Kubeflow: le ML industrialisé et à l’échelle dans Kubernetes
Pour les entreprises exploitant l’Intelligence Artificielle, bien maîtriser son intégration dans les écosystèmes de données reste un enjeu majeur. Parmi les défis à relever pour mettre en place l’IA de manière pérenne, l’industrialisation a su tirer son épingle du jeu pour devenir un élément indispensable d’une bonne intégration de l’IA en production. Dans cet article, nous vous proposons de vous tourner vers l’après industrialisation : le passage à l’échelle !
Cet article fait suite à plusieurs mois d’expérimentation de la solution Kubeflow permettant de déployer du Machine Learning (ML) à l’échelle dans un environnement Kubernetes. Il s’attachera à expliquer les briques constituantes de Kubeflow et les étapes d’adaptation d’un cas d’usage à son utilisation, pour finalement élargir sur les opportunités MLOps qu’offre l’outil.
Le Machine Learning “industrialisé et à l’échelle” : c’est quoi ?
Industrialisation du Machine Learning
Souvent, les projets faisant appel au ML commencent par une phase exploratoire où l’enjeu est de dérisquer le projet, s’assurer de la viabilité du cas d’usage et de la pertinence du flux de données. Pendant longtemps, les cas d’usage de ML se limitaient à une phase d’expérimentation plus ou moins exploratoire dont les modèles et artéfacts produits étaient directement envoyés en production, sans plus d’étapes intermédiaires. Il était alors difficile de retracer les actions ou les données sources ayant produit un modèle. Aujourd’hui, l’accent est mis sur la construction de systèmes permettant la maîtrise et la répétabilité des étapes réalisées et des artefacts utilisés. Ce sont les caractéristiques d’une application de ML pérenne.
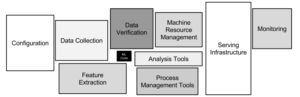
L’industrialisation des applications de ML consiste à mettre en place différentes mesures permettant d’assurer la maîtrise et la répétabilité des processus mis en jeu. On parle même parfois de Continuous Delivery for Machine Learning, dont on pourra citer quelques exemples : le monitoring de notre système de data science, automatiser les actions manuelles comme la récupération des données, l’entraînement des modèles, leur déploiement…
Une fois industrialisé, tout l’enjeu est de passer à l’échelle. C'est-à-dire de pouvoir amener non pas l’ensemble d’un service de ML jusqu’en production de manière maîtrisée et répétée, mais plusieurs simultanément. Dans cet article, nous allons nous intéresser à Kubeflow, une plateforme développée par Google, permettant de faire du machine learning à l'échelle.
Le pari qu’a fait Kubeflow est de miser sur une plateforme bien connue pour savoir gérer du contenu en parallèle et à l’échelle : Kubernetes.
Le ML à l’échelle, introduction à Kubeflow
L’histoire de Kubeflow commence chez Google comme un outil interne permettant d’exécuter des pipelines de TensorFlow Extended. Initialement destiné à faciliter l’orchestration de tâches TensorFlow dans un cluster Kubernetes, Kubeflow est désormais un outil open source, multi-cloud et multi-plateforme permettant de faire du Machine Learning dans Kubernetes. Sa mission est de permettre l’entraînement à l’échelle et le déploiement de modèles de Machine Learning le plus simplement possible, en laissant Kubernetes faire ce pour quoi il est réputé : la portabilité, la facilité de déploiement de micro-services et le passage à l’échelle sur demande. Kubeflow s’appuie sur la conteneurisation et le découplage en micro-services pour former une plateforme portable pouvant s’exporter sur n’importe quel environnement capable de déployer un cluster Kubernetes (notamment les principaux cloud providers).
Pour réaliser cette mission, Kubeflow s’appuie sur un jeu de micro-services interconnectés où chacun remplit un rôle bien précis. Leur but est de permettre de rendre simple et efficace le déploiement d’une application de ML en production.
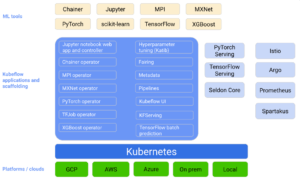
L’intention de cet article étant de détailler comment déployer une application de ML, on se contentera de lister ceux qui sont pertinents dans ce but:
- Kubeflow pipelines, qui permet de définir et de programmer des workflow de ML.
- Argo Workflows, qui permet d’orchestrer et d'exécuter ces pipelines dans Kubernetes
- Kubeflow Metadata, qui permet de tracer et sauvegarder les pipelines et leurs artéfacts (paramètres, hyper-paramètres, performances ou encore des métriques personnalisées).
- KfServing, qui permet de construire des services de prédiction autour des modèles entraînés.
- Istio Service Mesh, qui gère et organise les interactions réseau entre tous les micro-services.
Au global, Kubeflow est composé d’un grand nombre de micro-services. Ils visent à permettre l’adaptation de n’importe quel cas d’usage de ML à une implémentation dans Kubernetes, quel que soit son framework. Cette adaptation peut être retranscrite en plusieurs étapes :
- Écriture du workflow de Machine Learning à l’aide du SDK Python de Kubeflow Pipelines
- Orchestration et exécution du workflow dans des pods Kubernetes par Argo Workflows
- Persistance des modèles produits dans un Model Registry.
- Exposition des résultats dans un service de prédiction
Ce sont ces étapes qui vont particulièrement nous intéresser dans cet article.
Un workflow de ML dans Kubernetes
Adaptation d’un cas d’usage
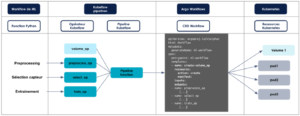
Le SDK de Kubeflow Pipelines permet de préparer le cas d’usage de ML à une exécution dans Kubernetes. Pour être compatibles avec la plateforme, les étapes du workflow doivent être toutes indépendantes, c’est-à-dire que chacune doit être packagée et exécutable indépendamment des autres.
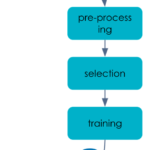
Prenons par exemple le cas de l’entraînement d’un modèle, il s’agit de découper le workflow en étapes indépendantes comme :
- preprocessing
- sélection des features utiles
- entrainement
Le résultat de ce workflow est un modèle entraîné permettant par la suite de faire de la prédiction.
L’étape clé dans ce découpage est le formatage des étapes sous forme de tâches exécutées dans des conteneurs, consommant un jeu de données et produisant un artéfact en sortie. De ce fait, chaque étape est totalement indépendante et seul le recoupement en cascade des jeux de données en entrée et en sortie de toutes les étapes permet de définir le workflow global.
Ce recoupement est fait au niveau de l’orchestrateur Argo Workflows. Le SDK de Kubeflow pipelines permet de convertir ces conteneurs en un Direct Acyclic Graph (DAG) intelligible par Argo Workflows. Comme dans tout orchestrateur, pour que Argo Workflows puisse construire un arbre d’exécution, il faut définir des opérations qu’il soit capable de comprendre et ensuite les organiser les unes par rapport aux autres ainsi que les dépendances qui les régissent.
from kfp import dsl
def preprocessing_op(input_path: str, sep: str, preprocess_output: str, volume):
return dsl.ContainerOp(
name="preprocess",
image=f"registry.gitlab.com/augustin.ardon/ml_workflow/
preprocessing:v1.0.0",
arguments=[
"--input-path", input_path,
"--sep", sep,
"--output-path", "%s/{{workflow.name}}/preprocessed.csv" % preprocess_output
],
file_outputs={
"output": "/output.txt"
},
pvolumes={preprocess_output: volume}
)
Il s’agit de la définition d’un opérateur à l’aide du SDK de Kubeflow pipelines. Cet opérateur réalise une étape de preprocessing et exploite une image créée au préalable. Cette définition comporte des paramètres définissant l’emplacement des jeux de données consommés et produits. En outre, on utilise un objet volume, qui est lui aussi un objet Kubeflow Pipelines et qui représente l’abstraction d’un espace de stockage Kubernetes. Il permet de faire en sorte que tous les pods partagent un espace de stockage commun de manière à faire transiter les états intermédiaires.
Une fois tous les opérateurs définis, il suffit de les organiser et de faire correspondre les jeux de données produits avec ceux consommés.
from kfp import dsl
@dsl.pipeline()
def pipeline_function(data_url=DATA_URL, sep=SEP, pvc_size=PVC_SIZE, model_bucket=MODEL_BUCKET):
vop = dsl.VolumeOp(name='create-volume', resource_name='my-artifacts-volume', modes=['ReadWriteOnce'], size=pvc_size)
processed = preprocessing_op(input_path=data_url, sep=sep, preprocess_output="/mnt, volume=vop.volume)\
.after(vop)
selected = select_op(input_path=processed.output,
selected_output="/mnt", volume=vop.volume)\
.after(processed)
trained = train_op(input_path=selected.output, model_bucket=model_bucket, trained_output="/mnt, volume=vop.volume)\
.after(selected)
Pour définir le DAG mentionné plus tôt, on crée une fonction Python décorée à l’aide de l’objet pipeline du SDK de Kubeflow pipelines. On peut alors appeler les opérateurs les uns après les autres en faisant correspondre les artéfacts produits et consommés entre les tâches.
Ici, les données d’entrée et de sortie du pipeline sont externalisées dans des espaces de stockage distants de type bucket S3. Tous les autres états intermédiaires transitent entre les opérateurs à l’aide du volume créé en tant que premier opérateur. Les dépendances entre les tâches sont définies grâce à l’attribut after et permettent ainsi de construire un DAG.
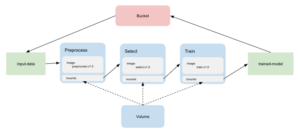
Le SDK de Kubeflow pipelines dispose d’un compilateur qui permet finalement de convertir ce pipeline en une structure de données intelligible par l’orchestrateur Argo Workflows. On a alors créé une ressource Kubernetes et lancé notre premier pipeline d’entraînement.
Il s’agit là d’un premier pas vers l’industrialisation. Les opérateurs de Kubeflow pipelines encapsulent des images Docker qui sont versionnées indépendamment les unes des autres. Et le pipeline global d’entraînement est matérialisé par un fichier de configuration YAML, lui aussi versionné. On peut donc construire une première ébauche de stratégie de versioning pour pouvoir tracer et historiser les entraînements. Une stratégie de versioning plus globale sera détaillée dans la suite de l’article.
Il est également important de remarquer le découplage entre les étapes constituantes du workflow et le pipeline en lui-même. La plateforme respecte également ce découplage étant donné que ce sont des micro-services différents qui sont responsables de ces opérations. Grâce à ce découplage, il est plus facilement possible de tester et d’identifier les sources d’erreurs dans les cas d’usage de ML.
Et sous le capot, qu’est ce qu’il se passe ?
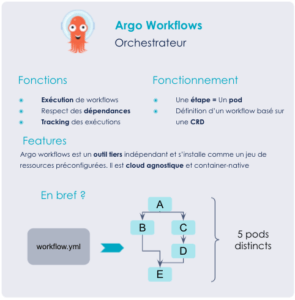
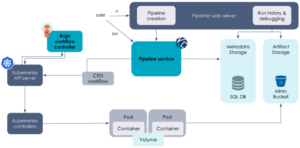
En réalité, c’est l’orchestrateur Argo Workflows qui réalise toutes les étapes présentées dans la partie précédente. Argo Workflows est un orchestrateur de tâches en parallèle et il est container-native. Il permet de construire des workflows complexes dans Kubernetes où chacune des étapes est exécutée dans un pod distinct. Il dispose notamment de fonctionnalités élaborées permettant de faire passer des paramètres et de faire persister des artefacts une fois les étapes réalisées.
Son fonctionnement est basé sur la définition d’une Custom Resource Definition (CRD) de Kubernetes nommée Workflow, qui contient l’ensemble des informations précisées précédemment. Écrite en YAML, cette CRD décrit entièrement le workflow. On y retrouve la définition des étapes, les dépendances des tâches ou la gestion de la persistance des états.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: artifact-passing-
spec:
entrypoint: artifact-passing-
templates:
- name: whalesay
container:
image: docker/whalesay:latest
command: [sh, -c]
args: ["cowsay hello world | tee /tmp/hello_world.txt"]
outputs:
artifacts:
# generate hello-art artifact from /tmp/hello_world.txt
# artifacts can be directories as well as files
- name: hello-art
path: /tmp/hello_world.txt
Par exemple, ce fichier représente un workflow dont la seule opération est de générer un artéfact hello-art contenant le retour de la commande cowsay hello world.
Une fois définie, cette CRD est analysée par le contrôleur d’Argo Workflows et l’ensemble des ressources nécessaires à l’exécution du workflow sont créées les unes après les autres.
Cependant, les workflows précédemment définis ne sont définis qu’à l’aide de ressources Kubernetes de type CRD, et donc écrites en Yaml. Pour faciliter la transition entre un workflow de machine learning classique et un workflow exécutée dans Kubernetes, Kubeflow pipelines fournit un SDK en Python permettant de faire la transition entre ces deux structures de données.
En effet le SDK de Kubeflow pipelines permet de construire une structure de données transitoire entre le workflow de machine learning et la CRD Kubernetes de Argo Workflows. Cette structure de données est d’ailleurs définie en Python, ce qui la rapproche du cas d’usage de machine learning initial et permet une adaptation à Kubernetes d’autant plus simple sur le terrain.
Outre les mécanismes présentés, Argo Workflows et Kubeflow Pipelines assurent un traçage et un historique de l’ensemble des paramètres et des artéfacts générés. Ces mécanismes permettent d’une part de suivre les exécutions en cours mais aussi de les comparer les unes aux autres.
Après l’entraînement : la prédiction dans Kubeflow
A l’issue de l’entraînement, on obtient un modèle de ML entraîné et disponible. Seulement voilà, il faut encore exploiter ce modèle pour construire un service d’inférence et permettre de réaliser des prédictions.
Créer un service d’inférence n’a jamais été aussi simple qu’avec KfServing
Pour ce faire, Kubeflow dispose d’une intégration avec Knative Serving. Knative Serving est une application cloud-native qui permet de créer des applications serverless dans un environnement Kubernetes. Cette intégration est réalisée à l’aide du service KfServing.
KfServing est en quelque sorte un passe-plat entre n’importe quel framework de machine learning et Knative Serving. Il permet, à partir d’un modèle de ML, de construire un service d’inférence et de réaliser des prédictions de manière efficace. Il dispose de toutes les fonctionnalités de Knative Service comme l’auto-scaling et le serverless, et construit une application autour du modèle fourni.
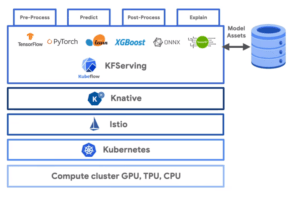
De la même façon que Argo Workflows, le fonctionnement de KfServing repose sur une CRD Kubernetes nommée InferenceService. Cette ressource contient l’ensemble des éléments nécessaires à la construction d’un service d’inférence, et en pratique cette configuration minimale n’est que l’emplacement de stockage du modèle autour duquel il faut construire un service d’inférence. Ce sont les rouages internes du service KfServing qui vont se charger de télécharger le modèle, de l’encapsuler dans une application et de faire réaliser les prédictions lorsque le service reçoit des requêtes.

Ce sont ici deux exemples de définition de CRD InferenceService. L’une est adaptée au framework Scikit-learn là où l’autre est prévue pour exploiter TensorFlow. La seule différence entre ces deux configurations est le mot clé caractérisant le type de modèle et son adresse de stockage.
Outre l’emplacement du modèle, il est possible de renseigner de multiples types d'opérations que le service doit exécuter en amont de la prédiction. Il est par exemple possible d’ajouter des étapes de processing de la donnée d’entrée. Ces étapes peuvent être soit ajoutées à l’aide des fonctionnalités classiques de KfServing qui supportent la plupart des framework, soit à l’aide d’images Docker personnalisées.
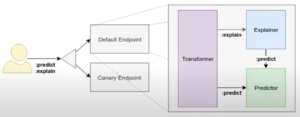
Ainsi, pour déployer une application pour réaliser de la prédiction dans Kubeflow, il suffit de créer une CRD InferenceService pointant sur le modèle enregistré, et de créer la ressource dans l’environnement Kubernetes.
apiVersion: "serving.kubeflow.org/v1beta1"
kind: "InferenceService"
metadata:
name: "sklearn-irisv2"
spec:
predictor:
sklearn:
protocolVersion: "v2"
storageUri: "gs://seldon-models/sklearn/iris"
Il s'agit de la configuration au format YAML de la CRD InferenceService pour construire un service d’inférence autour d’un modèle de ML défini à l’aide de Scikit-Learn et entraîné sur le cas d’usage Iris. Le service est alors disponible et opérationnel au sein du cluster.
SERVICE_HOSTNAME=$(kubectl get inferenceservice sklearn-irisv2 -o jsonpath='{.status.url}' | cut -d "/" -f 3)
curl -v \
-H "Host: ${SERVICE_HOSTNAME}" \
-d @./iris-input.json \
http://${INGRESS_HOST}:${INGRESS_PORT}/v2/models/sklearn-irisv2/infer
Encore une fois, le seul élément qui caractérise le service d’inférence est ce fichier de configuration YAML. On obtient donc un nouvel artéfact qui détermine une seule partie de notre application et qui peut être versionné pour s’inscrire dans une stratégie d’industrialisation efficace.
De plus, le découplage vu auparavant dans la partie entraînement est présent ici aussi. Le modèle et l’application qui l’expose sont totalement découplés aussi bien dans leur définition qu’à l’échelle des services de Kubeflow.
Et derrière, il se passe quoi ?
En réalité, après la création de la CRD InferenceService, les contrôleurs de KfServing construisent simplement une application autour du modèle renseigné dans la définition de la CRD. Cette application a seulement pour but d’encapsuler le modèle et de permettre de lui passer les requêtes que le service va recevoir. La responsabilité de la création du service est elle entièrement laissée à Knative Serving.
C’est enfin le couplage de Knative et d’Istio Service Mesh qui va créer un service au sens Kubernetes du terme, et l’exposer au sein de l’écosystème Kubernetes. Istio est responsable de la gestion du réseau entre tous les micro-services composants Kubeflow. Etant donné que l’on crée en quelque sorte un nouveau micro-service à l’aide de Knative Serving, il est nécessaire qu’Istio le prenne en charge également.
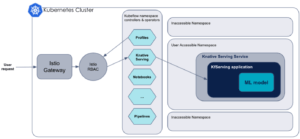
Industrialisation et passage à l’échelle d’un workflow de ML
Versionner et historiser pour mieux industrialiser
En regroupant l’ensemble des éléments nécessaires à l'entraînement d’un modèle de ML et à la construction d’un service de prédiction, on peut lister les objets suivants :
- Les données d’entrée
- Le code Python du cas d’usage de ML
- Les images Docker construites pour chacune des étapes du workflow
- La fonction définissant le DAG du workflow écrite avec Kubeflow Pipeline
- Le modèle entraîné
- Le fichier de configuration YAML définissant le service de prédiction
L’ensemble de ces éléments étant soit matérialisé par du code dans un répertoire, soit par des fichiers de configurations écrits en YAML, il devient possible de construire une stratégie de versioning complète et efficace. Couplée à une usine de développement et de production des artéfacts, on obtient une stratégie construisant les artéfacts et les images Docker à la volée.
Outre ces éléments de code et artéfacts, il est également nécessaire de versionner et d’historiser les éléments caractéristiques des entraînements tels que les méta-paramètres, et les données d’entrées ou encore les modèles entraînés. Kubeflow intègre directement ces mécanismes d’historisation à l’aide de son service Metadata et permet d’historiser ces éléments ainsi que de stocker leurs adresses de stockage. De même, Kubeflow intègre désormais un service de Model Registry qui assure la même fonction pour les modèles entraînés.
L’orchestrateur Argo Workflows intègre également les mécanismes permettant de relier ces versions, artéfacts et historiques entre eux et ainsi pouvoir retracer quel code source est à l’origine de quels artéfacts, quels méta-paramètres ont été utilisés pour produire quel modèle. Avec les bons paramétrages du service Kubeflow Pipelines, il est également possible de lier les performances des modèles à ces historisations.
Observer pour mieux comprendre
Outre le versioning, le monitoring des performances est lui aussi rendu possible d’une part par Kubeflow et Argo Workflows, et d’autre part par l’environnement Kubernetes lui-même.
- Kubeflow et Argo Workflows traquent et enregistrent automatiquement les performances et les métadonnées associées à tous les pipelines d’entraînement. Il est alors possible de retracer les performances de chaque modèle entraîné en retraçant quels sont les pipelines, les méta-paramètres et les données sur lesquels il se base.
- Une fois déployés, il est également possible de mesurer les performances des modèles. En effet, l’environnement Kubernetes offre une parfaite intégration avec des solutions de monitoring tel que Prometheus. Une fois relié au modèle entraîné et avec les bons paramètres, Prometheus peut relever les performances du modèle en temps et réel et relever des alertes en cas de détérioration des performances.
Il est cependant nécessaire de noter que les configurations de monitoring des performances des modèles ne sont pas encore assurées par Kubeflow. Les évolutions de la plateforme tendent à faciliter l’intégration avec des services de monitoring propres à Kubernetes, mais ces configurations restent à la charge de l’administrateur, aussi bien sur le plan de la configuration des services que de la construction et exposition des observables au sein de services d’inférences.
Et tout ça à l’échelle ?
Lorsque l’on parle de passage à l'échelle, on peut différencier trois types d’échelles différentes.
- L’augmentation du nombre d’entraînements et de services déployés
En prenant le pari de s’implémenter dans un environnement Kubernetes, Kubeflow bénéficie de fait de tous les avantages de la plateforme. Kubernetes est intrinsèquement capable de gérer de multiples applications à l’échelle. Par extension, c’est grâce au pattern contrôleur de Kubernetes que Kubeflow permet de gérer des applications de ML à l’échelle. Toutes les applications gérées par Kubeflow sont à terme retranscrites en ressources Kubernetes. C’est alors la responsabilité de la plateforme de les provisionner dans la mesure des ressources disponibles dans le cluster à un instant donné.
De ce fait, Kubeflow offre la possibilité de lancer de multiples entraînements en parallèle. Ces tâches seront ajoutées à une queue au sens Kubernetes du terme et exécutées.
- L’adaptation de la quantité de ressources allouées à un service pour faire face aux demandes des utilisateurs
L’ensemble des services liés au fonctionnement de Kubeflow est régi par des ressources Kubernetes qui leur assurent un scaling horizontal. C'est-à-dire que pour faire face à la demande des utilisateurs, Kubernetes va automatiquement augmenter le nombre d’instances disponibles pour répondre à ces requêtes.
De la même façon, lorsque le service KfServing de Kubeflow crée des services d'inférence, les mécanismes de passage à l’échelle sont directement incorporés dans le service. De ce fait, les services d’inférence propres à chaque modèle sont eux aussi scalables de manière horizontale.
- L’augmentation du nombre d’utilisateurs pouvant avoir accès à la plateforme
Pour faciliter l’administration des ressources, des pipelines d’entraînement et des services de prédiction, Kubeflow offre la possibilité de cloisonner les ressources selon des namespaces - des espaces de cloisonnement Kubernetes. On peut alors imaginer une configuration de Kubeflow avec différentes équipes, chacune disposant de multiples pipelines et modèles… pour obtenir une plateforme de déploiement d’applications de ML à l’échelle.
Et le MLOps dans tout ça ?
Grâce aux opportunités de versioning et de monitoring, on peut imaginer une stratégie d’intégration et de déploiement continu. En effet, l’adaptation progressive d’un cas d’usage de ML à une implémentation dans Kubeflow peut s’apparenter à un grand pipeline qui va petit à petit amener le cas d’usage à une application déployée et disponible dans un environnement Kubernetes, un peu comme une application classique en fait.
Les fonctions Python définissant les étapes du workflow sont du code source, qui une fois testé et packagé par de la CI produit un package sous la forme d’une image Docker. La fonction pipelines de Kubeflow exploite ces packages et les met en relation. Après une première étape de déploiement continu, on obtient un premier workflow de ML qui tourne dans Kubernetes et qui produit un modèle entraîné. Enfin, c’est au tour du service d’inférence de construire une application autour du modèle entraîné après un nouveau déploiement.
En reprenant la vision MLOps proposée par Google dans cet article, on peut enrichir le graphique qu’il propose à l’aide des briques de Kubeflow.
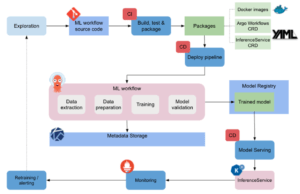
Conclusion
Comme dit précédemment, cet article fait suite à plusieurs mois d'expérimentations de Kubeflow dans le cadre de POCs. J’ai pu mettre en œuvre la plateforme et déployer de multiples modèles, versionnés et monitorés au sein d’un cluster Kubernetes. Il semblerait que Kubeflow réponde ainsi à la plupart des engagements qu’il prétend prendre sur le déploiement d’applications de ML dans Kubernetes. Je n’ai malheureusement pas pu tester toute la partie relative à la gestion d’une organisation à l’échelle avec la gestion des utilisateurs, la multi-tenancy et l’isolement des ressources...
Nous avions parlé dans cet article des avantages de découpler les architectures des projets de Machine Learning pour accélérer le delivery. Ici, chacune des étapes est découplée et gérée par un micro-service indépendant. De la retranscription d’un workflow de ML en ressources Kubernetes, à la construction du modèle d’inférence, toutes les responsabilités sont portées par des services différents.
Lors de mes expérimentations, j’ai notamment apprécié la facilité avec laquelle il était possible de penser une stratégie de versioning et de déploiement automatisé des modèles et des cas d’usage. Il existe des APIs pour manipuler la plupart des objets de Kubeflow Pipelines ce qui facilite grandement les déploiements et les manipulations des versions.
Je garde cependant des réserves sur l’aspect Plug&Play de la plateforme Kubeflow. Il s’agit en effet d’une plateforme qui comporte un très grand nombre de briques logicielles différentes et interdépendantes et dont les configurations sont parfois complexes à saisir dans leur ensemble. La prise en main de Kubeflow pour des applications basiques est certes relativement simple, mais on se rend vite compte qu’il ne s’agit que de la partie émergée de l’iceberg, et lorsque les besoins deviennent plus complexes, les choses se corsent !
On pourra retenir de la plateforme qu’il s’agit d’un bel outil qui permet de faire du ML dans Kubernetes. Il évolue très vite et dans une direction qui répond aux principaux besoins des utilisateurs : le monitoring, une meilleure CI… Il ne faut cependant pas en sous-estimer les complexités sous-jacentes.
Pour aller plus loin
Tutorial: From Notebook to Kubeflow Pipelines to KFServing: the Data Science... - Karl Weinmeister
Advanced Model Inferencing Leveraging KNative, Istio & Kubeflow Serving - Animesh Singh & Clive Cox