L'affaire des pages disparues
(Cet article est une traduction provenant du blog de Loïc LEFLOCH)
Un bon ami à moi a rencontré un problème étrange qu'il n'arrivait pas à résoudre lors du déploiement de son application.
Il m’a demandé de jouer le rôle du "canard en plastique", mais le problème n’était pas facile à corriger. L’application fonctionnait parfaitement partout, sauf en production, où elle rencontrait des erreurs. Voici l’histoire de comment un bug apparemment aléatoire s’est transformé en une véritable aventure de débogage.
Le bug
Lors de la mise à jour d’une application React Single Page Application (SPA) en production, certaines pages ont mystérieusement cessé de fonctionner. Le problème réapparaissait de manière sporadique sur différentes pages après une mise à jour, y compris sur des pages qui n’avaient même pas été modifiées dans la dernière version.
Visuellement, la mise en page des pages concernées était correcte, mais leur contenu ne s’affichait pas. Ce bug affectait différentes pages de manière aléatoire.
Avant de demander de l’aide, mon ami avait déjà réalisé de nombreux tests et identifié plusieurs éléments de contexte :
- Incohérences entre les environnements : La même version de l’application fonctionnait parfaitement en test et en staging, mais échouait en production.
- Comportement spécifique au domaine : Héberger le build de production sur un autre domaine réglait le problème.
- Erreurs aléatoires sur les pages : Les pages concernées affichaient correctement leur mise en page, mais leur contenu ne se chargeait pas. La page affectée changeait d’une version à l’autre.
Nouvel indice débloqué : Il y avait donc quelque chose de spécifique à l’environnement de production qui causait le problème.
Investigation du problème
L’application est une SPA développée avec React, ce qui signifie qu’elle repose essentiellement sur un fichier statique index.html qui charge les ressources JavaScript (JS) et CSS.
Sur la page dysfonctionnelle, l’erreur suivante apparaissait dans la console :
“Unexpected SyntaxError: expected expression, got '<' sur le fichier PlayerRecordPage.ded3f4ef.chunk.js.”
Cette erreur signifie généralement que le navigateur n’a pas pu interpréter correctement ce fichier JavaScript.
Première question à se poser : qu’est-ce qu’un chunk ? Pourquoi y a-t-il un fichier JavaScript spécifique à une page ?
L’application utilise Create React App, qui prend en charge le découpage du code (code splitting).
“Plutôt que de télécharger l’ensemble de l’application avant que les utilisateurs ne puissent l’utiliser, le code splitting permet de diviser le code en petits morceaux (chunks) qui sont chargés à la demande.”
L’application est configurée de manière à ce que chaque route ait son propre fichier JavaScript généré lors du build. Lorsqu’un utilisateur accède à une page, l’application charge le fichier JavaScript correspondant.
Cela explique pourquoi le site semble fonctionner correctement, mais que, sur certaines pages, seul le layout est visible alors que le contenu ne s’affiche pas : l’application est incapable d’exécuter le code de la page en raison de l’erreur.
Mise en page de l’application
Create React App utilise Webpack en interne pour construire l'application React.
Petite parenthèse : Create React App a longtemps été la solution privilégiée pour créer une nouvelle application React. Il est désormais obsolète et remplacé par React frameworks.
const routes = [
{
name: 'PLAYER_RECORD',
path: '/players/:identifier/record',
handler: loadable(() =>
import(/* webpackChunkName: "PlayerRecordPage" */ '../pages/playerRecord')
)
}
]
Cela signifie que le build va générer un fichier par fichier importé à la demande (lazy-imported).
Le nom du fichier suit le format [nombre].[hash].js.
- Le nombre est par défaut un index incrémenté.
- Nous pouvons utiliser les Magic Comments de Webpack pour configurer l’import à la demande (lazy import).
- webpackChunkName nous permet de donner un nom à notre chunk. Plutôt qu’un numéro aléatoire, nous obtenons un nom significatif, comme PlayerRecordPage.
- Dans notre build, le fichier généré s’appelait PlayerRecordPage.ded3f4ef.chunk.js.
Cela nous permet de voir immédiatement que l’erreur dans la console concerne le fichier contenant le code de la page qui ne fonctionne pas. Si le fichier avait été nommé 4.ded3f4ef.chunk.js, il aurait été plus difficile de comprendre d’où venait le problème.
Le hash dans le nom du fichier et le caching
Le hash dans le nom du fichier permet d’optimiser le cache à long terme.
Il s’agit d’un hash unique généré à partir du contenu du fichier.
- Si le contenu du fichier change lors d’un build ultérieur, le hash sera différent.
- Si le fichier ne change pas, le hash reste le même, évitant ainsi au navigateur de le re-télécharger inutilement.
Nouvel indice débloqué : Seules certaines pages spécifiques sont affectées par le bug. Cela pourrait être lié à un changement de chunk (le fichier source a été modifié depuis le dernier build).
Mais le code de cette page n’a pas changé depuis le dernier déploiement. Le chunk devrait donc être le même.
Un piège : propagation des changements dans les chunks
La technique de code splitting génère un fichier JavaScript spécifique pour le code de la page. Ce fichier intègre tout le code nécessaire au bon fonctionnement de la page.
Même si le code React de la page n’a pas changé, un fichier importé par cette page peut avoir été modifié.
Par exemple, si un composant générique Button situé dans app/components/Button a été mis à jour, cela peut affecter le chunk généré.
En effet, nous avons constaté que le code d’un composant générique avait été modifié.
Nouvel indice débloqué : Le hash du fichier de build a changé depuis le dernier déploiement.
Nous comprenons maintenant mieux comment le build est généré et comment les routes sont affichées.
Revenons maintenant à l’erreur dans la console pour creuser davantage.
Pourquoi le navigateur n’a-t-il pas pu interpréter le fichier JavaScript ?
Inspection avec les outils de développement
Dans l’onglet Network des DevTools, nous constatons que le fichier JavaScript est considéré comme un document au lieu d’un script.
C’est étrange. Il devrait être interprété comme un script.

Contenu du réseau
En regardant le contenu du fichier chargé par le navigateur, nous constatons que le fichier JavaScript problématique contient du HTML au lieu de code JavaScript.

Aperçu de la console : "Vous devez activer JavaScript pour exécuter cette application."
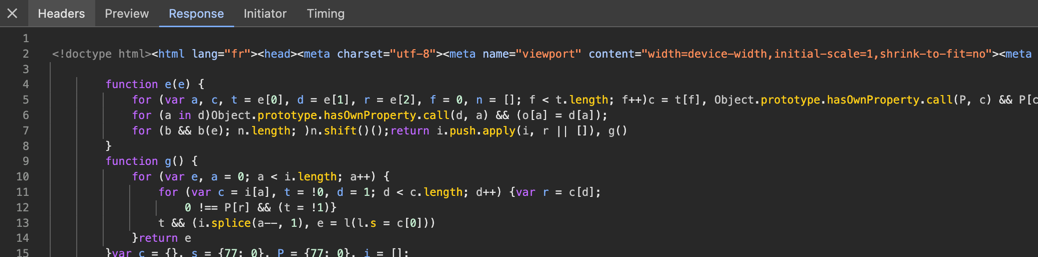
Source de la console - le contenu est en HTML
Ce n’est pas n'importe quel HTML, mais celui de notre fichier index.html de l'application.
Cela signifie que le serveur fournit le contenu du fichier index.html lorsque nous demandons ce fichier JavaScript spécifique.
Pourquoi notre serveur servirait-il le contenu du fichier HTML ?
Regardons cela de plus près.
L'application est servie via un serveur Apache avec la configuration suivante :
# Simplified example
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^ index.html [L]
</IfModule>
Cette configuration redirige toute demande de fichier inexistant vers index.html, ce qui est une pratique courante pour les SPA. Étant donné que les SPA utilisent leur propre routeur côté client pour gérer la navigation, toutes les URL qui ne correspondent pas à des fichiers existants sont dirigées vers index.html afin de permettre à l'application de gérer le chemin demandé.
Si nous recevons le contenu du fichier index.html, cela signifie qu'Apache n'a pas trouvé le fichier que nous avons demandé et est revenu à index.html.
Nouvel indice débloqué : Le fichier n'existe pas sur le serveur lorsqu'il est demandé.
> ls static/js/
main.js DashboardPage.c999599b.chunk.js PlayerRecordPage.296bf010.chunk.js
Nous pouvons voir que le fichier existe.
Le serveur pense que le fichier n'existe pas, mais il existe. Ce qui est vraiment étrange.
Est-ce un bug d'Apache ? Pas vraiment. Un bug du système de fichiers ? Allez !
Souvenez-vous quand nous disions que le même build de l'application ne présentait pas d'erreurs lorsqu'il était sur un autre domaine ? Ou en environnement de test ?
Quelles sont les différences entre l'environnement de production et les autres ?
Cloudflare.
Cloudflare est un réseau de distribution de contenu (CDN) et une plateforme de sécurité conçue pour optimiser les performances des sites web, améliorer la sécurité et accroître l'évolutivité.
Elle fonctionne en mettant en cache les réponses du serveur, en les distribuant à travers son réseau mondial, et en servant le contenu aux utilisateurs depuis le serveur le plus proche pour réduire la latence.
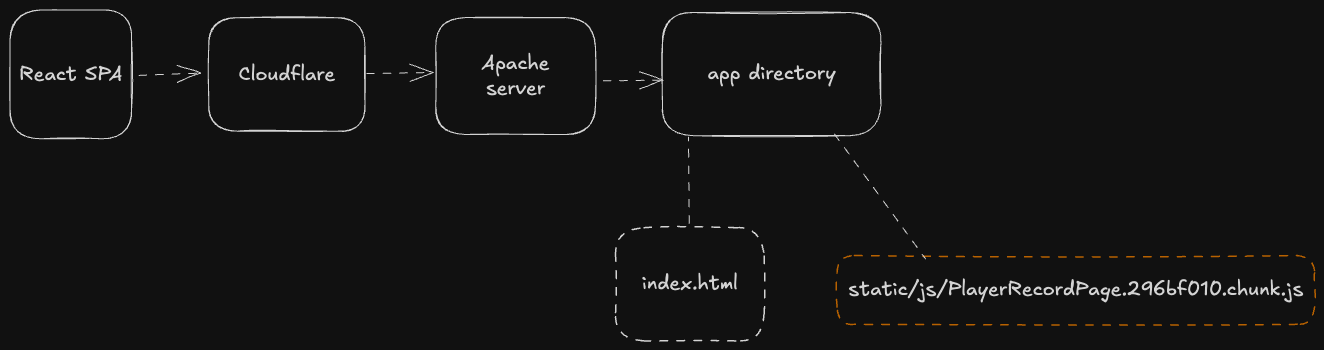
Diagramme d’architecture
“il n'y a que deux choses difficiles en informatique : l'invalidation du cache et le nommage”
Nous avons une erreur étrange et le cache est impliqué. Cela doit venir du cache.
Nouvel indice débloqué : Le cache peut être impliqué.
Cloudflare met en cache la réponse. Si le serveur Apache a par erreur servi le fichier index.html, Cloudflare l'a mis en cache ainsi, traitant le fichier .js comme du HTML. Les demandes suivantes pour ce fichier .js chargeraient le contenu mis en cache de index.html au lieu du fichier JavaScript correct.
Que se passe-t-il si nous demandons le fichier directement depuis le serveur sans passer par Cloudflare ?
> curl http://localhost:4000/static/js/PlayerRecordPage.296bf010.chunk.js
(this["webpackJsonp-website"] = this["webpackJsonp-website"] || []).push([[29], {
1003: function(e, a, t) {
...
Bingo ! Nous avons du code JavaScript, pas du HTML.
Ici, Cloudflare a le fichier index.html en cache, tandis que le fichier existe sur le serveur.
Nous avons un problème de cache.
Que se passe-t-il si nous vidons ce cache Cloudflare ? La page fonctionne à nouveau ! Le fichier JavaScript contient du JavaScript et non du HTML.
Confirmation du problème :
- En contournant Cloudflare et en demandant directement le fichier JavaScript depuis le serveur, celui-ci a renvoyé le contenu correct.
- Vider le cache de Cloudflare a résolu le problème.
Cloudflare met en cache ce que nous lui donnons. Cela signifie qu'à un moment donné, le serveur Apache a renvoyé le contenu du fichier HTML au lieu du fichier JavaScript. Et Cloudflare l'a mis en cache.
Donc, Cloudflare n'est pas le coupable. Dans ce cas, les capacités de mise en cache de Cloudflare ont involontairement amplifié le problème. Le serveur Apache a servi un contenu incorrect, Cloudflare l'a mis en cache et a livré la réponse incorrecte aux utilisateurs suivants.
Nouvel indice débloqué : Le fichier demandé n'existait pas lors de la première demande, mais existait après.
Résumons nos connaissances actuelles
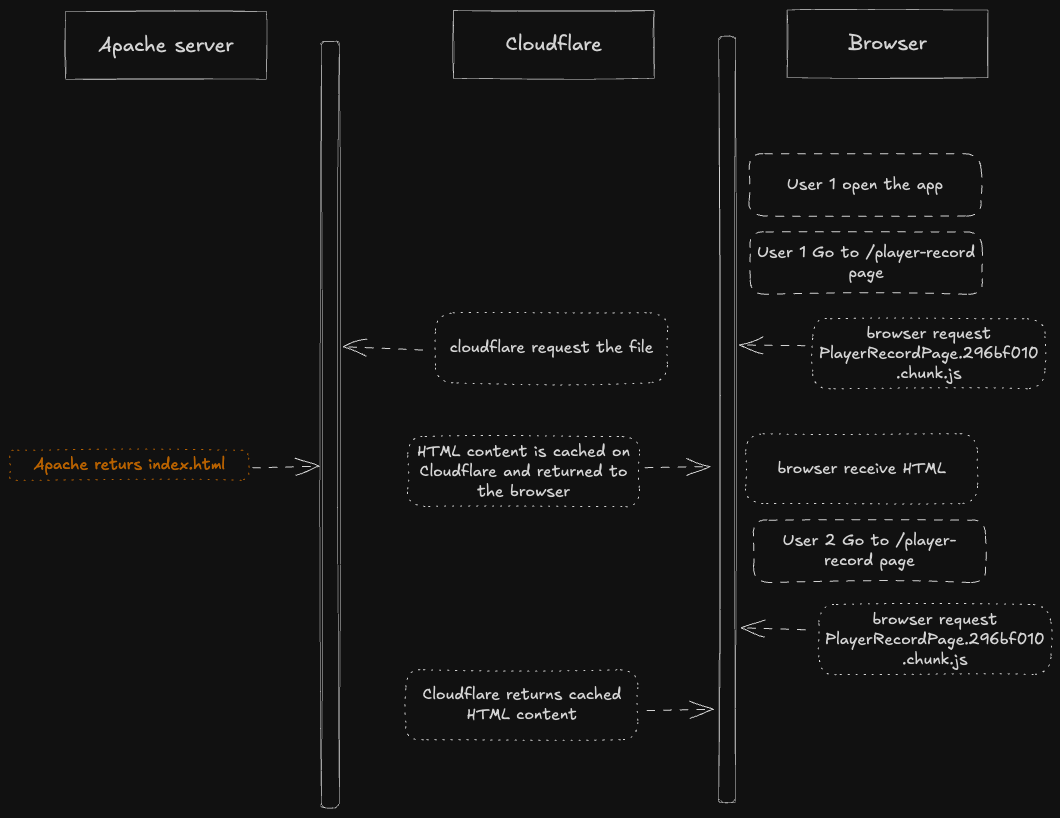
Résumé du bug
Comment pouvons-nous demander le fichier JavaScript alors qu'il n'existe pas ?
Voyons comment le fichier JavaScript est demandé.
Afin de demander le bon fichier JavaScript, l'application a un code JavaScript dans le fichier index.html qui associe la route chargée de manière paresseuse à son nom de fichier correspondant sur le serveur. De cette manière, nous pouvons faire correspondre le nom de la route avec le fichier qui contient son code.
// list the corresponding webpackChunkName for the file number
{
46: "LoginPage",
47: "PlayerRecordPage",
}
// list the hash for the file number
{
46: "44903d7a",
47: "296bf010",
}
En utilisant cette carte, l'application peut construire l'URL du nom de fichier /static/js/PlayerRecordPage.296bf010.chunk.js.
Nous savons que cette carte est valide car nous avons vu que le fichier existe sur le serveur. Et il y a peu de chances que create-react-app ait un bug.
Cela signifie qu'à un moment donné, le fichier index.html nous a donné un nom de fichier correct, mais le fichier n'existait pas sur le serveur.
Bizarre, non ?
Comment le fichier index.html peut-il faire référence à un fichier qui n'existe pas selon Apache ?
Cela signifierait qu'il fait référence au fichier alors qu'il n'existe pas encore.
Cela a du sens. Cloudflare est activé uniquement pour l'environnement de production. Nous ne pouvons pas reproduire le bug dans d'autres environnements où il n'y a pas de cache. Ce qui signifie qu'à un moment donné, le fichier existe.
Nouvel indice débloqué : Cela peut être lié à la manière dont le déploiement en production est effectué.
Ma première hypothèse était que le déploiement en production avait été effectué en utilisant la commande de build de create-react-app.
Lorsqu'on fait un build, cela crée un nouveau répertoire vide build et y place les fichiers. Le build pourrait générer le fichier index.html avant le fichier JavaScript.
Pour confirmer cela, il faudrait creuser en profondeur sur la manière dont create-react-app effectue le build.
Avant d'en arriver là, apprenons-en plus sur la façon dont le déploiement en production est effectué.
Comment fonctionne votre déploiement en production, avons-nous demandé ?
"Nous faisons le build sur le serveur de test avec les paramètres de test pour vérifier que tout fonctionne.
Une fois cela fait, nous faisons le build sur le serveur de staging avec les paramètres de production pour vérifier que cela ne casserait pas en production.
Ensuite, nous déplaçons le répertoire de build du serveur de staging vers le serveur de production."
Et comment le déplacez-vous ?
"Nous avons un script qui utilise rsync pour copier le répertoire de build dans un répertoire nommé next-deployment-build sur le serveur de production."
Et ensuite, que faites-vous ?
"Nous allons sur le serveur de production. Nous faisons une sauvegarde de notre répertoire de production actuel. Ensuite, nous utilisons rsync pour copier le contenu du répertoire next-deployment-build dans notre répertoire de production."
Voyez-vous ce qui se passe ici ? rsync.
Rsync est un outil de copie de fichiers qui synchronise les fichiers et répertoires entre deux emplacements. Il transfère uniquement les différences entre la source et la destination, assurant des mises à jour efficaces tout en préservant les permissions des fichiers, les horodatages et les liens.
Voici un exemple de script de déploiement en production utilisant rsync.
#!/bin/bash
# backup the production directory
rsync -avz \
--progress \
--delete-after \
/var/www/production /var/www/production-backup
# move files to production directory
rsync -avz \
--progress \
--delete-after \
/var/www/next-deployment-build/ /var/www/production
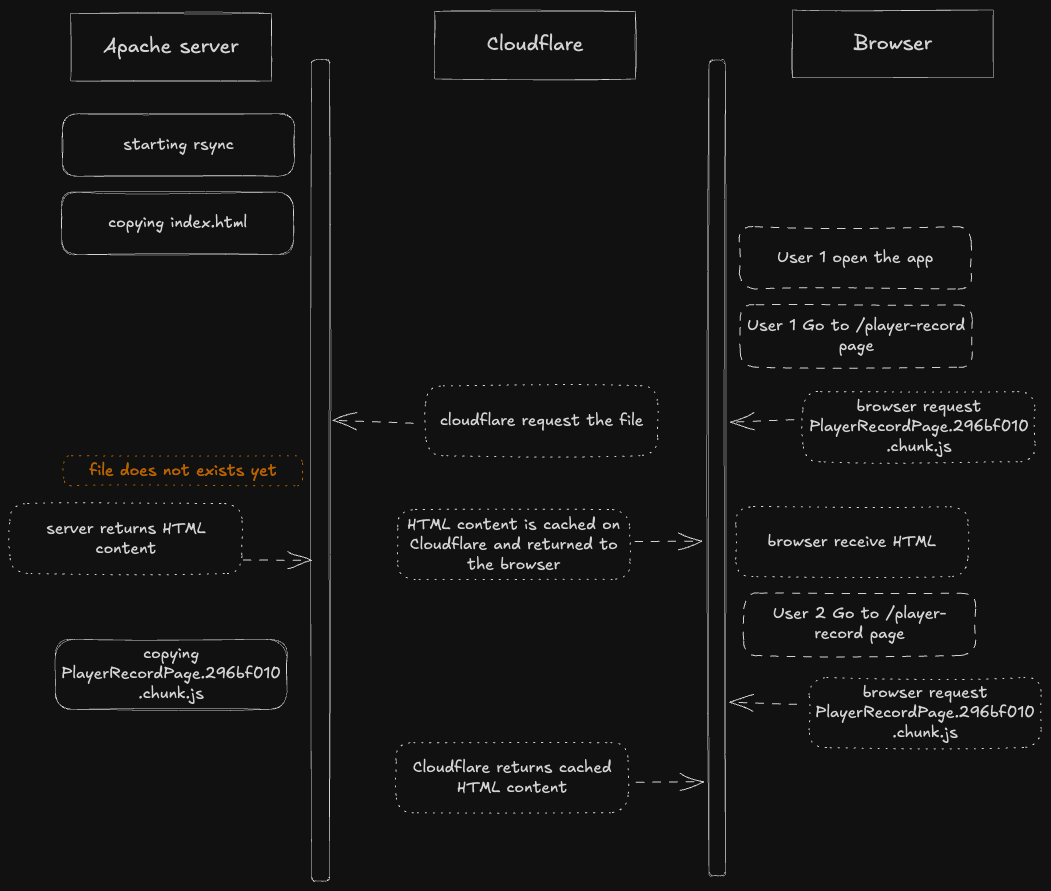
Donc, rsync copie les fichiers un par un dans le répertoire de production.
Cela signifie qu'il existe une fenêtre de temps où le nouveau fichier index.html a été copié, mais le fichier JavaScript ne l'a pas encore été.
Si quelqu'un charge le site pendant cette fenêtre, il servira le nouveau fichier index.html, qui nécessitera le fichier JavaScript, qui n'a pas encore été copié.
Le serveur Apache ne voit pas le fichier, il se rabat sur le index.html. Cloudflare le met en cache tel quel, en tant que contenu HTML.
L'utilisateur suivant aura le même index.html. Le fichier JavaScript est maintenant dans le répertoire de production car le rsync est terminé.
Mais Cloudflare continue de servir ce qu'il a dans son cache, à savoir le fichier HTML. Sans le cache de Cloudflare, un simple rafraîchissement de la page aurait résolu le problème. Ce qui aurait rendu le débogage du problème beaucoup plus compliqué. Comme nous l'avons vu, nous n'avons pas pu le reproduire dans d'autres environnements.
Même si nous avions pu reproduire le bug en chargeant le site à la fenêtre de temps exacte, le prochain rafraîchissement de l'application aurait corrigé le problème.
Sur un serveur de test avec peu d'utilisateurs, il était presque impossible d'avoir les bonnes conditions pour reproduire le bug.
Alors qu'en production, avec un grand nombre d'utilisateurs et le cache, le bug avait beaucoup plus de chances de se produire.
Que se passe-t-il ?
Pourquoi le débogage a été difficile ?
- Différences d'environnement : Le cache Cloudflare n'était pas activé dans les environnements de staging ou de test.
- Nature intermittente : Le problème n'est survenu que lorsque :
- Un nouveau hash SHA-1 a été généré pour un fichier JavaScript de la page.
- Un utilisateur a accédé à cette page spécifique pendant la fenêtre de déploiement.
- Le cache amplifiait le problème : Le cache de Cloudflare a conservé la réponse HTML incorrecte, même après que le fichier JavaScript ait été disponible sur le serveur. Mais cela nous a aidé à trouver la cause profonde du problème.
Alors, comment réparer cela ?
La solution : Déploiement atomique
Le déploiement atomique est une stratégie de déploiement conçue pour minimiser les temps d'arrêt et les risques en garantissant que les changements sont appliqués en une seule opération fluide. Cela empêche les utilisateurs d'accéder à des déploiements partiels et garantit que le site est entièrement opérationnel sans temps d'arrêt.
1: Préparation
Le processus commence dans un environnement de staging, qui est une réplique exacte de l'environnement de production. Cela garantit que la nouvelle version est testée dans des conditions qui imitent de près l'utilisation en conditions réelles. Par exemple, l'environnement de staging doit avoir la même configuration Cloudflare que l'environnement de production. Tester dans un environnement de staging réduit le risque de problèmes inattendus lorsque la nouvelle version est mise en production.
2: Isolation : nous gardons les anciennes et nouvelles versions séparées
La nouvelle version de l'application est complètement isolée de la version en production pendant le processus de déploiement. Cette isolation garantit que l'application en production reste intacte face à tout changement ou erreur potentielle dans la nouvelle version. L'isolation agit comme un filet de sécurité, vous permettant de tester et de déployer sans perturber les utilisateurs.
3: Changement de version
Lorsque vous êtes prêt à déployer la nouvelle version, vous passez à la nouvelle version en une seule opération rapide et atomique.
- Redirection du trafic : Diriger le trafic vers un nouvel ensemble de serveurs hébergeant la nouvelle version.
- Liens symboliques : Modifier les liens système de fichiers pour pointer vers la nouvelle version de l'application.
Un changement rapide minimise les temps d'arrêt.
Implémentation du déploiement atomique
Au lieu de copier les fichiers de manière incrémentielle, la nouvelle stratégie de déploiement fonctionne comme suit :
- Ajouter le build de staging dans /var/www/next-deployment-build
- Préparer le répertoire de déploiement dans /var/www/deployments/
- Ajouter le build au nouveau répertoire de déploiement
- Créer un lien symbolique vers le dossier de production.
#!/bin/bash
# Generate a timestamp
timestamp=$(date +"%Y%m%d%H%M%S")
# 1. copy build from staging server to next-deployment-build
# ...
# 2. Prepare the new directory name with the timestamp
new_dir="/var/www/deployments/$timestamp"
# 3. Add the build to the new directory.
mkdir $deployment_dir
cp -r /var/www/next-deployment-build/* "$deployment_dir/"
# 4. Create symlink from our deployment directory to our production directory. Voilà!
ln -sfn "$deployment_dir" /var/www/production
Cas résolu
Le bug était une combinaison de facteurs qui a rendu sa reproduction et son débogage difficiles au début. Nous avons eu la chance que le cache Cloudflare rende le problème plus visible.
Nous avons passé un bon moment à chercher quelle partie du système causait le problème.
J'ai essayé autant que possible d'expliquer le processus de débogage que nous avons suivi et les différentes étapes que nous avons prises pour trouver la cause profonde du problème. C'est un bon exemple de la façon dont certains problèmes n'apparaissent qu'avec un certain nombre d'utilisateurs et comment le déploiement atomique peut aider à prévenir ces problèmes.