kimi K2 à des déploiements réels. Sur un cluster de 72 H100, ils obtiennent un ordre de grandeur autour de 1 400 tokens par seconde par GPU, soit environ 100 000 tokens/seconde pour le cluster entier. À $2/h (prix utilisé par Tensor Economics) le H100, cela donne : 72 × $2 / 3600 ≈ $0,04/s, soit :$0,04 / 100 000 × 1 000 000 ≈ $0,40 par million d’output tokens.
Avec un coût d’input tokens autour de $0,10/M et d’output tokens a $0,40/M, nous sommes en dessous des prix API pratiqués par les principaux acteurs.
Le rôle du KV cache
Pour que notre batch tienne à grande échelle, il faut que le KV cache ne devienne pas le nouveau goulot d'étranglement. C'est le moment de voir ce que ça signifie.
Quand le modèle “fait attention” à un token, il calcule deux représentations de ce token, une clé (K) et une valeur (V). Ces deux représentations permettent aux tokens suivants de “regarder” ce token sans avoir à tout recalculer. Sans cache, à chaque nouveau token produit, il faudrait recalculer les K et V de tous les tokens précédents, ce qui serait quadratique à la longueur de la séquence.
L'astuce, c'est de garder ces clés et valeurs en mémoire une fois qu'elles ont été calculées. Quand on génère le token suivant, on ne calcule que les K et V du nouveau token, et on les ajoute au cache existant. Le coût par token reste linéaire. On échange du compute contre de la mémoire.
Le prix à payer, c'est la mémoire. Chaque utilisateur dans un batch a son propre KV cache, qui grandit à chaque token généré et qui doit être streamé à chaque forward pass. Avec une attention classique (multi-head attention, comme sur Llama 3), le KV cache fait environ 500 Ko par token. Un batch de 64 avec 10 000 tokens de contexte par utilisateur, ça fait 64 × 10 000 × 500 Ko = 320 Go de KV cache à charger à chaque forward pass. Ça peut devenir plus que le chargement des poids du modèle, et ça deviendrait vite le nouveau problème principal.
C'est là qu'entre en jeu MLA (Multi-head Latent Attention), introduit par DeepSeek en 2024. Au lieu de stocker les clés et valeurs complètes dans le cache, on les compresse dans une seule représentation latente. On obtient un résultat d'environ 70 Ko par token, soit 7 fois moins que l'attention classique, et sans dégrader la qualité du modèle. Notre batch 64 × 10 000 tokens passe à 45 Go de KV cache, et on peut tenir des batchs plus gros sur des contextes plus longs sans saturer la bande passante.
DeepSeek a poussé plus loin en septembre 2025 avec DSA (DeepSeek Sparse Attention), qui lit qu'une sous-partie (les 2 048 tokens jugés les plus pertinents par un "indexeur" léger) du contexte à chaque forward pass, au lieu du contexte entier. Avec un contexte long (100 000 tokens et plus), DSA peut encore réduire d’environ 5 fois la quantité de KV cache lue à chaque étape. C’est ce type d’optimisation qui rend économiquement plus viable les usages à très long contexte, où chaque requête peut charger des centaines de milliers d’input tokens.
Chaque innovation architecturale qui réduit la bande passante consommée par le decode se traduit directement par une baisse du coût de production de tokens, et donc par une marge supplémentaire pour le fournisseur (ou un prix de vente plus bas, selon sa stratégie).
Ce que cet article ne capture pas
Tout ce qu’on a fait jusqu’ici reste une approximation, même si elle s’appuie sur des mesures publiques à grande échelle. On a pris des hypothèses et on les a poussées jusqu'au bout. Mais certaines choses pourraient faire changer les chiffres.
D'abord, le $0,40 par million de tokens qu'on prend comme référence vient de mesures publiques sur DeepSeek V3.1 servi par des tiers, pas de données internes d'Anthropic ou d'OpenAI. Leurs modèles sont fermés, leurs stacks d'inférence aussi, et on ne sait pas exactement ce qui s'y passe. Il est tout à fait possible qu'Opus ou GPT-5 soient significativement plus gros que K2.6 ou DeepSeek V3.1, qu'ils tournent sur des configurations plus chères, ou qu'ils aient des contraintes de latence qui empêchent de pousser le batching aussi loin. Dans ce cas, leur coût marginal serait plus élevé que nos $0,40.
Ceci étant dit, un élément me fait penser que l'écart n'est pas massif : les prix API de Kimi K2.6 ($0,60 input, $2,80 output) et de Claude Sonnet ($3 input, $15 output) restent du même ordre de grandeur, alors que le modèle K2.6 semble obtenir de meilleurs résultats sur plusieurs benchmarks.
La différence se joue probablement ailleurs : coût d'entraînement, R&D, infrastructure, support, marketing, salaires, marge visée par l'entreprise. Toute cette partie, on ne la voit pas et on ne la calcule pas. Encore une fois, cet article parle uniquement du “coût calculable” de produire un token une fois que le modèle existe et tourne.
Deuxième point important : tous nos calculs sont faits en se basant sur une H100. Ce GPU a bientôt trois ans au moment où j'écris. Les H200 (sorties fin 2023) ont 1,7x plus de HBM et 1,4x plus de bande passante. Les B200 (sorties en 2024) poussent encore plus loin. Et les GB300 / NVL72 changent la donne sur le multi-node. Chaque génération de hardware réduit mécaniquement le coût de production, parfois dans des proportions significatives. Les $0,40/M sur 72 H100 avec un batch 64 sont déjà une estimation "conservatrice" par rapport à ce que les gros fournisseurs peuvent faire sur du hardware plus récent.
On retrouve donc un modèle économique d’échelle, appliqué à une infrastructure.
Combien de tokens avec 20€, 100€ ou 200€
Aujourd’hui, il existe plusieurs façons d’utiliser des LLM. La plus simple, et historiquement la plus courante, consiste à poser une question relativement courte et à laisser le modèle produire une réponse plus longue.
Dans ce cas, le ratio peut facilement être en faveur de l’output. Si j’envoie une question de 400 tokens et que le modèle produit une réponse de 2000 tokens, alors le ratio est de 1:5. Autrement dit, le modèle écrit cinq fois plus qu’il ne lit. C’est encore plus d’actualité avec les modèles de raisonnement, où une partie des tokens produits peut correspondre à du raisonnement interne avant la réponse finale. OpenAI documente par exemple les reasoning tokens comme une partie des tokens générés par le modèle, et Anthropic indique aussi que les tokens de réflexion étendue sont comptés dans les output tokens facturés.
Pour donner un ordre de grandeur, avec le tokenizer o200k_base utilisé par les modèles récents d’OpenAI, le texte français complet du Petit Prince représente environ 21 600 tokens, selon l’édition et la présence ou non des titres de chapitres.
En se basant sur les mesures publiques précédentes, soit 0,10 dollar par million d’input tokens et 0,40 dollar par million d’output tokens, on peut calculer le coût complet pour produire 1 million d’output tokens. Dans un ratio 1:5, le modèle lit 1 token pour en écrire 5. Donc, pour écrire 1 million de tokens, le modèle doit lire 0,2 million de tokens. Le coût devient alors 0,2 × $0,10 + $0,40 = $0,42
À titre informatif, un budget de 20 dollars donnerait accès à environ 9,5 millions d’input tokens et 47,6 millions d’output tokens. Avec 100 dollars, on passerait à 47,6 millions d’input tokens et 238 millions d’output tokens. Avec 200 dollars, à 95,2 millions d’input tokens et 476 millions d’output tokens.
Mais lorsque l’on passe à un système d’agents, le ratio change de sens. Un agent de code, comme Claude Code ou Codex, ne se contente pas de répondre à une question. Il construit son contexte au fil de l’eau : il lit des fichiers, inspecte des logs, exécute des commandes, relit les erreurs, compare des diffs, garde l’historique de ses actions, puis recommence.
Dans ce cas, le modèle lit souvent beaucoup plus qu’il n’écrit. On ne parle plus d’un ratio 1:5, mais plutôt de ratios comme 5:1, 20:1, 50:1, voire davantage. Dans l’autre sens, un ratio 5:1 signifie que pour 1 token écrit, l’agent a lu 5 tokens.
Dans un système d’agents, avec un budget de 20 dollars, un ratio 5:1 donne accès à environ 111,1 millions d’input tokens et 22,2 millions d’output tokens. Avec 100 dollars, on passe à 555,6 millions d’input tokens et 111,1 millions d’output tokens. Avec 200 dollars, à 1,11 milliard d’input tokens et 222,2 millions d’output tokens.
Or, les benchmarks publics suggèrent que les agents de code sont souvent au-delà de ce simple 5:1. SWE-Effi mesure explicitement les tokens envoyés au modèle et les tokens générés par celui-ci. Le papier décrit un effet de “token snowball” : l’agent qui enchaîne les appels, ajouté aux réponses précédentes et l’historique des actions font augmenter le nombre d’input tokens. Plusieurs configurations se situent autour de 10:1 à 30:1, et certains cas montent beaucoup plus haut lorsque l’agent multiplie les appels sans converger.
Prenons un scénario 20:1 comme point central. Dans ce cas, pour produire 1 million d’output tokens, l’agent doit aussi lire 20 millions d’input tokens. (20 × $0,10 + $0,40 = $2,40)
Pour un ratio de 20:1, et avec un budget de 20 dollars, on a accès à environ 166,7 millions d’input tokens et 8,3 millions d’output tokens. Avec 100 dollars, à 833 millions d’input tokens et 41,7 millions d’output tokens. Avec 200 dollars, à 1,67 milliard d’input tokens et 83,3 millions d’output tokens.
Encore une fois, ces chiffres ne sont pas des prix API. Ce sont des ordres de grandeur construits à partir de notre hypothèse de coût d’inférence, appuyée par des mesures publiques : 0,10 dollar par million d’input tokens et 0,40 dollar par million d’output tokens. Cette hypothèse sert à raisonner sur une infrastructure de production de tokens, pas de prétendre connaître les coûts internes d’OpenAI, d’Anthropic ou de Google.
Remerciements
Merci à Nicolas, Godefroy, et à tous les OCTO qui ont pris le temps de relire, questionner et challenger cet article. Leurs retours ont permis de clarifier les hypothèses, de rendre les calculs plus lisibles, et d’éviter plusieurs raccourcis trop faciles. Cet article est meilleur grâce à ces discussions.