Introduction aux bases de données temporelles
De nos jours, la donnée est omniprésente. Le but est de savoir comment la valoriser, et pour cela, le stockage de celle-ci est une problématique majeure dans de nombreux projets informatiques. De nombreuses bases de données de différents types existent et répondent chacune à des besoins bien précis. Nous pouvons citer les bases de données relationnelles comme MySQL optimisées pour le stockage de lignes de données, les bases de données orientées colonnes comme MariaDB ou Cassandra, optimisées pour les extractions rapides de colonnes de données, ou encore les bases de données documents comme MongoDB permettant de stocker la donnée sous forme de document, la plupart du temps sous format XML ou JSON.
Dans cet article, nous nous concentrerons sur les bases de données Timeseries, permettant de stocker et requêter des données temporelles.
Les TSDBs (TimeSeries Databases) ne sont pas nouvelles. Elles étaient tout d’abord utilisées pour stocker et gérer des données financières. Par la suite, l’IoT a grandement influencé leur utilisation. En effet, d’ici 2025, 80 zettaoctets de données seront générées par une utilisation courante d’environ 40 milliards d’objets munis de capteurs, récoltant de la donnée (smartphone, GPS, capteurs thermiques, terminal de paiements etc ...) d’après IDC (International Data Corporation). C’est dans ce contexte que l’utilisation des TSDBs prend tout son sens. Celles-ci ont été optimisées pour prendre en charge ces gros volumes de données.
Les TSDBs les plus populaires en 2020 sont les suivantes :
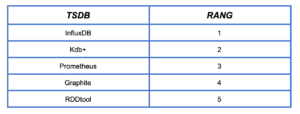
Classement effectué par le site DB-Engine qui se base sur le nombre de recherches sur le web, le nombre d’articles techniques à propos d’une base en particulier ainsi que d’autres critères
https://db-engines.com/en/ranking/time+series+dbms
Parmi les technologies cloud, nous pouvons retrouver AWS Timestream en beta, ou BigTable sur GCP, qui s’adaptent aux besoins des applications automatiquement en ajustant les capacités et les performances. De plus, BigTable peut s’intégrer avec des outils populaires tel Hadoop.
Durant mon stage chez OCTO j’ai été confronté à une problématique de stockage de la donnée nécessitant l’utilisation de ce genre de SGBD (Système de Gestion de Bases de Données). Ainsi cet article aura pour but de poser les bases des TSDBs et de partager ce que j’ai pu apprendre sur celles-ci.
I) Contexte
Dans le cadre de mon stage chez Octo, j’ai eu l’opportunité de travailler sur le projet Aura.
Aura est une association développant un projet open source ayant pour but de contribuer à l’amélioration du traitement des crises d’épilepsie. Elle vise à développer le premier outil connecté en santé permettant de détecter les signaux avant-coureurs des crises. Ce dispositif est fiable et discret. Cet outil accompagne les patients épileptiques tout au long de leurs journées. Une première étape consiste à récolter des données chez les patients afin d’entraîner un ensemble d’algorithmes de détection. Pour ceci, des capteurs connectés et adaptés à une utilisation quotidienne permettant de récolter ces données physiologiques sont portés par les patients.
Ces données récoltées via des capteurs IoT sont produites en grand nombre. Pour donner un bref aperçu, trois capteurs génèrent un total de 100 points de données par seconde pour une dizaine de patients. Après une journée de récolte, la totalité des données récoltées atteint approximativement trente millions de points de données. Plus précisément, les données récoltées sont transformés au format JSON, et 3 fichiers de cinq mille points de donnée sont créés. Après une journée de récolte, un total de 8,82 Go de données est amassé. Proportionnellement, sur une année, on atteint les 3,175 To de données. Mais ceci ne représente la donnée amassée que pour une dizaine de patient.
Une base de donnée temporelle a été choisie pour différentes raisons :
- Le nombre de données générées pour un test pilote de seulement une dizaine de patients.
- La nature de la donnée produite (donnée temporelle).
- L’analyse de cette donnée selon un axe de temps et la détection de motifs en fonction de la fenêtre de temps requêtée.
C’est dans ce cadre que j’ai été amené à produire un benchmark de deux TSDBs : InfluxDB, qui fut choisie car elle est leader du marché en version mono-noeud gratuite, et TimescaleDB, que je détaillerai dans un prochain paragraphe, et qui a la particularité d’être un module d’une base de données relationnelle : PostgreSQL.
II) Qu’est-ce qu’une donnée Timeseries
Les TSDBs ont pour but de stocker un certain type de données que l’on nommera données Timeseries ou données temporelles, qui dans un terme plus mathématique se nomment séries temporelles.
Un ensemble de données Timeseries est une séquence de données, aussi appelées points de données, ordonnées chronologiquement. Cet ensemble de données mesure la même entrée au cours du temps.
Il s’agit aussi d’un ensemble de mesures auxquelles on associe un timestamp (par exemple : ‘2020-03-17T12:00:00.000’). Ces points peuvent être composés de metadonnées.
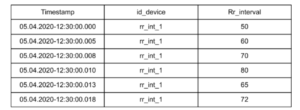
Exemple d’ensemble de mesures
Suivi de la variabilité cardiaque d’un patient au cours du temps
Qu’est-ce qui caractérise une donnée temporelle ?
L’ensemble de mesure n’est qu’une modélisation de la donnée récoltée, qui change en fonction de ce que l’on veut mesurer. Chaque ensemble de mesure présente un point commun : il possède, quel que soit le cas d’usage ainsi que l’entrée mesurée, un timestamp. Cependant, le nombre de métadonnées, les valeurs relevées ainsi que la fréquence de génération des points de données varient.
En reprenant l’exemple du projet Aura, le dispositif de récolte des données est composé de trois capteurs permettant de mesurer différents signaux:
- Gyromètre : mesure la vitesse des mouvements du patient selon les trois axes
- Accéléromètre : mesure l’accélération des mouvements du patient selon les trois axes
- Patch : mesure la durée entre deux pulsations cardiaques (variabilité du rythme cardiaque)
Ces données ne sont pas modélisées de la même manière. Cependant, elles présentent toutes un timestamp.
De plus, en comparant plus généralement deux ensembles de mesures provenant chacun de deux cas d’usage différents, le nombre de métadonnées ainsi que le nombre et le type de valeurs peut varier.
Il faut donc trouver un point commun entre toutes ces données temporelles.
Prenons la durée entre deux pulsations cardiaques ainsi que l’accélération selon les trois axes:
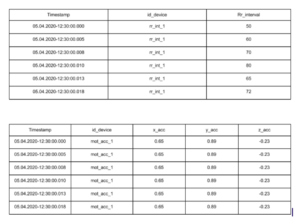
On remarque que :
- Les données sont enregistrées comme une nouvelle entrée.
- Les données sont générées dans l’ordre chronologique.
- La composante de temps représente une dimension principale de la donnée
Dans la grande majorité des cas, quel que soit le cas d’usage, la modification de la donnée se fait via des INSERTs et non des UPDATEs (append-only). Ces données arrivent de façon ordonnée dans le temps. De plus, la composante de temps est l’axe principal de chaque grandeur.
Pourquoi est-ce que, dans la majorité des cas, la donnée modifiée est enregistrée comme une nouvelle ligne et non comme une modification de la ligne en question ?
L’un des principaux objectifs des données temporelles est de suivre l’évolution et le changement de nos mesures.
Pour illustrer ceci, prenons un patient dont on mesure la variabilité du rythme cardiaque et considérons deux scénarios différents :
- Dans un premier temps, à chaque fois qu’une donnée est générée par le capteur, un UPDATE est effectué dans la table représentant la grandeur mesurée. Ceci implique un nombre de points de données bien moins conséquent que lors d’une politique insert-only. Mais comment avoir un suivi de l’évolution de cette variabilité du rythme cardiaque au cours du temps ?
- Dans un deuxième temps, à chaque fois qu’une donnée est générée par le capteur, un INSERT est effectué dans la base. Ceci implique un nombre de lignes beaucoup plus conséquent à stocker que dans le cas précédent, mais l’évolution de cette variabilité est possible en comparant les différentes lignes de données récoltées au cours du temps. Plus généralement, un monitoring des données est possible.
III) Pourquoi utiliser une Timeseries database ?
Il est possible d’utiliser d’autres types de bases de données afin de stocker et gérer des données temporelles. Cependant, les TSDBs étant conçues spécifiquement pour ce type de données, elles apportent des avantages que les autres bases de données n’ont pas.
1) Pour répondre à des besoins de scalabilité
Tout d’abord, la quantité de données à gérer lorsqu’il s’agit de données temporelles est la plupart du temps conséquente et implique généralement des coûts importants. La question de la scalabilité de notre base se pose. Nativement, les bases de données relationnelles sont difficilement scalables horizontalement. La stratégie adoptée pour gérer l’écriture de ces données temporelles dans une base (append-only) implique d’adapter la manière dont ces données sont stockées et indexées afin de répondre à des besoins spécifiques en écriture, en stockage et en lecture.
Les TSDBs sont optimisées pour gérer et stocker précisément des données temporelles. Ceci se traduit par de meilleures performances en injection de données, mais aussi en lecture. La stratégie adoptée pour améliorer les performances en écriture et en lecture dépend de la TSDB choisie.
Cependant, ces optimisations sont basées encore une fois sur le type de donnée et les avantages qu’il apporte (append-only et points de données classés par ordre chronologique).
2) Pour l’architecture mise en place
La problématique générale reste la même :
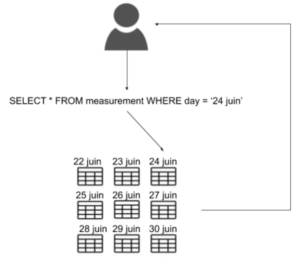
Quelle architecture mettre en place pour stocker la donnée afin que les requêtes en lecture sur un intervalle de temps donné soient rapidement exécutées ?
Les données relatives à une même fenêtre de temps doivent être facilement accessibles. L’architecture mise en place pour répondre à cette problématique varie d’une TSDB à une autre.
Pour donner un exemple, voici celle de TimescaleDB :
TimescaleDB est une base de données relationnelle open source permettant de stocker des données temporelles. Elle est un module de PostgreSQL (base de données relationnelle), optimisant cette dernière pour l’injection et les requêtes de données temporelles.
L’ajout d’une surcouche permet donc d’avoir accès à toutes les fonctionnalités de Postgres tout en pouvant utiliser des fonctions propres au traitement et à l’analyse de données temporelles ajoutées par TimescaleDB. De plus, TimescaleDB supporte le SQL standard qui est très répandu.
Les tables créées pour représenter la donnée sont respectivement associés à des Hypertables (https://docs.timescale.com/latest/using-timescaledb/hypertables).
Ces Hypertables sont des vues abstraites des tables précédemment créées.
Elles sont ensuite partitionnées en plusieurs “chunks” selon l’axe de temps et optionnellement une dimension (les dimensions sont équivalentes à des tags, terme utilisé par InfluxDB). C’est ici que l’utilisateur précise l’intervalle de temps de partitionnement (par exemple 1 jour, 1 mois, etc….) afin que la partition ne contienne que les données accumulées pendant cet intervalle. Au fur et à mesure que de la donnée sera injectée, de nouvelles partitions seront créées selon l’intervalle de temps choisi. L’utilisateur a la possibilité de préciser une dimension supplémentaire (autre que le timestamp) afin d’avoir un partitionnement plus fin (par exemple, pour des données récoltées via capteurs IoTs, l’id du capteur peut être une dimension).
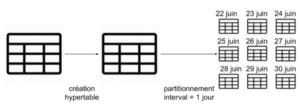
Ces partitions sont disjointes, ce qui permet de minimiser le nombre de partitions à interroger lorsqu’une requête est effectuée.
De plus, en adaptant la taille de l’intervalle de temps des partitions aux besoins de notre usecase, il est possible de minimiser encore plus le nombre de partitions à requêter, ce qui améliore les performances en lecture (par exemple, si nos requêtes s’effectuent sur une plage de temps d’une journée, préciser un partitionnement par jour nous permettra de ne requêter que la partition correspondant à nos besoins).
Partitionner la donnée selon la date dans des tables relationnelles permet de facilement distribuer la donnée sur plusieurs noeuds. Cela limite le nombre de tables requêtées à chaque lecture. De plus, l’ajout et la mise à jour de données sur un intervalle de temps passé est possible, même si elles ne sont pas fréquentes. Il est possible de mettre en place une stratégie d’allocation de ressources en fonction de l’activité du shard (données chaudes pour les intervalles récent, et donnée froide pour des intervalles passés).
3) Pour ses fonctionnalités
Les TSDBs mettent à disposition des outils d’analyse des données temporelles que les autres bases de données ne proposent pas en général. Ces outils simplifient l’analyse en proposant des fonctions plus simples d’utilisation, mais aussi des fonctions permettant de requêter de grands volumes de données sans surcharger le client, et de façon plus précise.
Quelques exemple de fonctionnalités :
- Downsampling : Permet d'agréger le nombre de points de données en amont afin d’améliorer les performances en lecture lorsqu’une requête est effectuée sur une large fenêtre de temps.
- Continuous Queries : Requêtes calculées et recalculées au fur et à mesure que de la donnée est ajoutée dans la base. Très utile lorsqu’il faut alimenter des dashboards en temps-réel.
- Data Retention Policy : Supprime la donnée après un certain temps. Celle-ci se base sur la dimension de temps. Par exemple, en précisant une durée de 24h, toutes les données ayant été injectées dans la base il y a 24h et plus seront supprimées.
- Time aggregation : Agrégation de la donnée selon l’axe de temps.
Les fonctionnalités énoncées plus haut semblent être partagées par de nombreuses TSDBs. Plus généralement, chaque TSDB possède son lot de fonctionnalités qui lui est propre.
4) Pour aller plus loin
Voici un article sur InfluxDB pour découvrir comment cela fonctionne sous le capot https://docs.influxdata.com/influxdb/v1.8/concepts/storage_engine/
Voici un article du blog Octo décrivant l’usage d’InfluxDB pour du monitoring de système https://blog.octo.com/monitorer-votre-infra-avec-telegraf-influxdb-et-grafana/
Conclusion
En conclusion, les TSDBs sont des bases de données adaptées à la gestion et au stockage d’un certain type de données (données datées), mais aussi à la manière dont elles seront consommées (requêtage par fenêtre continue de temps par exemple). Elles sont inspirées des technologies existantes et leur mode de fonctionnement (processus d’écriture, lecture, etc..) a été optimisé en prenant en compte la nature de la donnée traitée. Ces bases sont pour la plupart des bases de données NOSQL comme InfluxDB, mais peuvent aussi appartenir à la famille des bases de données relationnelles comme TimescaleDB. Leur capacité à prendre en charge un très grand nombre de données les rend populaires auprès de nombreux projets tel que ceux utilisant l’IoT.
Avec du recul, la stratégie adoptée lors de mon stage concernant la comparaison de ces deux TSDBs aurait pu être différente. Actuellement, et comme dit plus haut, la découverte et la prise en main de ces deux TSDBs nous a permis de conclure que leur utilisation est adaptée au cas d’usage Aura. Il nous est possible de conclure pour ce cas d’usage que la surcouche TimescaleDB de PostgreSQL nous permet d’avoir les mêmes performances en écriture et en lecture qu’une TSDB by-design tel qu’Influx. En effet, lors des tests, 30 millions de points étaient injectés en 1 heure environ dans l’une ou l’autre des bases de données.
L’utilisation d’une base de donnée relationnelle à laquelle on ajoute un module Timeseries offrirait des avantages supplémentaires par rapport à une TSDBs by-design ?
Sans être devenu un expert, j’ai pu prendre en main ces deux TSDBs “en surface” tout en essayant de découvrir ce qu’elles avaient “sous le capot”. Le déploiement et le requêtage de la donnée se font aisément. Cependant la compréhension de l’architecture mise en place pour les deux bases de données est beaucoup moins facile et il reste encore des choses à explorer.
A ce jour, je ne pourrai affirmer que ces technologies sont assez matures pour être déployées en production. Cependant, après six mois de stage et compte tenu du cas d’usage et de l’étude menée concernant ces deux bases, on peut conclure qu’elles sont adaptées à un projet IoT.