Kafka répond-il à mon besoin ?
Vous gérez de gros volumes de données et vous vous demandez si Kafka répond à vos besoins ? Vous êtes au bon endroit. Ici, nous allons vous présenter les différents cas d’utilisation et les contraintes de Kafka. Cela vous permettra, on l’espère, de faire un choix éclairé.
Au début de la précédente décennie, Linkedin a vu son architecture se complexifier en passant d’un modèle monolithique à une architecture orientée microservice. L’augmentation du trafic s’accompagnant d’un besoin d’exposer leurs données sous forme d’API, leurs pipelines de données se sont multipliés pour en déplacer toujours plus.
C’est dans ce contexte que Kafka est né. Les bases sont simples : un bus de messages capable d’encaisser du très (très) haut débit et un contrat d’interface simple. Kafka est désormais open source et largement utilisé.
Sa popularité vient de sa gestion des grosses volumétries, sa tolérance aux pannes et sa communauté d’utilisateurs. Là où d'autres files de messages s'essoufflent lorsque le nombre de messages augmente, Kafka peut facilement passer à l’échelle pour supporter la charge.
Le fonctionnement de Kafka
La grande scalabilité de Kafka provient de son architecture. Nous allons donc dans un premier temps faire un rappel de ses principes.
Basé sur des logs
Kafka est avant tout un moyen d’échanger des messages. Il permet à des applications d’émettre des messages qui pourront être lus par une ou plusieurs applications consommatrices. Selon le cas d’utilisation, l’ordre de lecture des messages peut être important ou non. Dans le cas où l'ordre de lecture doit être identique à celui de l’écriture, on retrouve une structure en file d'attente FIFO (First In First Out).
Dans Kafka, la donnée est modélisée sous forme de logs. Chaque message est matérialisé par une ligne. Le message peut être du plain text, du JSON, du binaire ou qu’importe, le système n’impose rien. Chaque message possède un identifiant unique qu’on appelle offset.
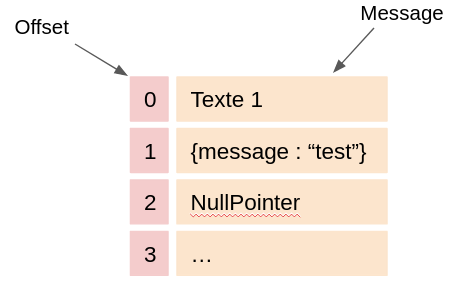
Les messages et les offsets associés sont stockés directement sur le disque. La séquence est immuable : il est impossible de changer l’ordre des messages une fois écrits. Néanmoins, ils sont supprimés automatiquement lorsque leur délai de rétention (7 jours par défaut) est dépassé.
Dans le jargon Kafka, on appelle producer une application qui va produire un message et un consumer une application qui va le lire. L’action de lire un message ne demande pas au consumer de connaître sa position dans la séquence car le dernier offset qu’il a lu est stocké au sein du cluster.
Diviser pour mieux distribuer
Les données dans Kafka sont divisées en topics qui contiennent des partitions. Un topic est un regroupement logique de messages, comme une table dans une base de données.
Sur chaque partition, le mode de lecture des messages se fait uniquement de manière séquentielle à partir du premier message. Ainsi, on peut garantir que l’ordre de consommation des messages est identique à l’ordre de production sur chaque partition.
Les partitions d’un topic sont réparties entre les différentes machines d’un cluster afin de distribuer la charge : cela réduit ainsi le temps de réponse aux requêtes envoyées par les consumers.
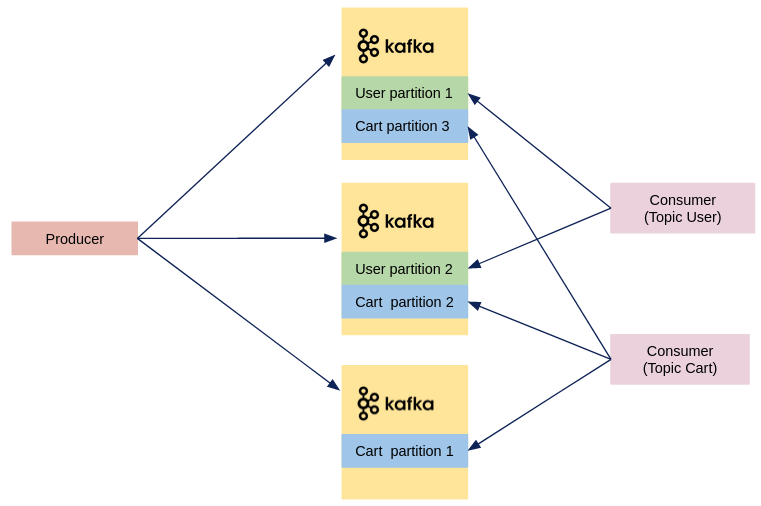
En plus d’être distribuées, les partitions sont répliquées sur le cluster. Comme ce sont des séquences immuables, elles peuvent être répliquées sans risquer que des mises à jour concurrentes viennent compromettre les données. Cela permet une résilience du cluster : si l’une des machines venait à être hors ligne, les données seraient toujours accessibles sur les autres machines.
Utilisable avec tout type de base
Maintenant que vos données sont stockées dans votre cluster Kafka, vous allez vouloir les lire pour les traiter. Pour vous faciliter la vie, il est possible de connecter les topics à des systèmes externes, comme des bases de données ou des index, grâce à l’outil Kafka Connect. Pour cela, on utilise des connecteurs adaptés à la base visée. Il existe deux types de connecteurs :
- source : les données sont extraites d’une base et envoyées dans des topics Kafka
- sink : les messages sont lus dans les topics Kafka et envoyés vers la base cible
Certains connecteurs sont open source, d’autres sont proposés par Confluent.
Les principaux cas d’usage de Kafka
Nous allons maintenant vous présenter les grands cas d’utilisation de Kafka, , à adapter selon vos besoins.
Temporisation et tolérance aux pannes
Kafka est capable d’ingérer des messages à très grande vitesse, là où des systèmes de stockage plus classiques ont du mal à supporter la charge et à indexer les logs au fur et à mesure. Placer Kafka devant un système de stockage ou de traitement permet de temporiser l’arrivée des données. On s’assure ainsi que le système de réception ne soit pas sous tension et qu’il puisse lire les données à son rythme grâce à ses propres consumers.
De plus, aucune donnée n’est perdue lors d’une interruption de service : si le système consommateur vient à redémarrer, il peut reprendre la lecture des données sur Kafka là où il s’était arrêté.
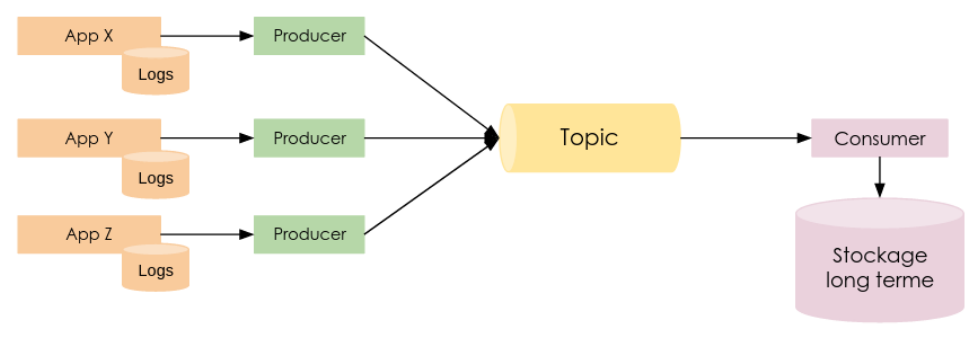
Agrégation de logs
Lorsque plusieurs applications produisent de grands volumes de logs, il est parfois nécessaire de les agréger dans un système avant de les traiter. Kafka peut servir de buffer pour la collecte des logs à plus ou moins long terme avant qu’ils soient transférés vers un système de stockage plus durable.
Change Data Capture (CDC)
Le Change Data Capture consiste à répliquer une base de données en capturant toutes les modifications apportées à cette base et en les appliquant à la copie. Cette architecture est en général utilisée lorsqu’on veut mettre en place de nouveaux traitements sur les données ou bien déplacer une base dans un nouvel environnement, le tout sans toucher à la prod. Kafka étant une file de messages, il se prête particulièrement au stockage des changements dans un ordre précis.
Comme vu précédemment, Kafka met à disposition des connecteurs, qui permettent de répliquer automatiquement des données d’une base à une autre. Par exemple, imaginons un connecteur qui extrait des données depuis une base relationnelle pour les envoyer dans un topic Kafka, puis un autre connecteur qui transfère ces données depuis Kafka vers une base dans le cloud. L’état de notre base relationnelle est donc répliqué à l’identique. Une fois les connecteurs mis en place, toutes ces données sont copiées automatiquement lors de leur création et de leur modification, sans aucune intervention humaine.
Des connecteurs existent pour un très grand nombre de bases, mais il est toujours possible de développer son propre connecteur si besoin.

Complex Event Processing (CEP)
Le cas d’usage suivant correspond au calcul et traitement de messages à la volée. Il permet de croiser et analyser les données provenant de plusieurs sources d'événements en temps réel. Ainsi, les événements ne sont pas traités tant que tous les flux attendus n’ont pas été reçus.
Il est par exemple utilisé dans le cadre de la détection de fraude, du marketing ciblé en temps réel, ou encore pour analyser les données collectées par des objets connectés.
Prenons l’exemple d’une montre connectée : si un capteur détecte une augmentation du rythme cardiaque et que le gps observe un déplacement, cela peut signifier que le porteur de la montre est en train de courir. Pour arriver à cette conclusion, il a fallu croiser les 2 streams de données et en extraire un résultat.
Ainsi, on transforme des flux d'événements séparés en informations exploitables qui peuvent servir à prendre des décisions.
Kafka est adapté à ce type de cas d’usage car il permet à chaque service CEP de lire des topics contenant des streams d’évènements et de publier ses résultats dans un topic séparé. Les traitements ne seront pas lancés tant que toutes les données des topics attendus n’ont pas été reçues. L’API Streams de Kafka facilite toutes les manipulations de données et il est possible de se connecter à tous types de bases pour extraire ou stocker des données.
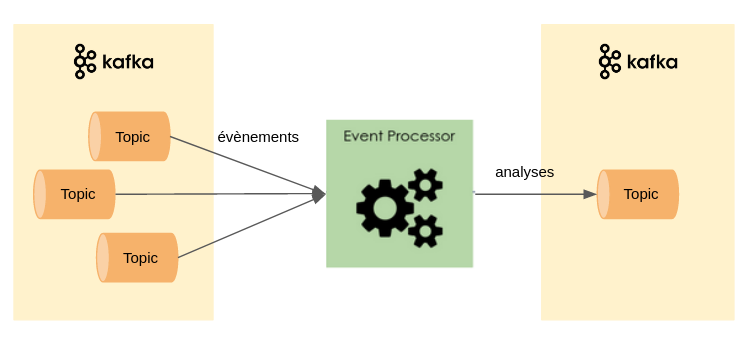
Il est également possible de créer des pipelines d’intégration de données plus complexes avec Kafka, constitués d’un enchaînement de traitements qui extraient leurs données d’un topic et envoient leurs résultats dans un autre topic. Chaque étape joue donc le rôle de consumer et de producer à la fois.
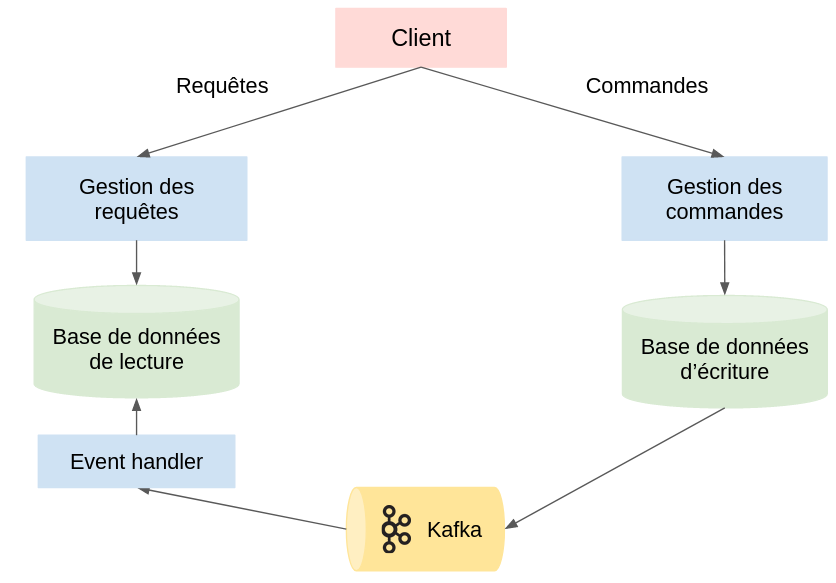
Command Query Responsibility Segregation (CQRS)
Il est possible de découpler la lecture et l’écriture au sein d’une application grâce au pattern CQRS. L’application est alors séparée en deux parties : celle qui met à jour les données et celle qui accède aux données. Les besoins entre ces deux parties peuvent être très différents : transaction, cohérence, normalisation pour l’écriture, et dénormalisation, scalabilité pour la lecture. En utilisant deux bases séparées ces deux parties peuvent alors être gérées par des équipes différentes, qui vont incorporer leurs modèles indépendamment.
On peut utiliser Kafka pour faire le lien entre ces deux parties : à chaque fois qu’un utilisateur met à jour des données, un événement est envoyé sur un topic Kafka. Un event handler consomme ensuite cet événement et le transforme afin de le stocker dans la base de données dédiée à la lecture. Cette base est alors requêtée pour afficher des données à l’utilisateur.
Ainsi, la base de données servant à la lecture peut être optimisée pour répondre aux requêtes de lecture sans se soucier de l’impact que cela pourrait avoir sur l’écriture des données, par exemple en utilisant un cache ou des index, et inversement.
Mais attention, ce pattern peut ajouter de la complexité non nécessaire à votre système.
Tous les cas d’usage que vous venez de voir peuvent exister côte à côte sur un cluster Kafka en interagissant avec des topics communs afin d’échanger des données. Le nombre de topics n’est pas limité au sein d’un cluster.
Les contraintes de Kafka
Kafka présente de nombreux avantages, mais ne convient pas à toutes les situations. Pour pouvoir l’utiliser, il faudra faire des choix en fonction de vos besoins.
Comment gérer l’ordre des messages ?
Afin de pouvoir distribuer les données, les topics sont divisés en plusieurs partitions. L’ordre des messages ne peut pas être garanti dans un topic, mais il l’est au sein d’une partition.
Pour comprendre pourquoi, il faut comprendre comment les messages sont consommés.
Les consumers sont en général regroupés dans des consumers groups. Les consumers d’un même consumer group vont consommer les mêmes topics. Pour ne pas lire plusieurs fois les mêmes messages, ces consumers se répartissent les partitions : chaque partition ne sera lue que par un seul consumer d’un même consumer group.
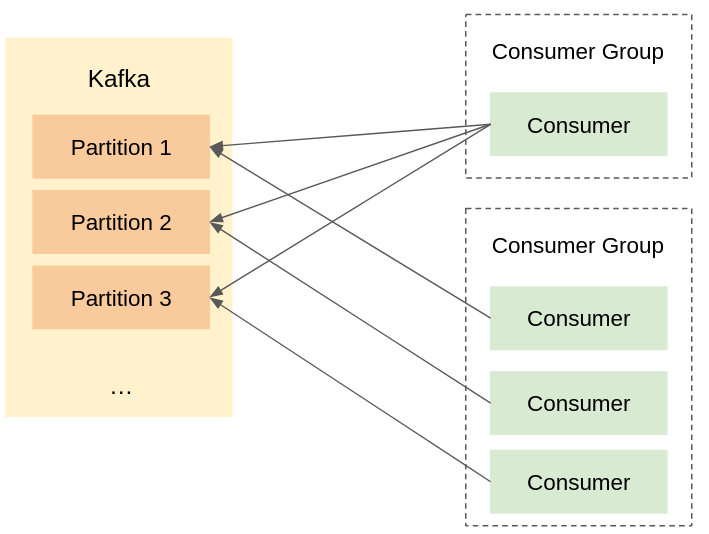
Les consumers lisent les messages à des vitesses différentes. Ainsi, si deux consumers lisent les données de deux partitions et que le deuxième consumer est plus rapide ou reçoit moins de messages, alors les messages de la seconde partition seront lus avant ceux de la première, même s’ils ont été produits dans l’ordre inverse.
Même si l’on envoie les messages sur un topic dans un certain ordre, ils n’est pas garanti qu’ils soient lus dans cet ordre. Par contre, au sein d’une partition, le consumer lit les messages les uns après les autres, donc l’ordre est toujours respecté.
Il faut donc regrouper les messages pour lesquels l’ordre est important dans la même partition. Pour cela, on utilise la clé du message : les messages avec la même clé iront sur une même partition, donc on peut s’assurer que ces messages seront lus dans l’ordre dans lequel ils ont été reçus par Kafka. Mais si vous ne précisez pas de clé pour vos messages, ils seront répartis sur des partitions différentes.
Enfin, il faut faire attention au nombre de producers : si plusieurs producers envoient des messages avec les mêmes clés, l’ordre ne sera pas nécessairement celui attendu car on ne peut pas prévoir quel producer enverra ses messages en premier.
Une scalabilité limitée par le nombre de partitions
Un des rôles du producer est de décider sur quelle partition va chaque message.
Pour cela, il regarde la clé du message, qui peut être nulle. Il envoie ensuite tous les messages avec la même clé sur la même partition d’un topic.
Ainsi, au moment de choisir le nombre de partitions d’un topic, il faut prendre en compte les différentes valeurs possibles de clés des messages. Il est inutile de configurer 10 partitions dans un topic si les messages ne peuvent prendre que 5 clés différentes : 5 partitions suffiront.
Il faut également prendre en compte le nombre de consumers que vous voudrez mettre dans vos consumers groups : si vous avez prévu de mettre 10 consumers, vous n’avez pas d'intérêt à mettre moins de 10 partitions car alors certains de vos consumers n’auront pas de partition assignée.
Enfin, il vaut mieux créer un nouveau topic que rajouter des partitions sur un topic. En ajoutant de nouvelles partitions, la répartition des clés sur les partitions du topic est modifiée automatiquement par Kafka. Cependant, les messages déjà dans les topics ne sont pas déplacés, ce qui signifie que des messages avec la même clé peuvent alors se retrouver sur des partitions différentes. Si l’ordre des messages est important et que vous utilisez des clés, il vaut donc mieux éviter de modifier le nombre de partitions après la création des topics.
Performance vs. résilience
Les données stockées dans les topics Kafka sont répliquées plusieurs fois sur un cluster. Chacune de ces réplications est appelée réplica. L’objectif est de ne perdre aucun message si l’une des machines Kafka venait à s’arrêter : plus les données sont répliquées, moins elles risquent de disparaître.
Attention, rajouter des réplicas peut augmenter la latence du système. En effet, il est possible de configurer le cluster pour que les messages ne soient considérés comme reçus que si toutes les réplicas synchrones, c’est-à-dire les réplicas qui sont à jour par rapport à la partition d’origine, les ont bien reçus. Cela permet de s’assurer qu’aucun message n’a été perdu. Dans ce cas, le temps de réponse du cluster lors de l’envoi d’un message va être proportionnel au nombre de réplicas qu’on a configurées.
Avoir plus de partitions prendra également plus d’espace disque sur vos machines.
Ce sont les producers qui doivent s’assurer que les messages ont bien été reçus par Kafka. Pour améliorer les performances, on peut donc jouer avec les paramètres de configuration des producers : idempotence (un message envoyé plusieurs fois sur le cluster Kafka ne sera pas dupliqué), max in flight requests (nombre maximal de messages différents envoyés en même temps), …
Combien de replicas choisir pour mon topic?
En général, on considère qu’un facteur de réplication de 3 est suffisant pour un environnement de production, mais il faut prendre en compte l’emplacement de ces réplicas. Si vous les placez toutes sur le même datacenter, alors vous n’êtes pas à l'abri de perdre des données en cas de crash du datacenter. Placez-les dans des datacenters / availability zones différents pour plus de sécurité.
Exactly Once
Kafka garantit l'”exactly once” à l'écriture, et “at least once” à la lecture. Cela signifie qu’on peut paramétrer Kafka pour s’assurer que chaque message sera produit une seule fois dans le topic visé, mais Kafka ne peut pas garantir qu’un message sera lu une seule fois par un consumer. Par contre, il garantit que chaque message sera lu au moins une fois.
Pourquoi Kafka ne peut pas assurer l’exactly once à la lecture ?
Pour savoir quels messages ont été lus par chaque consumer, Kafka sauvegarde leur offset, qui est le numéro du dernier message lu. Chaque consumer est responsable d’envoyer son offset aux machines Kakfa, on appelle cela un “commit”. Ainsi, si un consumer lit un message, le traite et rencontre une erreur avant d’avoir pu faire de commit, Kafka lui renverra le même message la prochaine fois qu’il lira le topic. Ce comportement pose donc problème si on a besoin que chaque message soit lu et traité une seule fois.
Cependant, en utilisant d’autres systèmes externes à Kafka, on peut faire en sorte que chaque message ne soit traité qu’une seule fois. Plusieurs possibilités s’offrent à vous :
- S’assurer que le traitement du message par les consumers est idempotent. De cette façon, même s’il est lu plusieurs fois cela n’aura aucune conséquence.
- S’aider d’une base de données relationnelle, par exemple en utilisant une transaction pour effectuer le commit d’offset et le traitement du message au même moment. On s’assure ainsi que si le commit n’a pas fonctionné, le message ne sera pas traité, et donc lorsque le message sera relu le traitement sera effectué pour la première fois.
- Écrire les messages dans une base de données de type clé-valeur. Les messages lus plusieurs fois auront la même clé et seront réécrits sous cette clé.
Conclusion
Vous avez maintenant un grand nombre d’informations nécessaires pour prendre votre décision.
Alors, Kafka répond-il à votre besoin ?
Pour plus d’informations sur le fonctionnement interne de Kafka, jetez un oeil à l’article Kafka 101 de Ata Lassey.
Pour creuser les patterns d’architecture, allez voir les articles des nos confrères :
- CQRS
- Complex Event Processing
Enfin, je tiens à remercier Cédric Martin, avec qui j’ai commencé la réflexion autour de cet article.