J’ai testé pour vous : PigUnit

Pourquoi tester Pig ?
J’ai cherché un outil de test sur Pig afin de :
- Gagner du temps dans mon développement. En effet, Pig demande de la patience, beaucoup de patience pour au final se trouver bien souvent avec une NullPointerException, ce qui ne facilite pas le debug (même en environnement local).
- Ne pas faire de régression. On peut en produire rapidement, à partir du moment où l’on commence à travailler à plusieurs sur les scripts, ou tout simplement avec les évolutions qui arrivent. Le pire ? On s’en rend compte à la fin de l’exécution, c’est-à-dire 2 heures après…
- Etre rassuré au moment du commit, puis de la mise en production. Parce qu’au départ c’était un POC, mais comme le script marchait bien le client voulait le mettre en PROD.
- Développer en TDD (Test Driven Development). On aime beaucoup le mouvement Software Craftsmanship chez OCTO, on voulait donc apporter les outils et méthodes de qualité du code afin de professionnaliser nos développements Pig.
- Automatiser les tests, mesurer la performance sur des datasets hébergés sur notre usine de développement. Avec Hadoop, la notion de performance revient au-devant de la scène et il est intéressant d’avoir des métriques sur l’exécution, connaitre le hash du commit qui a tué les perfs du script.
La théorie
PigUnit est un framework de test comme on peut en trouver sur la plupart des plateformes de programmation. Malgré le fait que la peinture ne soit pas sèche, il est possible grâce à celui-ci de commencer à industrialiser nos développements Pig. J’insiste sur le mot « commencer » car il résoudra certaines problématiques, alors que d’autres resteront sans solution, pour l’instant du moins…
Le Framework se présente sous la forme xUnit (à la manière de JUnit pour la plateforme Java) et s’intègre donc bien avec les IDE des java-istes (Eclipse, IntelliJ, Netbeans). Les tests unitaires sont écrits en langage Java à l’aide du Framework JUnit (fonctionne aussi avec TestNG), c’est-à-dire une classe annotée dans laquelle on écrira notre code de test.
Note : Par défaut PigUnit ignore les instructions store du script Pig. Le job Pig ne sera jamais lancé.
Mise en pratique
J’ai pris l’exemple d’un fichier contenant une liste de mots ; un par ligne sur lequel je procède à un simple ORDER BY en Pig, qui aura pour effet d’ordonner alphabétiquement ma liste de mots.
Pour suivre le déroulement, j’ai créé un petit projet sur GitHub qui possède trois scripts Pig et trois classes Java de test : https://github.com/BenJoyenConseil/pig-unit
![]()
Récupérer automatiquement les dépendances
Pour cette expérience, j’ai choisi maven comme outil de management des dépendances. Maven est un outil largement supporté par la communauté Java. Il bénéficie d’un repository central contenant un catalogue conséquent de bibliothèques dans lequel il existe désormais un artefact pour PigUnit (chance !!).
A la racine du projet, il faut un pom.xml contenant les bonnes dépendances. Ce fût laborieux pour la version 0.12.1 de Pig car la documentation n’est pas du tout complète, donc je voulais l’écrire quelque part afin de ne pas oublier :
Dépendances Maven
| groupId | artifactId | Scope | version |
| org.apache.pig | pigunit | Compile | 0.12.1 |
| org.apache.hadoop | hadoop-core | Test | 0.20.2 |
| jline | jline | Test | 0.9.94 |
| joda-time | joda-time | Test | 2.3 |
Testé avec
| jdk | 1.7.0_60 |
| maven | 3.2.1 |
| cygwin (sur Windows) | 1.7.30 |
Attention : Sous Windows, il faudra une installation basique de cygwin à ajouter dans le PATH car le framework utilise des directives Unix pour écrire les fichiers temporaires d’Hadoop.
Structure projet
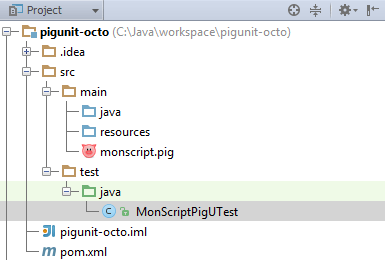
Une structure de projet classique se compose d’un dossier src dans lequel on trouve deux sous-dossiers :
- main qui contiendra les fichiers script.pig, voir potentiellement les UDF écrites en java.
- test qui contiendra un sous- dossier java contenant lui-même les classes Java de test des scripts. En option, ce dossier pourra contenir à la même hauteur que java un dossier resources dans lequel on retrouvera des données de test.
monscript.pig
Une ligne pour charger les données via le loader de Pig, et une ligne pour les ordonnées par ordre alphabétique. La seule logique est donc dans la deuxième ligne. Ce script est volontairement simple pour nous concentrer sur l’aspect test :
data = LOAD 'input' AS (name:chararray);
data_ordered = ORDER data BY name;
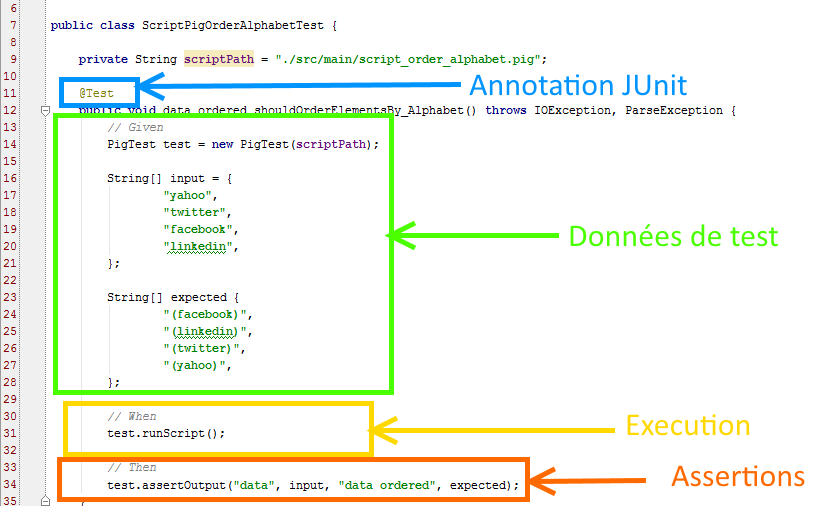
Dans mon dossier de test, il existe une classe nommée ScriptPigOrderAlphabetTest.java annotée. Je crée une méthode de test que je nommerais data_ordered_shouldOrderElementsBy_Alphabet() qui définit le comportement voulue de ma deuxième ligne de script.
Mock
PigUnit permet de remplacer (mocker) un alias particulier dans un script, par des données fournies de deux manières différentes.
- La première manière consiste à fournir de la donnée sous forme de tableau de String dans le code Java du test (exemple ci-dessous).
String[] input = {
"yahoo",
"twitter",
"facebook",
"linkedin",
};
test.assertOutput("data", input, "data_ordered", expected);
- La deuxième manière consiste à donner un fichier de ressources externe dans lequel est décrit le dataset (un csv par exemple).
PigTest.getCluster().update(new Path("test/data/pigunit/top_queries_input_data.txt"), new Path("top_queries_input_data.txt"));
Ce système de mock offre une grande souplesse ; on privilégiera de mocker les alias de nos scripts et de tester unitairement chaque expression Pig, une par une, dans des méthodes associant l’input et l’assertion. Tandis qu’un test d’intégration récupérant des données beaucoup plus conséquentes dans un fichier externe, testera de son côté toute la chaîne de traitement.
Comment ça se présente dans MonScriptPigUTest.java
public class ScriptPigOrderAlphabetTest {
private String scriptPath = "./src/main/monscript.pig";
@Test
public void data_ordered_shouldOrderElementsBy_Alphabet() throws IOException, ParseException {
// Given
PigTest test = new PigTest(scriptPath);
String[] input = {
"yahoo",
"twitter",
"facebook",
"linkedin",
};
// Then
test.assertOutput("data", input
}
}
Vous pouvez constater que le mock est fournie à la méthode assertOutput() afin de lui expliciter ce que nous voulons mocker, c’est-à-dire l’alias data qui contient le résultat du chargement de la donnée par le Loader Pig. On remarque qu’un seul alias ne peut pas être mocker.
On aurait aimé…
L’écosystème Java possède déjà un grand nombre de frameworks de mock bien aboutis (EasyMock, Mockito). Au final, PigUnit ne nous permet seulement de "mocker" la donnée d'entrée.
En regardant les sources je m'aperçois que PigUnit instancie un objet PigServer et copie la donnée que nous lui spécifions dans HDFS (si vous êtes en mode local, il utilisera le File System local. L'instance de PigServer se connecte à une instance de Pig, transforme le script en byte code Java, l'exécute et récupère l'ouput.
Il y a donc quelque chose qui me dérange : le fait que PigUnit se connecte à une instance de Pig et écrive sur le File System. Malgré son nom, PigUnit n'est pas un framework de test unitaire car il semble beaucoup trop dépendant de l’environnement sur lequel il s’exécute et donc que les tests soient agnostiques.
Assertion
Les assertions sont gérées directement à l'intérieur du framework. Via la méthode "assertOuput". PigUnit exécute notre code et procède à la comparaison du résultat avec l’expected.
assertOuput() prend donc en paramètre un alias sur lequel faire l’assertion puis un tableau de String en "expected" ou un fichier (objet de type java.io.File) contenant l’ouput espéré.
L'assertion qui sera utilisée par le framework est de type "equalTo" c'est-à-dire que la ligne d'indice 1 du résultat devra être équivalente au sens String.equalTo() à la ligne d'indice 1 de l'expected.
Comment ça se présente dans MonScriptPigUTest.java
Je choisis de mettre directement l’expected dans mon test :
String[] expected = {
"(facebook)",
"(linkedin)",
"(twitter)",
"(yahoo)",
};
// When
test.runScript();
// Then
test.assertOutput("data", input, "data_ordered", expected);
On aurait aimé
Les assertions sont assez limitées sur PigUnit. Comme la partie mock, j'aimerais pouvoir développer avec un framework conçu pour (ex : Hamcrest, AssertJ). La seule assertion possible est un "equalTo", ce qui nous oblige à tordre le test (=modifier le tableau de string en expected) quand on est confronté à un autre cas d'utilisation que un assert.Equal().
MRUnit, le framwork de test unitaire de MapReduce ressemble à PigUnit, mais à la différence il est possible de récupérer l'output brut de l'exécution afin de gérer les assertions comme on le souhaite.
Les UDF (User Defined Fonction)
Pour la question des UDF, je vous conseille de ne pas les tester avec PigUnit, mais directement en Java ou en Python puisqu’on les écrit dans ces langages, sur la méthode « exec » car cela vous permettra d’accéder à tout l’écosystème de test de la plateforme :
Code
@Test
public void exec_shouldReturnFalse_WhenStr1ContainsStr2() throws Exception {
// Given
Tuple tuple = TupleFactory.getInstance().newTuple();
tuple.append("blick bluck block");
tuple.append("black");
// When
boolean result = new SimilarityFunc().exec(tuple);
// Then
assertThat(result, is(equalTo(false)));
}
Petits tips
Mode local ou mode MapReduce
Le mode local est le mode par défaut dans PigUnit, par contre, il est possible de lancer ses tests sur un cluster Hadoop afin de faire des tests d’intégration.
- Il faut d’abord que le répertoire de configuration d’Hadoop (HADOOP_CONF_DIR) soit dans le CLASSPATH lors de l’exécution.
- Ensuite, il faut spécifier un paramètre système Java (accessible en Java via System.getProperty()) :
-Dpigunit.exectype.cluster=true
Ou directement dans le code
System.getProperties().setProperty("pigunit.exectype.cluster", "true")
Mon script référence une bibliothèque externe d'UDF
Parfois (souvent), le cas d’utilisation de Pig est assez particulier pour nous obliger à utiliser des UDF contenues dans un jar externe. Comme pour le mock d’un alias par le biais d’un fichier externe, on va procéder à l’upload du fichier sur HDFS grâce à l’objet cluster et sa méthode update(), pour ensuite l’utiliser dans notre script.
Le script
REGISTER datafu.jar;
DEFINE Median datafu.pig.stats.StreamingMedian();
data = LOAD 'input' using PigStorage() as (val:int);
median = FOREACH (GROUP data ALL) GENERATE Median(data);
Le test qui upload avant le jar
public class ScriptWithUDFUTest {
private String scriptPath = "./src/main/script_with_udf.pig";
@Test
public void montest_avec_datafu() throws IOException, ParseException {
// Given
PigTest.getCluster().update(new Path("./datafu-1.2.0.jar"), new Path("datafu.jar"));
PigTest test = new PigTest(scriptPath);
String[] input = {"1", "2", "3", "2", "2", "2", "3", "2", "2", "1"};
String[] expected = {"((2.0))"};
// When
test.runScript();
// Then
test.assertOutput("data", input, "median", expected);
}
}
Notez que mon JAR est à la racine du projet : ./datafu-1.2.0.jar
Mettre en place un build automatique sur une UDD
Côté UDD, j’ai utilisé Jenkins. Je l’ai installé sur une machine Linux de type Ubuntu Server 14.04. Dessus, il y a l’openjdk7 d’installé, et Git pour récupérer le code source du projet GitHub. Jenkins est configuré avec une installation de maven 3.2.1 (comme ma version locale) ainsi que le Git Plugin.
Si vous cherchez comment installer Jenkins, jetez un œil du côté du Wiki officiel qui est très efficace.
J’ai utilisé l’interface d’administration pour créer un job de type « maven » qui se lance après chaque commit
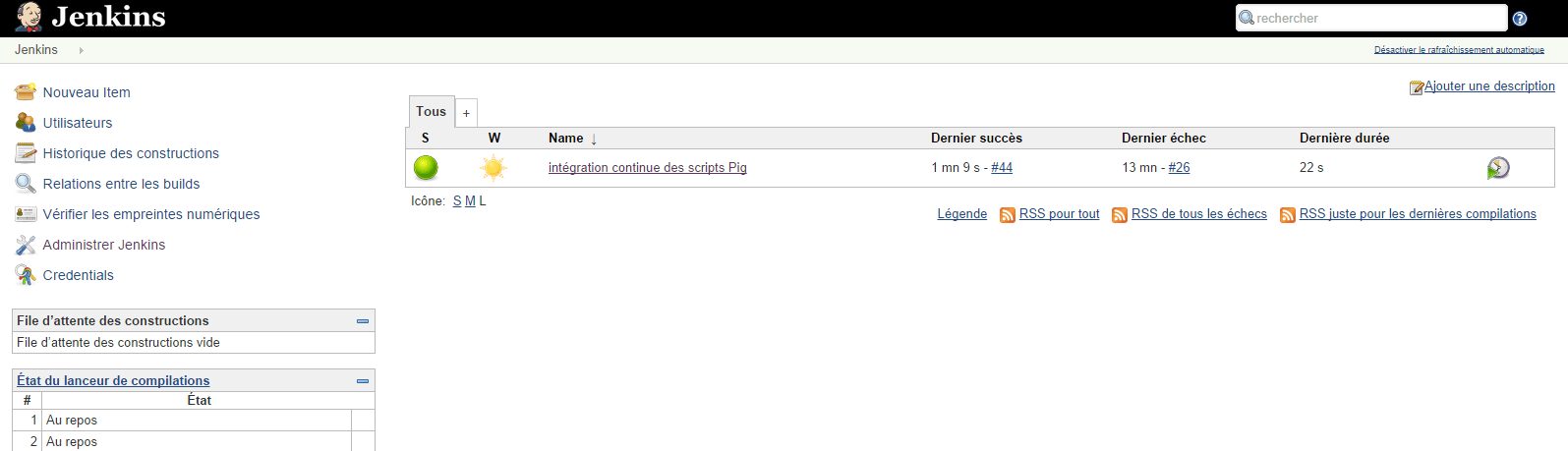
Vous pouvez spécifier que le job Jenkins se lance en local ou en mode mapreduce en ajoutant un paramètre de job de type booléen : -Dpigunit.exectype.cluster=true
Enfin, il est possible d'utiliser un autre plugin Jenkins (par exemple Global Build Stats) afin de suivre l'évolution du temps d'exécution, et repérer les évolutions qui tuent les perfs.
Pig en TDD
Les bonnes méthodes de développement c’est un sujet important chez nous, on a même une tribu dédiée à son évangélisation : Tribu Craftsmanship. Pour ceux qui seraient intéressés, voici comment j'ai procédé :
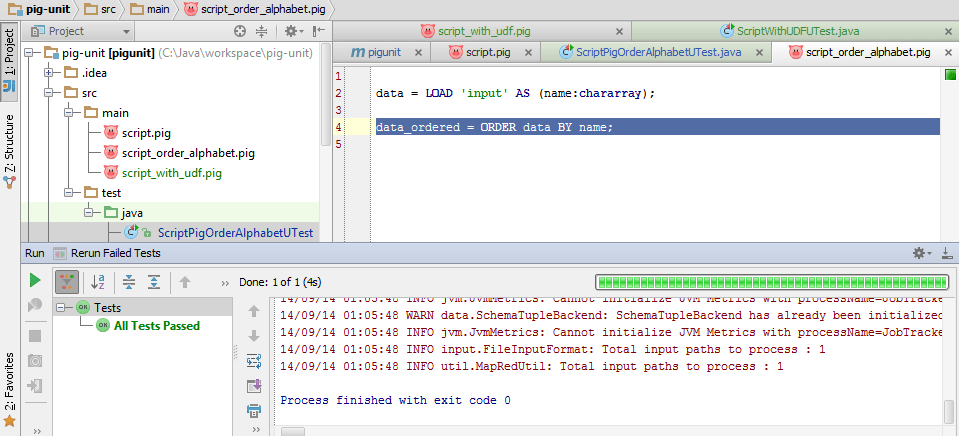
Sur script_order_alphabet.pig j’ai d’abord écrit le loader que je ne veux pas tester (ce qui reviendrait à tester le framework). Ensuite, mon premier traitement est en réalité un alias égal à un autre alias :
order_by_alphabeth = data;
J’ai écrit mon test en conséquence pour donner mon comportement, puis je l’ai exécuté dans mon IDE. Il était donc normalement rouge avec le diff suivant :

Mon comportement souhaité est un ordre alphabétique. Or, le premier élément se trouve être « yahoo ». La modification du code qui suit est donc très simple :
data_ordered = ORDER data BY name;
Issues avec PigUnit
On a eu des problèmes avec PigUnit, le produit n’est pas encore sec alors attendez-vous à avoir quelques surprises.
Nettoyer le cache
Si dans une classe de test il y a plusieurs méthodes de test (ce qui semble assez commun), il faut faire attention car il y aurait des effets de bord liés au fait que l’instance PigServer ne serait pas réinitialisée correctement :
http://www.millennialmedia.com/blog/2014/02/a-solution-to-lengthy-pigunit-tests/
Cygwin pour windows
Si vous avez un environnement de développement sous Windows et que Cygwin n’est pas installé ou n’est pas ajouté à la variable d’environnement PATH, une erreur de type « java.io.IOException: Cannot run program "chmod" » s’affichera.
ORDER BY en mapreduce
Avec mon Jenkins installé sur un cluster Hadoop, j’ai donc lancé mes builds en mode mapreduce afin de recréer un environnement d’exécution proche de la production. Mais voilà, dès qu’un script possédait au moins un ORDER BY, il plantait. Je n’ai pour l’heure pas réussi à résoudre ce problème plutôt gênant, mais il semblerait que ça provienne d’un problème de droit d’accès au fichier temporaire de sample utilisé par le TotalOrderPartitioner.
Maintenant que vous maîtrisez PigUnit j’espère que vous serez très bientôt tel Robert Redford, l’homme qui murmurait à l’oreille des cochons.

Récapitulatif
| Mocker facilement la donnée en spécifiant l’alias auquel se réfère le tableau de String qu’on donne.Le principe est simple et efficace. |  |
| Assertions : Le seul type d’assertion est « equalTo ». Non Intégration avec des frameworks spécialisés comme AssertJ ou Hamcrest. |  |
| La documentation digne d’un README Github (et encore il y en a des bien complets) et non d’un projet Apache. |  |
| L’intégration avec Maven/Gradle n’est pas du tout abordée dans la documentation et pourtant elle est maintenant « faisable ». Un plus quand il s’agit d’automatiser le build sur une UDD.Il est aussi possible de lancer les tests en mode « cluster » (par défaut en « local), ce que je n’ai pas pu tester malheureusement | |
En conclusion, PigUnit se situe sur un rapport Simplicité / Puissance très proche de la simplicité, mais il n’est pas encore assez flexible et puissant pour couvrir un workflow complexe. Il s’appuie sur JUnit ou TestNG mais ne permet pas l’utilisation de frameworks de mock ou d’assertion, ce qui limite les choses.
Malgré tout, entre mon environnement d’avant et d’après PigUnit, il n’y a pas photo : je suis bien plus performant (et heureux ?) avec et il a justifié les deux jours de veille que je lui avais réservé. Je dirais donc que c’est un bon début. Le temps d’exécution est acceptable (environ 10 secondes par test) en comparaison d’avant (un script mettait 2-3 minutes à s’exécuter).
Si vous vous demandez « est-ce que je pars là-dessus » je vous répondrais que ce n’est pas encore sec et donc qu’il faut s’attendre à quelques surprises. Mais c’est déjà suffisant pour « agilifier » son développement Pig.
| Note finale / 5 |  |
Comme ouverture, je vous invite à regarder le projet Nifty Pig Unit sur GitHub que je n’ai pas encore eu la chance de tester. Il promet d'ajouter la possibilité d'avoir plusieurs inputs pour un test, ajouter un système d'assertion beaucoup plus complet (respectant l'ordre, avec field validator, et personnalisation), et autorise l'utilisation de dump pour le debug. A surveiller !
Références :
- La page Apache du projet PigUnit.
- La page confluence des outils Pig
- Better, Faster and Simpler Pig Development Using PigUnit, de Sanjay Yermalkar
- Pig-Maven une intégration de PigUnit avec Maven, référençant les snapshots du repo Cloudera
- Exemples de tests avec PigUnit
- Comment écrire et tester un CustomLoader Pig
- MapReduce testing with PigUnit and JUnit d’Orzen Gulan
- Un tutoriel complet sur slideshare (attention : pas à jour)
- PigUnit sur NodeJS : npm
- Le code source sur GitHub
- Nifty PigUnit
- IMDB : L’homme qui murmurait à l’oreille des chevaux