Introduction to Datastax Brisk : an Hadoop and Cassandra distribution
As the Apache Hadoop ecosystem grows while its core matures, there are now several companies providing business-class Hadoop distribution and services. While EMC, after it acquires Greenplum, seem the biggest player other companies such as Cloudera or MapR are also competing.
This article introduces Datastax Brisk, an innovative Hadoop distribution that leverage Apache Hive data warehouse infrastructure on top of an HDFS-compatible storage layer, based on Cassandra. Brisk try to reconcile real-time applications with low-latency requirement (OLTP) and big data analytics (OLAP) in one system. "Oh really ?"
Introduction
Usually systems designed for OLAP and OLTP require different data models and OLTP systems need to be regularly offloaded because they don't cope with huge amount of data. Thus the need for ETL. But ETL processes are usually complex and not flexible, they have to be adapted each time the source or destination system slightly change. Lastly they are not well-suited for small but numerous datastreams, which is where we are heading with real time analytics.
If you were to design a unique system that could handle both low-latency queries and big data analytics you would need some kind of resources isolation so that a big batch running on your data doesn't impact the response time of your application. Let's see how Brisk handle these challenges.
Brisk Architecture
In the typical Hadoop Stack (see our related blog posts), the primary datastore is Hadoop Distributed FileSystem, aka HDFS. HDFS fits well MapReduce jobs thanks to data locality awareness but this comes at the expense of a major SPOF, the NameNode metadata server. Although the secondary NameNode server mitigates data loss risk, the failover time is in dozens of minutes.
With Brisk, the HDFS layer is replaced by a Cassandra-based filesystem. Similar to HDFS, large files are split in chunks (more precisely, in "rows") but stored in a column family. Data replication and consistency tradeoff are handled as in every column family in Cassandra. Locality awareness comes "for free", each data chunk has a key mapped in Cassandra's Distributed Hash Table : every node of the cluster knows where each piece of data is located. What's great with CassandraFS is it transparently replaces HDFS, whether you access HDFS through the native Java API or through the CLI, you don't have to change your existing code.
A typical Brisk cluster is comprised of two types of nodes. Some nodes are dedicated to do analytics while others only deal with low-latency queries. Both types of nodes run Cassandra but analytics nodes also run an Hadoop TaskTracker to execute long-running MapReduce programs. Cassandra-only nodes operate solely as a NoSQL datastore. Hadoop nodes and Cassandra-only nodes make two different groups inside the same Brisk cluster. If you are not familiar with Cassandra datamodel and its OLTP capabilities, now is the time to have a look at the "Play with Cassandra" blog posts series.
Data stored in the CassandraFS is actually stored in a keyspace handled only by Hadoop nodes. There is a JobTracker node, automatically elected among Hadoop nodes, which try to schedule job on TaskTrackers so that they work only with local data. If the JobTracker fails, you can manually force another Hadoop node to be the new JobTracker.
Things get a bit more complicated when you want to run MapReduce jobs on data stored in a regular keyspace. Part of the data could be assigned to vanilla Cassandra (remember that cassandra-only nodes and Hadoop nodes belong to the same "ring"/cluster). Possibly, tons of data need to be read (for analytics purpose) from nodes also facing real time requirements.
Brisk provides an elegant solution to the resource isolation problem thanks to Cassandra native replication ability. The trick is to :
- Replicate the keyspace so that the Hadoop nodes group owns a full copy of the data stored in the keyspace.
- Tell the Hadoop nodes to read data using only the copy and thus avoiding to hit the cassandra-only nodes.
In the end, the architecture looks like :
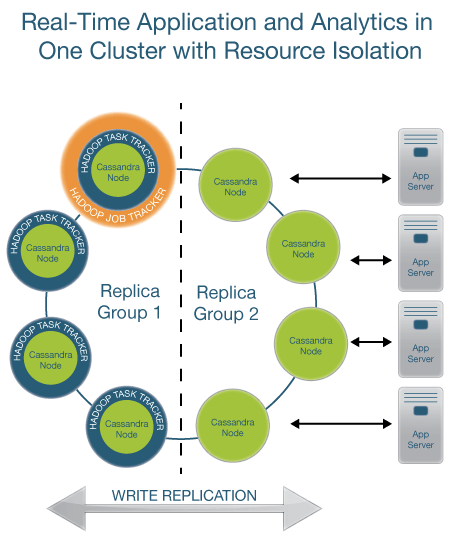
Details on write replication
A keyspace with these two properties (replication and "in your group"/local queries) can be created through cassandra-cli :
create keyspace myKS with placement_strategy='org.apache.cassandra.locator.NetworkTopologyStrategy' and strategy_options=[{Brisk:1, Cassandra:1}];
That's it. In this example the replication factor has been set to 2 (1+1) : one full copy of the data lays on each nodes group. The placement strategy tells the data routing mechanism to satisfy the consistency level of the request (read or write) favoring nodes “close” to the request issuer. In Brisk, when a node joins the cluster it will automatically declare itself as part of the “Brisk” virtual DC or Cassandra virtual DC depending on its role (OLAP or OLTP, role is configurable in /etc/init.d/cassandra or /etc/default/brisk file). That's why Cassandra-only nodes are concidered far-away (in another DC) from Hadoop nodes, thus Hadoop nodes avoid reading data from them. Long story short, replication, virtualDC and “network topology aware” strategy achieve the resource isolation property.
Likewise, if your MR job writes its results in a column family of the myKS keyspace, these results will eventually (as in eventually consistent, depending of your write consistency level) be copied on the Cassandra-only nodes group. Dont write too much data or the replication process could adversely impact the response time of your Cassandra-only nodes.
With Brisk, you program your MapReduce jobs as you would with a typical Hadoop stack. Unfortunately Hadoop streaming is not supported so you are left with no choice but Java.
Example of Mapreduce on Cassandra
In the following paragraphs I will go through the canonical WordCount example, but the input "text corpus" is stored in a regular Cassandra keyspace (instead of CassandraFS or HDFS) and the result will also be put back in Cassandra.
First thing first, we need a new keyspace and column family to store our text corpus. We also need a column family to store the output of the MR job. In the cassandra-cli (be sure Brisk was started with "Hadoop enabled") :
create keyspace wordcount with strategy_options=[{Brisk:1, Cassandra:0}];
use wordcount;
create column family input_words with comparator = AsciiType and default_validation_class = AsciiType;
create column family output_words with comparator = AsciiType and default_validation_class = AsciiType;
This keyspace will be stored only on the Hadoop nodes of the cluster, this is the meaning of the "strategy_options" parameter. None of the operations to come will involve Cassandra-only nodes. Next, we need some input texts. I chose the Bible (old and new testaments) because it's quite big and available in text format here. https://sites.google.com/site/ruwach/bibletext Get it and unzip it. The following python code snippet inserts each line of the Bible as a row in the input_words column family.
import sys,pycassa
from string import strip
pool = pycassa.connect('wordcount', ['localhost:9160'])
cf = pycassa.ColumnFamily(pool, 'input_words')
b = cf.batch(queue_size=100)
i = 0
for line in sys.stdin:
i += 1
b.insert('line'+str(i), {'bible' : strip(line)})
We execute it and insert the data :
find . -type f -name "*.txt" -print0 | xargs -0 cat | sed "s/^[0-9 ]*//" | python myscript.py
The MR program is available here : github repo It's the classical "wordcount" example. The following lines are specific to Brisk and are put in the run method of the job, where the job setup is done :
// Tell the Mapper to expect Cassandra columns as input
job.setInputFormatClass(ColumnFamilyInputFormat.class);
job.setOutputFormatClass(ColumnFamilyOutputFormat.class);
// Set the keyspace and column family for the output of this job
ConfigHelper.setOutputColumnFamily(job.getConfiguration(), "wordcount", "output_words");
ConfigHelper.setInputColumnFamily(job.getConfiguration(), "wordcount", "input_words");
// Set the predicate that determines what columns will be selected from each row
SlicePredicate predicate = new SlicePredicate().setColumn_names(Arrays.asList(ByteBufferUtil.bytes("bible")));
// The "get_slice" (see Cassandra's API) operation will be applied on each row of the ColumnFamily.
// Each row will be handled by one Map job.
ConfigHelper.setInputSlicePredicate(job.getConfiguration(), predicate);
The code is compiled and run :
/bin/rm -rf WordCountCassandra_classes ; mkdir WordCountCassandra_classes
classpath=. && for jar in /usr/share/brisk/{cassandra,hadoop}/lib/*.jar; do classpath=$classpath:$jar done
javac -classpath $classpath -d WordCountCassandra_classes WordCountCassandra.java
jar -cvf /root/WordCountCassandra.jar -C WordCountCassandra_classes/ .
brisk hadoop jar /root/WordCountCassandra.jar WordCountCassandra
Hopefully the job ended well and you can now ask "how many times does the word "advantage" appear in the Bible" by retrieving the column named "advantage" from the "bible" row of the "output_words" column family :
Welcome to the Cassandra CLI.
Type 'help;' or '?' for help.
Type 'quit;' or 'exit;' to quit.
[default@unknown] use wordcount;
[default@wordcount] get output_words[ascii('bible')]['advantage'];
=> (column=advantage, value=15, timestamp=1308734369159)
A more realistic example would have been to do analytics on evolving data (such as tweet feeds) stored in a column family updated by a "real time" application (such as a tweeter client) and output the results in another column family (preferably in another "keyspace", for ressource isolation reason). This way, you could do analytics on the latest data and let the results of the MR job be accessible to your application immediatly after they are available.
Apache Hive in Brisk
Brisk also includes Apache Hive, sligthly modified in order to work with CassandraFS. Hive provides a SQL-like syntax where queries are "translated" to MapReduce jobs. Hive really ease big data handling. Let's see how with the continuation of the WordCount example.
If the wordcount MR example went well, you now have an "output_words" Column family that looks like this :

With this schema it's easy to get the number of times the noun "aaron" appears in the Bible. But what if you want to know what is the most frequent word ? You would have to fetch all the columns, possibly write another MR job. Instead, we are going to use Hive which can response to this simple query in one line.
Hive integration in Brisk is straigthforward. The syntax is the same as Hive on top of HDFS, but in Brisk, the data is actually stored in CassandraFS. It gets (a bit) tricky when you want to map an existing Cassandra column family ("output_words" in our example) into a Hive table. Especially if the name and the number of columns are dynamic.
The following Hive-QL statement creates an Hive table whose data is stored in the Cassandra column family "output_words" and where each row is a 3-tuple [row key, column_name, column_value]. So, in this example, you end up with one row in the HiveTable for each distinct word in each text of the text corpus.
hive> CREATE DATABASE WordCountDB;
hive> CREATE EXTERNAL TABLE WordCountDB.output_words
(sourcetext string, word string, count int)
STORED BY 'org.apache.hadoop.hive.cassandra.CassandraStorageHandler'
WITH SERDEPROPERTIES ( "cassandra.columns.mapping" = ":key,:column,:value" )
TBLPROPERTIES ( "cassandra.ks.name" = "wordcount" );
hive> select * FROM WordCountDB.output_words limit 5;
OK
bible a 8638
bible aaron 323
bible aarons 29
bible abaddon 4
bible abagtha 1
Time taken: 0.549 seconds
Finally, to get the 5 most frequent words in the bible the Hive query looks like :
hive> select word, count FROM WordCountDB.output_words WHERE sourcetext='bible' AND length(word) > 3 ORDER BY count DESC limit 5;
OK
against 1591
also 1513
away 1020
after 959
among 881
Time taken: 34.671 seconds
Not bad hu ?
Conclusion
Brisk is more than just another Hadoop distribution. It has innovative features such as a distributed filesystem on top of Cassandra which act as a unique datastore for both low-latency queries and offline batch processing. It reduces the time between data creation and analysis thanks to “on the fly” data replication which suppress the need for ETL. It's a Free OpenSource Software and benefit from professional support by Datastax.